状態空間モデルを使った広告効果の持続性 [時系列解析 / 需要予測]
まずは、擬似データの作成から。

stanを使い、モデルを2つ試しました。
モデル1: 広告効果をベクトルで表現する
##################################################
transformed parameters {
alpha[i] = mu[i] + c1[i]*ad_flg[i];
}
model {
mu[i] ~ normal(mu[i-1], s_w);
c1[i] ~ normal(2*c1[i-1]-c1[i-2], s_c1);
y[i] ~ normal(alpha[i], s_v);
}
##################################################
mu: 水準
今日の水準 = 昨日の水準
c1: 広告効果
広告効果は滑らかであるという仮定から
今日の水準 - 昨日の水準 = 昨日の水準 - 一昨日の水準

モデル2: 広告効果の減衰をモデルに与える
log関数を使い、広告の減衰効果を表現しました。


stanを使い、モデルを2つ試しました。
モデル1: 広告効果をベクトルで表現する
##################################################
transformed parameters {
alpha[i] = mu[i] + c1[i]*ad_flg[i];
}
model {
mu[i] ~ normal(mu[i-1], s_w);
c1[i] ~ normal(2*c1[i-1]-c1[i-2], s_c1);
y[i] ~ normal(alpha[i], s_v);
}
##################################################
mu: 水準
今日の水準 = 昨日の水準
c1: 広告効果
広告効果は滑らかであるという仮定から
今日の水準 - 昨日の水準 = 昨日の水準 - 一昨日の水準
モデル2: 広告効果の減衰をモデルに与える
log関数を使い、広告の減衰効果を表現しました。
時系列分析と状態空間モデルの基礎: RとStanで学ぶ理論と実装
- 作者: 真哉, 馬場
- 出版社/メーカー: プレアデス出版
- 発売日: 2018/02/14
- メディア: 単行本
状態空間モデル、stanを使って未来を予測する [時系列解析 / 需要予測]
stanには、いくつかの構造があります。
stanコード
有名な data(AirPassengers) を使って予測をするのですが、重要なのがトレンドのメカニズムをどう書くか。
単純に
mu[i] ~ normal(mu[i-1], sd_mu)
としてしまうと、学習期間のトレンドは良いのですが、予測期間においてはうまく予測できません。
上の式は、昨日のトレンドは、今日のトレンドとしてしまっているために、予測するタイミングにおいて、トレンドが一定になってしまうからです。
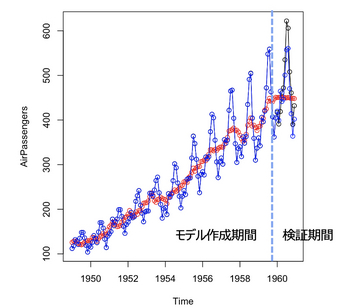
これを補正するには、色々なアイデアがあります。
例えば、
mu[i] ~ normal(2*mu[i-1] - mu[i-2], sd_mu)
一昨日から昨日の差分は、昨日から今日の差分とすると、ある程度トレンドを維持することができそうです。
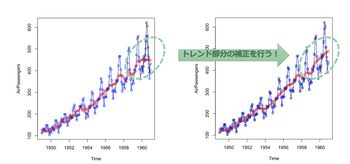
これ以外にもさまざまな工夫(自由度)があるのが、状態空間モデルの面白いところです。
stanコード
data {
データの設定
int pred_term; // 予測期間
}
parameters {
パラメータの設定
}
transformed parameters {
新しい変数の設定
}
model {
モデル式(メカニズム)
}
generated quantities{
予測式
}
有名な data(AirPassengers) を使って予測をするのですが、重要なのがトレンドのメカニズムをどう書くか。
単純に
mu[i] ~ normal(mu[i-1], sd_mu)
としてしまうと、学習期間のトレンドは良いのですが、予測期間においてはうまく予測できません。
上の式は、昨日のトレンドは、今日のトレンドとしてしまっているために、予測するタイミングにおいて、トレンドが一定になってしまうからです。
これを補正するには、色々なアイデアがあります。
例えば、
mu[i] ~ normal(2*mu[i-1] - mu[i-2], sd_mu)
一昨日から昨日の差分は、昨日から今日の差分とすると、ある程度トレンドを維持することができそうです。
これ以外にもさまざまな工夫(自由度)があるのが、状態空間モデルの面白いところです。
TVCMなどの試作実行前に行うAAテストの意味 その2 ボラティリティが高い時系列 [時系列解析 / 需要予測]
時系列モデルは、基本的には、以下の様に分解して作る。
元の時系列 = トレンド + 季節性 + 施策効果
ここで、AAテストというのは、トレンドや季節性を除去した際に、何もないノイズに5%とか10%のノイズを与えてそれが検知できるかをやっている。
最近、気がついたことであるが・・・
自分がこれまでよく分析していた業種の場合は、CM効果は、たかだが5%とか10%程度である。
一方、業種によれば、CM効果が300%とか400%といったものすごい効果がある業種も存在する。
ものすごくボラティリティが高い業種において、そのままでAAテストをしましょう、というのはあまり意味がないし、検知できる時系列でもない。
このような時系列の場合は、ボラティリティが高くなる要因をある程度除去をしてからAAテストをした方が良さそうである。
つまり、
元の時系列 = トレンド + 季節性 + 施策効果(施策の効果として5%想定) + 誤差
だと、誤差が300%とか400%になってしまう。
元の時系列 = トレンド + 季節性 + 施策効果(300%〜400%) + 施策効果(施策の効果として5%想定) + 誤差
としたAAテストをする方が良いだろう。
元の時系列 = トレンド + 季節性 + 施策効果
ここで、AAテストというのは、トレンドや季節性を除去した際に、何もないノイズに5%とか10%のノイズを与えてそれが検知できるかをやっている。
最近、気がついたことであるが・・・
自分がこれまでよく分析していた業種の場合は、CM効果は、たかだが5%とか10%程度である。
一方、業種によれば、CM効果が300%とか400%といったものすごい効果がある業種も存在する。
ものすごくボラティリティが高い業種において、そのままでAAテストをしましょう、というのはあまり意味がないし、検知できる時系列でもない。
このような時系列の場合は、ボラティリティが高くなる要因をある程度除去をしてからAAテストをした方が良さそうである。
つまり、
元の時系列 = トレンド + 季節性 + 施策効果(施策の効果として5%想定) + 誤差
だと、誤差が300%とか400%になってしまう。
元の時系列 = トレンド + 季節性 + 施策効果(300%〜400%) + 施策効果(施策の効果として5%想定) + 誤差
としたAAテストをする方が良いだろう。
TVCMなどの試作実行前に行うAAテストの意味 その1 必要条件 [時系列解析 / 需要予測]
時系列のモデル(状態空間モデル)を使い、TVCMなどの広告効果をモデル化することを考える。
その際、事前にAAテストを実施しておくことは大切。
目的は2つあって、
1. 仮に5%くらいのリフト(効果)があった時に、本当にその効果が検知できるかを事前に調べる。
2. 本当は差がないにもかかわらず、適当な区間でCMを打ったと仮定した時に、本来は効果が0であるにも関わらず、見せかけの効果を検出してしまわないかを調べる。
AAテストが問題なければ、実際の効果が正しく得られるかと言えばそうではないが
少なくともAAテストがグダグダな結果であれば、その後も分析も意味がないだろう。
つまり、必要十分条件ではないが、必要条件みたいなものだと思う。
その際、事前にAAテストを実施しておくことは大切。
目的は2つあって、
1. 仮に5%くらいのリフト(効果)があった時に、本当にその効果が検知できるかを事前に調べる。
2. 本当は差がないにもかかわらず、適当な区間でCMを打ったと仮定した時に、本来は効果が0であるにも関わらず、見せかけの効果を検出してしまわないかを調べる。
AAテストが問題なければ、実際の効果が正しく得られるかと言えばそうではないが
少なくともAAテストがグダグダな結果であれば、その後も分析も意味がないだろう。
つまり、必要十分条件ではないが、必要条件みたいなものだと思う。
SARIMAを使ったMMMモデル [時系列解析 / 需要予測]
昔は、時系列モデルといえば、よくARIMAを使っていたのですが、最近、めっきり状態空間モデルを使っている自分がいます。
そこで、MMMモデルでSARIMAに説明変数を加えたSARIMAXが使えないかと思い、久々にARIMAでモデル化をしました。
AP_ad1.fit <- auto.arima(
y = dat_ad,
xreg = x_ad1,
ic="aic",
trace=TRUE,
stepwise=FALSE,
approximation=FALSE,
num.cores=4
)
y:対象となる時系列
xreg:説明変数(広告効果)
ic:モデル選択で使用する情報基準
trace:試したモデルを表示する
stepwise:ステップワイズ法により計算時間が短縮される
approximation:近似オプション(時点数が多い場合)
parallel:並列処理のオプション
num.cores:並列処理の量を指定、NULLの場合は自動検出
※ traceとstepwiseがFである必要がある
トレンドと季節性がほぼ決まっているのであれば、SARIMAXも使えなくはないかなという印象です。
そこで、MMMモデルでSARIMAに説明変数を加えたSARIMAXが使えないかと思い、久々にARIMAでモデル化をしました。
AP_ad1.fit <- auto.arima(
y = dat_ad,
xreg = x_ad1,
ic="aic",
trace=TRUE,
stepwise=FALSE,
approximation=FALSE,
num.cores=4
)
y:対象となる時系列
xreg:説明変数(広告効果)
ic:モデル選択で使用する情報基準
trace:試したモデルを表示する
stepwise:ステップワイズ法により計算時間が短縮される
approximation:近似オプション(時点数が多い場合)
parallel:並列処理のオプション
num.cores:並列処理の量を指定、NULLの場合は自動検出
※ traceとstepwiseがFである必要がある
トレンドと季節性がほぼ決まっているのであれば、SARIMAXも使えなくはないかなという印象です。
[MMM] causal impact の評価 その4 周期性の設定 [時系列解析 / 需要予測]
CausalImpactで季節変動(周期変動)を入れるにはどうすれば良いか?
