ドコモとタカラトミー、玩具でプログラミング教育 [ファミリー]
e-Craftシリーズ embot(エムボット)
https://www.embot.jp/
少し前に登場した「embot」を段ボールを使って作り直しました的なものですかね?
Nintendo Switchもダンボールで作る『Nintendo Labo』というのが出たけど、どうなんだろう。
ものすごく流行っている感じがしない。。。
ダンボールって原価がすごく安い感じがするので、それと実売価格との乖離がある気がします。
実際は、思って以上にコストがかかっているのかもしれないけど、人間の頭の中にある心理的な価格「内的参照価格」を反映させた販売価格になっていると良いんですけどね。。。
だったら、ダンボールではなく、もう少し高級感がある仕上がりにした方が売れる気がしますが・・・w
https://www.embot.jp/
少し前に登場した「embot」を段ボールを使って作り直しました的なものですかね?
Nintendo Switchもダンボールで作る『Nintendo Labo』というのが出たけど、どうなんだろう。
ものすごく流行っている感じがしない。。。
ダンボールって原価がすごく安い感じがするので、それと実売価格との乖離がある気がします。
実際は、思って以上にコストがかかっているのかもしれないけど、人間の頭の中にある心理的な価格「内的参照価格」を反映させた販売価格になっていると良いんですけどね。。。
だったら、ダンボールではなく、もう少し高級感がある仕上がりにした方が売れる気がしますが・・・w
菅官房長官が笑顔で食べるニューオータニ「3千円パンケーキ」 [時事 / ニュース]
パンケーキに3000円って庶民感覚からズレているとか、いろいろ批判があるようですが、個人的には、別にそれくらい良いんじゃないか?って思います。
毎日食べているわけじゃないだろうし・・・。
それに、官房長官クラスが、ファミレスでパンケーキ食べている姿も逆にどうかと思います。。。

いずれにしろ、そんな報道を吹き飛ばすくらい菅官房長官が笑顔で食べるニューオータニ「3千円パンケーキ」。
気になるところです。w
毎日食べているわけじゃないだろうし・・・。
それに、官房長官クラスが、ファミレスでパンケーキ食べている姿も逆にどうかと思います。。。
いずれにしろ、そんな報道を吹き飛ばすくらい菅官房長官が笑顔で食べるニューオータニ「3千円パンケーキ」。
気になるところです。w
第116回 職団戦 (将棋大会) [将棋]
第116回大会結果一覧(2019年11月3日)
職団戦|将棋大会|日本将棋連盟
https://www.shogi.or.jp/tournament/job_group/
場所は、立川にある立飛アリーナで行われました。
立川からモノレールで一駅なのですが、思った以上に遠いです。。。

第115回大会でEクラスに出場したのですが、決勝で「トリプルアイズ(2)」に負けてしまい準優勝。
今回は、Dクラスに出場しました。
そして、前回同様、決勝まで勝ち上がり対戦はあの「トリプルアイズ(2)」です。
結果は、「リクルートホールディングス」が3-2で勝利し、今回は勝つことが出来ました。
おそらく、Cクラスに上がっても、また戦うことになると思います。
改めて将棋を勉強して強くならないとな、、、と思った今日この頃です。
職団戦|将棋大会|日本将棋連盟
https://www.shogi.or.jp/tournament/job_group/
場所は、立川にある立飛アリーナで行われました。
立川からモノレールで一駅なのですが、思った以上に遠いです。。。
第115回大会でEクラスに出場したのですが、決勝で「トリプルアイズ(2)」に負けてしまい準優勝。
今回は、Dクラスに出場しました。
そして、前回同様、決勝まで勝ち上がり対戦はあの「トリプルアイズ(2)」です。
結果は、「リクルートホールディングス」が3-2で勝利し、今回は勝つことが出来ました。
おそらく、Cクラスに上がっても、また戦うことになると思います。
改めて将棋を勉強して強くならないとな、、、と思った今日この頃です。
若洲公園のなが~いサイクリングコース [ファミリー]
若洲公園のなが~いサイクリングコース
サイクリング&貸自転車|若洲海浜公園&江東区立若洲公園|海上公園なび
http://www.tptc.co.jp/park/03_09/cycling
若洲公園でサイクリングをしていきました。
タンデム(2人乗り):(1時間)300円
普通自転車 小人(中学生以下):(1時間)50円
風力発電を1週するだけだったら短いのですが、海を見ながらゴルフ場を通り、展望台まで行って戻るコースがあります。
かなり真剣に自転車をこいでちょうど1時間くらい。
途中でゆっくり休憩したら1時間を超えます。w
普段電動自転車乗っていることもあり、多少のアップダウンがあるタンデム(2人乗り)はきつかったです。
膝がガクガクしました。
夏だったら熱中症になるレベルですが、ちょうどこの季節なので気持ちいい運動ができたかなと思います。


サイクリング&貸自転車|若洲海浜公園&江東区立若洲公園|海上公園なび
http://www.tptc.co.jp/park/03_09/cycling
若洲公園でサイクリングをしていきました。
タンデム(2人乗り):(1時間)300円
普通自転車 小人(中学生以下):(1時間)50円
風力発電を1週するだけだったら短いのですが、海を見ながらゴルフ場を通り、展望台まで行って戻るコースがあります。
かなり真剣に自転車をこいでちょうど1時間くらい。
途中でゆっくり休憩したら1時間を超えます。w
普段電動自転車乗っていることもあり、多少のアップダウンがあるタンデム(2人乗り)はきつかったです。
膝がガクガクしました。
夏だったら熱中症になるレベルですが、ちょうどこの季節なので気持ちいい運動ができたかなと思います。
「不偏分散による標準偏差」と「不偏標準偏差」の違い [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
「不偏分散による標準偏差」と「不偏標準偏差」は同じものですか?
【回答】
母分散 σ2 の平方根は、母標準偏差 σ 。
ここで、不偏分散を U2 として、「不偏分散による標準偏差(不偏分散の平方根)」 U は、なんとなく母標準偏差 σ の不偏推定量になっている気がするのですが、実は、不偏推定量にはなっていない。
このあたりの事を詳しくまとめているサイトがありました。
https://atarimae.biz/archives/8276
https://ja.wikipedia.org/wiki/%E6%A8%99%E6%BA%96%E5%81%8F%E5%B7%AE
https://en.wikipedia.org/wiki/Unbiased_estimation_of_standard_deviation
↑
不偏分散 U2 の平方根を不偏標準偏差だと教える大学の先生も多いようです。
この辺りは、感覚的に同じ不偏推定量になっていると錯覚してしまうことが原因だと思います。
不偏分散の値を s2 とします。
s2は、母分散 σ2 の不偏推定量であるので
E(s2) = σ2・・・①
となっています。
(証明は略)
「不偏分散による標準偏差」sが、母標準偏差 σの不偏推定量というのは、
E(s) = σ・・・②
であることなのですが、これは数学的には間違い
①から両辺平方根を取って②が導出できるという錯覚に陥りがちなのですが、①の平方根は、
√(E(s2)) であり、(E(√s2))=E(s)ではないので、①が正しいからと言って、②が成り立つとは言えません。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
「不偏分散による標準偏差」と「不偏標準偏差」は同じものですか?
