データ解析コンペ、中間発表 [データサイエンス、統計モデル]
久々のデータ解析コンペ。
中間発表の資料を慌てて作りました。
一応簡単なモデルと方針は示す予定。
今回のデータは、IDが入っていないので、追跡できない。
つまり、CRM的なことはできないので、集計されたデータをどう料理するかかなと。
時系列関連の発表が多いと予想。
自分も状態空間モデルだし。
中間発表の資料を慌てて作りました。
一応簡単なモデルと方針は示す予定。
今回のデータは、IDが入っていないので、追跡できない。
つまり、CRM的なことはできないので、集計されたデータをどう料理するかかなと。
時系列関連の発表が多いと予想。
自分も状態空間モデルだし。
日本がスペインに勝利 決勝T進出 [時事 / ニュース]
ドイツ戦もそうでしたが、、、負けると思い観ていなかった。m(_ _)m
(激しく後悔)
コスタリカに負けて、ドイツとスペインに勝つというのは、なかなか予想できるものでもない。
次は、クロアチアということで、12/6(火)にキックオフ。
Dobro
http://www.dobro.co.jp/
↑
ちなみに、八重洲にクロアチア料理のお店があるけど、なかなか美味しかったです。
(激しく後悔)
コスタリカに負けて、ドイツとスペインに勝つというのは、なかなか予想できるものでもない。
次は、クロアチアということで、12/6(火)にキックオフ。
Dobro
http://www.dobro.co.jp/
↑
ちなみに、八重洲にクロアチア料理のお店があるけど、なかなか美味しかったです。
ディズニーティンカーベルルーム [Disney / ディズニー]
ディズニーティンカーベルルーム
https://www.tokyodisneyresort.jp/hotel/tdh/room/detail/chara_tinkerbell/
スーペリアアルコーヴルーム、ということで、小さな窪みのベットがついています。
子供は、こういう秘密基地っぽいものが好きですよね。
これ以外には、引き出しタイプのベットも付いてくるので、大人数の宿泊も対応できると思います。

https://www.tokyodisneyresort.jp/hotel/tdh/room/detail/chara_tinkerbell/
スーペリアアルコーヴルーム、ということで、小さな窪みのベットがついています。
子供は、こういう秘密基地っぽいものが好きですよね。
これ以外には、引き出しタイプのベットも付いてくるので、大人数の宿泊も対応できると思います。
ディズニーホテル宿泊者特典「ハッピーエントリー」 [Disney / ディズニー]
ディズニーランドホテルの特典として、一般のゲストより15分前より入園できます。
ここで注意として、開演時間の15分前ではなく、一般のゲストより15分前ということ。
公式には9時に開園と書いていますが、実際は、一般ゲストは8時15分から、そして、「ハッピーエントリー」は8時から入れるっぽいことがSNSで発見しました。
そこで、7時30分くらいから並び始めました。
そして、予想通り8時から入ることができました。
真っ先に向かったのが、美女と野獣のアトラクション。
何度か乗っていますが、せっかくなので、朝一番で乗ることにしました。
ここで注意として、開演時間の15分前ではなく、一般のゲストより15分前ということ。
公式には9時に開園と書いていますが、実際は、一般ゲストは8時15分から、そして、「ハッピーエントリー」は8時から入れるっぽいことがSNSで発見しました。
そこで、7時30分くらいから並び始めました。
そして、予想通り8時から入ることができました。
真っ先に向かったのが、美女と野獣のアトラクション。
何度か乗っていますが、せっかくなので、朝一番で乗ることにしました。
ベッラヴィスタ・ラウンジ、スカーレットクリスマス [Disney / ディズニー]
“ディズニー・クリスマス”スペシャルディナー スカーレットクリスマス
https://www.tokyodisneyresort.jp/hotel/menu/7367/
ディナータイムは、1種類しかなく、スカーレットクリスマスというコース料理だけでした。
内容
■ モッツァレッラ トマト バジル バルサミコ
■ オマール海老とキャヴィア カンパチのサフランマリネと蕪 セルバチコとチコリ 紅心大根サルサと柚子の香り
■ ニョケッティ サルサポモドーロ 帆立貝 アーティチョーク オリーヴパウダー
または
生タリオリーニ 生ハムと季節野菜 トリュフのアクセント パルメザン
■ 金目鯛のヴァポーレ パプリカと松の実 マントヴァ風 アオリイカのフリット スカリオンオイル カラスミ
■ 和牛サーロインのビステッカ マルサラソース ビーフのインヴォルティーニ仕立て
■ 紅茶ムースと胡桃のダックワーズ リンゴソルベ
■ シェフこだわりのティラミス
■ コーヒー または 紅茶

写真は、モッツァレッラ トマト バジル バルサミコです。
マイクロトマトということで、ものすっごく小さいトマト!