RとPythonでは若干書き方異なるのですが、
impact <- CausalImpact(dat_ci, pre.period, post.period, model.args=list(nseasons=7))
model.args=list(nseasons=7)
↑
この部分が周期性を入れるパラメータとなります。
日データの場合、曜日効果を消すために7を設定します。
〜 過去の実験 〜
[MMM] causal impact の評価 その1
https://skellington.blog.ss-blog.jp/2023-04-24
[MMM] causal impact の評価 その2
https://skellington.blog.ss-blog.jp/2023-04-25
[MMM] causal impact の評価 その3
https://skellington.blog.ss-blog.jp/2023-05-09
RとPythonでは若干書き方異なるのですが、
impact <- CausalImpact(dat_ci, pre.period, post.period, model.args=list(nseasons=7))
model.args=list(nseasons=7)
↑
この部分が周期性を入れるパラメータとなります。
日データの場合、曜日効果を消すために7を設定します。
〜 過去の実験 〜
[MMM] causal impact の評価 その1
https://skellington.blog.ss-blog.jp/2023-04-24
[MMM] causal impact の評価 その2
https://skellington.blog.ss-blog.jp/2023-04-25
[MMM] causal impact の評価 その3
https://skellington.blog.ss-blog.jp/2023-05-09
[MMM] causal impact の評価 その3 [時系列解析 / 需要予測]
CTLとなる時系列とTGとなる時系列を用意し、CausalImpactを使いましたが、あまり精度は高くない。
個人的には、stan(MCMC)の方が精度が良いと感じていますが・・・
試しに過去のデータを使い2つの実験を行いました。
実験1: type Ⅰエラーの確認
時系列に効果を与えない時に効果なしとなるか。
つまり、広告を実施している仮想の期間を与えます。
実際には何もしていないので、期待されるリフトは0になるはずですね。
実験2: type Ⅱエラーの確認
効果を与えた時に効果が検出できるか。
過去、広告を実施してないので、仮にx%のリフト効果を時系列与えます。
そして、x%のノイズを検知できるかどうか。
→ causal impactの結果は、正しく検出できず。
一方、stan(MCMC)は実験1と実験2とも正しい結果を得ることができました。
causal impactは、さまざまな制約をおいた上で定式化をしていると思います。
その制約が満たされない時系列の場合、当然、正しい結果は得られません。
少し面倒かもしれませんが、きちんと定式化をすることが大切だと感じています。
〜 過去の実験 〜
[MMM] causal impact の評価 その1
https://skellington.blog.ss-blog.jp/2023-04-24
[MMM] causal impact の評価 その2
https://skellington.blog.ss-blog.jp/2023-04-25
個人的には、stan(MCMC)の方が精度が良いと感じていますが・・・
試しに過去のデータを使い2つの実験を行いました。
実験1: type Ⅰエラーの確認
時系列に効果を与えない時に効果なしとなるか。
つまり、広告を実施している仮想の期間を与えます。
実際には何もしていないので、期待されるリフトは0になるはずですね。
実験2: type Ⅱエラーの確認
効果を与えた時に効果が検出できるか。
過去、広告を実施してないので、仮にx%のリフト効果を時系列与えます。
そして、x%のノイズを検知できるかどうか。
→ causal impactの結果は、正しく検出できず。
一方、stan(MCMC)は実験1と実験2とも正しい結果を得ることができました。
causal impactは、さまざまな制約をおいた上で定式化をしていると思います。
その制約が満たされない時系列の場合、当然、正しい結果は得られません。
少し面倒かもしれませんが、きちんと定式化をすることが大切だと感じています。
〜 過去の実験 〜
[MMM] causal impact の評価 その1
https://skellington.blog.ss-blog.jp/2023-04-24
[MMM] causal impact の評価 その2
https://skellington.blog.ss-blog.jp/2023-04-25
[MMM] causal impact の評価 その2 [時系列解析 / 需要予測]
calsal impactを使っている人がいるので、どれだけ使えるか実験をしました。
結論からすると、TV CMの当該期間の推定は甘いし、その後のTV CMの残存部分の推定も甘い。
マーケターが簡単に使えるツールではあるものの、簡単という理由以外に使う理由はあまりなさそう。
(個人的には使わない方が良いと思っている)
ということで、自分でMCMC(stan)で推定をしました。
結果は、TV CMの期間もその後の減衰カーブもよくフィットできているのではと思っています。
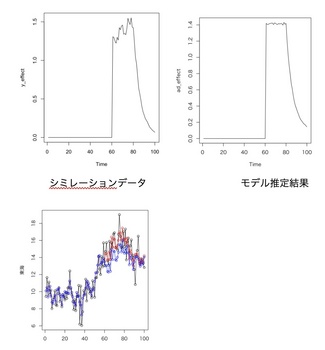
結論からすると、TV CMの当該期間の推定は甘いし、その後のTV CMの残存部分の推定も甘い。
マーケターが簡単に使えるツールではあるものの、簡単という理由以外に使う理由はあまりなさそう。
(個人的には使わない方が良いと思っている)
ということで、自分でMCMC(stan)で推定をしました。
結果は、TV CMの期間もその後の減衰カーブもよくフィットできているのではと思っています。
[MMM] causal impact の評価 その1 [時系列解析 / 需要予測]
calsal impactを使っている人がいるので、どれだけ使えるか実験をしました。
問題点1:減衰期間を設定できない(細かい設定ができない)
問題点2:アルゴリズムがブラックボックスであるため、上手く推定できているかの詳細な調査が難しい
問題点3:季節成分の設定ができない、また、出力速度を考えると、MCMCで推定しているわけではなさそう
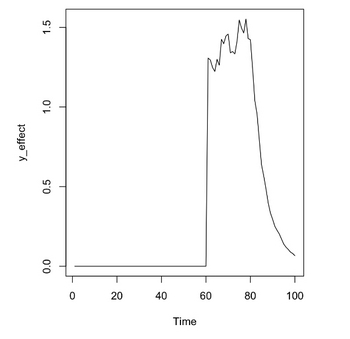
時間:1〜100時点
①広告非実施期間:1〜60
②広告実施期間:61〜80
③広告非実施期間(CM残存期間):80〜100
実験1(CausalImpact)
①広告非実施期間と②広告実施期間でのみ実験を行い、③広告非実施期間を含めない
②の部分の広告効果
# 推定した累積効果: 36.8
# 実際の累積効果: 27.7
↑
過大評価をしているものの、大きな問題はなさそうである
実験2(CausalImpact)
①広告非実施期間と②広告実施期間に加え、③広告非実施期間をpost.periodに加える
本来、③の期間はliftが減衰して与えているものの、CausalImpactはその部分の検知がかなり弱い。
②+③の部分の広告効果
# 推定した累積効果: 53.5
# 実際の累積効果: 35.8
↑
減衰効果を与えないと、過大評価をしている可能性が高い
問題点1:減衰期間を設定できない(細かい設定ができない)
問題点2:アルゴリズムがブラックボックスであるため、上手く推定できているかの詳細な調査が難しい
問題点3:季節成分の設定ができない、また、出力速度を考えると、MCMCで推定しているわけではなさそう
時間:1〜100時点
①広告非実施期間:1〜60
②広告実施期間:61〜80
③広告非実施期間(CM残存期間):80〜100
実験1(CausalImpact)
①広告非実施期間と②広告実施期間でのみ実験を行い、③広告非実施期間を含めない
Average Cumulative
Actual 16 311
Prediction (s.d.) 14 (0.35) 275 (7.08)
95% CI [13, 14] [261, 289]
Absolute effect (s.d.) 1.8 (0.35) 36.8 (7.08)
95% CI [1.1, 2.5] [22.9, 50.4]
Relative effect (s.d.) 13% (2.9%) 13% (2.9%)
95% CI [7.9%, 19%] [7.9%, 19%]
Posterior tail-area probability p: 0.001
Posterior prob. of a causal effect: 99.8998%
②の部分の広告効果
# 推定した累積効果: 36.8
# 実際の累積効果: 27.7
↑
過大評価をしているものの、大きな問題はなさそうである
実験2(CausalImpact)
①広告非実施期間と②広告実施期間に加え、③広告非実施期間をpost.periodに加える
本来、③の期間はliftが減衰して与えているものの、CausalImpactはその部分の検知がかなり弱い。
Average Cumulative
Actual 15 598
Prediction (s.d.) 14 (0.33) 545 (13.21)
95% CI [13, 14] [520, 572]
Absolute effect (s.d.) 1.3 (0.33) 53.5 (13.21)
95% CI [0.67, 2] [26.69, 79]
Relative effect (s.d.) 9.9% (2.7%) 9.9% (2.7%)
95% CI [4.7%, 15%] [4.7%, 15%]
Posterior tail-area probability p: 0.001
Posterior prob. of a causal effect: 99.8998%
②+③の部分の広告効果
# 推定した累積効果: 53.5
# 実際の累積効果: 35.8
↑
減衰効果を与えないと、過大評価をしている可能性が高い
RでCausalImpact(広告効果) [時系列解析 / 需要予測]
これまで広告効果などの推定は、staのMCMCで推定したり、自分でスクラッチで作っていました。
CausalImpactを使う人が多いので、自分も使ったのですが、思った以上に簡単!
ただ、どういう仮定を置いているとか、細かい設定ができないため、それっぽい答えが出てきても、なんだかよくわらかない状態になりました。
自分のプログラムの検証とかには使えるのかもと思いつつ、CausalImpactだけで広告最適化とかってのはかなり厳しいと感じています。
CausalImpactを使う人が多いので、自分も使ったのですが、思った以上に簡単!