【回答】
母分散 σ2 の平方根は、母標準偏差 σ 。
ここで、不偏分散を U2 として、「不偏分散による標準偏差(不偏分散の平方根)」 U は、なんとなく母標準偏差 σ の不偏推定量になっている気がするのですが、実は、不偏推定量にはなっていない。
このあたりの事を詳しくまとめているサイトがありました。
https://atarimae.biz/archives/8276
https://ja.wikipedia.org/wiki/%E6%A8%99%E6%BA%96%E5%81%8F%E5%B7%AE
https://en.wikipedia.org/wiki/Unbiased_estimation_of_standard_deviation
↑
不偏分散 U2 の平方根を不偏標準偏差だと教える大学の先生も多いようです。
この辺りは、感覚的に同じ不偏推定量になっていると錯覚してしまうことが原因だと思います。
不偏分散の値を s2 とします。
s2は、母分散 σ2 の不偏推定量であるので
E(s2) = σ2・・・①
となっています。
(証明は略)
「不偏分散による標準偏差」sが、母標準偏差 σの不偏推定量というのは、
E(s) = σ・・・②
であることなのですが、これは数学的には間違い
①から両辺平方根を取って②が導出できるという錯覚に陥りがちなのですが、①の平方根は、
√(E(s2)) であり、(E(√s2))=E(s)ではないので、①が正しいからと言って、②が成り立つとは言えません。
統計数理研究所 樋口前所長退任記念シンポジウム [データサイエンス、統計モデル]
統計数理研究所 樋口前所長退任記念シンポジウム
https://ism75sympo.peatix.com/
こちらに行ってきました。
それぞれの著名な先生の発表を聞くことができました。
持ち時間が少ないのと、樋口先生との思い出話も講演の中でそれなりに入っているので、統数研ならではの難しい内容ではなかったです。
これまで樋口先生の講演を何度か聞きましたが、難しい理論もその本質を分かりやすい言葉で説明されているなという印象です。
最近、なかなか研究出来ていませんが、改めて自分も研究しなきゃな、、、という気持ちになりました。
https://ism75sympo.peatix.com/
こちらに行ってきました。
それぞれの著名な先生の発表を聞くことができました。
持ち時間が少ないのと、樋口先生との思い出話も講演の中でそれなりに入っているので、統数研ならではの難しい内容ではなかったです。
これまで樋口先生の講演を何度か聞きましたが、難しい理論もその本質を分かりやすい言葉で説明されているなという印象です。
最近、なかなか研究出来ていませんが、改めて自分も研究しなきゃな、、、という気持ちになりました。
トヨタ、若手出張「エコノミー」に変更 「好待遇」是正へ労組に提案 [時事 / ニュース]
ビジネスクラスとエコノミークラスの間に、プレミアムエコノミーというクラスもあったりします。
ビジネスがダメなら、せめてプレエコくらいは良いんじゃないか?と思ったりします。
正直、アジア路線など、短時間のフライトならエコノミーで問題ないと思いますが、エコノミークラスで10時間以上のフライトをすると体に負担がかかり、着いた瞬間からバリバリ働くのはちょっと厳しい。
原点に戻って、何のために海外出張に行くのか?
最近では、リモートの会議の品質もあがっており、あえて海外に行かなくても良い環境ってそろってきています。
それでも、それなりの旅費やホテル代を払って海外に行くには、それなりの利点が求められるわけで、それに比べるとビジネス(or プレエコ)とエコノミーの旅費の差分って高々しれているのではないでしょうか。
むしろ、ビジネス(or プレエコ)にすることで、機内でも快適に仕事ができますし、着いてからの仕事の質も断然大きい。
ただ、こういうものって直接的に利益に換算することは難しく、会社としては目に見えるわかりやすいコスト削減に走りたくなるのもうなずけます。
まぁ、出張に行く方も出張費用の意識をしっかり持って、きちんとした成果を出していきたいものです。
なんとなく必要そうだからとか、とりあえず海外出張してみるか、という意識の人が多くなると、会社としても「エコノミーで!」ということになるかもしれませんね。
ビジネスがダメなら、せめてプレエコくらいは良いんじゃないか?と思ったりします。
正直、アジア路線など、短時間のフライトならエコノミーで問題ないと思いますが、エコノミークラスで10時間以上のフライトをすると体に負担がかかり、着いた瞬間からバリバリ働くのはちょっと厳しい。
原点に戻って、何のために海外出張に行くのか?
