アプリケーションエンジニアのためのApache Spark入門 [Hadoop / Spark]
『アプリケーションエンジニアのためのApache Spark入門』が発売され、寄贈されました。

アマゾンでベストセラーマークが付いていますね。
せっかくなので、これを機会に、Apache Sparkを触ってみたいと思います。
アプリケーションエンジニアのためのApache Spark入門
- 作者: 新郷美紀
- 出版社/メーカー: 秀和システム
- 発売日: 2018/02/17
- メディア: 単行本
アマゾンでベストセラーマークが付いていますね。
せっかくなので、これを機会に、Apache Sparkを触ってみたいと思います。
Hadoop / MapReduceの講座が無事に修了 [Hadoop / Spark]
Hadoop / MapReduceのオンライン講座ですが、無事に修了することができました。
課題が急に難しくなったり、課題の意図が分かり難く再提出をしたりと、2月~4月上旬はかなり大変でした。
業務時間+自己学習の時間を取って勉強し続けるってけっこう大変だな、って改めて思いました。
とはいえ、この手の分野って学び続ける必要があるので、引き続き4月以降も新たなチャレンジに向けて勉強時間を確保したいなって思います。
課題が急に難しくなったり、課題の意図が分かり難く再提出をしたりと、2月~4月上旬はかなり大変でした。
業務時間+自己学習の時間を取って勉強し続けるってけっこう大変だな、って改めて思いました。
とはいえ、この手の分野って学び続ける必要があるので、引き続き4月以降も新たなチャレンジに向けて勉強時間を確保したいなって思います。
【Hadoop MapReduce】プログラムを学習するスタイル [Hadoop / Spark]
HadoopのMapReduce、Pythonの考え方やプログラムを一通り学んだ後、以前買ったPython入門の本をパラパラ眺めてみた。
本を買った当初は、なるほど、と新しく覚えることがいっぱいだったのだが、改めて見てみると、ほとんど既知の知識になっていて、改めてここ1か月くらいで、ここまでスキルが向上したんだな、と感じました。
学習するスタイルとして、計算結果を書く解答の枠があるのだが、ほぼ0から自分でプログラムを書いていきます。
また、解答を書いた後も、正解のプログラムコードもなく、これで良いんだっけ?と不安な状態で最後でやり続ける必要がありました。
結果、そういう野放し状態の中で、自分独りで作り上げるしかない状況に追い込まれることが大切なのかな、って思います。
データ解析などを教えていた時も、野放し状態で放置した人と、割と手取り足取り教えた人の成長を見た時に、結果すごく伸びたなって思う人は、ほぼ野放し状態で自由に考えてもらった人でした。
もちろん、平均的な人を育成する上では、後者の方がリスクもないし、成長できる人も多いと思います。
放置プレーの場合、伸びる人は伸びるけど、挫折する人をどうフォローしていくか、ということも考えていかないといけませんが・・・。

本を買った当初は、なるほど、と新しく覚えることがいっぱいだったのだが、改めて見てみると、ほとんど既知の知識になっていて、改めてここ1か月くらいで、ここまでスキルが向上したんだな、と感じました。
学習するスタイルとして、計算結果を書く解答の枠があるのだが、ほぼ0から自分でプログラムを書いていきます。
また、解答を書いた後も、正解のプログラムコードもなく、これで良いんだっけ?と不安な状態で最後でやり続ける必要がありました。
結果、そういう野放し状態の中で、自分独りで作り上げるしかない状況に追い込まれることが大切なのかな、って思います。
データ解析などを教えていた時も、野放し状態で放置した人と、割と手取り足取り教えた人の成長を見た時に、結果すごく伸びたなって思う人は、ほぼ野放し状態で自由に考えてもらった人でした。
もちろん、平均的な人を育成する上では、後者の方がリスクもないし、成長できる人も多いと思います。
放置プレーの場合、伸びる人は伸びるけど、挫折する人をどうフォローしていくか、ということも考えていかないといけませんが・・・。
- 出版社/メーカー: 翔泳社
- 発売日: 2013/07/08
- メディア: Kindle版
【Hadoop MapReduce】配列のコピーについて [Hadoop / Spark]
Hadoopのプログラムではなく、pythonの話。
思うような結果が得られなくて、原因を色々調べていたら、どうやら配列のコピーがおかしいことが解った。
配列のコピーをうっかり
Array1 = Array0
と書いてしまったのだが、これだとArray0を操作したら、同時にArray1の値も変わってしまう。
コピーした後、Array0とArray1を別々に扱いたい場合は、
from copy import deepcopy
Array1 = deepcopy(Array0)
としてコピーをする必要がある。