ただ、どういう仮定を置いているとか、細かい設定ができないため、それっぽい答えが出てきても、なんだかよくわらかない状態になりました。
自分のプログラムの検証とかには使えるのかもと思いつつ、CausalImpactだけで広告最適化とかってのはかなり厳しいと感じています。
統計数理研究所「Rによる時系列解析入門」のセミナー [時系列解析 / 需要予測]
「Rによる時系列解析入門」のセミナー
を受講しました。
内容は初級ということで、状態空間モデルなどは入っていなかったです。
ただ、初級だけど、そこそこ難しい。
自分がどこの知識が弱いか理解するのにとても役に立ちますね。
授業はオンラインでしたが、色々な人が様々な質問をしてくれるのも良いです。
自分が見過ごしていた部分など、別の視点の質問など、なるほど!と思ってしまいます。
いずれにしろ、ほぼ1日潰れてしまうので、仕事の調整が大変なのですが、また次回の統数研のセミナーを受講してみたいです。
を受講しました。
内容は初級ということで、状態空間モデルなどは入っていなかったです。
ただ、初級だけど、そこそこ難しい。
自分がどこの知識が弱いか理解するのにとても役に立ちますね。
授業はオンラインでしたが、色々な人が様々な質問をしてくれるのも良いです。
自分が見過ごしていた部分など、別の視点の質問など、なるほど!と思ってしまいます。
いずれにしろ、ほぼ1日潰れてしまうので、仕事の調整が大変なのですが、また次回の統数研のセミナーを受講してみたいです。
欠損値を含む状態空間モデル [時系列解析 / 需要予測]
通常の時系列モデルの場合は、欠損値を含む場合は、モデリングするのが難しいです。
状態空間モデルを使うと、欠損値を含むデータに対してもモデリングできるのがメリットです。
方針というのはこんな感じです。
(状態モデル)
→ データ(観測データ)が欠損していても、状態はそのまま推移していると考える。
for(i in 2:T) {
mu[i] ~ normal(mu[(i-1)], sd_a);
}
(観測モデル)
→ 観測モデルは、状態モデルから推定されるので、観測できている時点の状態データを持ってくる。
for(i in 1:len_obs) {
y[i] ~ normal(mu[obs_no[i]], sd_v);
}
状態空間モデルを使うと、欠損値を含むデータに対してもモデリングできるのがメリットです。
方針というのはこんな感じです。
(状態モデル)
→ データ(観測データ)が欠損していても、状態はそのまま推移していると考える。
for(i in 2:T) {
mu[i] ~ normal(mu[(i-1)], sd_a);
}
(観測モデル)
→ 観測モデルは、状態モデルから推定されるので、観測できている時点の状態データを持ってくる。
for(i in 1:len_obs) {
y[i] ~ normal(mu[obs_no[i]], sd_v);
}
ARMAモデルからGARCHモデルへ その2 GARCH(p, q) [時系列解析 / 需要予測]
まずは、通常のARモデルの推定方法から
### 係数や次数の自動推定
ar.fit1 <- ar(nikkei.d)
# ARMA(p, q)の推定
est1 <- arima(nikkei.d, order=c(1,0,0)) #AR1を推定
# 残差にARをあてはめる
ar(est1$residuals)$order # 自己相関なし
Box.test(est1$residuals, type="L") # 自己相関なし
# 残差の二乗にARをあてはめる
ar(est1$residuals^2)$order # 自己相関あり
Box.test(est1$residuals^2, type="L") # 自己相関あり
# Janque-Bera 検定
library(tseries)
jarque.bera.test(nikkei.d)
jarque.bera.test(est1$residuals)
### GARCH(p, q) = (1, 1)
install.packages("fGarch")
library(fGarch)
model.g <- garchFit(~arma(0,1)+garch(1,1), data=nikkei.d, TRACE=FALSE)
plot(model.g)
summary(model.g)
### 係数や次数の自動推定
ar.fit1 <- ar(nikkei.d)
# ARMA(p, q)の推定
est1 <- arima(nikkei.d, order=c(1,0,0)) #AR1を推定
# 残差にARをあてはめる
ar(est1$residuals)$order # 自己相関なし
Box.test(est1$residuals, type="L") # 自己相関なし
# 残差の二乗にARをあてはめる
ar(est1$residuals^2)$order # 自己相関あり
Box.test(est1$residuals^2, type="L") # 自己相関あり
# Janque-Bera 検定
library(tseries)
jarque.bera.test(nikkei.d)
jarque.bera.test(est1$residuals)
### GARCH(p, q) = (1, 1)
install.packages("fGarch")
library(fGarch)
model.g <- garchFit(~arma(0,1)+garch(1,1), data=nikkei.d, TRACE=FALSE)
plot(model.g)
summary(model.g)
ARMAモデルからGARCHモデルへ その1 分散が不均一の現象 [時系列解析 / 需要予測]
一般的なARMA(p , q)モデルでは、残差εが正規分布に従うホワイトノイズであることを仮定している
→ モデル診断で推定された誤差が正規性と無相関性を満たすかどうかを確認する
正規性とのあてはまりを視覚的に確認する方法として、QQプロットが利用される
統計的検定の枠組みを使って正規分布の適合を調べる方法の一つにJarque-Bera検定がある
帰無仮説H0: データは正規分布にしたがっている
対立仮説H1: データは正規分布に従っていない
一般的に株式や為替などの対数収益率は正規分布より裾が厚い分布に従うことが知られている
こうした性質を表現するモデルとして、正規分布より裾が厚い分布(t分布など)、不均一分散モデル、レジームシフトモデルなどが提案されている
株式は為替の収益率データの自己相関はそれほど強くないことが多いが、分散(ボラティリティ)は強い相関を持つことが知られている
収益率を二乗すると、符号を無視して変動の大きさの相関を測っていることになり、何らかのショックでいったんボラティリティが高まった時にそれが継続する傾向があれば、自己相関関数は大きくなる
ARMA(p, q)モデルでは、誤差項εの分散が時間的に一定であると仮定したため、分散が不均一の現象を表現することはできない
誤差分散の時間変動を表現できるモデルとして考えらたのがGARCHモデル
→ モデル診断で推定された誤差が正規性と無相関性を満たすかどうかを確認する
正規性とのあてはまりを視覚的に確認する方法として、QQプロットが利用される
統計的検定の枠組みを使って正規分布の適合を調べる方法の一つにJarque-Bera検定がある
帰無仮説H0: データは正規分布にしたがっている
対立仮説H1: データは正規分布に従っていない
一般的に株式や為替などの対数収益率は正規分布より裾が厚い分布に従うことが知られている
こうした性質を表現するモデルとして、正規分布より裾が厚い分布(t分布など)、不均一分散モデル、レジームシフトモデルなどが提案されている
株式は為替の収益率データの自己相関はそれほど強くないことが多いが、分散(ボラティリティ)は強い相関を持つことが知られている
収益率を二乗すると、符号を無視して変動の大きさの相関を測っていることになり、何らかのショックでいったんボラティリティが高まった時にそれが継続する傾向があれば、自己相関関数は大きくなる
ARMA(p, q)モデルでは、誤差項εの分散が時間的に一定であると仮定したため、分散が不均一の現象を表現することはできない
誤差分散の時間変動を表現できるモデルとして考えらたのがGARCHモデル
日本行動計量学会 第23回春の合宿セミナー [時系列解析 / 需要予測]
参加しました。
土日に開催となると、なかなか参加出来ない場合が多いのですが、今回は、zoomでのオンライン開催ということで自宅からアクセスして勉強させてもらいました。
時系列前半に関して2日間というセミナーはあまりなく、良い勉強になりました。
さっそく使ってみたいと思います。
土日に開催となると、なかなか参加出来ない場合が多いのですが、今回は、zoomでのオンライン開催ということで自宅からアクセスして勉強させてもらいました。
時系列前半に関して2日間というセミナーはあまりなく、良い勉強になりました。
さっそく使ってみたいと思います。
【時系列】広告効果をモデリングする ~その8 将来を予測する方法~ [時系列解析 / 需要予測]
その1からその7まではあくまでも既存のデータに対するフィットだけでした。
stanを使って将来のデータに対してどのように予測するか?
