里見女流5冠 奨励会三段リーグ戦 最後の挑戦 [将棋]
奨励会三段リーグが、10/21から始まっています。
プロになるための最終関門ですが、年齢制限があって、26歳までに突破する必要があります。
そして、今回がその最後のリーグ戦。
厳密には10勝8敗以上の成績を上げれば、29歳まで三段リーグに参加できるので、
勝ち越すことができれば、次回もチャンスはあります。
一方、西山朋佳(女性)も、三段リーグに参戦していて、現在2連勝。
順位も高順位なので、里見女流5冠よりも先に女性初のプロ誕生になるかもしれません。
プロになるための最終関門ですが、年齢制限があって、26歳までに突破する必要があります。
そして、今回がその最後のリーグ戦。
厳密には10勝8敗以上の成績を上げれば、29歳まで三段リーグに参加できるので、
勝ち越すことができれば、次回もチャンスはあります。
一方、西山朋佳(女性)も、三段リーグに参戦していて、現在2連勝。
順位も高順位なので、里見女流5冠よりも先に女性初のプロ誕生になるかもしれません。
公立中高一貫校受験説明会 [ファミリー]
まだまだ先の話ですが、塾が主催する「公立中高一貫校受験説明会」に行ってきました。
自分の時は、中学受験なんかしなかったし、そもそも東京に住んでいなかったので、受験事情というものが全く分かっておらず、「中学受験ってどんなものか?」という情報収集に近かったです。
まとめるとこんな感じでした
・私立受験と違って、基本は学校で勉強する範囲からの出題となる
・ただし、応用力が求められる問題が多く、地頭の良さが必要
・読み書きを正確に速く(基礎問題も重要)
・論理的な思考力、推理力が必要
倍率は、まじめに勉強している人が受験している中で5倍~7倍とかなり狭き門
なので、「不合格」=「失敗」でないという認識を持って、受験をする
実際に、過去問を解いてみましたが、個人的には良い問題が多い印象でした。
詰め込むだけでは解けない問題で、中学受験だけじゃなく、
受験勉強をしていく中で、その後の高校受験や大学受験の基礎体力が向上していくと感じました。
自分の時は、中学受験なんかしなかったし、そもそも東京に住んでいなかったので、受験事情というものが全く分かっておらず、「中学受験ってどんなものか?」という情報収集に近かったです。
まとめるとこんな感じでした
・私立受験と違って、基本は学校で勉強する範囲からの出題となる
・ただし、応用力が求められる問題が多く、地頭の良さが必要
・読み書きを正確に速く(基礎問題も重要)
・論理的な思考力、推理力が必要
倍率は、まじめに勉強している人が受験している中で5倍~7倍とかなり狭き門
なので、「不合格」=「失敗」でないという認識を持って、受験をする
実際に、過去問を解いてみましたが、個人的には良い問題が多い印象でした。
詰め込むだけでは解けない問題で、中学受験だけじゃなく、
受験勉強をしていく中で、その後の高校受験や大学受験の基礎体力が向上していくと感じました。
バレーの発表会 [ファミリー]
退院してすぐでしたが、バレーの発表会がありました。
前日にリハーサルがあり、咳も出ていなかったので参加することに。
ちゃんと覚えているかドキドキしながら見ていましたが、踊り切っていました。
前日にリハーサルがあり、咳も出ていなかったので参加することに。
ちゃんと覚えているかドキドキしながら見ていましたが、踊り切っていました。
俺のイタリアン TOKYO [グルメ / クッキング]
俺のイタリアン TOKYO
http://www.oreno.co.jp/restaurant/俺のイタリアンtokyo/
俺のイタリアン TOKYO - 銀座一丁目/イタリアン [食べログ]
https://tabelog.com/tokyo/A1301/A130101/13173949/
娘の誕生日パーティーで行ってきました。
入口が分かりづらいのですが、エスカレーターで地下1階に降ります。
(エレベータではつながっていません。)
隣が「俺のフレンチ」です。
入ってみると、割とざわざわしていて、子連れでも特に気を使うことなく食事ができました。
安くはないけど、美味しい料理をコストパフォーマンス良く食べることができます。
一人でも入れそうな雰囲気でした。
誕生日のデザートプレートを頼んだら、生演奏時に、「happy birthday to you」の歌を歌ってくれました。