最近では、リモートの会議の品質もあがっており、あえて海外に行かなくても良い環境ってそろってきています。
それでも、それなりの旅費やホテル代を払って海外に行くには、それなりの利点が求められるわけで、それに比べるとビジネス(or プレエコ)とエコノミーの旅費の差分って高々しれているのではないでしょうか。
むしろ、ビジネス(or プレエコ)にすることで、機内でも快適に仕事ができますし、着いてからの仕事の質も断然大きい。
ただ、こういうものって直接的に利益に換算することは難しく、会社としては目に見えるわかりやすいコスト削減に走りたくなるのもうなずけます。
まぁ、出張に行く方も出張費用の意識をしっかり持って、きちんとした成果を出していきたいものです。
なんとなく必要そうだからとか、とりあえず海外出張してみるか、という意識の人が多くなると、会社としても「エコノミーで!」ということになるかもしれませんね。
双子用ベビーカーの女性、市営バスが乗車拒否か 名古屋 [時事 / ニュース]
定期的に出てくるベビーカー問題。
昔に比べて巨大化していたり、そもそも双子用なので、大きいのは仕方ない。
普通のサイズのベビーカーで公共機関に乗っても文句を言う輩がいるので、なおさら二人乗りとなると炎上するのもわかる気がします。
混雑している時間をずらせ、とか、タクシー利用しろといった声も多くあるのですが、
・どうしてもその時間に移動しなければならない。
・タクシーばっかり利用しているとお金がかかって仕方がない。
といった理由もあるわけです。
そもそも、あなたたちの将来の年金を払ってくれるという感謝の気持ちを忘れて、大切な子供を暖かく見守れないのはただの老害。
ベビーカーを利用するほうもジャイアンのように当然の権利として乗るのではなく、それなりのマナーは必要ですが、それなりに子供を連れての移動って大変なんですよね。。。
話を戻して、双子用ベビーカーの問題は今後もっと出てくると思います。
事前にバス会社に連絡しておけばよかったのか?その場合、どういうサポートが受けられるのか等々、双子ベビーカーで移動する必要がある場合の連絡先など公共機関でもっと告知していく必要がありそうです。
今後は、不妊治療が増えて双子ベイビーは増えくると思います。
こういうニュースが流れてくると、将来子供を欲しいと思う気持ちがなくなっていかないですかね。
そして、巡り巡って自分たちに跳ね返ってくることになります。
昔に比べて巨大化していたり、そもそも双子用なので、大きいのは仕方ない。
普通のサイズのベビーカーで公共機関に乗っても文句を言う輩がいるので、なおさら二人乗りとなると炎上するのもわかる気がします。
混雑している時間をずらせ、とか、タクシー利用しろといった声も多くあるのですが、
・どうしてもその時間に移動しなければならない。
・タクシーばっかり利用しているとお金がかかって仕方がない。
といった理由もあるわけです。
そもそも、あなたたちの将来の年金を払ってくれるという感謝の気持ちを忘れて、大切な子供を暖かく見守れないのはただの老害。
ベビーカーを利用するほうもジャイアンのように当然の権利として乗るのではなく、それなりのマナーは必要ですが、それなりに子供を連れての移動って大変なんですよね。。。
話を戻して、双子用ベビーカーの問題は今後もっと出てくると思います。
事前にバス会社に連絡しておけばよかったのか?その場合、どういうサポートが受けられるのか等々、双子ベビーカーで移動する必要がある場合の連絡先など公共機関でもっと告知していく必要がありそうです。
今後は、不妊治療が増えて双子ベイビーは増えくると思います。
こういうニュースが流れてくると、将来子供を欲しいと思う気持ちがなくなっていかないですかね。
そして、巡り巡って自分たちに跳ね返ってくることになります。
「東京ガス : がすてなーに」がリニューアルオープン [ファミリー]
東京ガス : がすてなーに
https://www.gas-kagakukan.com/
しばらく改装工事をしていた「がすてなーに」ですが、リニューアルしました。
屋上にある芝生は、子供たちの宝物。
ゴロゴロしたり、海や夕焼けを見たり。

https://www.gas-kagakukan.com/
しばらく改装工事をしていた「がすてなーに」ですが、リニューアルしました。
屋上にある芝生は、子供たちの宝物。
ゴロゴロしたり、海や夕焼けを見たり。
牛角ビュッフェ 市川コルトンプラザ店 [グルメ / クッキング]
牛角の焼肉ビッフェというのがあります。
牛角の食べ放題のお店。
東京都内には少ないのですが、千葉方面にはちらほらあって、日帰りのスーパー銭湯に寄ってから牛角ビッフェを利用しました。
本当は、焼肉からの温泉が良いのですが、お腹のすき具合と相談して、先にお風呂にしました。。。
市川コルトンプラザ(ニッケコルトンプラザ)は、初めて利用しましたが、映画館が入っていたり、ショッピングモールが入っていたり、また、レストランもなかなか魅力的なレストランが多かったです。
今回は、「牛角ビュッフェ」がメインだったので、ゆっくりモールの中を見れなかったけど、今度じっくり散策してみたいです。
キッズエリアも充実していますね♪
https://www.nikke-purekids.jp/attraction/ichikawa.html
牛角の食べ放題のお店。
東京都内には少ないのですが、千葉方面にはちらほらあって、日帰りのスーパー銭湯に寄ってから牛角ビッフェを利用しました。
本当は、焼肉からの温泉が良いのですが、お腹のすき具合と相談して、先にお風呂にしました。。。
市川コルトンプラザ(ニッケコルトンプラザ)は、初めて利用しましたが、映画館が入っていたり、ショッピングモールが入っていたり、また、レストランもなかなか魅力的なレストランが多かったです。
今回は、「牛角ビュッフェ」がメインだったので、ゆっくりモールの中を見れなかったけど、今度じっくり散策してみたいです。
キッズエリアも充実していますね♪
https://www.nikke-purekids.jp/attraction/ichikawa.html
イマドコサーチ(NTTドコモ)の設定でのトラブル解消 [ファミリー]
子供がどこにいるか把握できるイマドコサーチというものがあります。
子供がどこにいるかキッズケータイのGPSを使って、親ケータイから検索できるというサービス。
登録してすぐに使えるかと思ったら、意外と時間がかかりました。
【親ケータイの設定】
イマドコサーチのアプリをインストールします。
そこから契約しているキッズケータイの電話番号を登録しておきます。
【キッズケータイの設定】
意外と忘れがちなのが、キッズケータイ側の設定。
検索される側も検索する方の電話番号の登録が必要でした。
また、デフォルト設定だと、検索したタイミングでキッズケータイのバイブが振動してしまって、今、検索中ということが伝わってしまいます。
検索していることをキッズケータイ側に知られたくない場合は、バイブ設定をオフにしておくことで、検索中をオフにすることができます。
【その他のエラー原因】
それでもイマドコサーチが出来な場合あります。
実は今回はこれが原因でした。
それは・・・
親ケータイで登録しているキッズケータイの電話番号が間違えていた!
自分の家族以外の電話番号も登録できるみたいです。
もちろん、相手側が承認しない限りは検索できないのですが、間違って、相手側が承認してしまった場合は、赤の他人の居場所をサーチするということもできそうです。。。
なかなか怖い話だったりします。
子供がどこにいるかキッズケータイのGPSを使って、親ケータイから検索できるというサービス。
登録してすぐに使えるかと思ったら、意外と時間がかかりました。
【親ケータイの設定】
イマドコサーチのアプリをインストールします。
そこから契約しているキッズケータイの電話番号を登録しておきます。
【キッズケータイの設定】
意外と忘れがちなのが、キッズケータイ側の設定。
検索される側も検索する方の電話番号の登録が必要でした。
また、デフォルト設定だと、検索したタイミングでキッズケータイのバイブが振動してしまって、今、検索中ということが伝わってしまいます。
検索していることをキッズケータイ側に知られたくない場合は、バイブ設定をオフにしておくことで、検索中をオフにすることができます。
【その他のエラー原因】
それでもイマドコサーチが出来な場合あります。
実は今回はこれが原因でした。
それは・・・
親ケータイで登録しているキッズケータイの電話番号が間違えていた!
