確率的グラフィカルモデルの産業界への応用 [ベイジアンネット]
久々に日吉まで行きましたが、学生がいっぱいいてうらやましい感じがしました。w
ベイジアンネットの紹介から実際に使われている事例などの紹介でした。
会場は満員でみんな関心が高いトピックなんでしょうかね。
実際に使ってみたい事例などもあり、良いヒントを得ることができました♪
BAYONET:条件付き確率(CPT) の計算方法の違い [ベイジアンネット]
BAYONETでベイジアンネットワークを構築していたときの備忘録。
目的変数が2つあり、それぞれが条件付きの構造を持っているため、それを上手く表現できないか?と考えました。
変数A 変数B 件数
1 1 10
1 0 100
0 1 0
0 0 1000
という構造だったと仮定します。
つまり、変数Bが1の場合、必ず変数Aは1になる構造となっています。
A -> B というモデルを作り、Bの証拠状態を1に設定します。
B = 1の時、変数Aが1になる確率は、10 / 10 で1.0になるはずですが、得られる結果は、0.9083となります。
この原因は、条件付き確率(CPT) の計算方法による違いとのこと。
計算方法 1: MAP
MAP は正規化を行う際にサンプル数に1を加算します。
変数A 変数B 件数
1 1 10+1=11
1 0 100+1=101
0 1 0+1=1
0 0 1000+1=1001
計算方法 2: ML
MLは、得られたクロス集計表を真としてそのまま計算します。
MAPとMLの違いですが、データ数が多くなれば、MAPはMLに違づいていきます。
しかし、データ数が少ない場合、仮に
変数C 件数
1 2
0 0
であった場合、MLで計算すると、Cは必ず1を取るという状態になってしまいます。
これをMAPで計算すると、
変数C 件数
1 2+1
0 0+1
となり、C=1の確率は、3/4=0.75という状態になります。
データが少ない場合はMAPで計算し、データが多くなればMLでも良いということなんでしょう。
これらを閾値で自動的に判断するAUTOというオプションもあるようです。
ここで、注意として、各セルを+1するってことは、各変数が取りうる値は、それぞれ同じ確率で発生するという事前分布を仮定しています。
事前情報が何も分からないところからの初期値としては、なんとなく正しい気もしますが、今回のように絶対に発生しないケースにおいても、確率が1.0にならないので注意が必要ですね。

- 作者: 田中和之
- 出版社/メーカー: コロナ社
- 発売日: 2009/10/13
- メディア: 単行本(ソフトカバー)
ベイジアンネットワーク BAYONETをインストール [ベイジアンネット]
http://www.msi.co.jp/bayonet/
昨年に行われたセミナーでの講演がきっかけです。
さて、軽く触った時点で感じたこと。
データ読み込みで、データベースからとテキストファイルからが選択できますが、テキストファイルだと、csv形式しか読み込めない。。。
せめて、タブ形式も読み込めるようになって欲しいものであるが…
さて、300メガ弱のファイルを読み込んで、モデリングをしようとしたら、いきなりメモリが足りません的なエラーが出てきた。
C:\【インストールフォルダ】\BAYONET\bin\
bayonet.l4j.ini
↑
ここに最大メモリとかの設定があるみたい。
初期値は、
-Xmx1024m
とあるので、1ギガに設定されています。
とりあえず、4ギガくらいに設定してみたら、普通に読み込めました。
次は、サラッとモデルを作ってみようかと思います。

- 作者: 涌井 良幸
- 出版社/メーカー: ナツメ社
- 発売日: 2012/02/21
- メディア: 単行本
ベイジアンネットを使って経験値や感性をモデル化 [ベイジアンネット]
実際のデータはないのだが、経験などを元に感覚的に変数と変数の重みを理解している場合が多い。
それらの感覚値を元にした分布をたくさん発生させて、それをモデル化しようというモノ。
シミュレーションに近い感じかもしれない。
やり方としては、
1. 頭の中にある感性を取りだす。(ヒヤリングで)
2. その重みに従った分布で乱数を発生させる。
今回は、IBM SPSS Clementine(PASW Modeler)を使って乱数を発生せました。
3. あらかじめモデル化できているので、モデル化。
今回は、数理システムさんのBayonetを使用しました。
モデル化した後は、○○部分を変化させ、△△部分にどこにどれくらいの影響を与えることができるのかを分析することができます。
ベイジアンネットワークでモデル化すると、こういったシミュレーションもできるので素敵です。
今回の取り組みで面白いなぁと思った点は、データがまったくなくても、頭の中にある知見を構造化できた点です。
もっと詳細に精度高くするんだったら、ここにアンケートとかをくっつけてみると良いでしょう。