「generated quantities」を使うことで、将来を予測することができます。
例えば、
となります。
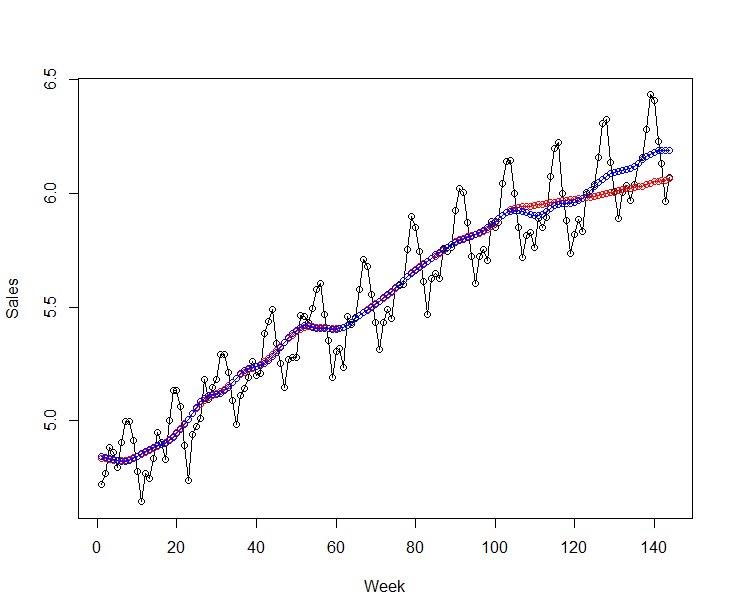
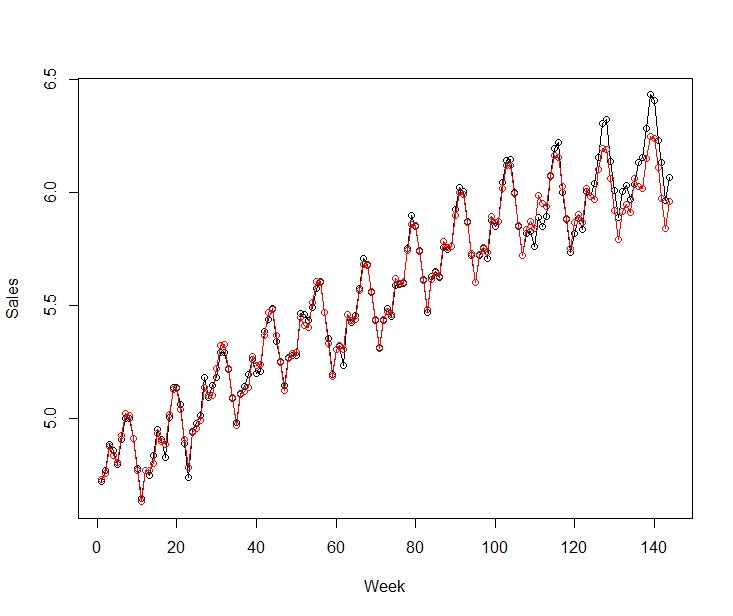
トレンドの予測が重要で、直近のトレンドから大きくトレンドが変化していると上手く予測できていません。
AirPassengersの例だと、最後3年分を予測期間とした場合、
予測のトレンド:赤色
実際のトレンド:青色
となり、予測値は実測値よりも下ぶれてしまいます。
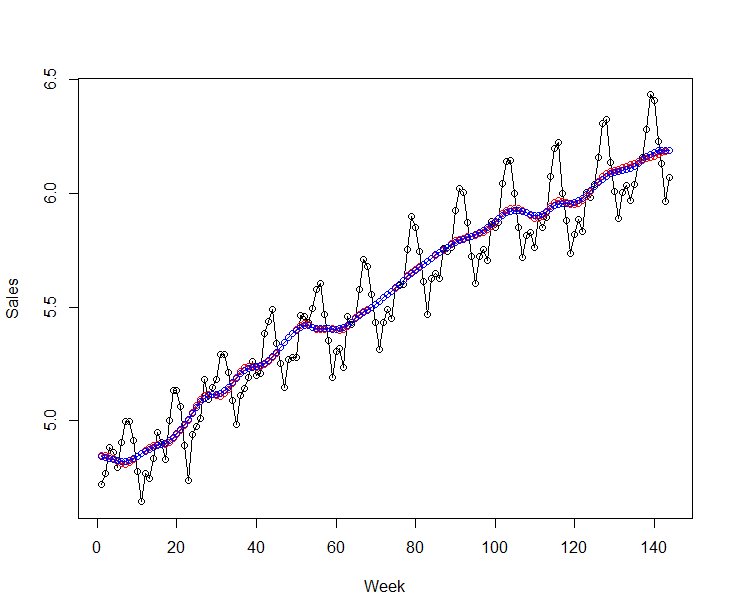
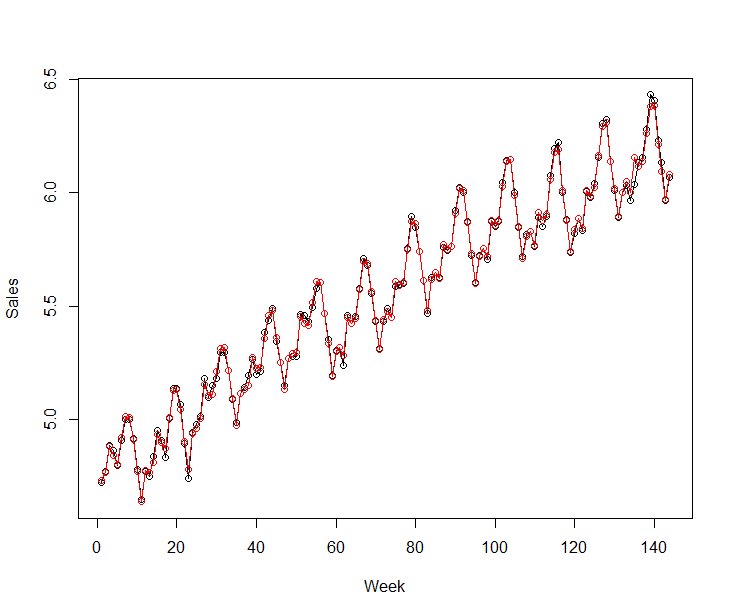
一方、最後1年分を予測期間とした場合、
トレンドが大きく変化していないので、予測値と実測値がほぼ同じとなっていることが確認できるかと思います。
stanを使って将来のデータに対してどのように予測するか?
「generated quantities」を使うことで、将来を予測することができます。
例えば、
generated quantities{
vector[T + pred_term] mu_pred;
vector[T + pred_term] x_seasonal_pred;
mu_pred[1:T] = mu;
x_seasonal_pred[1:T] = x_seasonal;
for(i in 1:pred_term){
mu_pred[T + i] = normal_rng(2*mu_pred[T+i-1] - mu_pred[T+i-2], sd_mu);
}
for(i in 1:pred_term){
x_seasonal_pred[T + i] = normal_rng(-sum(x_seasonal_pred[(T+i-11):(T+i-1)]), sd_sea);
}
}
となります。
トレンドの予測が重要で、直近のトレンドから大きくトレンドが変化していると上手く予測できていません。
AirPassengersの例だと、最後3年分を予測期間とした場合、
予測のトレンド:赤色
実際のトレンド:青色
となり、予測値は実測値よりも下ぶれてしまいます。
一方、最後1年分を予測期間とした場合、
トレンドが大きく変化していないので、予測値と実測値がほぼ同じとなっていることが確認できるかと思います。
【時系列】広告効果をモデリングする ~その7 周期性をモデル化~ [時系列解析 / 需要予測]
ARIMAモデルとかだと、元系列をトレンド+季節成分+不規則変動に分けたりします。
状態空間モデルも同じように周期性(季節成分)をモデル化することができます。
ポイントは、季節成分の部分。
x_seasonal[i] ~ normal(-sum(x_seasonal[(i-11):(i-1)]), sd_sea);
例えば、月別データ(周期が12か月)の場合は、
a1 + a2 + ... + a12 = ε, ε~N(0, σ2)
と周期成分の合計が0になるように書くことができ、
a1 = -Σ(a2 + ... + a12)
となっています。
■ rのコード
■ stanファイル
状態空間モデルも同じように周期性(季節成分)をモデル化することができます。
ポイントは、季節成分の部分。
x_seasonal[i] ~ normal(-sum(x_seasonal[(i-11):(i-1)]), sd_sea);
例えば、月別データ(周期が12か月)の場合は、
a1 + a2 + ... + a12 = ε, ε~N(0, σ2)
と周期成分の合計が0になるように書くことができ、
a1 = -Σ(a2 + ... + a12)
となっています。
■ rのコード
AirPassengers <- c(112, 118, 132, 129, 121, 135, 148, 148, 136, 119, 104, 118,
115, 126, 141, 135, 125, 149, 170, 170, 158, 133, 114, 140,
145, 150, 178, 163, 172, 178, 199, 199, 184, 162, 146, 166,
171, 180, 193, 181, 183, 218, 230, 242, 209, 191, 172, 194,
196, 196, 236, 235, 229, 243, 264, 272, 237, 211, 180, 201,
204, 188, 235, 227, 234, 264, 302, 293, 259, 229, 203, 229,
242, 233, 267, 269, 270, 315, 364, 347, 312, 274, 237, 278,
284, 277, 317, 313, 318, 374, 413, 405, 355, 306, 271, 306,
315, 301, 356, 348, 355, 422, 465, 467, 404, 347, 305, 336,
340, 318, 362, 348, 363, 435, 491, 505, 404, 359, 310, 337,
360, 342, 406, 396, 420, 472, 548, 559, 463, 407, 362, 405,
417, 391, 419, 461, 472, 535, 622, 606, 508, 461, 390, 432)
head(AirPassengers, 10)
ts.plot(log(AirPassengers), type="o", ylab="AirPassengers")
# データの準備
data_list <- list(
y = log(AirPassengers),
T = length(AirPassengers)
)
# モデルの推定
seasonal_model <- stan(
file = "D:\\Projects\\LM\\arima\\seasonal_model_1.stan",
data = data_list,
chains = 3,
seed = 1234
)
■ stanファイル
data {
int T; // データ取得期間の長さ
vector[T] y; // 観測値
}
parameters {
vector[T] mu; // 水準成分の推定値(過程誤差)
vector[T] x_seasonal; // 季節成分の推定値(過程誤差)
real sd_mu; // 水準成分の標準偏差(過程誤差)
real sd_sea; // 季節成分の標準偏差(過程誤差)
real sd_v; // 観測誤差の標準偏差
}
transformed parameters {
vector[T] alpha;
for (i in 1:T) {
alpha[i] = mu[i] + x_seasonal[i];
}
}
model {
// 水準成分
for(i in 3:T) {
mu[i] ~ normal(2*mu[i-1] - mu[i-2], sd_mu);
}
// 季節成分
for(i in 12:T) {
x_seasonal[i] ~ normal(-sum(x_seasonal[(i-11):(i-1)]), sd_sea);
}
// 観測モデル
for(i in 1:T) {
y[i] ~ normal(alpha[i], sd_v);
}
}
【時系列】広告効果をモデリングする ~その6 広告効果が時間とともに変動~ [時系列解析 / 需要予測]
広告のありなしで時系列にどのような影響を与えるかモデルかしたいのですが、広告効果はいずれの期間も一定と考えるのか、広告効果も時間とともに変動すると考えるのか。
広告効果はいずれの期間も一定
https://skellington.blog.ss-blog.jp/2020-11-01
↑
こちらの続き。
広告効果が時間とともに変動するとのことなので、
reg_mean[i] = mu[i] + b*x_cm[i]
⇒ reg_mean[i] = mu[i] + b[i] * x_cm[i];
このように時変係数(広告効果)をベクトル化して書いておきます。
広告効果はいずれの期間も一定
https://skellington.blog.ss-blog.jp/2020-11-01
↑
こちらの続き。
広告効果が時間とともに変動するとのことなので、
reg_mean[i] = mu[i] + b*x_cm[i]
⇒ reg_mean[i] = mu[i] + b[i] * x_cm[i];
このように時変係数(広告効果)をベクトル化して書いておきます。
data {
int T; // データ取得期間の長さ
vector[T] y; // 観測値
vector[T] x_cm; // 説明変数
}
parameters {
vector[T] mu; // 状態の推定値(水準成分)
vector[T] b; // 時変係数の推定値
real s_w; // 過程誤差の標準偏差
real s_t; // 時変形数の標準偏差
real s_v; // 観測誤差の標準偏差
}
transformed parameters{
vector[T] reg_mean;
for(i in 1:T){
reg_mean[i] = mu[i] + b[i] * x_cm[i];
}
}
model {
// 状態方程式に従い、状態が遷移する
for(i in 2:T) {
mu[i] ~ normal(mu[i-1], s_w);
b[i] ~ normal(b[i-1], s_t);
}
// 観測方程式に従い、観測値が得られる
for(i in 1:T) {