自分の家族以外の電話番号も登録できるみたいです。
もちろん、相手側が承認しない限りは検索できないのですが、間違って、相手側が承認してしまった場合は、赤の他人の居場所をサーチするということもできそうです。。。
なかなか怖い話だったりします。
アップリフトモデルを作るコツと注意点1 アップリフトモデルとは? [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
最近、着目されているアップリフトモデルとは?
企業側がクーポンなりポイントなりをカスタマ(消費者)に付与して、カスタマの購買意欲を上げようという施策を考えたとします。
【パターン1】
購買意欲高い人にクーポンをあげてしまったらどうなるか?
もともと、買おうと思っていたところ、割引クーポンもらったのでカスタマの心理としては、ラッキー♪と思うでしょう。
企業側としては、クーポンが無駄になるので、単なるコスト増になります。
【パターン2】
購買意欲が低い人(かつ、クーポンの感度が低い人)にクーポンをあげてしまったらどうなるか?
この人はクーポンをもらってももらわなくても、もともと購買意欲が低いので、スパムメールとなります。
【パターン3】
購買意欲が低い人(かつ、クーポンの感度が高い人)にクーポンをあげてしまったらどうなるか?
もともと、買うつもりは低かったけど、せっかくクーポンもらったので、購買しようかな!と思い買ってくれたとしたら、企業側としては良い広告の投資となります。
企業側が狙いたいのは、パターン3の人なのですが、こういう人をどうやって見つけるか?というのは、やってみるとかなり難しいことが分かります。
難しいという理由ですが、なんとなく出来そうでそれっぽい答えが出てくるのですが、実際に何が起こっているかを見てみると、失敗しているということがよくあります。
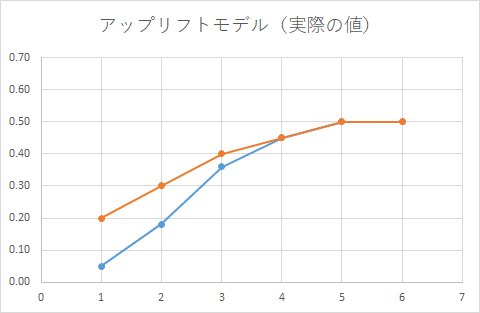
今、添付のような広告効果があったとします。
オレンジ色が広告をもらった時の効果。
青色が広告をもらわなかった時の効果。
横軸(x軸)は、なんらかの変数(セグメント)で、xが増えれば購買意欲が増えていきます。
もう一度、アップリフトモデルでやりたいことを整理すると、広告をもらったときともらわなかったときの差分をきちんと測定したい。
上記のグラフからわかることは、
x=1の人に広告を打つと、効果高い
x=2, x=3とxが増えるにしたがって効果は低くなる
x=4, 5, 6の人は広告の効果はなし
となっています。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
最近、着目されているアップリフトモデルとは?
企業側がクーポンなりポイントなりをカスタマ(消費者)に付与して、カスタマの購買意欲を上げようという施策を考えたとします。
【パターン1】
購買意欲高い人にクーポンをあげてしまったらどうなるか?
もともと、買おうと思っていたところ、割引クーポンもらったのでカスタマの心理としては、ラッキー♪と思うでしょう。
企業側としては、クーポンが無駄になるので、単なるコスト増になります。
【パターン2】
購買意欲が低い人(かつ、クーポンの感度が低い人)にクーポンをあげてしまったらどうなるか?
この人はクーポンをもらってももらわなくても、もともと購買意欲が低いので、スパムメールとなります。
【パターン3】
購買意欲が低い人(かつ、クーポンの感度が高い人)にクーポンをあげてしまったらどうなるか?
もともと、買うつもりは低かったけど、せっかくクーポンもらったので、購買しようかな!と思い買ってくれたとしたら、企業側としては良い広告の投資となります。
企業側が狙いたいのは、パターン3の人なのですが、こういう人をどうやって見つけるか?というのは、やってみるとかなり難しいことが分かります。
難しいという理由ですが、なんとなく出来そうでそれっぽい答えが出てくるのですが、実際に何が起こっているかを見てみると、失敗しているということがよくあります。
今、添付のような広告効果があったとします。
オレンジ色が広告をもらった時の効果。
青色が広告をもらわなかった時の効果。
横軸(x軸)は、なんらかの変数(セグメント)で、xが増えれば購買意欲が増えていきます。
もう一度、アップリフトモデルでやりたいことを整理すると、広告をもらったときともらわなかったときの差分をきちんと測定したい。
上記のグラフからわかることは、
x=1の人に広告を打つと、効果高い
x=2, x=3とxが増えるにしたがって効果は低くなる
x=4, 5, 6の人は広告の効果はなし
となっています。
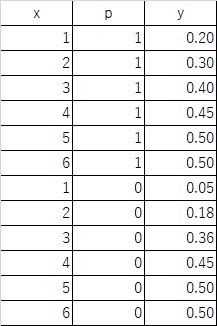
## 母集団の作成
set.seed(1234)
# ターゲットグループの設定
df_1t <- data.frame(y=rbinom(1000, 1, 0.20), x=1, p=1)
df_2t <- data.frame(y=rbinom(1000, 1, 0.30), x=2, p=1)
df_3t <- data.frame(y=rbinom(1000, 1, 0.40), x=3, p=1)
df_4t <- data.frame(y=rbinom(1000, 1, 0.45), x=4, p=1)
df_5t <- data.frame(y=rbinom(1000, 1, 0.50), x=5, p=1)
df_6t <- data.frame(y=rbinom(1000, 1, 0.50), x=6, p=1)
# コントロールグループの設定
df_1c <- data.frame(y=rbinom(1000, 1, 0.05), x=1, p=0)
df_2c <- data.frame(y=rbinom(1000, 1, 0.18), x=2, p=0)
df_3c <- data.frame(y=rbinom(1000, 1, 0.36), x=3, p=0)
df_4c <- data.frame(y=rbinom(1000, 1, 0.45), x=4, p=0)
df_5c <- data.frame(y=rbinom(1000, 1, 0.50), x=5, p=0)
df_6c <- data.frame(y=rbinom(1000, 1, 0.50), x=6, p=0)
# データの作成
df <- rbind(df_1t, df_2t, df_3t, df_4t, df_5t, df_6t
, df_1c, df_2c, df_3c, df_4c, df_5c, df_6c)
with(subset(df, p==1), by(y, INDICES=x, FUN=mean))
with(subset(df, p==0), by(y, INDICES=x, FUN=mean))
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
これから複数回にわたり、失敗例を紹介していきます。
まずは、簡単に思いつく方法から。
広告の効果を特徴量に入れて、ロジスティック回帰モデルを作てみたらどうだろうか?