娘はちょっと照れていましたが、また行きたいみたいで、楽しいお誕生日会になったようです。
http://www.oreno.co.jp/restaurant/俺のイタリアンtokyo/
俺のイタリアン TOKYO - 銀座一丁目/イタリアン [食べログ]
https://tabelog.com/tokyo/A1301/A130101/13173949/
娘の誕生日パーティーで行ってきました。
入口が分かりづらいのですが、エスカレーターで地下1階に降ります。
(エレベータではつながっていません。)
隣が「俺のフレンチ」です。
入ってみると、割とざわざわしていて、子連れでも特に気を使うことなく食事ができました。
安くはないけど、美味しい料理をコストパフォーマンス良く食べることができます。
一人でも入れそうな雰囲気でした。
誕生日のデザートプレートを頼んだら、生演奏時に、「happy birthday to you」の歌を歌ってくれました。
娘はちょっと照れていましたが、また行きたいみたいで、楽しいお誕生日会になったようです。
芋ほり 2017 [ファミリー]
幼稚園の芋ほりでしたが、ちょうど風邪をひいてしまい参加できませんでした。
娘は、「芋ほり」を楽しみにしていたので、マザー牧場の芋ほりに行くことにしました。
ほとんど掘られてしまっていて、端っこのエリアが少し残っていました。
4株(一区画)500円で参加できます。
軍手は100円で購入可能。
マザー牧場人いわく、2kgくらい出てくるよ~ってことでしたが、実際に掘ってみるとそうとう大きなお芋がたくさん出てきました。
家に持って帰って測ってみると4.8kgありました!



娘は、「芋ほり」を楽しみにしていたので、マザー牧場の芋ほりに行くことにしました。
ほとんど掘られてしまっていて、端っこのエリアが少し残っていました。
4株(一区画)500円で参加できます。
軍手は100円で購入可能。
マザー牧場人いわく、2kgくらい出てくるよ~ってことでしたが、実際に掘ってみるとそうとう大きなお芋がたくさん出てきました。
家に持って帰って測ってみると4.8kgありました!
佐倉天然温泉 澄流(すみれ) [温泉・スーパー銭湯]
佐倉天然温泉 澄流(すみれ)
http://www.sakurasomeino-sumire.com
マザー牧場の帰りに寄りました。
熱いお風呂だけじゃなく、古いお風呂もあり、
また、黄ゆずといった替り湯もありました。
成田空港の近くなので、少し遠い気もしますが、なかなか良い温泉です。
中で食事もできるのですが、温泉の周りで食事できるところも多いのか中のレストランは空いていました。
近くに行くことあれば、また寄ってみたいです。
http://www.sakurasomeino-sumire.com
マザー牧場の帰りに寄りました。
熱いお風呂だけじゃなく、古いお風呂もあり、
また、黄ゆずといった替り湯もありました。
成田空港の近くなので、少し遠い気もしますが、なかなか良い温泉です。
中で食事もできるのですが、温泉の周りで食事できるところも多いのか中のレストランは空いていました。
近くに行くことあれば、また寄ってみたいです。
bayesmのcheeseを使ったモデリング、その1~通常の線形回帰モデル [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
write.table(cheese, "cheese.txt", sep="\t", quote=F, col.names=T, row.names=F, append=F)
↑
いったん、ローカルにテキストファイルとして吐き出して、いろいろなモデルを作っていきます。
モデルは、SPSS Modelerを使用。
cheese のデータ概要ですが、全部で5,555レコード。
IDとなる、RETAILER数は、88社で、RETAILERをIDとすると、同じRETAILERのデータが複数存在します。
階層ベイズを使って線形回帰モデルを行っていくのですが、同じRETAILERでデータが、だいたい60レコード存在します。
5,555レコードあるのですが、
モデル作成用:5,359レコード
モデル検証用:176レコード
にランダムに分けます。
モデル検証用として、RETAILER 88社から2レコードずつ、合計176レコード取っておきます。
まずは、階層ベイズを使わないで、普通に線形回帰をしたらどうなるか?