思うような結果が得られなくて、原因を色々調べていたら、どうやら配列のコピーがおかしいことが解った。
配列のコピーをうっかり
Array1 = Array0
と書いてしまったのだが、これだとArray0を操作したら、同時にArray1の値も変わってしまう。
コピーした後、Array0とArray1を別々に扱いたい場合は、
from copy import deepcopy
Array1 = deepcopy(Array0)
としてコピーをする必要がある。
【Hadoop MapReduce】最終課題に向けて [Hadoop / Spark]
Hadoopの勉強もだいぶ終盤に差し掛かっていて、いよいよ最終課題を残すのみとなりました。
Hadoopが難しいというよりかは、Python特有の癖みたいなのを把握するのに苦労しました。
SPSS Modeler(Clementine)でストリームを書くと1分くらいで書けちゃう処理を、MapReduceプログラムで書くと丸々二日かかったりと。。。
それが、急に視界が開けてきて、最近では、数十分程度で書けるようになってきました。
こういうプログラムって慣れるまでが大変ですね。。。
処理を比較したら、手元のデータが小さいこともあって、SPSS Modelerの処理とHadoopの処理があんまり変わらなかったです。
むしろコードを書く時間や可読性を考えたら、SPSS Modeler最高となるわけで…
これが、SPSS Modelerで処理できないくらいのボリュームになってくると、Hadoopの意味も出てくるのかもしれません。
Hadoopが難しいというよりかは、Python特有の癖みたいなのを把握するのに苦労しました。
SPSS Modeler(Clementine)でストリームを書くと1分くらいで書けちゃう処理を、MapReduceプログラムで書くと丸々二日かかったりと。。。
それが、急に視界が開けてきて、最近では、数十分程度で書けるようになってきました。
こういうプログラムって慣れるまでが大変ですね。。。
処理を比較したら、手元のデータが小さいこともあって、SPSS Modelerの処理とHadoopの処理があんまり変わらなかったです。
むしろコードを書く時間や可読性を考えたら、SPSS Modeler最高となるわけで…
これが、SPSS Modelerで処理できないくらいのボリュームになってくると、Hadoopの意味も出てくるのかもしれません。
【Hadoop MapReduce】ファイル結合 [Hadoop / Spark]
Hadoopのジョブに対して、ジョブを実行するコマンドとして、
hs mapper.py reducer.py inputファイル outputディレクトリ
と入力する必要があります。
2つのファイルを結合する場合、ファイルを2つインプットファイルとして処理する必要があります。
その場合、ファイル名の代わりにHDFS内のディレクトリ名を与えるようです。
hs mapper.py reducer.py inputディレクトリ outputディレクトリ
Hadoopのファイル結合ですが、AとBのファイルを結合する際に
"keyid", "A", "hoge_1", ... "hoge_n"
"keyid", "b", "foo_1", ... "foo_m"
として、reducerに渡して、ソートされた状態を活かしての結合処理すればOK。
hs mapper.py reducer.py inputファイル outputディレクトリ
と入力する必要があります。
2つのファイルを結合する場合、ファイルを2つインプットファイルとして処理する必要があります。
その場合、ファイル名の代わりにHDFS内のディレクトリ名を与えるようです。
hs mapper.py reducer.py inputディレクトリ outputディレクトリ
Hadoopのファイル結合ですが、AとBのファイルを結合する際に
"keyid", "A", "hoge_1", ... "hoge_n"
"keyid", "b", "foo_1", ... "foo_m"
として、reducerに渡して、ソートされた状態を活かしての結合処理すればOK。
【Hadoop MapReduce】MapReduce Design Patterns [Hadoop / Spark]
Filtering: フィルタリングパターン
⇒ 大きなデータセットから小さなサンプルを抽出する
Summarizing: 集約パターン
⇒ 問題の本質を捉える
Structural: 構造パターン
⇒ 階層型データベースへの移行に関連している
Others...
Orgamization: データの統合
I/O:データの入出力
鉄板の参考書:Mapreduce Design Patterns

⇒ 大きなデータセットから小さなサンプルを抽出する
Summarizing: 集約パターン
⇒ 問題の本質を捉える
Structural: 構造パターン
⇒ 階層型データベースへの移行に関連している
Others...