具体的な数式はこうなります。
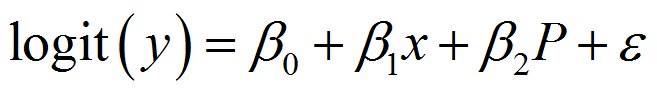
広告(クーポンの効果)を変数に入れているので、クーポンをもらったときともらわなかった時の差分を計算することが出来そうです。
具体的な差分の方法としては、こうなります。
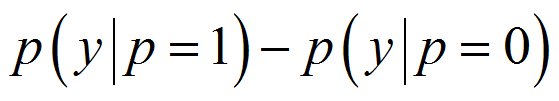
作成したロジスティック回帰モデルに、P=1(クーポン付与)とP=0(クーポン非付与)の値を入れます。
P=1は、クーポンをもらった時の状態
P=0は、クーポンをもらっていない時の状態
なんだか上手くいきそうな気がしますが、感度分析(実際にどのように予測しているか)をしてみると、下記になります。
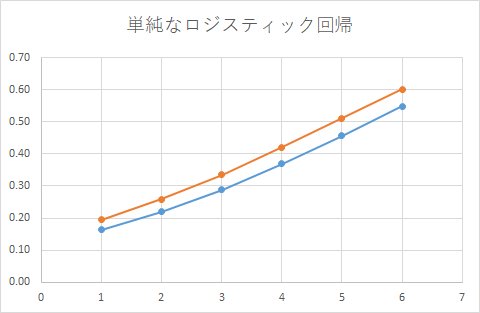
正しいモデルは、こうでした。
随分と間違えたモデルになっています。
その理由を知るために、どういうモデルを作ったのか?を考えると
広告の効果は、一律にβ2 * P で表現してしまっているところにあります。
もともとのアップリフトモデルの思想としては、人によって広告の感度が違う。
その人の異質性(クーポン感度の違い)をモデル化したい、でした。
しかし、実際に作っているモデル(ロジットモデル)は、全員同じパラメータβ3で表現してしまっています。
ということで、シンプルなロジスティック回帰モデルを作成するだけでは、人ごとの広告の効果を正しく測定することはできません。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
これから複数回にわたり、失敗例を紹介していきます。
まずは、簡単に思いつく方法から。
広告の効果を特徴量に入れて、ロジスティック回帰モデルを作てみたらどうだろうか?
具体的な数式はこうなります。
広告(クーポンの効果)を変数に入れているので、クーポンをもらったときともらわなかった時の差分を計算することが出来そうです。
# モデルの作成(シンプルなロジスティック回帰)
fit.1 <- glm(y~x+p, family = binomial, data = df)
df.fit.1 <- data.frame(df, response=predict(fit.1, type="response"))
with(subset(df.fit.1, p==1), by(response, INDICES=x, FUN=mean))
with(subset(df.fit.1, p==0), by(response, INDICES=x, FUN=mean))
具体的な差分の方法としては、こうなります。
作成したロジスティック回帰モデルに、P=1(クーポン付与)とP=0(クーポン非付与)の値を入れます。
P=1は、クーポンをもらった時の状態
P=0は、クーポンをもらっていない時の状態
なんだか上手くいきそうな気がしますが、感度分析(実際にどのように予測しているか)をしてみると、下記になります。
正しいモデルは、こうでした。
随分と間違えたモデルになっています。
その理由を知るために、どういうモデルを作ったのか?を考えると
広告の効果は、一律にβ2 * P で表現してしまっているところにあります。
もともとのアップリフトモデルの思想としては、人によって広告の感度が違う。
その人の異質性(クーポン感度の違い)をモデル化したい、でした。
しかし、実際に作っているモデル(ロジットモデル)は、全員同じパラメータβ3で表現してしまっています。
ということで、シンプルなロジスティック回帰モデルを作成するだけでは、人ごとの広告の効果を正しく測定することはできません。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
これから複数回にわたり、失敗例を紹介していきます。

↑
こちらの本の9章に『Uplift Modelingによるマーケティング資源の効率化』という章があります。
その9.4章 2つの予測モデルを利用したUplift Modelingをみると、ターゲティング群とコントロール群でロジスティック回帰モデルを作成し、その差分(比率)をみることで効果を測定できるという考えです。
コントロール(C)、ターゲティング群(T)として
C:低&T:低 ⇒ 無関心
C:低&T:高 ⇒ 説得可能(クーポン付与対象者)
C:高&T:低 ⇒ 天邪鬼(???)
C:高&T:高 ⇒ 鉄板(クーポンコストが無駄)
クーポンもらわないと購買意欲高いのに、もらったら購買意欲が下がるような天邪鬼っているのだろうか?
コントロールとターゲティングのマトリックスで考えると、そういう可能性も考えられるわけですが、ビジネス感覚(マーケティングの感覚)として、ホンマか???と思ってしまいます。
まぁ、この方法に沿ってモデルを作成すると、そういう天邪鬼となってしまう群が出てくることも確かです。
結論から書けば、ちょっとした予測モデルのさじ加減で、クーポンをもらった方が購買確率が下がる人が出てきてしまう。
しかし、本当に購買意欲が下がるのかといえば、それは間違い。
単に予測モデルの作り方が間違えているだけ、というのが結論です。
実際に、二つのモデルを作るやり方をしてみると…
2つのロジスティック回帰モデルを作成するやり方
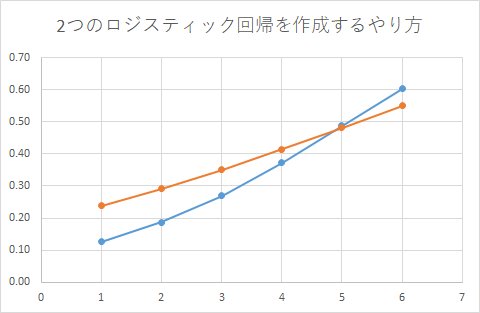
確かに、x=6の付近では、ターゲティンググループの方が購買確率が高くなっていますね。
天邪鬼なのでしょうか?