目的変数:VOLUME
説明変数:DISP, log_PRICE
↑
もともとのデータは、PRICEが入っているのですが、ここではlog変換を行ってlog_PRICEを説明変数としています。
分析結果は、こんな感じ。
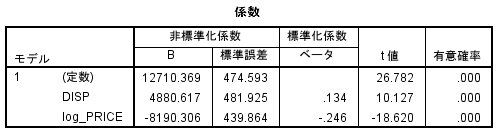
DSIP, log_PRICE ともに有意となっています。
DISP(陳列)した方が売れますし、PRICE(価格)が高くなると売れなくなります。
納得の結果ですね。
ただ、R2は、0.088とそれほど高くありません。
推定結果と実際の値を比較してみても、上手く予想できていないことがよくわかります。
【推定結果と実際の値の散布図】
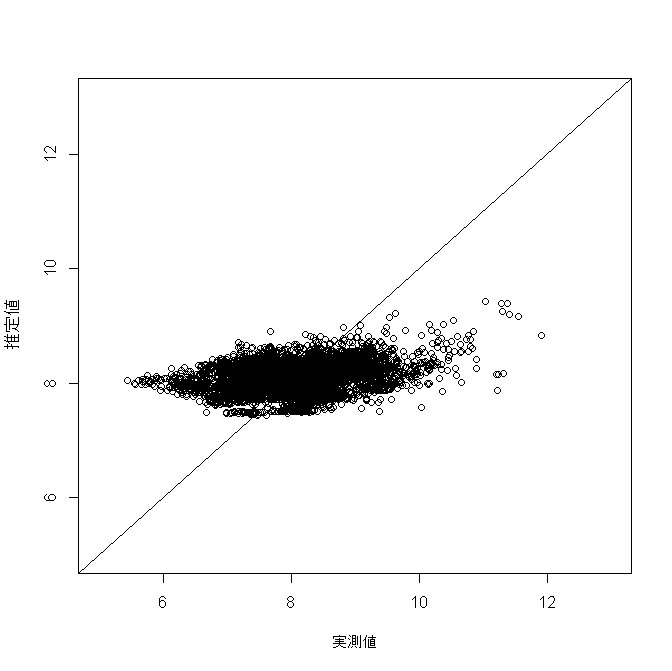
【推定結果と実際の値のピアソンの積率相関係数】
0.098
ということで、ここから工夫をしていくわけですが、
1. 通常の線形回帰モデル ← 今、ココ
2. RETAILER をフラグ化した線形回帰モデル
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
とモデリングしていきます。
write.table(cheese, "cheese.txt", sep="\t", quote=F, col.names=T, row.names=F, append=F)
↑
いったん、ローカルにテキストファイルとして吐き出して、いろいろなモデルを作っていきます。
モデルは、SPSS Modelerを使用。
cheese のデータ概要ですが、全部で5,555レコード。
IDとなる、RETAILER数は、88社で、RETAILERをIDとすると、同じRETAILERのデータが複数存在します。
階層ベイズを使って線形回帰モデルを行っていくのですが、同じRETAILERでデータが、だいたい60レコード存在します。
5,555レコードあるのですが、
モデル作成用:5,359レコード
モデル検証用:176レコード
にランダムに分けます。
モデル検証用として、RETAILER 88社から2レコードずつ、合計176レコード取っておきます。
まずは、階層ベイズを使わないで、普通に線形回帰をしたらどうなるか?