y[i] ~ normal(reg_mean[i], s_v);
}
}
【時系列】広告効果をモデリングする ~その5 外生変数を入れる(広告効果が一定)~ [時系列解析 / 需要予測]
広告のありなしで時系列にどのような影響を与えるかモデルかしたいのですが、広告効果はいずれの期間も一定と考えるのか、広告効果も時間とともに変動すると考えるのか。
まずは、話を簡単にするために「広告効果はいずれの期間も一定」とします。
reg_mean[i] = mu[i] + b*x_cm[i]
↑
この部分ですが、bは固定のパラメータを与えることで推定できるのですが、実際は、時間とともに水準も変化するし、広告効果も変動していると考えた方が状態空間モデルっぽい書き方かと思います。
まずは、話を簡単にするために「広告効果はいずれの期間も一定」とします。
reg_mean[i] = mu[i] + b*x_cm[i]
↑
この部分ですが、bは固定のパラメータを与えることで推定できるのですが、実際は、時間とともに水準も変化するし、広告効果も変動していると考えた方が状態空間モデルっぽい書き方かと思います。
data {
int T; // データ取得期間の長さ
vector[T] y; // 観測値
vector[T] x_cm; // 説明変数
}
parameters {
vector[T] mu; // 状態の推定値(水準成分)
real b; //
real s_w; // 過程誤差の標準偏差
real s_v; // 観測誤差の標準偏差
}
transformed parameters{
vector[T] reg_mean;
for(i in 1:T){
reg_mean[i] = mu[i] + b*x_cm[i];
}
}
model {
for(i in 2:T) {
mu[i] ~ normal(mu[i-1], s_w);
}
for(i in 1:T) {
y[i] ~ normal(reg_mean[i], s_v);
}
}
【時系列】広告効果をモデリングする ~その4 ローカルレベルモデル~ [時系列解析 / 需要予測]
久々に時系列の話。
広告効果をモデリングする手法は、簡単に線形回帰モデルなどを使って対処する方法もあるのですが、何かと問題がありました。
そこで王道となる状態空間モデルを使って広告効果をモデリングしてみようと思います。
まずは、ツールの話から。
■ dlm、KFASパッケージを利用
線形モデルで、誤差に正規ホワイトノイズを仮定する場合に使うことができます。
動的線形モデル(Dynamic Linear Model)と呼ばれています。
⇒ 最尤推定+カルマンフィルタによる方法
1)最尤法によるモデルパラメータの推定
2)カルマンフィルタによる予測
■ Stanを利用
非線形なモデルや、正規分布以外の分布を扱う場合に使うことができます。
⇒ ベイズ推定(MCMC法)による方法
MCMCにより、モデルパラメータ分布と予測分布を推定
個人的には、ちょっとstanのコードを書くのが面倒なのですが、覚えてしまえば色々なモデルを解くことができるstanがおススメです。
状態空間モデルは様々なモデルがあるのですが、まずは、一番シンプルなローカルレベルモデルを適用するとどうなるか見てみたいと思います。
ローカルレベルモデルは、ランダムウォーク・プラス・ノイズとも呼ばれ、トレンドや季節性が見られない系列に用いることができます。
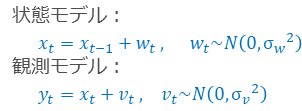
広告効果をモデリングする手法は、簡単に線形回帰モデルなどを使って対処する方法もあるのですが、何かと問題がありました。
そこで王道となる状態空間モデルを使って広告効果をモデリングしてみようと思います。
まずは、ツールの話から。
■ dlm、KFASパッケージを利用
線形モデルで、誤差に正規ホワイトノイズを仮定する場合に使うことができます。
動的線形モデル(Dynamic Linear Model)と呼ばれています。
⇒ 最尤推定+カルマンフィルタによる方法
1)最尤法によるモデルパラメータの推定
2)カルマンフィルタによる予測
■ Stanを利用
非線形なモデルや、正規分布以外の分布を扱う場合に使うことができます。
⇒ ベイズ推定(MCMC法)による方法
MCMCにより、モデルパラメータ分布と予測分布を推定
個人的には、ちょっとstanのコードを書くのが面倒なのですが、覚えてしまえば色々なモデルを解くことができるstanがおススメです。
状態空間モデルは様々なモデルがあるのですが、まずは、一番シンプルなローカルレベルモデルを適用するとどうなるか見てみたいと思います。
ローカルレベルモデルは、ランダムウォーク・プラス・ノイズとも呼ばれ、トレンドや季節性が見られない系列に用いることができます。
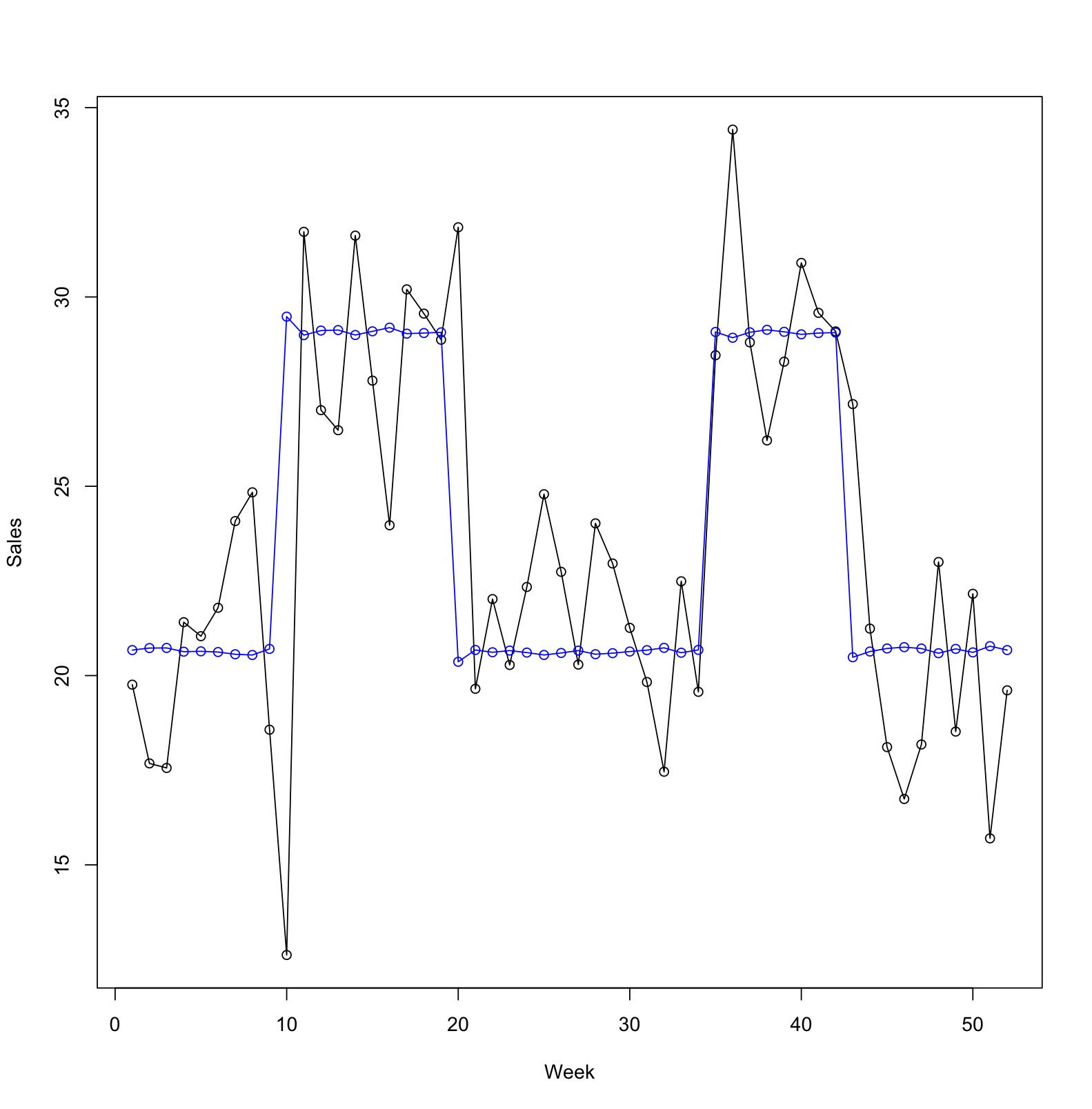
【時系列】広告効果をモデリングする 〜その3 線形回帰モデルにラグを入れる〜 [時系列解析 / 需要予測]
本来は状態空間モデルを使ってベースラインの状態を推定するのが正しいアプローチだと思うのですが、線形回帰モデルでどこまでできるかやってみたいと思います。
シンプルな線形回帰モデルに1日前の売上を説明変数にしてモデルを作ります。
y(Sales) = b0 + b1 * x(CM) + b2 * Sales_1day + ε
この意味としては、
・売上の状態(ベースライン)は少しずつ変化していく
・その状態を観測することはできない
・今日の状態は昨日の状態に近いだろう
という思想になっています。
結果を見て気がついたのですが、このモデルだと上手くベースラインを見つけられません。
まず、lag_Salesのp値が1に近いです。
このことは、1日前の売上が分かったからと言って、今日の売上を説明する力は弱いとなっています。
また、係数の値も他と比べて小さく影響は少なそうです。
実測値と予測値のプロットを描いても、ラグを入れないシンプルな線形回帰モデルと大差はありませんね。
〜過去の記事〜
【時系列】広告効果をモデリングする
その1 ABテスト(t検定)
https://skellington.blog.ss-blog.jp/2020-07-20
その2 簡単な線形回帰モデル
https://skellington.blog.ss-blog.jp/2020-07-21
シンプルな線形回帰モデルに1日前の売上を説明変数にしてモデルを作ります。
y(Sales) = b0 + b1 * x(CM) + b2 * Sales_1day + ε
この意味としては、
・売上の状態(ベースライン)は少しずつ変化していく
・その状態を観測することはできない
・今日の状態は昨日の状態に近いだろう
という思想になっています。
# 1日前の売上データを作成する
df_sales <- data.frame(Sales, lag_Sales=lag(Sales), CM)
df_sales <- df_sales[-1,] # 1行目のNAを除外する
# y(Sales) = b0 + b1 * x(CM) + b2 * Sales_1day + ε
model.lm2 <- lm(Sales ~ CM + lag_Sales, data=df_sales)
summary(model.lm2)
dat_predict2 <- predict(model.lm2)
ts.plot(cbind(Sales, dat_predict2), type="o",
col=c("black","blue"), xlab="Week", ylab="Sales")
Call:
lm(formula = Sales ~ CM + lag_Sales, data = df_sales)
Residuals:
Min 1Q Median 3Q Max
-8.0836 -1.9773 0.0437 1.7893 7.7820
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 21.1791 2.4207 8.749 1.66e-11 ***
CM 8.6245 1.1534 7.478 1.37e-09 ***
lag_Sales -0.0256 0.1117 -0.229 0.82
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.927 on 48 degrees of freedom
Multiple R-squared: 0.6691, Adjusted R-squared: 0.6554
F-statistic: 48.54 on 2 and 48 DF, p-value: 2.961e-12
結果を見て気がついたのですが、このモデルだと上手くベースラインを見つけられません。
まず、lag_Salesのp値が1に近いです。
このことは、1日前の売上が分かったからと言って、今日の売上を説明する力は弱いとなっています。
また、係数の値も他と比べて小さく影響は少なそうです。
実測値と予測値のプロットを描いても、ラグを入れないシンプルな線形回帰モデルと大差はありませんね。
〜過去の記事〜
【時系列】広告効果をモデリングする
その1 ABテスト(t検定)
https://skellington.blog.ss-blog.jp/2020-07-20
その2 簡単な線形回帰モデル
https://skellington.blog.ss-blog.jp/2020-07-21
【時系列】広告効果をモデリングする 〜その2 簡単な線形回帰モデル〜 [時系列解析 / 需要予測]
シンプルに線形回帰モデルとして、
y(Sales) = b0 + b1 * x(CM) + ε
というモデルを作ってみるとどうなるか?