- 作者: 繁桝 算男
- 出版社/メーカー: 培風館
- 発売日: 2006/07
- メディア: 単行本

ベイジアンネットワーク技術 ユーザ・顧客のモデル化と不確実性推論
- 作者: 本村 陽一
- 出版社/メーカー: 東京電機大学出版局
- 発売日: 2006/07/20
- メディア: 単行本
BayoNet 紹介セミナー [ベイジアンネット]
ベイジアンネット(BayoNet)に興味がある人が多いのか、けっこうな人数がいました。
話の流れとしては、
・ベイジアンネットとは?
・ベイジアンネット構築
・マーケティングへの応用
・製品紹介
の4本立てで、合計3時間の講義です。
自分自身、けっこう使っている方だと思うので、内容的にはちょっと物足りない気もしましたが、初心者や初めての方にとっては、逆にボリュームモリモリの充実した内容だったのでは?と思います。
数理システムさんて、こういう無料紹介セミナーをやってくれるので、助かります。
SPSSだと、お金取りそうなないようだけど。w
個人的に興味深かったのは、
分岐経路、線形経路、合流経路の違い。
基本的にベイジアンネットで矢印の向きは関係ありませんが、証拠状態が決まったときに、条件付独立になるとか、条件付従属になるのかって部分は、モデルを作る段階で意識をしておかないとダメですね。。。
また、Space Shuttle Autolanderというデータを使ってのモデル構築では、データの数が少ない場合の注意点なども紹介されていました。
マーケティングへの応用では、芳賀先生のアイスクリームアンケートを使った事例紹介などもあり、最後まで楽しかったです。
新しいバージョンの方も開発中らしく、こちらの方も楽しみです。

ベイジアンネットワーク技術 ユーザ・顧客のモデル化と不確実性推論
- 作者: 本村 陽一
- 出版社/メーカー: 東京電機大学出版局
- 発売日: 2006/07/20
- メディア: 単行本
- 作者: 繁桝 算男
- 出版社/メーカー: 培風館
- 発売日: 2006/07
- メディア: 単行本
モンティ・ホール問題 [ベイジアンネット]
モンティ・ホール問題
最近、ベイジアンネットワークなるものがにわかに流行っている。
グループ会で、勉強会をすることになったのだが、ベイジアンネットワークの前にベイズの定理を調べてると、色々と面白い問題を見つけた。
例題 その1
アメリカのクイズ番組の例( モンティ・ホール問題 )
今、三つの宝箱があったとする。
![]()
宝は、三つのうち、一つだけ入っている。
司会者のモンティは、どの宝箱に宝が入っているか知っている。
ここで、プレイヤーが第一の選択をした後、モンティは他の二つの宝のうち一つをあけ、宝がからっぽであることをみせる。

司会者のモンティはプレイヤーに、初めの選択のままでよいか、もう一つの箱に変更するか、再選択させる。

ここで問題。
プレイヤーは、選択を変更すべきだろうか?
あるいは、そのままが良いのだろうか?
回答は三つに分かれるのではないだろうか。
1. 変えても変えなくても同じ
2. 変えたほうが良い
3. 変えないほうが良い
もし、あなたがこのテレビ番組に出たら、どの選択をしますか???(・∀・)
ベイジアンネットワークの概説・技術・応用 [ベイジアンネット]
ベイジアンネットワークの概説・技術・応用
http://www.ebrain-j.com/cgi-bin/seminar/seminar_detail.cgi?id=20070823-0024&date=200708
受講料が1名56,700円(受講料54,000円、消費税2,700円)と少々高いが、、、
行ってきました。
内容は、