正しい集計結果は、こうでした。
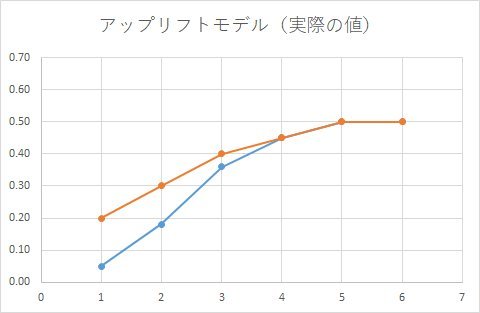
前回の「単純なロジスティック回帰を使う失敗例」と同様に随分と間違えたモデルになっています。
なぜ、このような結果になってしまったのか、問題点を整理します。
下のグラフが実際のデータ。
オレンジ色と青色を独立に最尤推定しています。
そこで推定されたモデルはそれぞれのデータでフィットするようになっているので、ある変数で見た時に、その値(βの係数)がターゲティンググループの方が必ず大きくなる!というような制約をいれているわけではないです。
なので、たまたま逆転してしまう個所が出てくるのは当然。
変数の数が増えてくるとこういう個所がどんどん出てきます。
では、逆転しているのは、係数による微妙なところだから、差はなし(0と置換)として良いのでしょうか?
予測モデルを、特定の部分(x=6)だけ0にしてしまうのも良くないです。
都合が悪い部分を、恣意的にいじってしまうとなぜ悪いか?
勝手に値を置換してしまうと、クーポンのコストを予測する時に問題が出てきます。
実際のyの平均値は、こうなっています。
> mean(subset(df, p==1)$y)
[1] 0.3875
> mean(subset(df, p==0)$y)
[1] 0.341
コントロール群の期待確率の平均は、0.341
ターゲティング群の期待確率の平均は、0.3875
つまり、1000円のクーポンをターゲティング群に付与すると平均で387.5円のクーポンのコストが発生することを意味しています。
予測モデル自体は微妙な統計モデルになっていますが、それでも予測モデルの期待確率の平均を計算すると、
[予測モデルの]コントロール群の期待確率の平均は、0.341
[予測モデルの]ターゲティング群の期待確率の平均は、0.3875
となっており、全体の平均値は正しいです。
しかし、天邪鬼のセグメントの予測値が都合が悪いからといって、0置換してしまうと、その部分の確率がゆがめられてしまい、コストの計算もゆがめられたもの担ってしまいます。
企業は、クーポンなどを配布する際にそれをマーケティングコストとして扱い、その予算を管理しています。
今回のマーケティング施策では、○○円のコストを使うという精度の高い予測が必要ですが、そのコスト予測がおかしなことになってしまう問題点があります。
ということで、「2つの予測モデルを利用したUplift Modeling」をまとめると、
・2つの予測モデルを別々に作ってしまうと本来はいないはずの天邪鬼セグメントが発生してしまう
・天邪鬼の確率(コントロールの方が確率が高いセグメント)を恣意的に置換するのは、コストを予測するという点においてベースライン(平均値)において誤差が生じる
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
これから複数回にわたり、失敗例を紹介していきます。
- 作者: 有賀 康顕
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/01/16
- メディア: 単行本(ソフトカバー)
↑
こちらの本の9章に『Uplift Modelingによるマーケティング資源の効率化』という章があります。
その9.4章 2つの予測モデルを利用したUplift Modelingをみると、ターゲティング群とコントロール群でロジスティック回帰モデルを作成し、その差分(比率)をみることで効果を測定できるという考えです。
コントロール(C)、ターゲティング群(T)として
C:低&T:低 ⇒ 無関心
C:低&T:高 ⇒ 説得可能(クーポン付与対象者)
C:高&T:低 ⇒ 天邪鬼(???)
C:高&T:高 ⇒ 鉄板(クーポンコストが無駄)
クーポンもらわないと購買意欲高いのに、もらったら購買意欲が下がるような天邪鬼っているのだろうか?
コントロールとターゲティングのマトリックスで考えると、そういう可能性も考えられるわけですが、ビジネス感覚(マーケティングの感覚)として、ホンマか???と思ってしまいます。
まぁ、この方法に沿ってモデルを作成すると、そういう天邪鬼となってしまう群が出てくることも確かです。
結論から書けば、ちょっとした予測モデルのさじ加減で、クーポンをもらった方が購買確率が下がる人が出てきてしまう。
しかし、本当に購買意欲が下がるのかといえば、それは間違い。
単に予測モデルの作り方が間違えているだけ、というのが結論です。
実際に、二つのモデルを作るやり方をしてみると…
# モデルの作成(シンプルなロジスティック回帰を2つ作る)
# データの作成
df_t <- rbind(df_1t, df_2t, df_3t, df_4t, df_5t, df_6t)
df_c <- rbind(df_1c, df_2c, df_3c, df_4c, df_5c, df_6c)
fit.2t <- glm(y~x, family = binomial, data = df_t)
fit.2c <- glm(y~x, family = binomial, data = df_c)
df.fit.2t <- data.frame(df_t, response=predict(fit.2t, type="response"))
df.fit.2c <- data.frame(df_c, response=predict(fit.2c, type="response"))
with(df.fit.2t, by(response, INDICES=x, FUN=mean))
with(df.fit.2c, by(response, INDICES=x, FUN=mean))
2つのロジスティック回帰モデルを作成するやり方
確かに、x=6の付近では、ターゲティンググループの方が購買確率が高くなっていますね。
天邪鬼なのでしょうか?
正しい集計結果は、こうでした。
前回の「単純なロジスティック回帰を使う失敗例」と同様に随分と間違えたモデルになっています。
なぜ、このような結果になってしまったのか、問題点を整理します。
下のグラフが実際のデータ。
オレンジ色と青色を独立に最尤推定しています。
そこで推定されたモデルはそれぞれのデータでフィットするようになっているので、ある変数で見た時に、その値(βの係数)がターゲティンググループの方が必ず大きくなる!というような制約をいれているわけではないです。
なので、たまたま逆転してしまう個所が出てくるのは当然。
変数の数が増えてくるとこういう個所がどんどん出てきます。
では、逆転しているのは、係数による微妙なところだから、差はなし(0と置換)として良いのでしょうか?
予測モデルを、特定の部分(x=6)だけ0にしてしまうのも良くないです。
都合が悪い部分を、恣意的にいじってしまうとなぜ悪いか?