目的変数:VOLUME
説明変数:DISP, log_PRICE
↑
もともとのデータは、PRICEが入っているのですが、ここではlog変換を行ってlog_PRICEを説明変数としています。
分析結果は、こんな感じ。
DSIP, log_PRICE ともに有意となっています。
DISP(陳列)した方が売れますし、PRICE(価格)が高くなると売れなくなります。
納得の結果ですね。
ただ、R2は、0.088とそれほど高くありません。
推定結果と実際の値を比較してみても、上手く予想できていないことがよくわかります。
【推定結果と実際の値の散布図】
【推定結果と実際の値のピアソンの積率相関係数】
0.098
ということで、ここから工夫をしていくわけですが、
1. 通常の線形回帰モデル ← 今、ココ
2. RETAILER をフラグ化した線形回帰モデル
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
とモデリングしていきます。
bayesmのcheeseを使ったモデリング、その2~RETAILERをフラグ化した線形回帰モデル [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル ← 今回
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
通常の線形回帰モデルでは、個々のRETAILERの特性を上手く吸収できずに、いまいちな結果に終わりました。
「個々のRETAILERごとに反応が変わるならば、RETAILERフラグを作ってはどうだろうか?」
ということでRETAILERをフラグ化してみます。
【推定結果と実際の値の散布図】
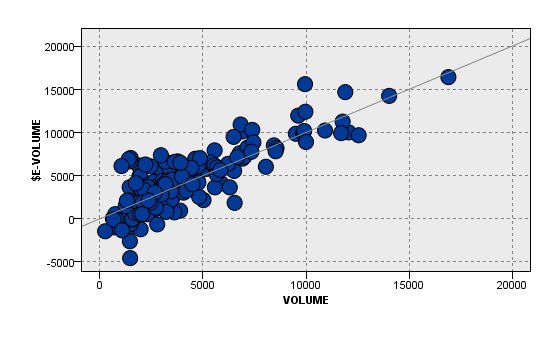
【推定結果と実際の値のピアソンの積率相関係数】
0.705
(通常の回帰モデルの場合は、0.098)
ということで、大幅に精度が上がりました。
RETAILERでフラグ化を行うということは、
説明変数
・切片 → RETAILERごとに異なる
・DISP → 共通の値
・log_PRICE → 共通の値
となっています。
階層ベイズを使った線形回帰モデルでは、切片だけでなくDISPやlog_PRICEもRETAILERごとに異質性を計算することができます。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル ← 今回
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
通常の線形回帰モデルでは、個々のRETAILERの特性を上手く吸収できずに、いまいちな結果に終わりました。
「個々のRETAILERごとに反応が変わるならば、RETAILERフラグを作ってはどうだろうか?」
ということでRETAILERをフラグ化してみます。
【推定結果と実際の値の散布図】
【推定結果と実際の値のピアソンの積率相関係数】
0.705
(通常の回帰モデルの場合は、0.098)
ということで、大幅に精度が上がりました。
RETAILERでフラグ化を行うということは、
説明変数
・切片 → RETAILERごとに異なる
・DISP → 共通の値
・log_PRICE → 共通の値
となっています。
階層ベイズを使った線形回帰モデルでは、切片だけでなくDISPやlog_PRICEもRETAILERごとに異質性を計算することができます。
bayesmのcheeseを使ったモデリング、その3~機械学習のアプローチ [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル
作成したモデルは、ニューラルネットワーク、決定木(CHAID)です。
通常の線形回帰モデル:0.098
フラグ化した線形回帰モデル:0.705
ニューラルネットワーク:0.816
決定木(CHAID):0.705
