データサイエンスが活きる文化と苦しむ文化 [データサイエンス、統計モデル]
そういえば、転職して3年が過ぎた。
上手く行ったプロジェクトもあったが、そうでなかったプロジェクトもある。
少し振り返ってみると・・・
データサイエンス組織が会社で活きるために必要な文化ってなんだろうか?
大きく2つあるように感じる。
1. 予算を取得するまでに、時間がかかりすぎる
(アイデアを試すまでの時間が長い)
やってみないとわからないことが多い。
いきなり、「数億の金をくれ」といっているわけではない。
小さなPOCをするために何ヶ月も説明をし、頭が硬い役員を説得し続けるのは疲れる。
2. データサイエンスが分かってる人の割合
わかりやすく書くと、仲間がいるかどうか。
既にチームがある場合、そこのチームとの相性もある。
ML組織がある場合、割と、データサイエンスとの親和性はあるように感じる。
一方、アナリティクスの人にデータサイエンスを伝えることは難しい。
アナリティクス:基本的なシンプルな集計で戦略や方向性を考える。
わかりやすい言葉を説明すると、要は風呂敷を拡げる。
その風呂敷を畳む、実現可能な施策に落とし込むのがデータサイエンス。
この風呂敷をアナリストとデータサイエンスが良い具合に作ることが重要。
ここの相性が悪いと、絵に描いた餅を出してみろとか、屏風の虎といったことが起こる。
自分自身は、アナリストとデータサイエンティストは、メロンパンとメロン(フルーツ)くらいの差があると思っている。
なんとなく似たものだし、味も似ているかもしれないが、実際は全然異なる。
メロンパンしか食べたことがない人にメロンの味を伝えることは難しいのだ。
上手く行ったプロジェクトもあったが、そうでなかったプロジェクトもある。
少し振り返ってみると・・・
データサイエンス組織が会社で活きるために必要な文化ってなんだろうか?
大きく2つあるように感じる。
1. 予算を取得するまでに、時間がかかりすぎる
(アイデアを試すまでの時間が長い)
やってみないとわからないことが多い。
いきなり、「数億の金をくれ」といっているわけではない。
小さなPOCをするために何ヶ月も説明をし、頭が硬い役員を説得し続けるのは疲れる。
2. データサイエンスが分かってる人の割合
わかりやすく書くと、仲間がいるかどうか。
既にチームがある場合、そこのチームとの相性もある。
ML組織がある場合、割と、データサイエンスとの親和性はあるように感じる。
一方、アナリティクスの人にデータサイエンスを伝えることは難しい。
アナリティクス:基本的なシンプルな集計で戦略や方向性を考える。
わかりやすい言葉を説明すると、要は風呂敷を拡げる。
その風呂敷を畳む、実現可能な施策に落とし込むのがデータサイエンス。
この風呂敷をアナリストとデータサイエンスが良い具合に作ることが重要。
ここの相性が悪いと、絵に描いた餅を出してみろとか、屏風の虎といったことが起こる。
自分自身は、アナリストとデータサイエンティストは、メロンパンとメロン(フルーツ)くらいの差があると思っている。
なんとなく似たものだし、味も似ているかもしれないが、実際は全然異なる。
メロンパンしか食べたことがない人にメロンの味を伝えることは難しいのだ。
標準 ベイズ統計学 [データサイエンス、統計モデル]

- 出版社/メーカー: 朝倉書店
- 発売日: 2022/06/08
- メディア: 単行本
朝野先生が勧められていた本。
以前、amazonで購入しようとしたら売り切れて変えなかったのだが、たまたま確認したら売っていたので、即購入。
実際、Rのコードも載っているし、説明も詳しい。
曖昧になっていた部分がスッキリする本なので、手元において繰り返し読みたいと思います。
生存時間分析: パラメトリック [データサイエンス、統計モデル]
指数関数:時間経過に伴ってハザード関数が変化しない
指数生存分布が無記憶性を持つため、運が良かったら生き残るが、運が悪かったら死ぬというモデル。
短期間のモデリングには使えるが、長期のモデリングには向いていない。
ワイブル分布:時間経過に伴ってハザード関数が単調増加する
対数正規分布, 対数ロジスティック分布:時間経過に伴ってハザード関数が増加する部分と減少する部分が混在する
Rで実行する場合は、これらは以下のコードで簡単に実行できる。
## model1-指数分布
model1 <- survreg(Surv(time, status) ~ xxx,
data=Dataset, dist="exponential")
## model2-ワイブル分布
model2 <- survreg(Surv(time, status) ~ xxx,
data=Dataset, dist="weibull")
summary(model2)
## model3-対数正規分布
model3 <- survreg(Surv(time, status) ~ xxx,
data=Dataset, dist="lognormal")
summary(model3)
## model4-対数ロジスティック分布
model4 <- survreg(Surv(time, status) ~ xxx,
data=Dataset, dist="loglogistic")
summary(model4)
指数生存分布が無記憶性を持つため、運が良かったら生き残るが、運が悪かったら死ぬというモデル。
短期間のモデリングには使えるが、長期のモデリングには向いていない。
ワイブル分布:時間経過に伴ってハザード関数が単調増加する
対数正規分布, 対数ロジスティック分布:時間経過に伴ってハザード関数が増加する部分と減少する部分が混在する
Rで実行する場合は、これらは以下のコードで簡単に実行できる。
## model1-指数分布
model1 <- survreg(Surv(time, status) ~ xxx,
data=Dataset, dist="exponential")
## model2-ワイブル分布
model2 <- survreg(Surv(time, status) ~ xxx,
data=Dataset, dist="weibull")
summary(model2)
## model3-対数正規分布
model3 <- survreg(Surv(time, status) ~ xxx,
data=Dataset, dist="lognormal")
summary(model3)
## model4-対数ロジスティック分布
model4 <- survreg(Surv(time, status) ~ xxx,
data=Dataset, dist="loglogistic")
summary(model4)
生存時間分析: セミパラメトリック [データサイエンス、統計モデル]
生きるか死ぬか、といったバイナリ(1 or 0)のモデルかといえば、ロジスティック回帰もあります。
ロジスティック回帰分析と生存時間分析の違いは?
1,0にのみ興味がある場合 → ロジスティック回帰分析
1,0にのみ興味があるが、時間間隔にも興味がある → 生存時間分析
カプランマイヤー(kaplan-meier)とcoxの比例ハザードモデルの違いは何か?
説明変数が1つだけ:カプランマイヤー法
説明変数が複数ある:コックス比例ハザードモデル
# コックス比例ハザード回帰分析
head(Dataset)
# コックス比例ハザード回帰分析
model.cox <- coxph(Surv(time, status) ~ line_ex + multi_br + br_ex+ave_disc + sum_disp + sum_flier + ave_PI + max_price,
data = Dataset)
# 分析結果の確認
summary(model.cox)
説明変数は、下記のとおりです。
#ライン拡張フラグ(1ライン拡張0それ以外):line_ex
#マルチブランド(1マルチブランド0それ以外):multi_br
#ブランド拡張(1ブランド拡張0それ以外):br_ex
#発売後4週間山積み陳列実施日数:ave_disc
#発売後4週間チラシ掲載日数:sum_disp
#発売後4週間平均点数PI: sum_flier
#最大売価: ave_PI
#発売後4週間平均値引き率: max_price
")
ロジスティック回帰分析と生存時間分析の違いは?