Orgamization: データの統合
I/O:データの入出力
鉄板の参考書:Mapreduce Design Patterns
- 作者: Tom White
- 出版社/メーカー: Oreilly & Associates Inc
- 発売日: 2015/04/10
- メディア: ペーパーバック
【Hadoop MapReduce】MapReduceの処理効率を向上させる"combiners" [Hadoop / Spark]
combiners: MapReduceの処理効率を向上させるためにコンバイナを使用する
複数のMapperがデータを取得し、単一のReducerで処理をするのだが、大量のレコードをMapperがReducerに渡してしまうと、処理速度が遅くなってしまいます。
そこで、MapperとReducerの間にたちデータを処理するのがcombiners。
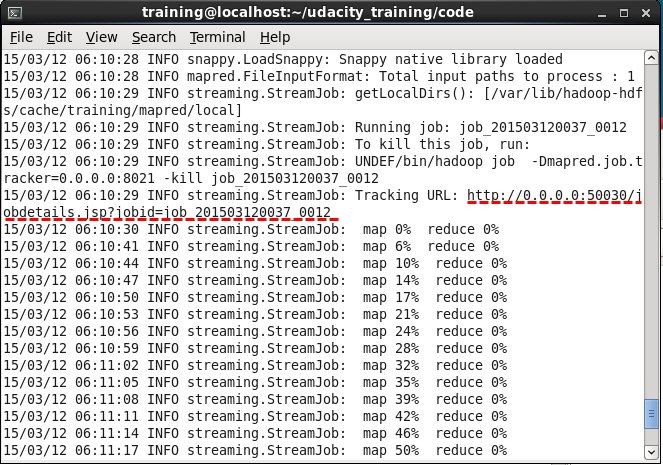
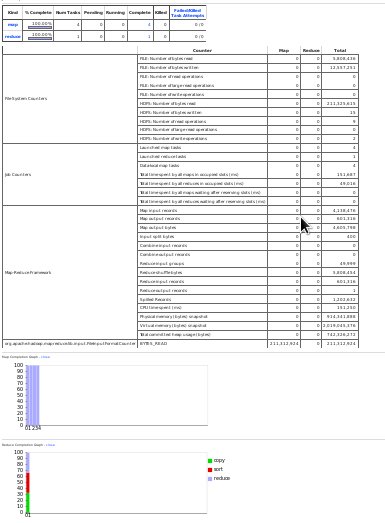
Hadoopnoのログを見ると、URLが書かれていて、そこにアクセスると、MapperやReducerがどれくらいのレコードを受け取って、どれくらいのレコードをアウトプットしたのかなどの情報が見れます。
複数のMapperがデータを取得し、単一のReducerで処理をするのだが、大量のレコードをMapperがReducerに渡してしまうと、処理速度が遅くなってしまいます。
そこで、MapperとReducerの間にたちデータを処理するのがcombiners。
Hadoopnoのログを見ると、URLが書かれていて、そこにアクセスると、MapperやReducerがどれくらいのレコードを受け取って、どれくらいのレコードをアウトプットしたのかなどの情報が見れます。
【Hadoop MapReduce】Filtering Patterns [Hadoop / Spark]
基本的な、mapperとreducerの書き方はだいたいわかったので、
MapReduce Design Patternsというものを勉強し始めました。
よく使うフィルタリング、サンプリング、集計、データ結合などの基本的な部分を理解することで、それを組み合わせ使えるようになることが目的です。
Filtering Patterns
・Simple Filter
・Bloom Filter
確率的なフィルタ
・Sampling
・Random Sampling
・Top N
MapReduce Design Patternsというものを勉強し始めました。
よく使うフィルタリング、サンプリング、集計、データ結合などの基本的な部分を理解することで、それを組み合わせ使えるようになることが目的です。
Filtering Patterns
・Simple Filter
・Bloom Filter
確率的なフィルタ
・Sampling
・Random Sampling
・Top N
【Hadoop MapReduce】ループ処理で1を足しあげる処理 [Hadoop / Spark]
※ Pythonを使って、MapperとReducerを書いています。
ループ処理をする際に、変数に1を足していく処理をする場合があります。
変数として、
numSales
を定義したとして、
ついつい、
++numSales
と書きたくなるのですが、C言語の書き方で、Pythonでは
numSales += 1
と書くとのこと。
ちょっとした方言の違いみたいなもんですかね。
ループ処理をする際に、変数に1を足していく処理をする場合があります。
変数として、
numSales
を定義したとして、
ついつい、
++numSales