びっくりするくらい小さいトマトでした。
味はしっかりしています。w
なんでも、プロメテウス火山の噴石をイメージしているとか。
ディズニーシーらしい、美味しい料理でした。
https://www.tokyodisneyresort.jp/hotel/menu/7367/
ディナータイムは、1種類しかなく、スカーレットクリスマスというコース料理だけでした。
内容
■ モッツァレッラ トマト バジル バルサミコ
■ オマール海老とキャヴィア カンパチのサフランマリネと蕪 セルバチコとチコリ 紅心大根サルサと柚子の香り
■ ニョケッティ サルサポモドーロ 帆立貝 アーティチョーク オリーヴパウダー
または
生タリオリーニ 生ハムと季節野菜 トリュフのアクセント パルメザン
■ 金目鯛のヴァポーレ パプリカと松の実 マントヴァ風 アオリイカのフリット スカリオンオイル カラスミ
■ 和牛サーロインのビステッカ マルサラソース ビーフのインヴォルティーニ仕立て
■ 紅茶ムースと胡桃のダックワーズ リンゴソルベ
■ シェフこだわりのティラミス
■ コーヒー または 紅茶
写真は、モッツァレッラ トマト バジル バルサミコです。
マイクロトマトということで、ものすっごく小さいトマト!
びっくりするくらい小さいトマトでした。
味はしっかりしています。w
なんでも、プロメテウス火山の噴石をイメージしているとか。
ディズニーシーらしい、美味しい料理でした。
ビジネスデータサイエンスの教科書 [データサイエンス、統計モデル]
メンバーにお薦めされた本。

流行りのpythonではなく、Rで書かれているのもありがたいw
- 出版社/メーカー: すばる舎
- 発売日: 2020/07/22
- メディア: 単行本
流行りのpythonではなく、Rで書かれているのもありがたいw
多重共線性の話 〜その1 一般的な問題点 [よもやま日記]
参考にした本
")
説明変数の中に相関が強い変数が含まれると両者の識別が難しくなる