- 作者: 繁桝 算男, 本村 陽一, 植野 真臣
- 出版社/メーカー: 培風館
- 発売日: 2006/07
- メディア: 単行本
を詳しく解説するないようになっています。
この本、誤字とかが多く、気になっていたんですが、やはり、誤字でした。
これは誤字だろうと思っていても、本当だろうか?って思っていました。
順番は、午前中に繁桝先生、午後から植野先生、本村先生という順番。
特に、本村先生はよりユーザーに近い内容だったので、応用しやすい内容だったと思います。
繁桝先生、植野先生は、数学に近く、果たして受講者の何人が理解できたんだろうか?
俺は、大学の時にベイズをやっていたので、復習っぽかったが、初めてベイズに触れた人は、かなり苦しいものがあったのではと思う。
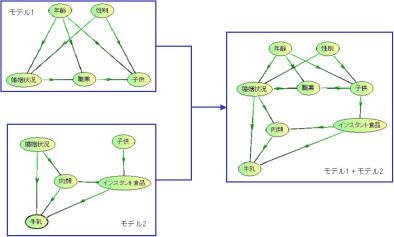
二つのモデルの統合 その2 [ベイジアンネット]
二つのモデルの統合 その2
二つのモデルを一つのプロジェクト上に読み込む方法
ただし一方のファイルはBIF形式でエクスポートしておく必要がある。
【準備】
プロパティダイアログの
bayonet→misc→tabs
の設定画面でprojectの値をTrueに設定し、BayoNetを再起動。
グラフ属性パネルにProjectタブが表示される。
【手順】
二つのモデルm1.xmlの上にm2.bifを読み込む。
1)通常通りm1.xmlを読み込む。
2)Projectタブの下方にある[UpdateProject]ボタンをクリックする。
3)表示されたダイアログでm2.bifを指定する。
【その他】
以上の操作でモデルm1とm2が同じプロジェクト上に表示される。
ただし、両方のモデルに同じ変数名がある場合にはm2で上書きされる。
また、BIF形式にはデータとの関連付け情報が無いため、モデルm2に対するCPT更新はできない。
CPT更新が必要な場合にはDSTの設定が必要になる。
その際は【準備】と同様の手順でDSTタブを表示するように設定。
二つのモデルの統合 その1 [ベイジアンネット]
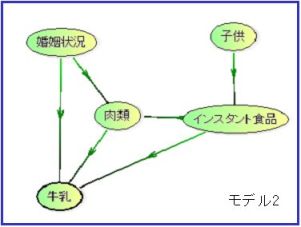
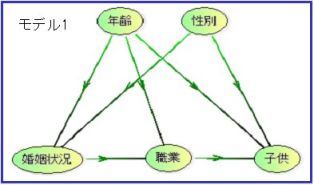
ベイジアンネットで作成した二つのモデルを統合したい場合がある。
変数として、
年齢、性別、
婚姻状況、職業、子供、
牛乳、肉類、インスタント食品
の計8変数を考える。
1レコードに全変数があれば、一度でモデルを作成することができるのだが、
データ1
年齢、性別、
婚姻状況、職業、子供、
データ2
婚姻状況、職業、子供、
牛乳、肉類、インスタント食品
の二つに分かれていると考える。
二つのデータは、IDをキーとしたものがない。
しかし、
婚姻状況、職業、子供、
の3変数の状態をキーとして結合できそうである。
具体的な手順は、明日。
(*´ェ`*)
ベイジアンネットの確率伝播について [ベイジアンネット]
確率がどのように伝播しているのかをシミュレーションしました。
図1のようなモデルを考えます。