フラグ化した線形回帰モデルと決定木の精度が、ほぼ同等となりました。
ニューラルネットワークの精度が、頭一つ抜けていいますね。
決定木がどのように予測をしたか分析してみると、
第一階層は、RETAILERごとにざっくりと分類します。
第二階層以下は、DISPとlog_PRICEで切っていきます。
DISPは、{0, 1}のデータなので、問題ないのですが、
log_PRICEは、連続値のデータが入っています。
そのため、決定木でざっくりと切ってしまうと、その区切りの予測値は全部同じ値になってしまうため、細かい予測値を出すことができません。
このあたりが、ニューラルネットワークより精度が劣る一つの原因になっていると思われます。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル
作成したモデルは、ニューラルネットワーク、決定木(CHAID)です。
通常の線形回帰モデル:0.098
フラグ化した線形回帰モデル:0.705
ニューラルネットワーク:0.816
決定木(CHAID):0.705
フラグ化した線形回帰モデルと決定木の精度が、ほぼ同等となりました。
ニューラルネットワークの精度が、頭一つ抜けていいますね。
決定木がどのように予測をしたか分析してみると、
第一階層は、RETAILERごとにざっくりと分類します。
第二階層以下は、DISPとlog_PRICEで切っていきます。
DISPは、{0, 1}のデータなので、問題ないのですが、
log_PRICEは、連続値のデータが入っています。
そのため、決定木でざっくりと切ってしまうと、その区切りの予測値は全部同じ値になってしまうため、細かい予測値を出すことができません。
このあたりが、ニューラルネットワークより精度が劣る一つの原因になっていると思われます。
bayesmのcheeseを使ったモデリング、その4~階層ベイズを使った線形回帰モデル [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-10
目的変数:VOLUME(販売数量)
観測モデルの説明変数:DISP(陳列の有無), log_PRICE(販売価格のlog), 切片
階層モデル:切片のみ
RETAILERごとに説明変数のβ(係数)を求めることができます。
本当は、RETAILERに関する情報(土地情報, 店舗数)などを追加で用意できると、それらの特徴ごとに、βの傾向を把握することができます。
例えば、地方都市だと、陳列の有無が重要であるとか。
今回の cheese にはそのような情報が含まれていないので、切片のみのモデルとなっています。
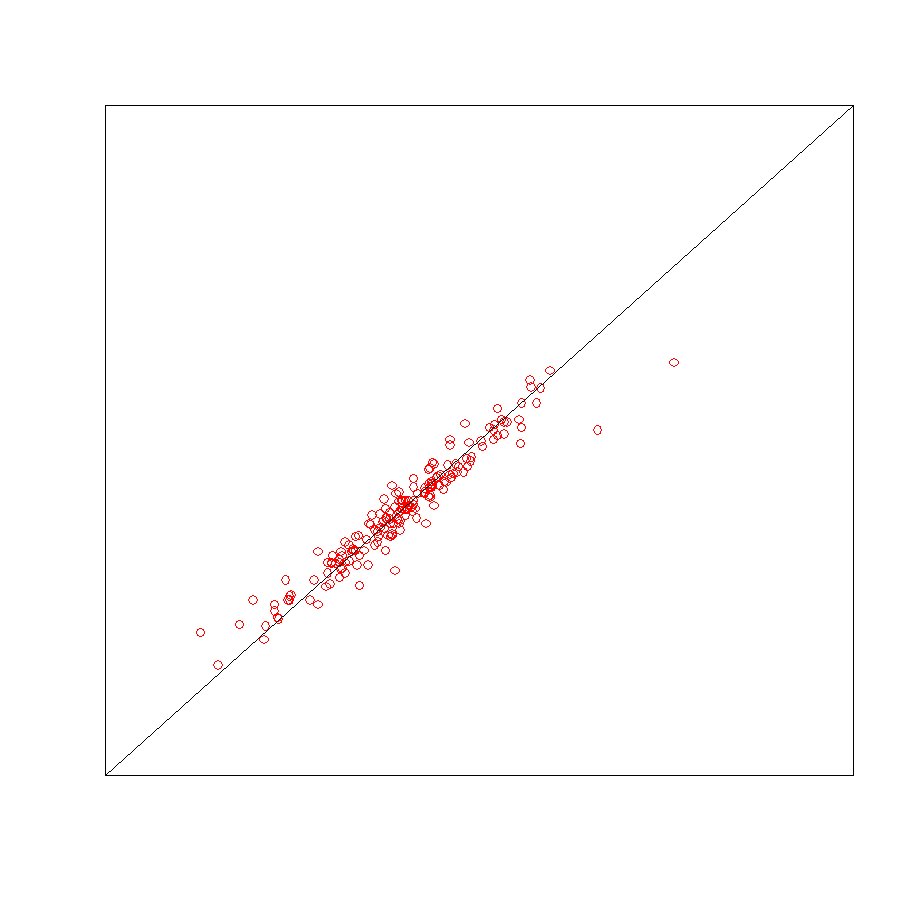
【推定結果と実際の値の散布図】
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-10
目的変数:VOLUME(販売数量)
観測モデルの説明変数:DISP(陳列の有無), log_PRICE(販売価格のlog), 切片
階層モデル:切片のみ
RETAILERごとに説明変数のβ(係数)を求めることができます。
本当は、RETAILERに関する情報(土地情報, 店舗数)などを追加で用意できると、それらの特徴ごとに、βの傾向を把握することができます。
例えば、地方都市だと、陳列の有無が重要であるとか。
今回の cheese にはそのような情報が含まれていないので、切片のみのモデルとなっています。
【推定結果と実際の値の散布図】
映画『斉木楠雄のΨ難』 [テレビ / 映画]
息子が珍しく、邦画を観たいってことで、この映画を観てきました。
もともと、コミックとかアニメでやっていたみたいですが、まったく読んだことも、観たこともなく、
映画のポスターを観ると、なんか微妙そう・・・と思っていました。
映画が始まると、予想は全く外れ、爆笑の連続でした。
めちゃくちゃ面白い映画でした!