・係数の標準誤差が大きくなる
・t値が小さくなる → 係数が有意になりにくくなる(※ 後で実験を行う)
・係数が理論から予想される値と大きく乖離することがある
・個別係数のt値が小さいにも関わらず、決定係数が大きくなる
・データのわずかな変動や観測期間の変更などで係数が大きく変化する
シミュレーションデータを使った実験
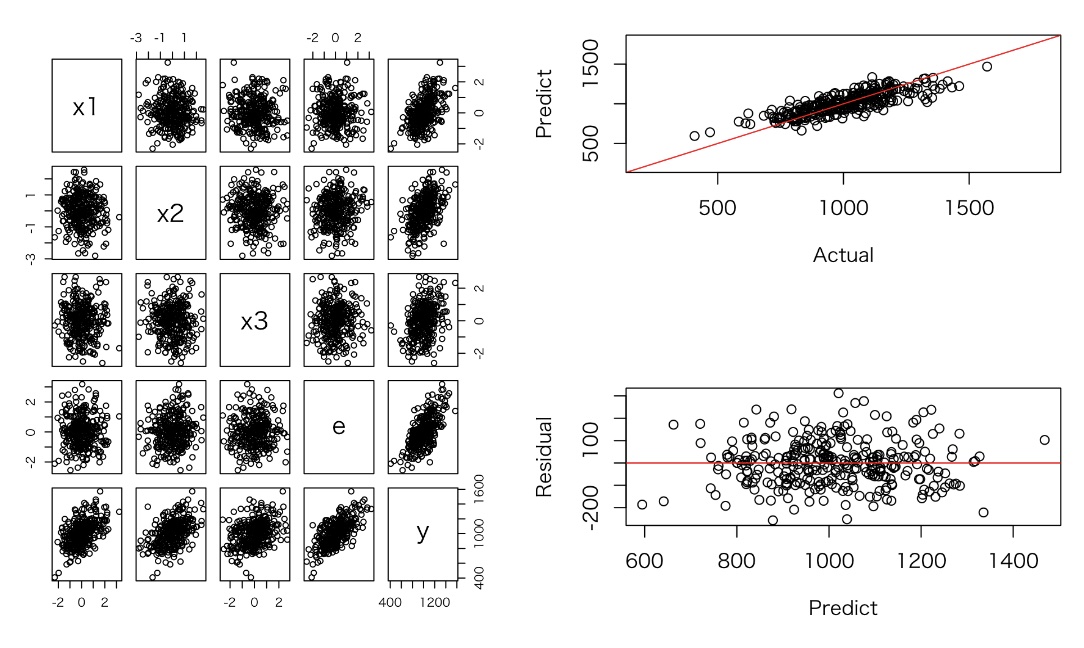
実験1: 多重共線性でない独立なデータを300レコード発生させ、回帰分析を行う
- 出版社/メーカー: 有斐閣
- 発売日: 2009/03/01
- メディア: 単行本
説明変数の中に相関が強い変数が含まれると両者の識別が難しくなる
・係数の標準誤差が大きくなる
・t値が小さくなる → 係数が有意になりにくくなる(※ 後で実験を行う)
・係数が理論から予想される値と大きく乖離することがある
・個別係数のt値が小さいにも関わらず、決定係数が大きくなる
・データのわずかな変動や観測期間の変更などで係数が大きく変化する
シミュレーションデータを使った実験
実験1: 多重共線性でない独立なデータを300レコード発生させ、回帰分析を行う
多重共線性の話 〜その2 一般的な問題点 [データサイエンス、統計モデル]
回帰係数は、シミュレーション結果と異なるが、予測結果は問題ない。
多重共線性が起こっているx1, x2において、係数の標準誤差が大きくなっている(t値が小さくなる)ことが確認できる。
x1とx2間に強い線形の関係が見られる。
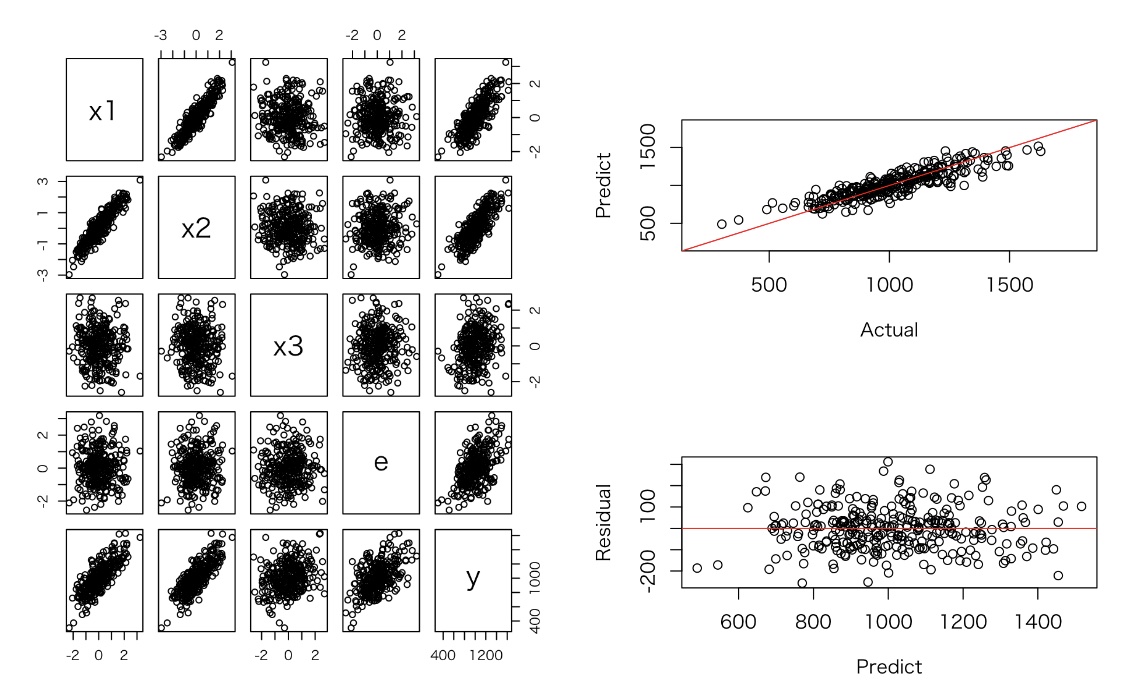
x1, x2, x3のいくつかの変数を使ったモデルを作成し、R2やAICの比較を行った。
多重共線性が起こっているx1, x2において、係数の標準誤差が大きくなっている(t値が小さくなる)ことが確認できる。
x1とx2間に強い線形の関係が見られる。