1,0にのみ興味がある場合 → ロジスティック回帰分析
1,0にのみ興味があるが、時間間隔にも興味がある → 生存時間分析
カプランマイヤー(kaplan-meier)とcoxの比例ハザードモデルの違いは何か?
説明変数が1つだけ:カプランマイヤー法
説明変数が複数ある:コックス比例ハザードモデル
# コックス比例ハザード回帰分析
head(Dataset)
# コックス比例ハザード回帰分析
model.cox <- coxph(Surv(time, status) ~ line_ex + multi_br + br_ex+ave_disc + sum_disp + sum_flier + ave_PI + max_price,
data = Dataset)
# 分析結果の確認
summary(model.cox)
説明変数は、下記のとおりです。
#ライン拡張フラグ(1ライン拡張0それ以外):line_ex
#マルチブランド(1マルチブランド0それ以外):multi_br
#ブランド拡張(1ブランド拡張0それ以外):br_ex
#発売後4週間山積み陳列実施日数:ave_disc
#発売後4週間チラシ掲載日数:sum_disp
#発売後4週間平均点数PI: sum_flier
#最大売価: ave_PI
#発売後4週間平均値引き率: max_price
- 作者: 佐藤 忠彦
- 出版社/メーカー: 朝倉書店
- 発売日: 2015/08/25
- メディア: 単行本(ソフトカバー)
生存時間分析: ノンパラメトリック [データサイエンス、統計モデル]
Rを使った生存時間分析(ノンパラメトリック)です。
# ノンパラメトリック
# カプランマイヤー(kaplan-meier)
# カプランマイヤー(kaplan-meier)
with(data=Dataset, Surv(time, status))[1:20]
survfit(Surv(time, status)~1, data=Dataset)
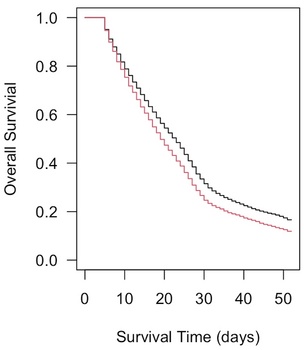
# カプランマイヤー曲線
survfit1 <- survfit(Surv(time, status)~1, data=Dataset)
plot(survfit1)
plot(survfit1, conf.int=FALSE, las=1, xlab="Survival Time (days)", ylab="Overall Survival")
# グループ別のカプランマイヤー曲線
survfit2 <- survfit(Surv(time,status)~multi_br, data=Dataset)
survfit2
plot(survfit2,las=1,xlab="Survival Time (days)", ylab="Overall Survivial", lty=1, col=1:2)
# ノンパラメトリック
# カプランマイヤー(kaplan-meier)
# カプランマイヤー(kaplan-meier)
with(data=Dataset, Surv(time, status))[1:20]
survfit(Surv(time, status)~1, data=Dataset)
# カプランマイヤー曲線
survfit1 <- survfit(Surv(time, status)~1, data=Dataset)
plot(survfit1)
plot(survfit1, conf.int=FALSE, las=1, xlab="Survival Time (days)", ylab="Overall Survival")
# グループ別のカプランマイヤー曲線
survfit2 <- survfit(Surv(time,status)~multi_br, data=Dataset)
survfit2
plot(survfit2,las=1,xlab="Survival Time (days)", ylab="Overall Survivial", lty=1, col=1:2)
生存時間分析の3つのアプローチ [データサイエンス、統計モデル]
生存時間分析の3つのアプローチ
1.ノンパラメトリック
2.セミパラメトリック
3.パラメトリック
Rで解析を行うには、survfitが便利らしい。
1.ノンパラメトリック
カプランマイヤー(kaplan-meier)を使う。
2.セミパラメトリック
coxの比例ハザードモデルが有名。
部分的にパラメトリック、疫学が中心。
3.パラメトリック
指数分布、ワイブル、対数正規、対数ロジスティック、ガンマ
将来的に、階層ベイズに持ち込むには、(ワイブル or 対数正規)でモデルを作る。
1.ノンパラメトリック
2.セミパラメトリック
3.パラメトリック
Rで解析を行うには、survfitが便利らしい。
1.ノンパラメトリック
カプランマイヤー(kaplan-meier)を使う。
2.セミパラメトリック
coxの比例ハザードモデルが有名。
部分的にパラメトリック、疫学が中心。
3.パラメトリック
指数分布、ワイブル、対数正規、対数ロジスティック、ガンマ
将来的に、階層ベイズに持ち込むには、(ワイブル or 対数正規)でモデルを作る。
- 作者: 佐藤 忠彦
- 出版社/メーカー: 朝倉書店
- 発売日: 2015/08/25
- メディア: 単行本(ソフトカバー)
エンゲージメントの測定 [データサイエンス、統計モデル]
以下のような課題を考えるとします。
Aさん
4月の購入確率:0.9
5月の購入確率:0.8
Bさん
4月の購入確率:0.2
5月の購入確率:0.1
Cさん
4月の購入確率:0.5
5月の購入確率:0.1
今、離反防止施策を考えた時に、Aさんは対象外というのはわかりやすい。
Bさんはどうか?
元々、エンゲージメントが薄い顧客なので、毎月の購入確率は低いが特に離反をしているというわけではない。
Cさんの場合、エンゲージメントが高かった、急速にエンゲージメントが悪化している。
これらのエンゲージメントとその悪化要因をどうじに測定できないだろうか?
Aさん
4月の購入確率:0.9
5月の購入確率:0.8
Bさん
4月の購入確率:0.2
5月の購入確率:0.1
Cさん
4月の購入確率:0.5
5月の購入確率:0.1
今、離反防止施策を考えた時に、Aさんは対象外というのはわかりやすい。
Bさんはどうか?
元々、エンゲージメントが薄い顧客なので、毎月の購入確率は低いが特に離反をしているというわけではない。
Cさんの場合、エンゲージメントが高かった、急速にエンゲージメントが悪化している。
これらのエンゲージメントとその悪化要因をどうじに測定できないだろうか?