勝手に値を置換してしまうと、クーポンのコストを予測する時に問題が出てきます。
実際のyの平均値は、こうなっています。
> mean(subset(df, p==1)$y)
[1] 0.3875
> mean(subset(df, p==0)$y)
[1] 0.341
コントロール群の期待確率の平均は、0.341
ターゲティング群の期待確率の平均は、0.3875
つまり、1000円のクーポンをターゲティング群に付与すると平均で387.5円のクーポンのコストが発生することを意味しています。
予測モデル自体は微妙な統計モデルになっていますが、それでも予測モデルの期待確率の平均を計算すると、
[予測モデルの]コントロール群の期待確率の平均は、0.341
[予測モデルの]ターゲティング群の期待確率の平均は、0.3875
となっており、全体の平均値は正しいです。
しかし、天邪鬼のセグメントの予測値が都合が悪いからといって、0置換してしまうと、その部分の確率がゆがめられてしまい、コストの計算もゆがめられたもの担ってしまいます。
企業は、クーポンなどを配布する際にそれをマーケティングコストとして扱い、その予算を管理しています。
今回のマーケティング施策では、○○円のコストを使うという精度の高い予測が必要ですが、そのコスト予測がおかしなことになってしまう問題点があります。
ということで、「2つの予測モデルを利用したUplift Modeling」をまとめると、
・2つの予測モデルを別々に作ってしまうと本来はいないはずの天邪鬼セグメントが発生してしまう
・天邪鬼の確率(コントロールの方が確率が高いセグメント)を恣意的に置換するのは、コストを予測するという点においてベースライン(平均値)において誤差が生じる
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
これから複数回にわたり、失敗例を紹介していきます。
前回は、「2つの予測モデルを使う失敗例」を書きました。
別々にモデルを作るのがダメだったら、交互作用項を含むモデルを作れば良いんじゃないか?という発想になります。
交互作用項を含むロジスティック回帰とは、説明変数の中に交互作用項を加えたロジスティック回帰のことです。
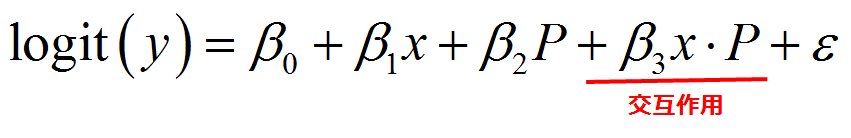
交互作用項を含むロジスティック回帰
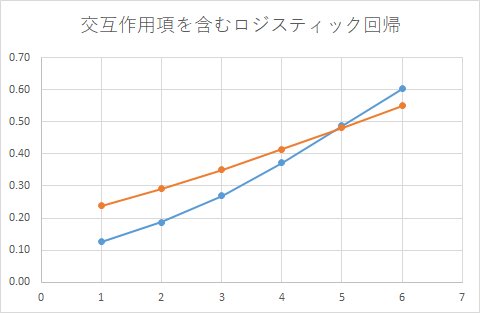
2つのロジスティック回帰モデルを作成するやり方
この結果を見ると、2つの予測モデルを使う場合と全く同じグラフになっていることが分かります。
尤度関数を書ける方は、実際に書いてみると証明できるのですが、交互作用項を含むロジスティック回帰を展開すると、2つの予測モデルを別々に作る場合と一致することが確認できるかと思います。
【2つの予測モデル(ロジスティック回帰)】
[ターゲティング群]
Coefficients:
Estimate
(Intercept) -1.43897 A
x 0.27338 B
[コントロール群]
Coefficients:
Estimate
(Intercept) -2.41547 C
x 0.47310 D
【交互作用項を含むロジスティック回帰】
Coefficients:
Estimate
(Intercept) -2.41547 E
x 0.47310 F
p 0.97650 G
x:p -0.19971 H
⇒ ターゲティング群のパラメータの計算方法
A = E + G
B = F + H
⇒ ターゲティング群のパラメータの計算方法
C = E
D = F
となり、二つのグラフが一致することが確認できました。
これまでいろいろな工夫を考えたアプローチの例を紹介しました。
一見、頭の中では上手くいきそう!と思っても、やってみると意外と難しいことが分かったかと思います。
ロジスティック回帰(統計モデル)のアプローチが上手く行かないのであれば、SVMや決定木といった機械学習系のアプローチはどうか?といった発想になるかと思います。
次回から、いくつかの機械学習系のアプローチを考えていきます。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
これから複数回にわたり、失敗例を紹介していきます。
前回は、「2つの予測モデルを使う失敗例」を書きました。
別々にモデルを作るのがダメだったら、交互作用項を含むモデルを作れば良いんじゃないか?という発想になります。
交互作用項を含むロジスティック回帰とは、説明変数の中に交互作用項を加えたロジスティック回帰のことです。
# モデルの作成(交互作用ありのロジスティック回帰)
fit.3 <- glm(y~x+p+x:p, family = binomial, data = df)
df.fit.3 <- data.frame(df, response=predict(fit.3, type="response"))
with(subset(df.fit.3, p==1), by(response, INDICES=x, FUN=mean))
with(subset(df.fit.3, p==0), by(response, INDICES=x, FUN=mean))
交互作用項を含むロジスティック回帰
2つのロジスティック回帰モデルを作成するやり方
この結果を見ると、2つの予測モデルを使う場合と全く同じグラフになっていることが分かります。
尤度関数を書ける方は、実際に書いてみると証明できるのですが、交互作用項を含むロジスティック回帰を展開すると、2つの予測モデルを別々に作る場合と一致することが確認できるかと思います。
【2つの予測モデル(ロジスティック回帰)】
[ターゲティング群]
Coefficients:
Estimate
(Intercept) -1.43897 A
x 0.27338 B
[コントロール群]
Coefficients:
Estimate
(Intercept) -2.41547 C
x 0.47310 D
【交互作用項を含むロジスティック回帰】
Coefficients:
Estimate
(Intercept) -2.41547 E