後、美少女役に橋本環奈も出演。
美少女役なんですが、映画では腹黒い部分の演じる必要があるわけですが、
そういうダークサイドの部分もしっかりと演じていました。
機会があれば、コミックやアニメも見てみたいです。
アニメですが、第二期が年明けから始まるそうです。
")
")
もともと、コミックとかアニメでやっていたみたいですが、まったく読んだことも、観たこともなく、
映画のポスターを観ると、なんか微妙そう・・・と思っていました。
映画が始まると、予想は全く外れ、爆笑の連続でした。
めちゃくちゃ面白い映画でした!
後、美少女役に橋本環奈も出演。
美少女役なんですが、映画では腹黒い部分の演じる必要があるわけですが、
そういうダークサイドの部分もしっかりと演じていました。
機会があれば、コミックやアニメも見てみたいです。
アニメですが、第二期が年明けから始まるそうです。
斉木楠雄のΨ難 映画ノベライズ みらい文庫版 (集英社みらい文庫)
- 作者: 麻生 周一
- 出版社/メーカー: 集英社
- 発売日: 2017/10/04
- メディア: 新書
映画ノベライズ 斉木楠雄のΨ難 (JUMP j BOOKS)
- 作者: 麻生 周一
- 出版社/メーカー: 集英社
- 発売日: 2017/10/04
- メディア: 新書
縄文式土器を作成 [ファミリー]
![小学8年生(4) 2017年 11 月号 [雑誌]](https://images-fe.ssl-images-amazon.com/images/I/61JOOEIA7NL._SL160_.jpg "小学8年生(4) 2017年 11 月号 [雑誌]")
- 作者:
- 出版社/メーカー: 小学館
- 発売日: 2017/09/28
- メディア: 雑誌
付録を使って縄文式土器を作りました。
息子は、もともと、縄文時代とか弥生時代の話が好きなので、親子で縄文土器を作りとても楽しかったです。
実際に作ってみると、難しい部分があり、昔の人はこんな風に土器を作っていたんだなぁと、すごく勉強になりました。
ただ、この雑誌についていた「安倍晋三」の漫画がひど過ぎますね。。。
はっきりと悪意のある描写をしていて、この内容を子供の雑誌に載せるのはいかがなものか、、、と思ってしまいました。
階層ベイズ2項ロジットモデルの推定 [階層ベイズ]
階層ベイズ2項ロジットモデルの推定をする際に、よく使われるのが R のパッケージの "bayesm" でしょうか。
rhierBinLogit / rhierMnlRwMixture という関数を使います。
ただ、細かい設定をしたい場合は、尤度関数を書く必要があります。
## 2項ロジットモデルの対数尤度関数の定義
loglike <- function(y, X, beta) {
u <- X %*% beta
p <- exp(u)/(1 + exp(u))
ll <- y * log(p) + (1 - y) * log(1 - p)
sum(ll)
}
↑
尤度関数はこうなります。
尤度関数を自由に扱うことができれば、ここから Nested Logit に拡張したり、いろいろな分析をすることができるのですが、少しプログラムをいじると、急に動かなくなるのが難しいところ。。。
その場合は、原理原則に戻って、丁寧にプログラムを作っていく必要がありますね。。。
なかなか動かないプログラムが、上手く動くようになった瞬間が、一番目の醍醐味ですね。
二番目の醍醐味は、シミュレーションした結果から、何かマーケティング的に面白い知見を得られた瞬間。
苦労が多ければ多いほど、成功したときに喜びは大きい。