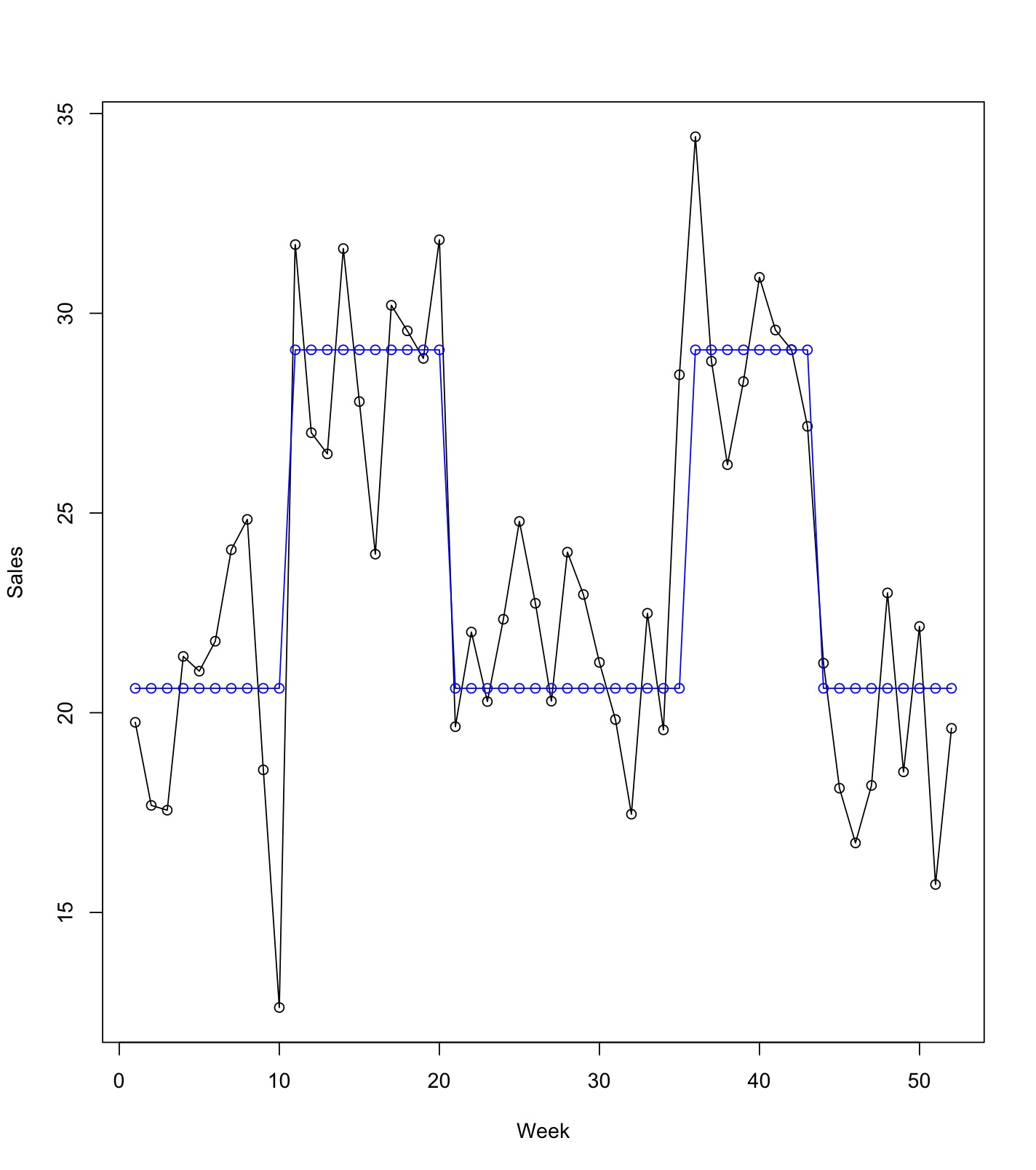
実測値と予測値をプロットしてみると単純な線形回帰モデルの限界が見えてきます。
目的変数(y:売上)のベースラインが少しずつ上がったり下がってりしているのですが、
線形回帰モデル
y(Sales) = b0 + b1 * x(CM) + ε
ベースライン(切片)は、どの時点でも b0 で与えられるため一定値となっています。
このベースライン(状態)を上手くモデルの中に取り入れるにはどうすれば良いかを考える必要がありそうですね。
〜過去の記事〜
【時系列】広告効果をモデリングする
その1 ABテスト(t検定)
https://skellington.blog.ss-blog.jp/2020-07-20
y(Sales) = b0 + b1 * x(CM) + ε
というモデルを作ってみるとどうなるか?
model.lm <- lm(Sales ~ CM)
summary(model.lm)
Call:
lm(formula = Sales ~ CM)
Residuals:
Min 1Q Median 3Q Max
-7.9909 -2.0493 -0.1044 1.8314 7.8491
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.6109 0.4925 41.85 < 2e-16 ***
CM 8.4736 0.8371 10.12 1.07e-13 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.872 on 50 degrees of freedom
Multiple R-squared: 0.672, Adjusted R-squared: 0.6655
F-statistic: 102.5 on 1 and 50 DF, p-value: 1.068e-13
# 実測値と予測値を重ねる
dat_predict <- predict(model.lm)
ts.plot(cbind(Sales, dat_predict), type="o",
col=c("black","blue"), xlab="Week", ylab="Sales")
実測値と予測値をプロットしてみると単純な線形回帰モデルの限界が見えてきます。
目的変数(y:売上)のベースラインが少しずつ上がったり下がってりしているのですが、
線形回帰モデル
y(Sales) = b0 + b1 * x(CM) + ε
ベースライン(切片)は、どの時点でも b0 で与えられるため一定値となっています。
このベースライン(状態)を上手くモデルの中に取り入れるにはどうすれば良いかを考える必要がありそうですね。
〜過去の記事〜
【時系列】広告効果をモデリングする
その1 ABテスト(t検定)
https://skellington.blog.ss-blog.jp/2020-07-20
【時系列】広告効果をモデリングする 〜その1 ABテスト(t検定)〜 [時系列解析 / 需要予測]
まずはサンプルデータの作成から。
まずは、時系列データということを無視して、CMの期間の有無でt検定をやってみます。
CMの有無でABテストをしているイメージです。
p値は、1.531e-13となっており、非常に小さいですね。
なので、広告の有無で、統計的には差がありそうだということがわかります。
#データの準備
#売上データ
Sales <- c(19.76, 17.68, 17.56, 21.41, 21.04, 21.79, 24.08, 24.84, 18.57, 12.62,
31.72, 27.01, 26.48, 31.62, 27.79, 23.97, 30.20, 29.56, 28.87, 31.84,
19.65, 22.02, 20.28, 22.34, 24.79, 22.74, 20.29, 24.02, 22.96, 21.26,
19.83, 17.46, 22.49, 19.57, 28.46, 34.42, 28.80, 26.21, 28.29, 30.90,
29.58, 29.09, 27.17, 21.24, 18.11, 16.74, 18.18, 23.00, 18.52, 22.16,
15.70, 19.61)
#広告データ(キャンペーンデータ)
CM <- c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0)
# CMあり/なし期間別の統計量
# CMあり期間はSalesが高くなる
by(Sales, INDICES=CM, FUN=summary)
ts.plot(Sales, type="o", ylab="Sales")
まずは、時系列データということを無視して、CMの期間の有無でt検定をやってみます。
CMの有無でABテストをしているイメージです。
t.test(Sales ~ CM)
Welch Two Sample t-test
data: Sales by CM
t = -10.765, df = 41.172, p-value = 1.531e-13
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-10.063060 -6.884064
sample estimates:
mean in group 0 mean in group 1
20.61088 29.08444
p値は、1.531e-13となっており、非常に小さいですね。
なので、広告の有無で、統計的には差がありそうだということがわかります。
VARモデルとGranger因果性の検定 [時系列解析 / 需要予測]
コロナウィルスの影響で世界的な株安になっています。
日本、ヨーロッパ、アメリカの株価がそれぞれどのように影響しているのかを、「Granger因果性の検定」を使って分析しました。
割とそれっぽい結果が出ています。
~まとめ~
jpの株式収益率は、uk, usに対してGranger因果の意味で影響を及ぼしているとはいえない
ukの株式収益率は、jp, usに対してGranger因果の意味で影響を及ぼしている
usの株式収益率は、jp, ukに対してGranger因果の意味で影響を及ぼしている
日本、ヨーロッパ、アメリカの株価がそれぞれどのように影響しているのかを、「Granger因果性の検定」を使って分析しました。
割とそれっぽい結果が出ています。
~まとめ~
jpの株式収益率は、uk, usに対してGranger因果の意味で影響を及ぼしているとはいえない
ukの株式収益率は、jp, usに対してGranger因果の意味で影響を及ぼしている
usの株式収益率は、jp, ukに対してGranger因果の意味で影響を及ぼしている
弱定常と強定常 [時系列解析 / 需要予測]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
時系列分析で、出てくる、"定常"とは?