多項ロジットモデルの最尤推定 [データサイエンス、統計モデル]
多項ロジットモデルは、対象が3つ以上の質的変数を目的変数とする推定する
## R package [nnet] を利用 library(nnet)
## 多項ロジスティック判別を実行
Logistic = multinom(grape ~ ., data = wine.train) summary(Logistic)
パッケージを使うと一行でかけるのですが、最尤法を実装してみました。
小数点の細かい部分で誤差は出ていますが、パッケージでの実行結果と同じになっています。
##多項ロジットモデル
hh <-nrow(wine.train) ##データ数 b0<-c(0, 0, 0, 0, 0, 0)
## Logit model の対数尤度関数の定義 fr <- function(x) {
LL = 0
a0 <- x[1] # grape2 切片 a1 <- x[2] # grape2 x1 a2 <- x[3] # grape2 x2 b0 <- x[4] # grape3 切片 b1 <- x[5] # grape3 x1 b2 <- x[6] # grape3 x2
# 効用の計算
U_1 <- 0
U_2 <- a0 + a1*wine.train[,"x1"] + a2*wine.train[,"x2"]
U_3 <- b0 + b1*wine.train[,"x1"] + b2*wine.train[,"x2"]
d <- exp(U_1) + exp(U_2) + exp(U_3)
LLI <- wine.train[,"grape1"]*U_1 + wine.train[,"grape2"]*U_2
+ wine.train[,"grape3"]*U_3 -log(d)
##対数尤度の計算 LL <- sum(LLI) return(LL)
}
## 対数尤度関数fr の最大化
res <- optim(b0, fr, method = "BFGS", hessian = TRUE,
control=list(fnscale=-1))
matrix(res$par, nrow = 2, ncol = 3, byrow = T)

## R package [nnet] を利用 library(nnet)
## 多項ロジスティック判別を実行
Logistic = multinom(grape ~ ., data = wine.train) summary(Logistic)
パッケージを使うと一行でかけるのですが、最尤法を実装してみました。
小数点の細かい部分で誤差は出ていますが、パッケージでの実行結果と同じになっています。
##多項ロジットモデル
hh <-nrow(wine.train) ##データ数 b0<-c(0, 0, 0, 0, 0, 0)
## Logit model の対数尤度関数の定義 fr <- function(x) {
LL = 0
a0 <- x[1] # grape2 切片 a1 <- x[2] # grape2 x1 a2 <- x[3] # grape2 x2 b0 <- x[4] # grape3 切片 b1 <- x[5] # grape3 x1 b2 <- x[6] # grape3 x2
# 効用の計算
U_1 <- 0
U_2 <- a0 + a1*wine.train[,"x1"] + a2*wine.train[,"x2"]
U_3 <- b0 + b1*wine.train[,"x1"] + b2*wine.train[,"x2"]
d <- exp(U_1) + exp(U_2) + exp(U_3)
LLI <- wine.train[,"grape1"]*U_1 + wine.train[,"grape2"]*U_2
+ wine.train[,"grape3"]*U_3 -log(d)
##対数尤度の計算 LL <- sum(LLI) return(LL)
}
## 対数尤度関数fr の最大化
res <- optim(b0, fr, method = "BFGS", hessian = TRUE,
control=list(fnscale=-1))
matrix(res$par, nrow = 2, ncol = 3, byrow = T)
スパース回帰分析とパターン認識 データサイエンス入門シリーズ
- 出版社/メーカー: 講談社
- 発売日: 2020/04/30
- メディア: Kindle版
エクセルで分散を計算、VAR.SとVAR.Pの違い [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
エクセルの関数で分散を計算するとき、VAR.SとVAR.Pの違いがわかりません。
【回答】
VAR.S:不偏分散
VAR.P:標本分散
↑
データ数が多い場合は、どっちを使ってもほとんど同じ結果になります。
不偏分散を使い場合
抽出したデータの分散に興味があるのではなく、その背後にある母集団の分散に興味がある場合です。
例えば、センター試験の点数の分散を計算するときに、受験生を10人ランダムに抽出して分散を計算しました。
10人の分散はあくまでも抽出した人の分散なので、母集団の分散を推定するためには少し補正が必要です。
このような場合にVAR.S:不偏分散を使います。
標本分散を使う場合
学校で身長や体重の分散を計算したい。
子供全員のデータを使って分散を計算します。
この場合、背後にあるなんらかの母集団を仮定しているわけではなく、標本そのものの分散に興味あります。
この場合にVAR.P:標本分散を使います。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
エクセルの関数で分散を計算するとき、VAR.SとVAR.Pの違いがわかりません。
【回答】
VAR.S:不偏分散
VAR.P:標本分散
↑
データ数が多い場合は、どっちを使ってもほとんど同じ結果になります。
不偏分散を使い場合
抽出したデータの分散に興味があるのではなく、その背後にある母集団の分散に興味がある場合です。
例えば、センター試験の点数の分散を計算するときに、受験生を10人ランダムに抽出して分散を計算しました。
10人の分散はあくまでも抽出した人の分散なので、母集団の分散を推定するためには少し補正が必要です。
このような場合にVAR.S:不偏分散を使います。
標本分散を使う場合
学校で身長や体重の分散を計算したい。
子供全員のデータを使って分散を計算します。
この場合、背後にあるなんらかの母集団を仮定しているわけではなく、標本そのものの分散に興味あります。
この場合にVAR.P:標本分散を使います。
男女賃金格差の問題 [データサイエンス、統計モデル]
以前、男女賃金格差の問題について、統計モデルを作り構造を明らかにしたのだが、各所で話題になっており、こういう分析をサポートできたことが嬉しい。
職種、入社前の賃金(前職の賃金)、入ってからの伸び代の多寡など、さまざまな要因がある。
そういった影響を除いたとしたら、いったどれくらいの賃金差があるのか。
簡単に見えて難しい。
それっぽい回帰分析を適用しても、真の構造は見えてこないだろう。
また、機械学習やAIといった技術でも解明できないし、誤った認識をしてしまう可能性がある。
まだまだ賃金のモデルは完成ではが、引き続きリサーチを続けていきたいと思う。
職種、入社前の賃金(前職の賃金)、入ってからの伸び代の多寡など、さまざまな要因がある。
そういった影響を除いたとしたら、いったどれくらいの賃金差があるのか。
簡単に見えて難しい。
それっぽい回帰分析を適用しても、真の構造は見えてこないだろう。
また、機械学習やAIといった技術でも解明できないし、誤った認識をしてしまう可能性がある。
まだまだ賃金のモデルは完成ではが、引き続きリサーチを続けていきたいと思う。
給料の補正と階層ベイズ [データサイエンス、統計モデル]
階層ベイズの事例に、給料の事例がよく載っています。
おそらくアヒル本とかで紹介されて、みんなその事例を使っているのかなと。
実際に、階層ベイズと給料の関係は相性がよく、男性と女性のPayGapを考えた際に、単純な回帰モデルではなく、階層ベイズを使った方が構造含めて理解できるので、とても強力な手法だったりします。
最近、階層ベイズを使った給料のモデリングを行っており、どこかの学会で発表とかできないかなと。
おそらくアヒル本とかで紹介されて、みんなその事例を使っているのかなと。