rhierBinLogit / rhierMnlRwMixture という関数を使います。
ただ、細かい設定をしたい場合は、尤度関数を書く必要があります。
## 2項ロジットモデルの対数尤度関数の定義
loglike <- function(y, X, beta) {
u <- X %*% beta
p <- exp(u)/(1 + exp(u))
ll <- y * log(p) + (1 - y) * log(1 - p)
sum(ll)
}
↑
尤度関数はこうなります。
尤度関数を自由に扱うことができれば、ここから Nested Logit に拡張したり、いろいろな分析をすることができるのですが、少しプログラムをいじると、急に動かなくなるのが難しいところ。。。
その場合は、原理原則に戻って、丁寧にプログラムを作っていく必要がありますね。。。
なかなか動かないプログラムが、上手く動くようになった瞬間が、一番目の醍醐味ですね。
二番目の醍醐味は、シミュレーションした結果から、何かマーケティング的に面白い知見を得られた瞬間。
苦労が多ければ多いほど、成功したときに喜びは大きい。
SPSS Datathon 2017 特別講演 [データサイエンス、統計モデル]
SPSS Datathon - 研究奨励賞復活!データサイエンティストへの道
http://spss-datathon.com
↑
12月6日に開催されます。
こちらで講演するのですが、今回は、「時系列分析」について話そうかと思っています。
当日の観覧受付は、上記のサイトから申し込みできるようです。
http://spss-datathon.com
↑
12月6日に開催されます。
こちらで講演するのですが、今回は、「時系列分析」について話そうかと思っています。
当日の観覧受付は、上記のサイトから申し込みできるようです。
日付差を計算させるSQL [データサイエンス、統計モデル]
データベースが異なると、SQLの書き方も若干変わってきます。
データベースを変更する際、思った以上に移管コストがかかるので、注意が必要ですね。。。(涙
以下、備忘録
■ 日時データを日付データに置換するSQL
## Netezza(PureData)の場合
SELECT
DATE(日時フィールド) AS "日付フィールド"
FROM データベース名
## Oracle Exadataの場合
SELECT
TRUNC(日時フィールド, 'DD') AS "日付フィールド"
FROM データベース名
■ 日付差を計算させるSQL
## Netezza(PureData)の場合
SELECT
DATE_1 - DATE_2 AS "日付差",
FROM データベース名
## Oracle Exadataの場合
SELECT
TRUNC(DATE_1, 'DD') - TRUNC(DATE_2, 'DD') AS "日付差"
FROM データベース名
データベースを変更する際、思った以上に移管コストがかかるので、注意が必要ですね。。。(涙
以下、備忘録
■ 日時データを日付データに置換するSQL
## Netezza(PureData)の場合
SELECT
DATE(日時フィールド) AS "日付フィールド"
FROM データベース名
## Oracle Exadataの場合
SELECT
TRUNC(日時フィールド, 'DD') AS "日付フィールド"
FROM データベース名
■ 日付差を計算させるSQL
## Netezza(PureData)の場合
SELECT
DATE_1 - DATE_2 AS "日付差",
FROM データベース名