定常は、弱定常と強定常があります。
cの条件は、
・任意の時点で、期待値(平均値)が同じ
・任意の時点で、分散が同じ
・任意の時点で、共分散が同じ
です。
強定常は、さらに条件が厳しく、弱定常の条件に加えて
・任意の時点で、確率分布も同じ
の条件が必要になります。
# トレンドがのっていないホワイトノイズの生成
# 正規分布から発生させた乱数(正規ホワイトノイズ)
# 時系列 x を100個作成
x <- rnorm(100)
トレンドがのっていないホワイトノイズの時系列 x は、
・任意の時点で、期待値(平均値)が同じ
・任意の時点で、分散が同じ
・任意の時点で、共分散が同じ
に加えて、
・任意の時点で、確率分布が正規分布
といえるので、強定常の時系列といえます。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
時系列分析で、出てくる、"定常"とは?
定常は、弱定常と強定常があります。
cの条件は、
・任意の時点で、期待値(平均値)が同じ
・任意の時点で、分散が同じ
・任意の時点で、共分散が同じ
です。
強定常は、さらに条件が厳しく、弱定常の条件に加えて
・任意の時点で、確率分布も同じ
の条件が必要になります。
# トレンドがのっていないホワイトノイズの生成
# 正規分布から発生させた乱数(正規ホワイトノイズ)
# 時系列 x を100個作成
x <- rnorm(100)
トレンドがのっていないホワイトノイズの時系列 x は、
・任意の時点で、期待値(平均値)が同じ
・任意の時点で、分散が同じ
・任意の時点で、共分散が同じ
に加えて、
・任意の時点で、確率分布が正規分布
といえるので、強定常の時系列といえます。
基礎からわかる時系列分析 [時系列解析 / 需要予測]
")
基礎からわかる時系列分析 ―Rで実践するカルマンフィルタ・MCMC・粒子フィルター (Data Science Library)
- 作者: 萩原 淳一郎
- 出版社/メーカー: 技術評論社
- 発売日: 2018/03/23
- メディア: 大型本
自分の勉強用に購入しました。
理論的な説明だけでなく、Rのコードも載っているので参考になりますね。
時系列解析 季節調整済みARIMAモデルを推定 その2 [時系列解析 / 需要予測]
時系列解析 季節調整済みARIMAモデルを推定
http://skellington.blog.so-net.ne.jp/2018-02-19
↑
同じようなアプローチをSPSS Modelerを使って行っていきます。
データは、RのAirPassengersのデータを使います。
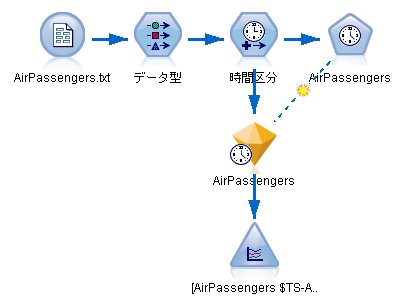
【時間区分】ノードの設定
時間区分:月数
年月のラベル:1949年1月に設定
将来への拡張:12か月分を予測
【時系列(モデル)】ノードの設定
今回のデータは、
・エキスパートモデラー
・ARIMA(0,1,1)(0,1,1)
のどちらも同じ結果となりました。
自動モデリング(エキスパートモデラー)ではなく、手動で行う場合は、下図となります。
対象の時系列の変換で、"自然対数"に設定しておきます。
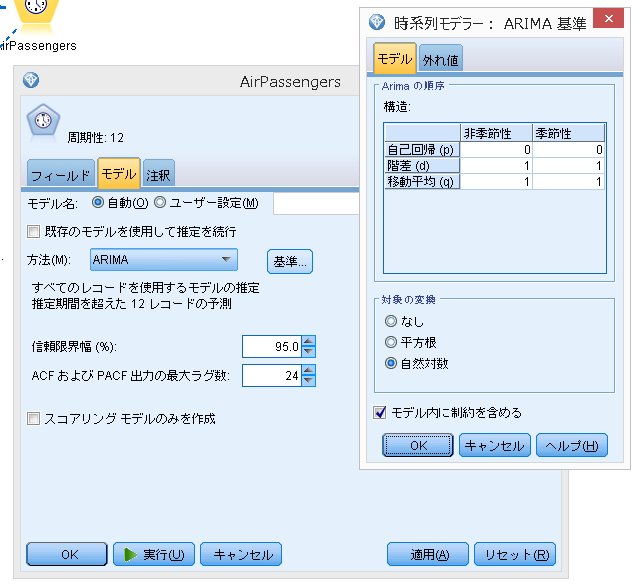
後は、モデルを作成し終了。
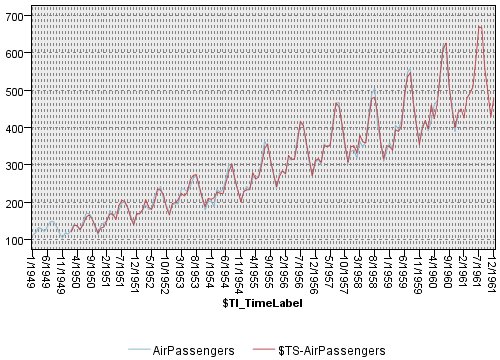
出力結果(将来の予測)を確認すると、Rのパッケージで予測したものとほとんど同じ値になっていました。
http://skellington.blog.so-net.ne.jp/2018-02-19
↑
同じようなアプローチをSPSS Modelerを使って行っていきます。
データは、RのAirPassengersのデータを使います。
【時間区分】ノードの設定
時間区分:月数
年月のラベル:1949年1月に設定
将来への拡張:12か月分を予測
【時系列(モデル)】ノードの設定
今回のデータは、
・エキスパートモデラー
・ARIMA(0,1,1)(0,1,1)
のどちらも同じ結果となりました。
自動モデリング(エキスパートモデラー)ではなく、手動で行う場合は、下図となります。
対象の時系列の変換で、"自然対数"に設定しておきます。
後は、モデルを作成し終了。
出力結果(将来の予測)を確認すると、Rのパッケージで予測したものとほとんど同じ値になっていました。
時系列解析 季節調整済みARIMAモデルを推定 [時系列解析 / 需要予測]
Rのパッケージをインストールするとついてくる有名な時系列のデータAirPassengersがあります。
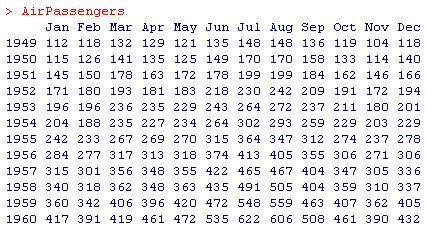
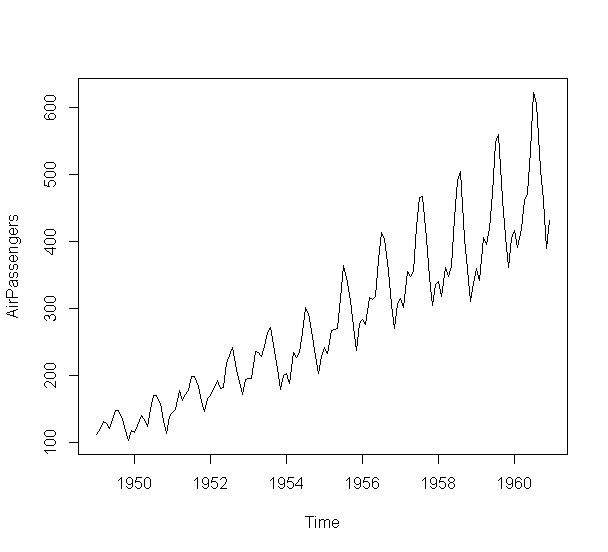
このような時系列データは、企業の売上データとしてよく見るかと思います。
特徴としては、
・はっきりとした季節性がみられる
・時間とともに売上や人数といった(平均値)が大きくなる
・時間とともに売上や人数といった(分散)が大きくなる
となっています。
時系列においては、定常か非定常かがとても重要で、このデータは明らかに非定常の時系列となっています。
このようなデータを季節調整済みARIMA(SARIMA)を使って時系列分析を行っていきます。
SPSS ModelerにもARIMAが実装されているので、同様のアプローチで分析が可能です。
この様な時系列データを分析する手順としては、
1. logで置換
2. 自己相関と偏相関を確認する
3. 階差を取って、自己相関と偏相関を確認する
4. 季節階差を取って、自己相関と偏相関を確認する
5. SARIMA(0,1,1)(0,1,1)でフィッティング
6. 予測をする
となります。
SARIMA(0,1,1)(0,1,1)は別名、エアラインモデルとも呼ばれているそうです。
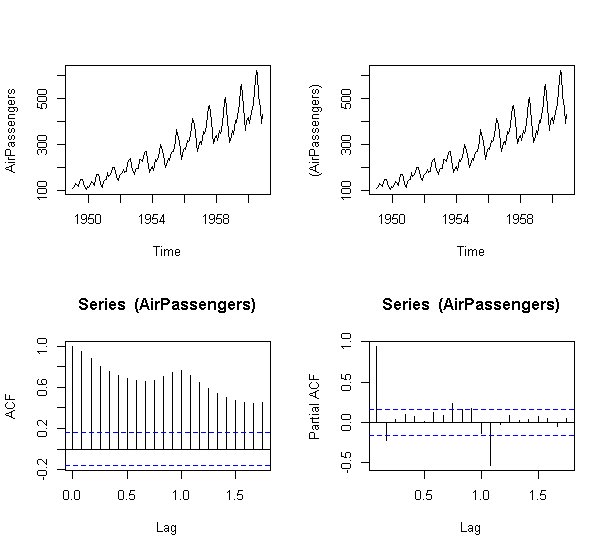
左上:元の時系列
右上:元の時系列のlogを取ったもの
左下:自己相関
右下:偏自己相関
自己相関を見ると、1期前,2期前,3期前,・・・,n期前の情報がダラダラと残っていることがわかります。
偏相関を見ると、ちょうど1年前の相関がありますが、それ以外の相関は消えていることが分かります。