実際に、階層ベイズと給料の関係は相性がよく、男性と女性のPayGapを考えた際に、単純な回帰モデルではなく、階層ベイズを使った方が構造含めて理解できるので、とても強力な手法だったりします。
最近、階層ベイズを使った給料のモデリングを行っており、どこかの学会で発表とかできないかなと。
ロケーションテック [データサイエンス、統計モデル]
位置情報を使ったビジネスの事例紹介の本。
")
10年くらい前に、位置情報データで何ができるかをいろいろ検討した時期がありましたが、
時代が巡り巡って、今だとどんなことができるのか。
いろいろなことは技術的にできるようになってきたが、
個人情報的な部分も多いので、どこまでそれを活用するか、
というのはあると思います。
位置情報だけでなく、基本的なデータ含めたリコメンドもそうですよね。
個別に最適化していけばいくほど、そのリコメンドによって、自分自身の興味も狭くなっていく危険も出てくる。
- 出版社/メーカー: 日経BP 日本経済新聞出版
- 発売日: 2022/04/12
- メディア: ムック
10年くらい前に、位置情報データで何ができるかをいろいろ検討した時期がありましたが、
時代が巡り巡って、今だとどんなことができるのか。
いろいろなことは技術的にできるようになってきたが、
個人情報的な部分も多いので、どこまでそれを活用するか、
というのはあると思います。
位置情報だけでなく、基本的なデータ含めたリコメンドもそうですよね。
個別に最適化していけばいくほど、そのリコメンドによって、自分自身の興味も狭くなっていく危険も出てくる。
スパース回帰分析とパターン認識 [データサイエンス、統計モデル]
データサイエンスの本は割とpythonで書かれている本が多いのですが、めずらしくRで書かれている本。
そして、Rで書かれているだけでなく、数理的な展開がとても丁寧に書かれていました。
")
テーマとしては、スパース推定だけでなく、流行りの深層学習やパターン認識が書かれています。
このあたりは、自分は避けてきた内容なので、こういう世界もあるんだなという新鮮な印象でした。
そして、Rで書かれているだけでなく、数理的な展開がとても丁寧に書かれていました。
スパース回帰分析とパターン認識 (データサイエンス入門シリーズ)
- 出版社/メーカー: 講談社
- 発売日: 2020/02/28
- メディア: 単行本(ソフトカバー)
テーマとしては、スパース推定だけでなく、流行りの深層学習やパターン認識が書かれています。
このあたりは、自分は避けてきた内容なので、こういう世界もあるんだなという新鮮な印象でした。
線形回帰と変数の貢献度 [データサイエンス、統計モデル]
ビジネス側の知りたいこととして、各変数がどれくらい目的変数に影響を与えているかを知りたいというの多い。
y = b0 + b1*x1 + b2*x2 + b3*x3 +eというモデルの場合、
変数x1が30%, x2が40%, x3が20%、残りが10%
実際は、各変数は独立でなく、相関があります。
なので、標準化偏回帰係数を使って、各変数の効果量を計算しても、他の効果量が混ざってしまいます。
少し調べてみたら、relative weight analysis(RWA)がありました。
あまり見ない方法なのですが、今度、トライしてみようと思います。
y = b0 + b1*x1 + b2*x2 + b3*x3 +eというモデルの場合、
変数x1が30%, x2が40%, x3が20%、残りが10%
実際は、各変数は独立でなく、相関があります。
なので、標準化偏回帰係数を使って、各変数の効果量を計算しても、他の効果量が混ざってしまいます。
少し調べてみたら、relative weight analysis(RWA)がありました。
あまり見ない方法なのですが、今度、トライしてみようと思います。
JMRA、マハラノビス研究会報告 [データサイエンス、統計モデル]
「マハラノビス研究会報告」&「データ解析担当者交流会」
https://www.jmra-net.or.jp/activities/seminar/2023/20230728.html
マハラノビス研究会報告 朝野熙彦
https://www.jmra-net.or.jp/Portals/0/committee/innovation/20230414_001.pdf
「マハラノビス研究会報告」&「データ解析担当者交流会」に行ってきました。
前半が報告会で、後半が交流会。
交流会は懐かしい人や一緒に研究をした人たちと交流することができとても役に立ちました。
引き続き研究を進めたいなと気持ちが強くなった今日この頃です。
https://www.jmra-net.or.jp/activities/seminar/2023/20230728.html
マハラノビス研究会報告 朝野熙彦
https://www.jmra-net.or.jp/Portals/0/committee/innovation/20230414_001.pdf
「マハラノビス研究会報告」&「データ解析担当者交流会」に行ってきました。
前半が報告会で、後半が交流会。
交流会は懐かしい人や一緒に研究をした人たちと交流することができとても役に立ちました。
引き続き研究を進めたいなと気持ちが強くなった今日この頃です。
マハラノビス研究会報告 [データサイエンス、統計モデル]
JMRA(日本マーケティングリサーチ協会)
https://www.jmra-net.or.jp/committee/researchinnovation.html
昨年、朝野先生たちとマハラノビスについての研究を行っていたのですが、
(↑から)研究会報告をダウンロードできます。
自分は、多重共線性あたりを研究していました。
https://www.jmra-net.or.jp/committee/researchinnovation.html
昨年、朝野先生たちとマハラノビスについての研究を行っていたのですが、
(↑から)研究会報告をダウンロードできます。
自分は、多重共線性あたりを研究していました。
平均・分散から始める一般化線形モデル入門 [データサイエンス、統計モデル]
状態空間モデルを理解するのに馬場さんの本がものすごくわかりやすかったので、こちらも買いました。

なかなか分散にフォーカスした本がないので、貴重な本だと思っています。
ブートストラップ、最尤法からはじまり、一般化線形モデルに話が続きます。
そして、ANOVAやゼロ切断モデルといった少しマニアックな話も出てきました。
こういう角度からモデリングを見つめ直してみるのも面白いですね。
- 作者: 馬場 真哉
- 出版社/メーカー: プレアデス出版
- 発売日: 2015/07/14
- メディア: 単行本
なかなか分散にフォーカスした本がないので、貴重な本だと思っています。
ブートストラップ、最尤法からはじまり、一般化線形モデルに話が続きます。
そして、ANOVAやゼロ切断モデルといった少しマニアックな話も出てきました。
こういう角度からモデリングを見つめ直してみるのも面白いですね。
ROC-AUCではなくAUPRCが良いらしい [データサイエンス、統計モデル]
Unbalanced Data? Stop Using ROC-AUC and Use AUPRC Instead
https://towardsdatascience.com/imbalanced-data-stop-using-roc-auc-and-use-auprc-instead-46af4910a494
こちらの記事によると・・・
多くの場合、ROC-AUCを使っている人も多いですが
(自分も使っていますが)
データがアンバランスな場合はAUPRCという記事です。
例えば、インターネットの世界では、反応する人はかなり少ない。
y=1: 20
y=0: 2000
だったとします。
実際はもっと極端かもしれません。
この場合は、y=1を見つける速度に違いがあるため、ROC-AUCではなく、AUPRCを使うのがいいらしい。
https://towardsdatascience.com/imbalanced-data-stop-using-roc-auc-and-use-auprc-instead-46af4910a494
こちらの記事によると・・・
多くの場合、ROC-AUCを使っている人も多いですが
(自分も使っていますが)
データがアンバランスな場合はAUPRCという記事です。
例えば、インターネットの世界では、反応する人はかなり少ない。
y=1: 20
y=0: 2000
だったとします。
実際はもっと極端かもしれません。