x1, x2, x3のいくつかの変数を使ったモデルを作成し、R2やAICの比較を行った。
> vif(res_123)
x1 x2 x3
6.453802 6.462609 1.003874
> vif(res_12)
x1 x2
6.450832 6.450832
> vif(res_13)
x1 x3
1.002045 1.002045
> vif(res_23)
x2 x3
1.003412 1.003412
多重共線性の話 〜その3 一般的な問題点 [データサイエンス、統計モデル]
実験3: 実験2のデータを1000回発生させ、回帰分析を行う
x1とx2の回帰係数に強い負の相関がある(x1, x2が正の相関であるため)
x1とx2の平均は、おおむね正しい結果となっている
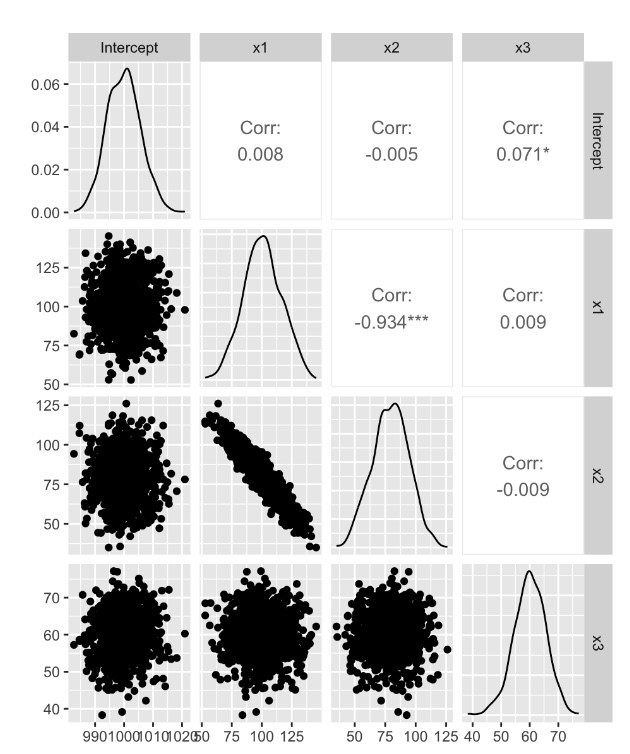
x1とx2の回帰係数に強い負の相関がある(x1, x2が正の相関であるため)
x1とx2の平均は、おおむね正しい結果となっている
多重共線性の話 〜その4 一般的な問題点 [データサイエンス、統計モデル]
実験4: 実験2のデータ数を増やし、実験3と同様のシミュレーションを行う
多重共線性の対処法
データ量を増やす
追加情報を使う(β1+β2=1)
おまじない(民間療法)
説明変数を減らす
x1, x2の相関が高い場合、x1 - x2, x2を変数にする
階差を取る
データ数を減らす
データ数を300から3000,0000に増やし、実験3と同様のシミュレーションを1000回行った
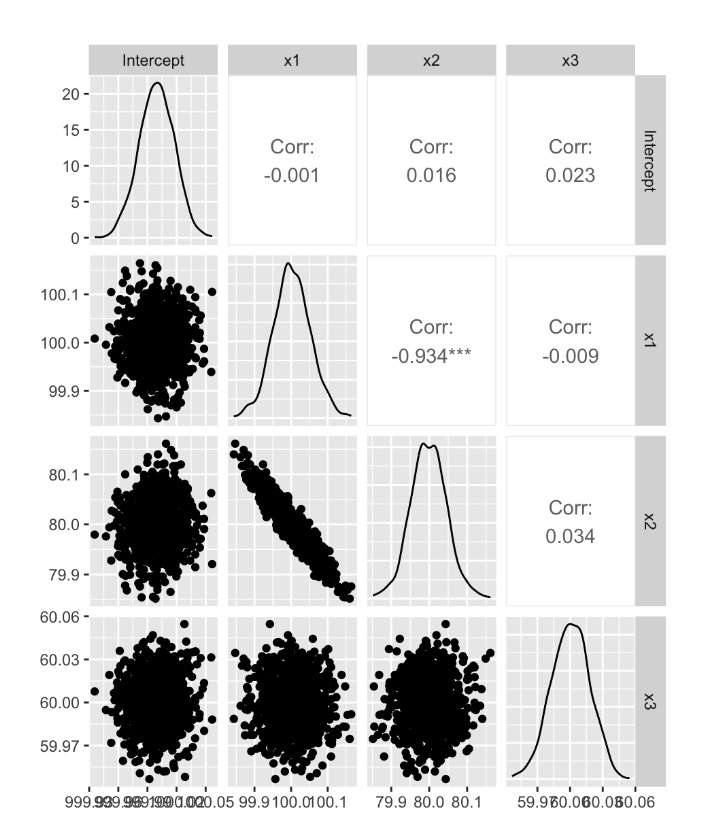
x1とx2の回帰係数の分布には相関が見られるものの、データを増やすことでx1とx2の分布はおおむねシミュレーションと同じ値になっている。
多重共線性の対処法
データ量を増やす
追加情報を使う(β1+β2=1)
おまじない(民間療法)
説明変数を減らす