## Oracle Exadataの場合
SELECT
TRUNC(DATE_1, 'DD') - TRUNC(DATE_2, 'DD') AS "日付差"
FROM データベース名
普通の回帰ではなく、階層ベイズを使う利点 [階層ベイズ]
階層ベイズで変数が多くなると、計算時間が多くなってしまうので、
なんとか変数選択できないか?と考えました。
例えば、
1. まず、最初に、通常の回帰を行い、有意でないパラメータをみつける
2. 有意な変数のみ、階層ベイズの変数として使用する
というのは、どうかと思いました。
自分の先生に確認したところ、
『階層ベイズは、個人ごとのパラメータを推定できるのが利点。
つまり、普通の回帰(平均的にみれば)では、有意でないかもしれないけど、
ごく少数の人には有効な変数を発見できる。
』
とのことでした。
なるほど、、、
階層ベイズで、個人の異質性を表現することができますが、それは、普通の回帰分析では有意な変数でもある人にとって見れば有意でないし、
また、その逆で、有意でない変数もある人にとって見れば、すごく効いてくる変数かもしれない。
個人ごとのβのパラメータのヒストグラムです。
図1:βの平均値は、-0.224
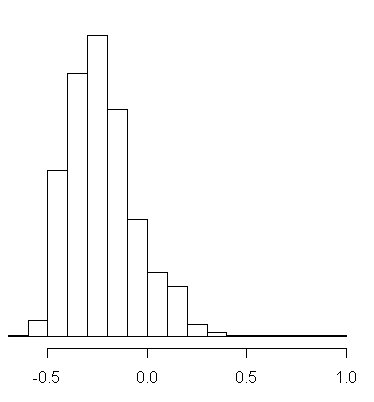
図1は、きれいな正規分布に近い形をしています。
よく見ると、個人ごとに幅はあり、プラスの効果になっている人もいれば、マイナスの効果になっている人もいます。
図2:βの平均値は、0.008
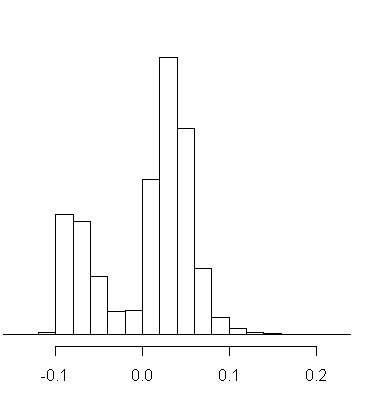
図2は、明らかに二つのタイプの人がいることが分かります。
プラスに効く人とマイナスに効く人。
そして、平均値は、ちょうど二つの谷の0.008となっています。
通常の回帰分析では、このβの効果は、0.008と判断してしまうところですが、
実際は、0.008という平均の値を持っている人は、ほとんどいなくて、
よりマイナスか、よりプラスかのどちらか極端の値を持っている人だけとなります。
なんとか変数選択できないか?と考えました。
例えば、
1. まず、最初に、通常の回帰を行い、有意でないパラメータをみつける
2. 有意な変数のみ、階層ベイズの変数として使用する
というのは、どうかと思いました。
自分の先生に確認したところ、
『階層ベイズは、個人ごとのパラメータを推定できるのが利点。
つまり、普通の回帰(平均的にみれば)では、有意でないかもしれないけど、
ごく少数の人には有効な変数を発見できる。
』
とのことでした。
なるほど、、、
階層ベイズで、個人の異質性を表現することができますが、それは、普通の回帰分析では有意な変数でもある人にとって見れば有意でないし、
また、その逆で、有意でない変数もある人にとって見れば、すごく効いてくる変数かもしれない。
個人ごとのβのパラメータのヒストグラムです。
図1:βの平均値は、-0.224
図1は、きれいな正規分布に近い形をしています。
よく見ると、個人ごとに幅はあり、プラスの効果になっている人もいれば、マイナスの効果になっている人もいます。
図2:βの平均値は、0.008
図2は、明らかに二つのタイプの人がいることが分かります。
プラスに効く人とマイナスに効く人。
そして、平均値は、ちょうど二つの谷の0.008となっています。
通常の回帰分析では、このβの効果は、0.008と判断してしまうところですが、
実際は、0.008という平均の値を持っている人は、ほとんどいなくて、
よりマイナスか、よりプラスかのどちらか極端の値を持っている人だけとなります。