この場合は、y=1を見つける速度に違いがあるため、ROC-AUCではなく、AUPRCを使うのがいいらしい。
評価指標入門〜データサイエンスとビジネスをつなぐ架け橋 [データサイエンス、統計モデル]
評価指標入門〜データサイエンスとビジネスをつなぐ架け橋

どういう場合にどんな評価指標を使えばいいのか、意外と難しい。
たぶん多くの誤用が見られるし、当時はこれが正しいと思っていても、実は別の指標が良いかもというアップデートも定期的に必要。
- 出版社/メーカー: 技術評論社
- 発売日: 2023/02/18
- メディア: Kindle版
どういう場合にどんな評価指標を使えばいいのか、意外と難しい。
たぶん多くの誤用が見られるし、当時はこれが正しいと思っていても、実は別の指標が良いかもというアップデートも定期的に必要。
米マイクロソフト、追加の人員削減発表へ [データサイエンス、統計モデル]
世界的に多くの企業がレイオフを始めています。
マイクロソフトだけでなく、amazonとかfacebookとか、
少し前までは、セクシィな仕事としてデータサイエンティストはブームになり、
エンジニア系のデータサイエンティストが雨上がりの筍の様に湧いてきていた気がします。
![週刊ダイヤモンド22年2/12号 [雑誌]](https://m.media-amazon.com/images/I/51-Ycquci7L._SL160_.jpg "週刊ダイヤモンド22年2/12号 [雑誌]")
そういえば、給料を3倍にするぞ、みたいな突然自分達が特別の人材のような振る舞いをする人たちもいましたね。
少しずつ、あるべき姿に戻りつつあるのかもしれません。
マイクロソフトだけでなく、amazonとかfacebookとか、
少し前までは、セクシィな仕事としてデータサイエンティストはブームになり、
エンジニア系のデータサイエンティストが雨上がりの筍の様に湧いてきていた気がします。
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2022/02/07
- メディア: Kindle版
そういえば、給料を3倍にするぞ、みたいな突然自分達が特別の人材のような振る舞いをする人たちもいましたね。
少しずつ、あるべき姿に戻りつつあるのかもしれません。
フィッシャーの線形判別とマハラノビスの距離 [データサイエンス、統計モデル]
フィッシャーの線形判別で距離を汎距離(マハラノビスの距離)に置き換えることで何が有利になるかを実験した。
郡を判別するシミュレーションデータを作成したが、結果は予想通り、汎距離(マハラノビスの距離)の方が精度が高い。
汎距離は、変数と変数の相関を利用するので、ある意味当然の結果となっている。
次のわからないこととして、二群の場合は話は簡単であるが、多群の場合、どうモデルを拡張したら良いかはよくわからない。
この辺りは引き続き、次のリサーチのネタとして考えていこうと思う。
郡を判別するシミュレーションデータを作成したが、結果は予想通り、汎距離(マハラノビスの距離)の方が精度が高い。
汎距離は、変数と変数の相関を利用するので、ある意味当然の結果となっている。
次のわからないこととして、二群の場合は話は簡単であるが、多群の場合、どうモデルを拡張したら良いかはよくわからない。
この辺りは引き続き、次のリサーチのネタとして考えていこうと思う。
t検定と分散分析の違い [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
t検定と分散分析の違いが分かりません。
【回答】
t検定は、一つの変数の効果について差があるかどうかを検定します。
F検定は、t検定と同じく一つの変数について検定もできるが、一般的には二つ以上の変数について検定する手法です。
一つの変数に適用した場合、t検定とF検定が一致します。
F検定一つ覚えておけば、t検定は不要なのですが、t検定の方が理解がしやすいってのがあるのかもしれません。
以下の通り、t検定とF検定の結果は一致します。
# t検定
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales, var.equal = T)
# t検定の結果
# t = -2.2088, df = 18, p-value = 0.04039
# F検定
sales <- c(A.sales, B.sales)
campaign.B <- c(rep(0,length(A.sales)), rep(1,length(B.sales)))
df <- as.data.frame(cbind(sales, campaign.B))
model.lm <- lm(sales ~ campaign.B, data=df)
# F検定の結果1
summary(model.lm)
# F-statistic: 4.879 on 1 and 18 DF, p-value: 0.04039
# F検定の結果2: 分散分析
anova(model.lm)
# campaign.B 1 782101 782101 4.879 0.04039
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
t検定と分散分析の違いが分かりません。
【回答】
t検定は、一つの変数の効果について差があるかどうかを検定します。
F検定は、t検定と同じく一つの変数について検定もできるが、一般的には二つ以上の変数について検定する手法です。
一つの変数に適用した場合、t検定とF検定が一致します。
F検定一つ覚えておけば、t検定は不要なのですが、t検定の方が理解がしやすいってのがあるのかもしれません。
以下の通り、t検定とF検定の結果は一致します。
# t検定
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales, var.equal = T)
# t検定の結果
# t = -2.2088, df = 18, p-value = 0.04039
# F検定
sales <- c(A.sales, B.sales)
campaign.B <- c(rep(0,length(A.sales)), rep(1,length(B.sales)))
df <- as.data.frame(cbind(sales, campaign.B))
model.lm <- lm(sales ~ campaign.B, data=df)
# F検定の結果1
summary(model.lm)
# F-statistic: 4.879 on 1 and 18 DF, p-value: 0.04039
# F検定の結果2: 分散分析
anova(model.lm)
# campaign.B 1 782101 782101 4.879 0.04039
正確多重共線性データに対するマハラノビスの距離 [データサイエンス、統計モデル]
多重共線性のデータを考える。
x1, x2, x3, x4, x5は、独立の正規分布
x_sum = x1 + x2 + x3 + x4 + x5
x1, x2 ,x3, x4, x5は、多重共線性が起こっていないが、x_sumを混ぜたデータは多重共線性が
起こっている。
データA:x1, x2, x3, x4, x5
データB:x1, x2, x3, x4, x5, x_sum
それぞれに、マハラノビスの距離、一般逆行列を使ったマハラノビスの距離を適用するとどうなるか?
# 実験1:多重共線性が起こっていないデータに通常の方法でmdを計算する
# 実験2:多重共線性が起こっているデータに通常の方法でmdを計算する
# 実験3:多重共線性が起こっていないデータに一般逆行列を使いmdを計算する
# 実験4:多重共線性が起こっているデータに一般逆行列を使いmdを計算する
実験2は、逆行列が計算できないのでエラーとなる。
一方で、実験1,3,4は同じ答えとなる。
つまり、逆行列を一般逆行列に拡張しても結果は同じ。
x1, x2, x3, x4, x5は、独立の正規分布
x_sum = x1 + x2 + x3 + x4 + x5
x1, x2 ,x3, x4, x5は、多重共線性が起こっていないが、x_sumを混ぜたデータは多重共線性が
起こっている。
データA:x1, x2, x3, x4, x5
データB:x1, x2, x3, x4, x5, x_sum
それぞれに、マハラノビスの距離、一般逆行列を使ったマハラノビスの距離を適用するとどうなるか?