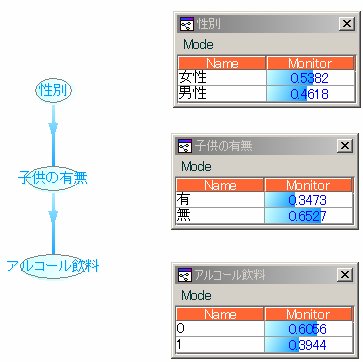
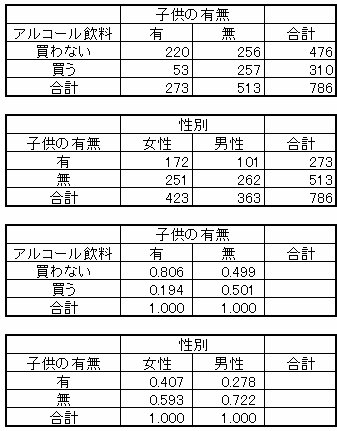
ここで、N = 10,000人と仮定します。
子供の有無
有:4,066人
無:5,934人
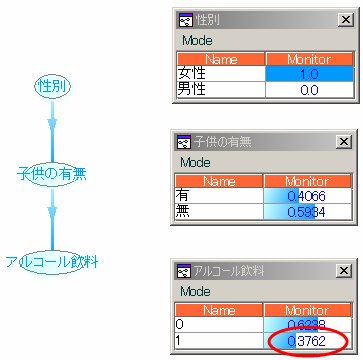
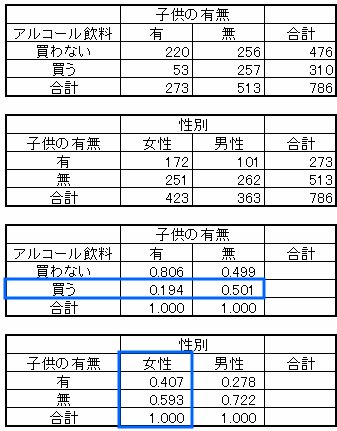
子供の有無
有&買う:4,066人×0.194 = 788.8
無&買う:5,934人×0.501 = 2,972.9
計 3761.7人
上記の様な場合とは、、、
何かのアンケートを使いモデルを作成したとします。
しかし、新しいデータでは、子供の有無の情報がなかったとします。
子供の有無のデータは解りませんが、その分布はすでに解っています。
この様な場合、確率伝播/シミュレーションが威力を発します。
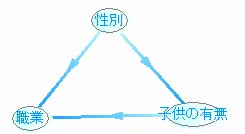
3つのノードを使ったベイジアンネット [ベイジアンネット]
下記のようなベイジアンネットを考えたとします。
パターン1
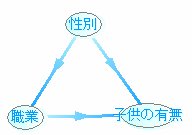
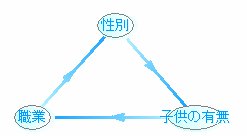
パターン2
パターン3
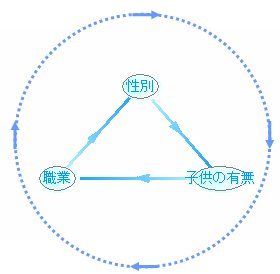
パターン4
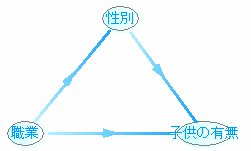
この中でシミュレーションができないのが1つあります。
それは、パターン3です。
よくみるとネットワークが循環してしまっています。
パターン3
ここで、性別, 子供の有無, 職業の各事前分布は
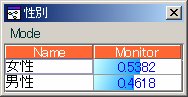
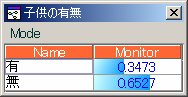
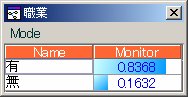
となっています。
ここで、性別と子供の有無の証拠状態が決まると
各パターンで職業の事後確率がどのように変化するのか
計算を行いました。
この結果は、[性別-子供の有無]と[職業]のクロス表
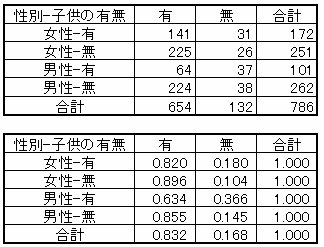
と同じになります。
これは、確率的に同じネットワークに変換できるからです。
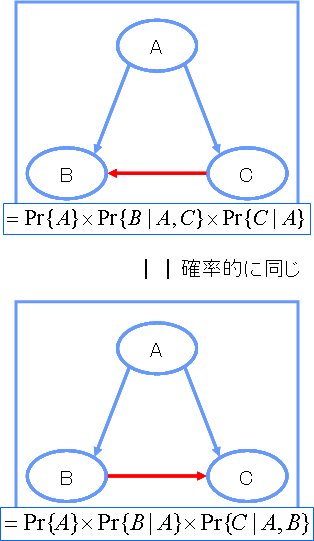
ベイジアンネットを使いこなす [ベイジアンネット]
Bayonet(ベイヨネット)は、ポテンシャルは高いツールだと思いますが、
正直、使い勝手は、かなり悪い…
そこで、BayonetとClementine組み合わせて分析をすることにしました。
今、下記のようなベイジアンネットを考えたとします。
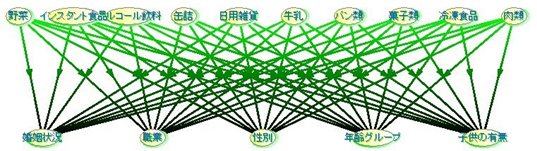
例えば、牛乳やパン類を購入する人は、どういうタイプの人なのかをシミュレーションします。