と書きたくなるのですが、C言語の書き方で、Pythonでは
numSales += 1
と書くとのこと。
ちょっとした方言の違いみたいなもんですかね。
【Hadoop MapReduce】文字列とfloatの比較 [Hadoop / Spark]
Pythonを使って、MapperとReducerを書いていたのだが、初歩的なミスをいくつかしたのでその備忘録として。
文字列の大小を比較する際
salesMax = max(thisSale, salesMax)
という関数を使ったのだが、上手くmax値を集計できていませんでした。
よくよく調べてみると、
thisSaleは文字型
salesMaxは数値型でした。
驚きなのが、文字型と数値型を比較できることなのですが。。。
自分としては、文字型と数値型を比較するとエラーで比較できないと思っていたのですが、プログラムの方で良しなに(?)大小比較をしていたようで、
499.99
99.99
↑
これらを文字列として、比較すると、99.99の方が選ばれて変な結果になってしまいました。
正しく書くと、
salesMax = max(float(thisSale), salesMax)
と数値型にそろえる必要があります。
文字列の大小を比較する際
salesMax = max(thisSale, salesMax)
という関数を使ったのだが、上手くmax値を集計できていませんでした。
よくよく調べてみると、
thisSaleは文字型
salesMaxは数値型でした。
驚きなのが、文字型と数値型を比較できることなのですが。。。
自分としては、文字型と数値型を比較するとエラーで比較できないと思っていたのですが、プログラムの方で良しなに(?)大小比較をしていたようで、
499.99
99.99
↑
これらを文字列として、比較すると、99.99の方が選ばれて変な結果になってしまいました。
正しく書くと、
salesMax = max(float(thisSale), salesMax)
と数値型にそろえる必要があります。
【IBM SPSS Modeler】HadoopとMapReduceの勉強 [Hadoop / Spark]
HadoopとMapReduceの勉強。
今まで、Hadoopという名前や概念は知っていましたが、具体的な処理の内容などは分かっていなかったです。
Intro to Hadoop and MapReduce
https://www.udacity.com/course/ud617
↑
このオンライン学習を見て、実際にコードを書いたり、仮想マシンでコードを動かしたりすると、なるほど、こういうことだったのか!とよく分かりました。
実際に手を動かしてみることってすごく大切ですよね。
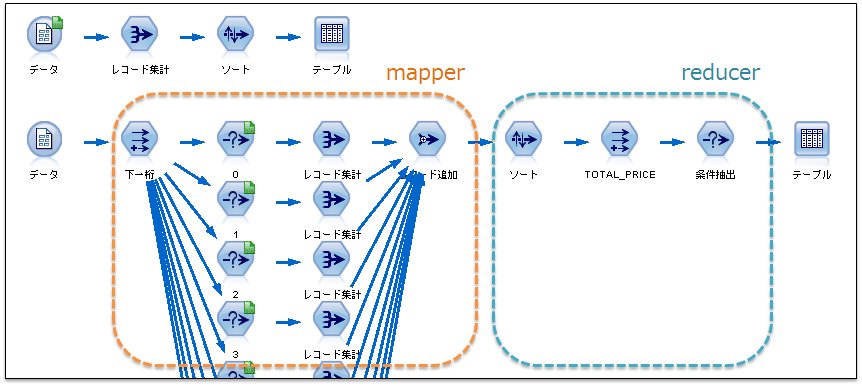
あえて、mapper.py reducer.py をIBM SPSS Modelerで書いてみました。
もちろん、MapReduceということで、分散処理ではないですし、処理時間も遅いですが。。。
今まで、Hadoopという名前や概念は知っていましたが、具体的な処理の内容などは分かっていなかったです。
Intro to Hadoop and MapReduce
https://www.udacity.com/course/ud617
↑
このオンライン学習を見て、実際にコードを書いたり、仮想マシンでコードを動かしたりすると、なるほど、こういうことだったのか!とよく分かりました。
実際に手を動かしてみることってすごく大切ですよね。
あえて、mapper.py reducer.py をIBM SPSS Modelerで書いてみました。
もちろん、MapReduceということで、分散処理ではないですし、処理時間も遅いですが。。。