# 実験1:多重共線性が起こっていないデータに通常の方法でmdを計算する
# 実験2:多重共線性が起こっているデータに通常の方法でmdを計算する
# 実験3:多重共線性が起こっていないデータに一般逆行列を使いmdを計算する
# 実験4:多重共線性が起こっているデータに一般逆行列を使いmdを計算する
実験2は、逆行列が計算できないのでエラーとなる。
一方で、実験1,3,4は同じ答えとなる。
つまり、逆行列を一般逆行列に拡張しても結果は同じ。
t検定と線形回帰分析の対応 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
t検定と線形回帰分析の対応が分かりません。
【回答】
一変数の場合、それぞれの結果を比較することで、回帰分析の結果の一部がt検定の結果と一致していることが確認できます。
t検定で検定しても良いのですが、統計モデルを作る方がより分析に広がりが出て来ます。
# t.test()
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales, var=T)
# t = -2.2088, df = 18, p-value = 0.04039
# lm
sales <- c(A.sales, B.sales)
campaign.B <- c(rep(0,length(A.sales)), rep(1,length(B.sales)))
df <- as.data.frame(cbind(sales, campaign.B))
model.lm <- lm(sales~campaign.B, data=df)
summary(model.lm)
# campaign.B 395.5 179.1 2.209 0.0404 *
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
t検定と線形回帰分析の対応が分かりません。
【回答】
一変数の場合、それぞれの結果を比較することで、回帰分析の結果の一部がt検定の結果と一致していることが確認できます。
t検定で検定しても良いのですが、統計モデルを作る方がより分析に広がりが出て来ます。
# t.test()
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales, var=T)
# t = -2.2088, df = 18, p-value = 0.04039
# lm
sales <- c(A.sales, B.sales)
campaign.B <- c(rep(0,length(A.sales)), rep(1,length(B.sales)))
df <- as.data.frame(cbind(sales, campaign.B))
model.lm <- lm(sales~campaign.B, data=df)
summary(model.lm)
# campaign.B 395.5 179.1 2.209 0.0404 *
多重共線性の話 ~その7 階層ベイズ [データサイエンス、統計モデル]
階層ベイズ回帰モデル
定式化
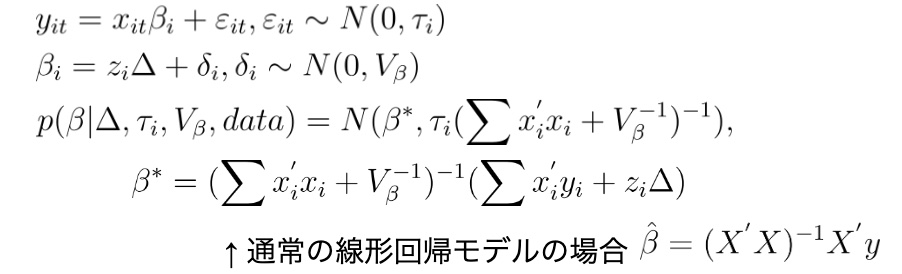
ridge回帰の正則化と同様のことが起こっているため、ベイズモデルは多重共線性を気にしなくても問題なさそうである。
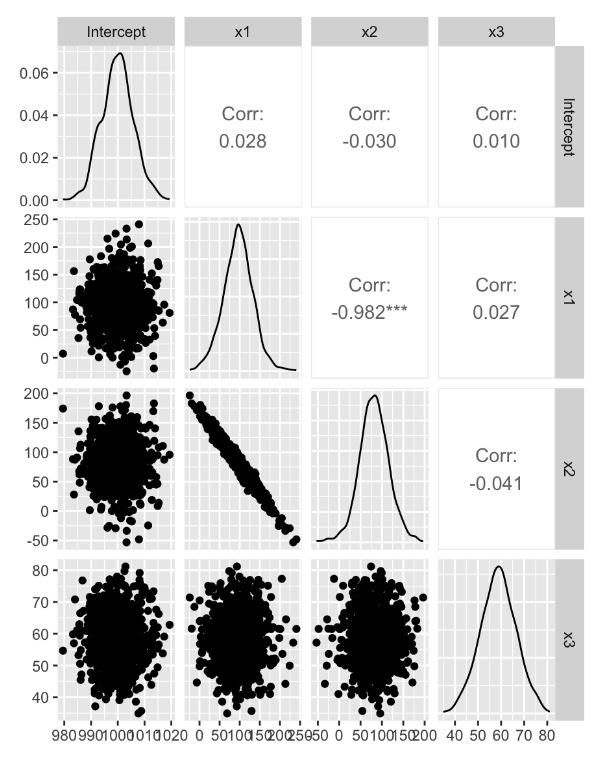
実際のデータでシミュレーションをすると。
【多重共線性が起こっているデータ(ランク落ちではない)】
結果は、シミュレーションデータを再現できているものの、x1,x2の係数の相関は、かなりつよい結果となっている
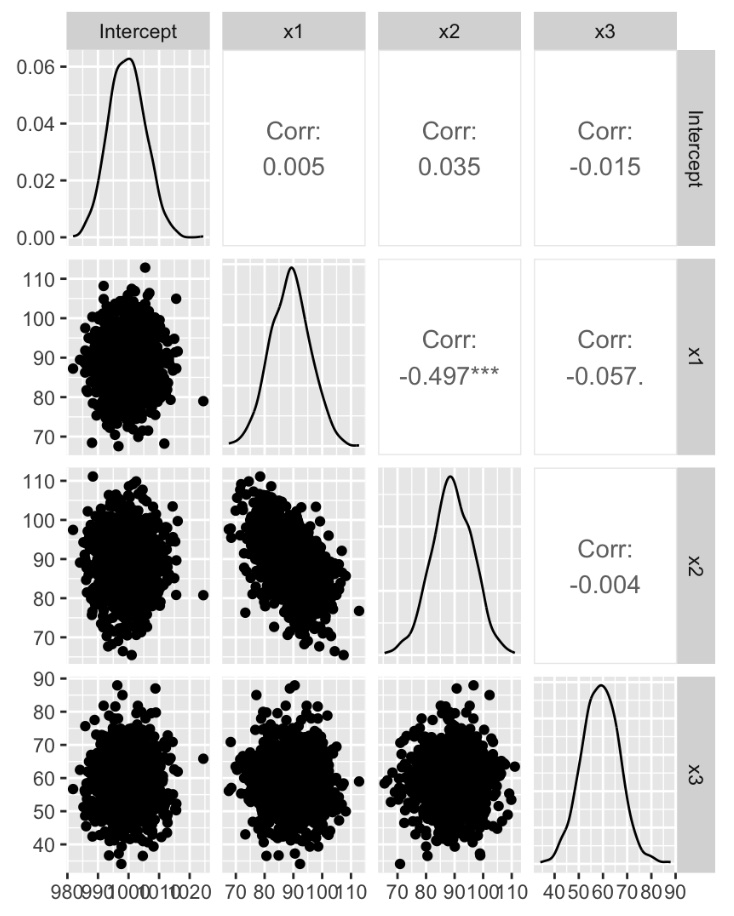
【完全多重共線性が起こっているデータ(ランク落ち)】
一般逆行列の場合と同様に、x1, x2で二等分した値になる
定式化
ridge回帰の正則化と同様のことが起こっているため、ベイズモデルは多重共線性を気にしなくても問題なさそうである。
実際のデータでシミュレーションをすると。
【多重共線性が起こっているデータ(ランク落ちではない)】
結果は、シミュレーションデータを再現できているものの、x1,x2の係数の相関は、かなりつよい結果となっている
【完全多重共線性が起こっているデータ(ランク落ち)】
一般逆行列の場合と同様に、x1, x2で二等分した値になる
多重共線性の話 ~その6 多重共線性を回避する方法 [データサイエンス、統計モデル]
多重共線性があると、逆行列が求められないのが問題。
特に、完全な多重共線性の場合(ランク落ちしている場合)は、計算ができない。
そこで、通常の逆行列を拡張した一般逆行列(ムーア・ペンローズ逆行列)を導入することで、この問題を回避することができます。
通常の行列式による、回帰係数は、以下のように計算できます。
beta <- solve((t(X) %*% X)) %*% t(X) %*% y
これを一般逆行列(ムーア・ペンローズ逆行列)で書くと
beta <- ginv((t(X) %*% X)) %*% t(X) %*% y
となります。
通常のデータやランク落ちしない多重共線性の場合は、答えは一致します。
では、ランク落ちしている場合はどうなるか?
y <- 1000 + 100*x1 + 80*x2 + 60*x3 + 100*e
という場合、
- lmの結果:多重共線性が起こっている片方の回帰係数がNAとなる
- 行列計算の場合:逆行列が計算できないので、「システムは正確に特異です」となる
- 一般逆行列の場合:x1=100, x2=80だが、x1, x2で二等分した値になる
(x1 ≒ x2 ≒ 90)
特に、完全な多重共線性の場合(ランク落ちしている場合)は、計算ができない。
そこで、通常の逆行列を拡張した一般逆行列(ムーア・ペンローズ逆行列)を導入することで、この問題を回避することができます。
通常の行列式による、回帰係数は、以下のように計算できます。
beta <- solve((t(X) %*% X)) %*% t(X) %*% y
これを一般逆行列(ムーア・ペンローズ逆行列)で書くと
beta <- ginv((t(X) %*% X)) %*% t(X) %*% y
となります。
通常のデータやランク落ちしない多重共線性の場合は、答えは一致します。
では、ランク落ちしている場合はどうなるか?