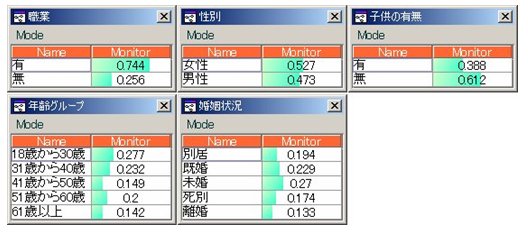
上記状態は、何も証拠状態がない状態。
つまり、事前分布を表しています。
ここで、牛乳とパン類を購入する人という証拠状態を決定します。

1回限りのシミュレーションだと、これで問題ないのですが、
全組み合わせのシミュレーションを行う機能はついていません!(号泣
今回の場合、バスケットにいれる種類は10種類あります。
その時の状態は、
・バスケットに入れる
・バスケットに入れない
・バスケットに入れるか入れないか決定しない
の3状態。
つまり、
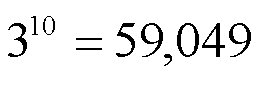
回、チクチクとシミュレーションをする必要があります。
状態をしぼって、
・バスケットに入れる
・バスケットに入れるか入れないか決定しない
の2状態にしても、
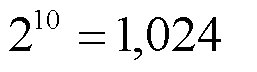
回のシミュレーションが必要になってきます。○| ̄|_
数理システムに聞いてみたところ、
・確率推論の API を TCP/IP 経由で実行するプログラムを作成
・Propagationを全パターン実行する
しかないと・・・(;∀;)
しかも、saveされたデータが
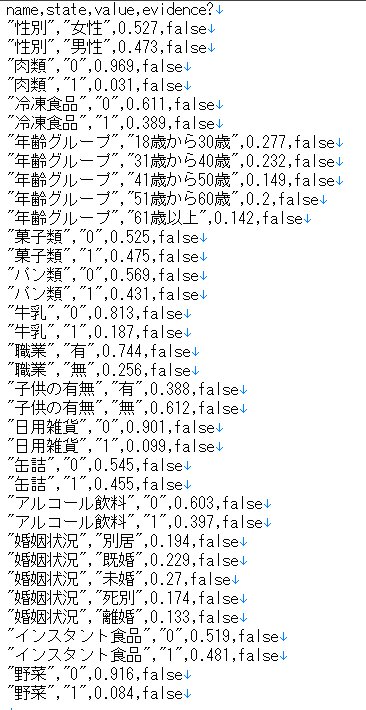
というデータになっており、このままでは、分析ができません・・・
なかなか痒いところに手が届かないツールになっています。
そこで、Clementine君を使って、