x 0.47310 F
p 0.97650 G
x:p -0.19971 H
⇒ ターゲティング群のパラメータの計算方法
A = E + G
B = F + H
⇒ ターゲティング群のパラメータの計算方法
C = E
D = F
となり、二つのグラフが一致することが確認できました。
これまでいろいろな工夫を考えたアプローチの例を紹介しました。
一見、頭の中では上手くいきそう!と思っても、やってみると意外と難しいことが分かったかと思います。
ロジスティック回帰(統計モデル)のアプローチが上手く行かないのであれば、SVMや決定木といった機械学習系のアプローチはどうか?といった発想になるかと思います。
次回から、いくつかの機械学習系のアプローチを考えていきます。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
前回までは、ロジスティック回帰を使う場合、どのようにモデルを予測していて、実際はどうなっているか、の乖離を見てきました。
これから、複数回にわたり機械学習モデルを見ていきます。
まずは、サポートベクターマシン(英: support vector machine, SVM)から。
正しい集計結果は、こうでした。
SVMは、カーネルタイプによってどのように判別するか変わってきます。
線形、RBF、多項式、Sigmoidがあります。
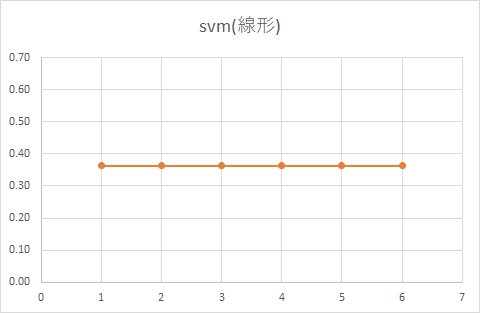
■ 線形
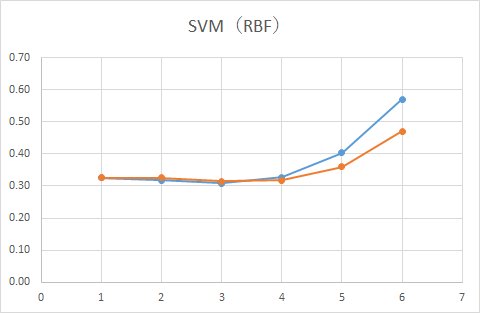
■ RBF
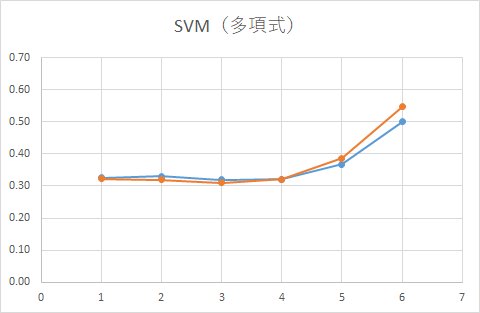
■ 多項式
■ Sigmoid
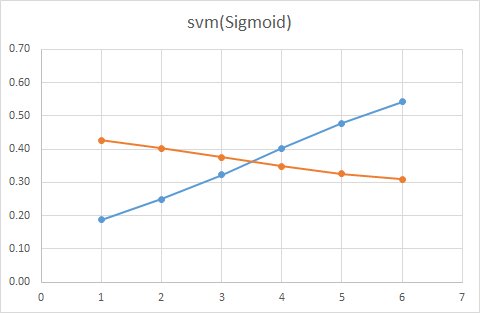
SVMでは「マージン最大化」という方法で線を引きます。
境界からもっとも近いベクトルとの距離を計算することで、パラメータを推定する速度が速いのが特徴なのですが、一方で、統計モデルなどと違い判別する境界以外に存在するデータの密度はみていません。
データが密集している部分はそれなりに離れているけど、
境界部分の距離が近いような場合ですと上手く予測できないのが欠点です。
例えば、SVM(線形)を見てみると、データ量が多い場合は、クーポンをもらった人ももらわなかった人も同じ確率であることが分かります。
試しに、12000人のサンプルサイズから10%だけサンプルした1200人でモデルを作った場合どうなるか見てみます。
データが発生するパラメータは同じですが、データ量が少なくなっているため、境界部分近くのデータも減少し、境界がはっきりするためどこも同じ確率といった金太郎飴状態は解消されるはずです。
■ 線形(利用するデータをランダムに10%だけ抽出)
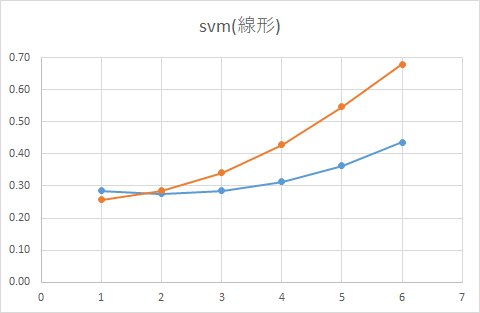
実際に予測した結果がこちら。
確かにクーポンをもらった人ともらわなかった人の確率は異なりますが、実際の集計結果とは程遠い結果になってしまっています。
また、統計的には、データ数をワザと減らすアプローチは正しいアプローチとは言えません。
信頼区間が拡大し、精度が低下するからです。
いずれにしろ、サポートベクターマシン(英: support vector machine, SVM)で作成したアップリフトモデルは、実際の値をずいぶんかけ離れた予測値になっていることがわかりました。
もっとパラメータをチューニングすれば別の結果になっていくと思いますが、実際に運用することを考えると、SVMを使ってのアップリフトモデルの運用は厳しい気がします。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
前回までは、ロジスティック回帰を使う場合、どのようにモデルを予測していて、実際はどうなっているか、の乖離を見てきました。
これから、複数回にわたり機械学習モデルを見ていきます。
まずは、サポートベクターマシン(英: support vector machine, SVM)から。
正しい集計結果は、こうでした。
SVMは、カーネルタイプによってどのように判別するか変わってきます。
線形、RBF、多項式、Sigmoidがあります。
■ 線形
■ RBF
■ 多項式
■ Sigmoid
SVMでは「マージン最大化」という方法で線を引きます。
境界からもっとも近いベクトルとの距離を計算することで、パラメータを推定する速度が速いのが特徴なのですが、一方で、統計モデルなどと違い判別する境界以外に存在するデータの密度はみていません。
データが密集している部分はそれなりに離れているけど、
境界部分の距離が近いような場合ですと上手く予測できないのが欠点です。
例えば、SVM(線形)を見てみると、データ量が多い場合は、クーポンをもらった人ももらわなかった人も同じ確率であることが分かります。
試しに、12000人のサンプルサイズから10%だけサンプルした1200人でモデルを作った場合どうなるか見てみます。
データが発生するパラメータは同じですが、データ量が少なくなっているため、境界部分近くのデータも減少し、境界がはっきりするためどこも同じ確率といった金太郎飴状態は解消されるはずです。
■ 線形(利用するデータをランダムに10%だけ抽出)
実際に予測した結果がこちら。
確かにクーポンをもらった人ともらわなかった人の確率は異なりますが、実際の集計結果とは程遠い結果になってしまっています。
また、統計的には、データ数をワザと減らすアプローチは正しいアプローチとは言えません。
信頼区間が拡大し、精度が低下するからです。
いずれにしろ、サポートベクターマシン(英: support vector machine, SVM)で作成したアップリフトモデルは、実際の値をずいぶんかけ離れた予測値になっていることがわかりました。
もっとパラメータをチューニングすれば別の結果になっていくと思いますが、実際に運用することを考えると、SVMを使ってのアップリフトモデルの運用は厳しい気がします。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19