y <- 1000 + 100*x1 + 80*x2 + 60*x3 + 100*e
という場合、
- lmの結果:多重共線性が起こっている片方の回帰係数がNAとなる
- 行列計算の場合:逆行列が計算できないので、「システムは正確に特異です」となる
- 一般逆行列の場合:x1=100, x2=80だが、x1, x2で二等分した値になる
(x1 ≒ x2 ≒ 90)
多重共線性の話 ~その5 多重共線性を回避する方法 [データサイエンス、統計モデル]
多重共線性を回避する方法として、いろいろな方法があるが、
ぱっと思いつくのは、lasso回帰とridge回帰かもしれません。
lassoにしろridge回帰にしろ、基本的にはデータドリブンなアプローチなので、仮説発見としては良いかもしれませんが、背景の構造が明確な場合は、想定通りの結果にならない可能性があります。
例えば、lassoは、よくスパースなデータに対しての変数選択として使われます。
ridgeも正則化をしている意味では、数学的には似ています。
多重共線性が起こっている場合、一般に逆行列が計算できない問題が発生するが、正則化を追加することにより,回帰係数が不安定になることを防いでいます。
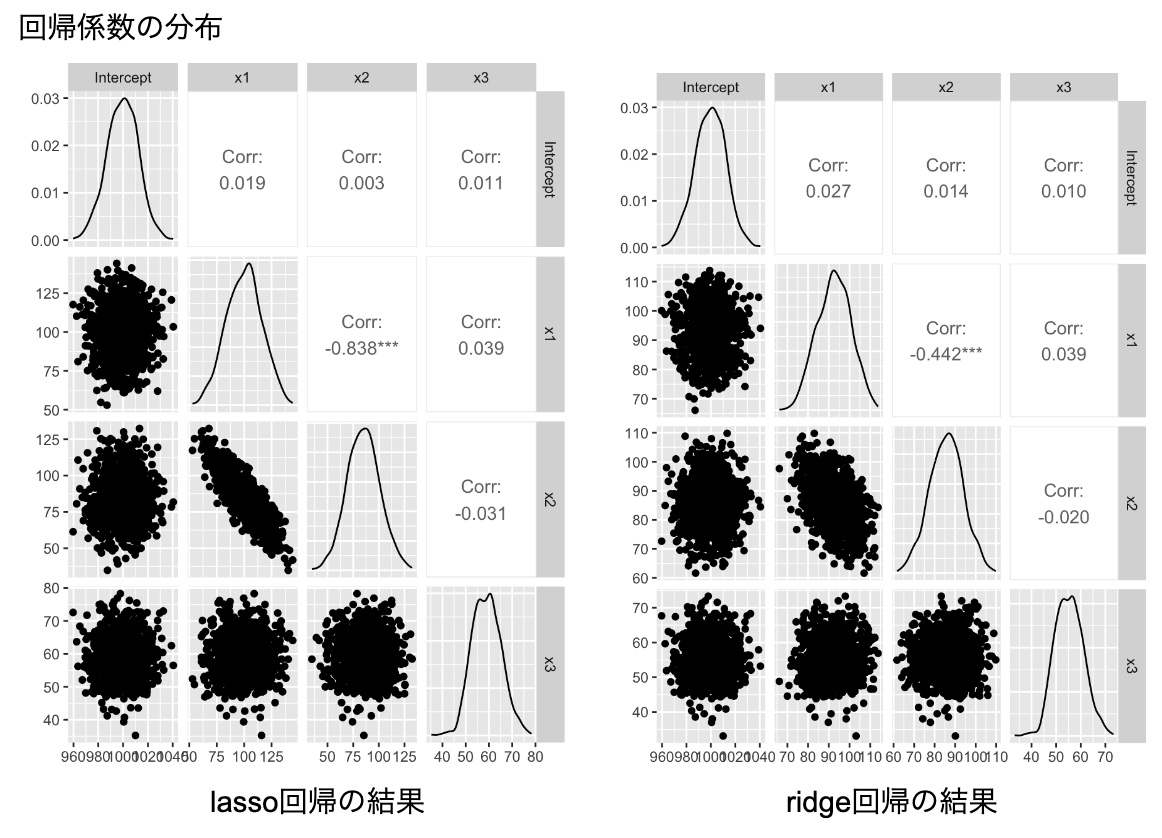
左の図はlassoの結果で、右の図がridge回帰の結果。
lasso回帰の方がridge回帰よりもx1とx2の(負の)相関は強い。
また、真のパラメータを再現できるわけではないですし、特に、ridge回帰の場合は、回帰係数が不安定になることを防ぐために、各回帰係数の値が小さく見積もられていることがわかります。
多重共線性が回避できたという感じはしなく、無難に線形回帰に近い結果が出てきているだけとも言えます。
ぱっと思いつくのは、lasso回帰とridge回帰かもしれません。
lassoにしろridge回帰にしろ、基本的にはデータドリブンなアプローチなので、仮説発見としては良いかもしれませんが、背景の構造が明確な場合は、想定通りの結果にならない可能性があります。
例えば、lassoは、よくスパースなデータに対しての変数選択として使われます。
ridgeも正則化をしている意味では、数学的には似ています。
多重共線性が起こっている場合、一般に逆行列が計算できない問題が発生するが、正則化を追加することにより,回帰係数が不安定になることを防いでいます。
左の図はlassoの結果で、右の図がridge回帰の結果。
lasso回帰の方がridge回帰よりもx1とx2の(負の)相関は強い。
また、真のパラメータを再現できるわけではないですし、特に、ridge回帰の場合は、回帰係数が不安定になることを防ぐために、各回帰係数の値が小さく見積もられていることがわかります。
多重共線性が回避できたという感じはしなく、無難に線形回帰に近い結果が出てきているだけとも言えます。
多重共線性の話 〜その4 一般的な問題点 [データサイエンス、統計モデル]
実験4: 実験2のデータ数を増やし、実験3と同様のシミュレーションを行う
多重共線性の対処法
データ量を増やす
追加情報を使う(β1+β2=1)
おまじない(民間療法)
説明変数を減らす
x1, x2の相関が高い場合、x1 - x2, x2を変数にする
階差を取る
データ数を減らす
データ数を300から3000,0000に増やし、実験3と同様のシミュレーションを1000回行った