のようなデータ形式に変換するストリームを作成しました。
(・∀・)!
Bayonet君もせめて、上記のような形にファイルを作成してもらえるとありがたいのですがネ♪
PS
Bayonetでお困りの方がいれば、変換するストリームを差し上げます。
ご連絡ください。
決定木とベイジアンネット(Bayesian networks) [ベイジアンネット]
有名な?アヤメ(Iris)のデータを使って決定木とベイジアンネットの精度を比較しました。
他のデータを使ったりオプションを変えたりするともちろん異なる結果が出ると思いますので、そのあたりはご参考にしてください。
まずは、Clementine 9.0の新アルゴリズムCHAIDを使いました。
モデル作成用データでモデルを作成し、検証用データで精度を確かめます。
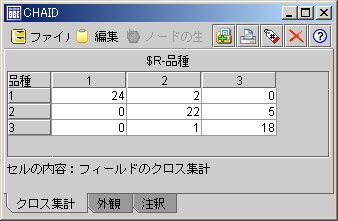
検証用データの72レコード中、64レコードが正解です。
64 / 72 = 88.8(%)
同じようなことをBayonetを使って行いました。
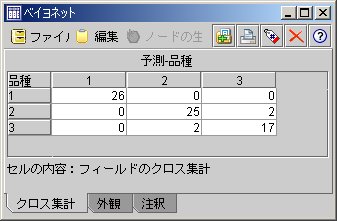
検証用データの72レコード中、68レコードが正解です。
68 / 72 = 94.4(%)
今回のデータでは、ベイジアンネットの方がよく当たっていました。
最初に、書いたようにデータやモデル構築のオプションで精度は変わるので
一概にどっちが精度が良いとかってのは、言えません。
ここで、ベイジアンネットのシミュレーションのよさを考えたいと思います。
下記の様に
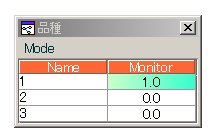
自信を持って、1だと断言している場合と、
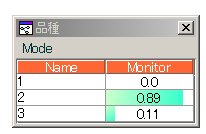
の様に0.89くらいは2で、0.11くらいは3であるといってくる場合があります。
そこで、それぞれ、どれくらいの精度なのか検証用データに当てはめました。
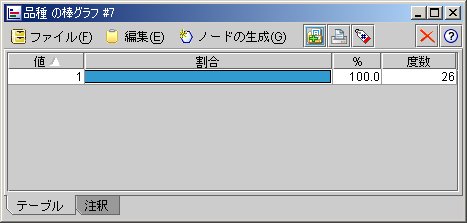
上記の場合、検証用データでも100%、【1】でした
下記の場合、検証用データに当てはめてみると
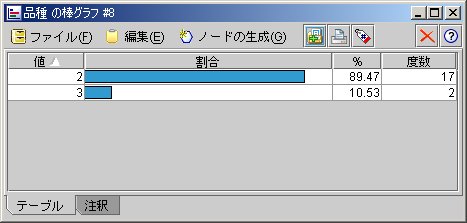
というように、89.47%は【2】で10.53%は【3】となっています!!!
つまり、ベイジアンネットの確率の分布とぴったり一致しているわけですね。
ベイジアンネットは確率の世界です。
【買う/買わない】の予測だけではなく、どれくらいの割合【買う/買わない】ということをシミュレーションすることができます。
ベイジアンネットの魅力 [ベイジアンネット]
ベイジアンネットとは、いくつかの説明変数どうしの関係を確率で考え、依存関係(?)に近いものを視覚的に考えることができます。
ベイジアンネットのソフトウェアはいくつかあります。
フリーのものから、商用ソフトウェアまで。
ISFIでは、数理システムのBayoNetを使ってます。
http://www.msi.co.jp/BAYONET/index.html
ベイジアンネットで一番の魅力は、シミュレーション機能です。
統計解析やデータマイニング手法を用いてモデルを作成したモデルを実際のマーケティングで活用するためには、数理モデルを使ってモデルを最適化したり、シミュレーションする必要が出てきます。
ベイジアンネットは、モデリング機能とシミュレーション機能がついてますので、モデリングからシミュレーションまでシームレスに分析できます。
☆ベイジアンネットのデモ事例☆
太蔵くんは、東京ディズーランドの雑誌を買うために本屋へ行きました。

お店に、「雑誌A」と「雑誌B」が置いてありました。
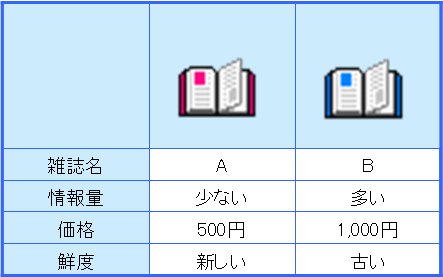
太蔵くんは、どちらを買おうか悩んでいます。

ベイジアンネットを使って、「雑誌A」と「雑誌B」の
選択確率を算出します。
ここで、説明変数として
・情報量
・鮮度
・価格
などが考えられます。
さらには、店舗の場所、規模など、いくつかの条件を元に、「雑誌A」と「雑誌B」の購入確率をシミュレーションすることができるわけです。
これ以外にも、アクセスログ解析やテキストマイニングとベイジアンネットを融合させることで、面白い分析ができるかと思います。

