多重共線性の話 〜その4 一般的な問題点 [データサイエンス、統計モデル]
実験4: 実験2のデータ数を増やし、実験3と同様のシミュレーションを行う
多重共線性の対処法
データ量を増やす
追加情報を使う(β1+β2=1)
おまじない(民間療法)
説明変数を減らす
x1, x2の相関が高い場合、x1 - x2, x2を変数にする
階差を取る
データ数を減らす
データ数を300から3000,0000に増やし、実験3と同様のシミュレーションを1000回行った
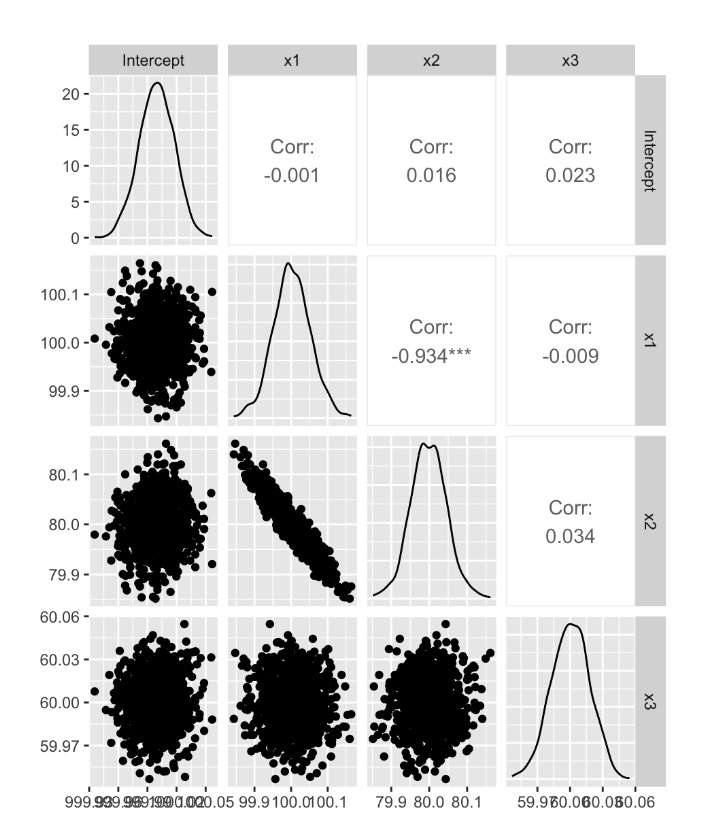
x1とx2の回帰係数の分布には相関が見られるものの、データを増やすことでx1とx2の分布はおおむねシミュレーションと同じ値になっている。
多重共線性の対処法
データ量を増やす
追加情報を使う(β1+β2=1)
おまじない(民間療法)
説明変数を減らす
x1, x2の相関が高い場合、x1 - x2, x2を変数にする
階差を取る
データ数を減らす
データ数を300から3000,0000に増やし、実験3と同様のシミュレーションを1000回行った
> summary(para)
Intercept x1 x2 x3
Min. : 999.9 Min. : 99.84 Min. :79.85 Min. :59.95
1st Qu.:1000.0 1st Qu.: 99.97 1st Qu.:79.97 1st Qu.:59.99
Median :1000.0 Median :100.00 Median :80.00 Median :60.00
Mean :1000.0 Mean :100.00 Mean :80.00 Mean :60.00
3rd Qu.:1000.0 3rd Qu.:100.03 3rd Qu.:80.03 3rd Qu.:60.01
Max. :1000.1 Max. :100.16 Max. :80.16 Max. :60.05
x1とx2の回帰係数の分布には相関が見られるものの、データを増やすことでx1とx2の分布はおおむねシミュレーションと同じ値になっている。


コメント 0