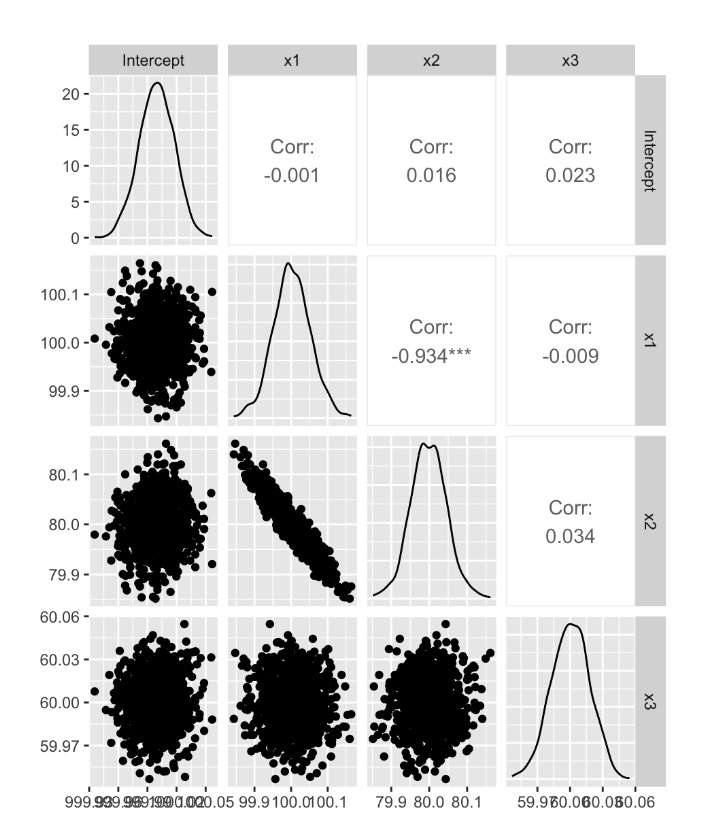
x1とx2の回帰係数の分布には相関が見られるものの、データを増やすことでx1とx2の分布はおおむねシミュレーションと同じ値になっている。
多重共線性の対処法
データ量を増やす
追加情報を使う(β1+β2=1)
おまじない(民間療法)
説明変数を減らす
x1, x2の相関が高い場合、x1 - x2, x2を変数にする
階差を取る
データ数を減らす
データ数を300から3000,0000に増やし、実験3と同様のシミュレーションを1000回行った
> summary(para)
Intercept x1 x2 x3
Min. : 999.9 Min. : 99.84 Min. :79.85 Min. :59.95
1st Qu.:1000.0 1st Qu.: 99.97 1st Qu.:79.97 1st Qu.:59.99
Median :1000.0 Median :100.00 Median :80.00 Median :60.00
Mean :1000.0 Mean :100.00 Mean :80.00 Mean :60.00
3rd Qu.:1000.0 3rd Qu.:100.03 3rd Qu.:80.03 3rd Qu.:60.01
Max. :1000.1 Max. :100.16 Max. :80.16 Max. :60.05
x1とx2の回帰係数の分布には相関が見られるものの、データを増やすことでx1とx2の分布はおおむねシミュレーションと同じ値になっている。
多重共線性の話 〜その3 一般的な問題点 [データサイエンス、統計モデル]
実験3: 実験2のデータを1000回発生させ、回帰分析を行う
x1とx2の回帰係数に強い負の相関がある(x1, x2が正の相関であるため)
x1とx2の平均は、おおむね正しい結果となっている
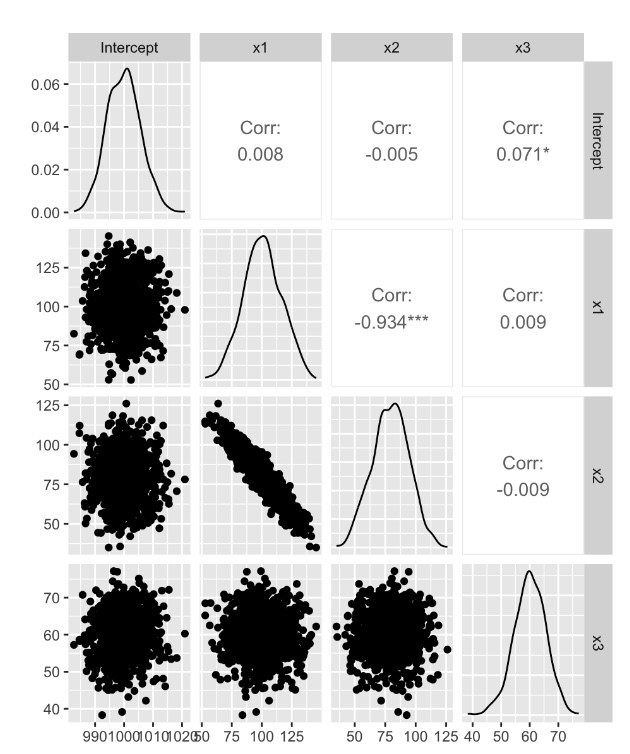
x1とx2の回帰係数に強い負の相関がある(x1, x2が正の相関であるため)
x1とx2の平均は、おおむね正しい結果となっている
多重共線性の話 〜その2 一般的な問題点 [データサイエンス、統計モデル]
回帰係数は、シミュレーション結果と異なるが、予測結果は問題ない。
多重共線性が起こっているx1, x2において、係数の標準誤差が大きくなっている(t値が小さくなる)ことが確認できる。
x1とx2間に強い線形の関係が見られる。
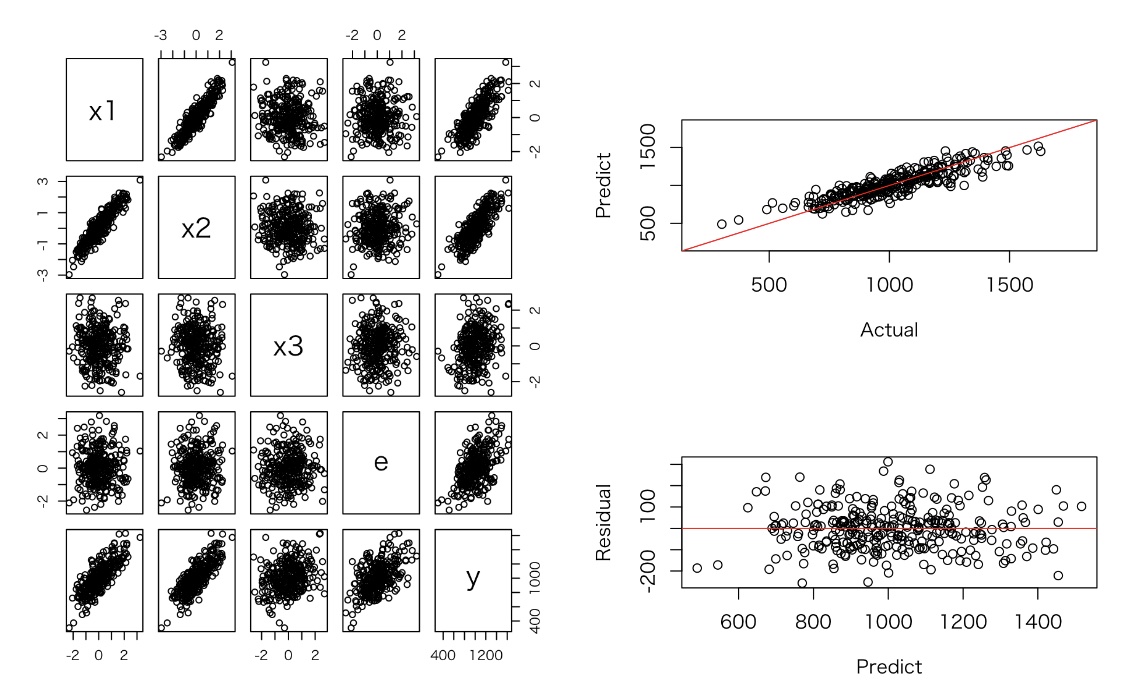
x1, x2, x3のいくつかの変数を使ったモデルを作成し、R2やAICの比較を行った。
多重共線性が起こっているx1, x2において、係数の標準誤差が大きくなっている(t値が小さくなる)ことが確認できる。
x1とx2間に強い線形の関係が見られる。
x1, x2, x3のいくつかの変数を使ったモデルを作成し、R2やAICの比較を行った。
> vif(res_123)
x1 x2 x3
6.453802 6.462609 1.003874
> vif(res_12)
x1 x2
6.450832 6.450832
> vif(res_13)
x1 x3
1.002045 1.002045
> vif(res_23)
x2 x3
1.003412 1.003412