acfのオプション type="partial" で偏自己相関をプロットできます。
オプション一覧はこちら。
type="correlation" :自己相関(デフォルト)
type="covariance":自己共分散
type="partial":偏相関

data(AirPassengers)
plot(AirPassengers)
このような時系列データは、企業の売上データとしてよく見るかと思います。
特徴としては、
・はっきりとした季節性がみられる
・時間とともに売上や人数といった(平均値)が大きくなる
・時間とともに売上や人数といった(分散)が大きくなる
となっています。
時系列においては、定常か非定常かがとても重要で、このデータは明らかに非定常の時系列となっています。
このようなデータを季節調整済みARIMA(SARIMA)を使って時系列分析を行っていきます。
SPSS ModelerにもARIMAが実装されているので、同様のアプローチで分析が可能です。
この様な時系列データを分析する手順としては、
1. logで置換
2. 自己相関と偏相関を確認する
3. 階差を取って、自己相関と偏相関を確認する
4. 季節階差を取って、自己相関と偏相関を確認する
5. SARIMA(0,1,1)(0,1,1)でフィッティング
6. 予測をする
となります。
SARIMA(0,1,1)(0,1,1)は別名、エアラインモデルとも呼ばれているそうです。
## 1. logで置換
## 2. 自己相関と偏相関を確認する
par(mfrow=c(2,2))
plot(AirPassengers)
plot(log(AirPassengers))
acf(log(AirPassengers))
acf(log(AirPassengers),type="partial")
airline <- log(AirPassengers)
左上:元の時系列
右上:元の時系列のlogを取ったもの
左下:自己相関
右下:偏自己相関
自己相関を見ると、1期前,2期前,3期前,・・・,n期前の情報がダラダラと残っていることがわかります。
偏相関を見ると、ちょうど1年前の相関がありますが、それ以外の相関は消えていることが分かります。
acfのオプション type="partial" で偏自己相関をプロットできます。
オプション一覧はこちら。
type="correlation" :自己相関(デフォルト)
type="covariance":自己共分散
type="partial":偏相関
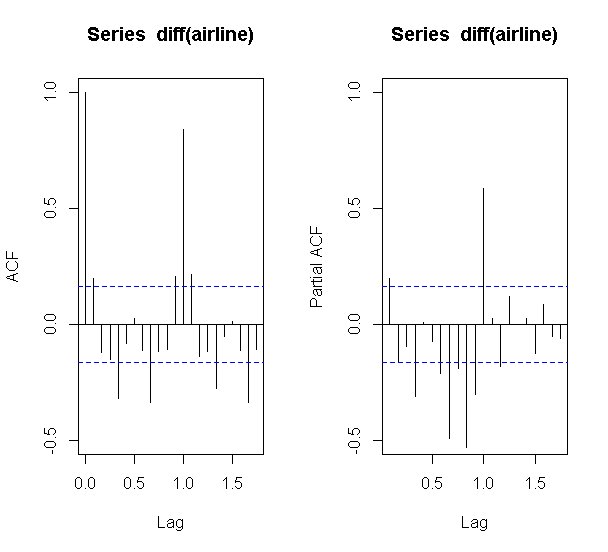
## 3. 階差を取って、自己相関と偏相関を確認する
par(mfrow=c(1,2))
acf(diff(airline),ylim=c(-0.5,1.0))
acf(diff(airline),type="partial", ylim=c(-0.5,1.0))
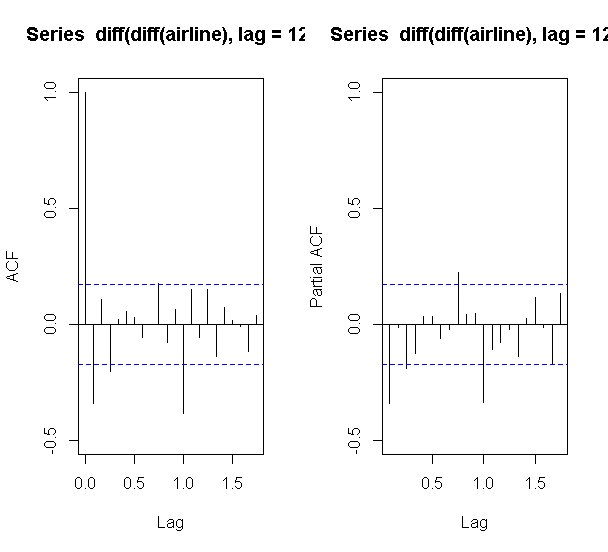
## 4. 季節階差を取って、自己相関と偏相関を確認する
par(mfrow=c(1,2))
acf(diff(diff(airline),lag=12),ylim=c(-0.5,1.0))
acf(diff(diff(airline),lag=12),type="partial", ylim=c(-0.5,1.0))
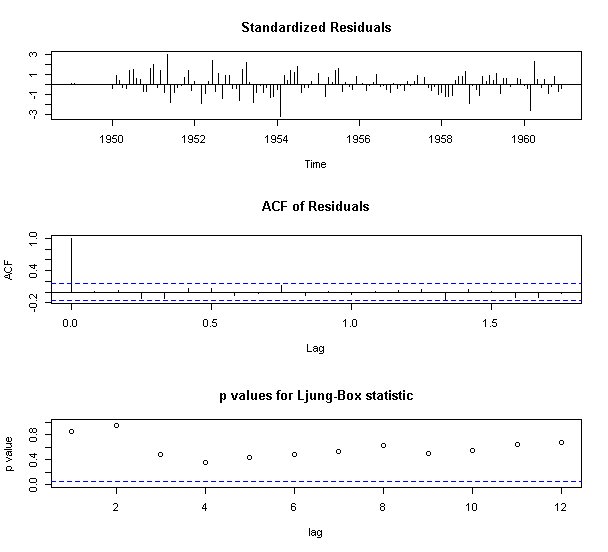
## 5. SARIMA(0,1,1)(0,1,1)でフィッティング
fit <- arima(airline, order=c(0,1,1), seasonal=list(order=c(0,1,1),period=12))
tsdiag(fit, gof.lag=12)
## 6. 予測をする
predict(fit, n.ahead=12)
時系列解析 TSSS [時系列解析 / 需要予測]
統計数理研究所の公開講座「時系列解析入門」に行ってきました。
講座の中で、時系列解析をするRのパッケージTSSSの紹介がありました。
WindowsとLinuxには対応しているようですが、Mac OCには対応していないとのこと。
インストール手順
1. R package TSSS - 統計数理研究所
http://jasp.ism.ac.jp/ism/TSSS/
2. バイナリファイル TSSS_xxx.zip を適当なフォルダにダウンロード
3. パッケージをインストールする。
実際に、インストールしたTSSSを使うときは、
library(TSSS)
で使うことができます。
講座の中で、時系列解析をするRのパッケージTSSSの紹介がありました。
WindowsとLinuxには対応しているようですが、Mac OCには対応していないとのこと。
インストール手順
1. R package TSSS - 統計数理研究所
http://jasp.ism.ac.jp/ism/TSSS/
2. バイナリファイル TSSS_xxx.zip を適当なフォルダにダウンロード
3. パッケージをインストールする。
実際に、インストールしたTSSSを使うときは、
library(TSSS)
で使うことができます。
【SPSS Datathon】日本科学未来館 未来館ホールで発表 [時系列解析 / 需要予測]
SPSS Datathon - 研究奨励賞復活!データサイエンティストへの道
http://spss-datathon.com
↑
こちらで発表してきました。
日本科学未来館は、よく子供と行くところで、つい先日もここに子供と遊びに行ったばかりでした。
そんな場所での講演となると、なんだか不思議な感覚です。
発表内容は、「ビジネスにおける時系列分析」という視点で発表しました。
何かの参考になれば幸いです。
http://spss-datathon.com
↑
こちらで発表してきました。
日本科学未来館は、よく子供と行くところで、つい先日もここに子供と遊びに行ったばかりでした。
そんな場所での講演となると、なんだか不思議な感覚です。
発表内容は、「ビジネスにおける時系列分析」という視点で発表しました。
何かの参考になれば幸いです。