x1, x2の相関が高い場合、x1 - x2, x2を変数にする
階差を取る
データ数を減らす
データ数を300から3000,0000に増やし、実験3と同様のシミュレーションを1000回行った
> summary(para)
Intercept x1 x2 x3
Min. : 999.9 Min. : 99.84 Min. :79.85 Min. :59.95
1st Qu.:1000.0 1st Qu.: 99.97 1st Qu.:79.97 1st Qu.:59.99
Median :1000.0 Median :100.00 Median :80.00 Median :60.00
Mean :1000.0 Mean :100.00 Mean :80.00 Mean :60.00
3rd Qu.:1000.0 3rd Qu.:100.03 3rd Qu.:80.03 3rd Qu.:60.01
Max. :1000.1 Max. :100.16 Max. :80.16 Max. :60.05
x1とx2の回帰係数の分布には相関が見られるものの、データを増やすことでx1とx2の分布はおおむねシミュレーションと同じ値になっている。
多重共線性の話 ~その5 多重共線性を回避する方法 [データサイエンス、統計モデル]
多重共線性を回避する方法として、いろいろな方法があるが、
ぱっと思いつくのは、lasso回帰とridge回帰かもしれません。
lassoにしろridge回帰にしろ、基本的にはデータドリブンなアプローチなので、仮説発見としては良いかもしれませんが、背景の構造が明確な場合は、想定通りの結果にならない可能性があります。
例えば、lassoは、よくスパースなデータに対しての変数選択として使われます。
ridgeも正則化をしている意味では、数学的には似ています。
多重共線性が起こっている場合、一般に逆行列が計算できない問題が発生するが、正則化を追加することにより,回帰係数が不安定になることを防いでいます。
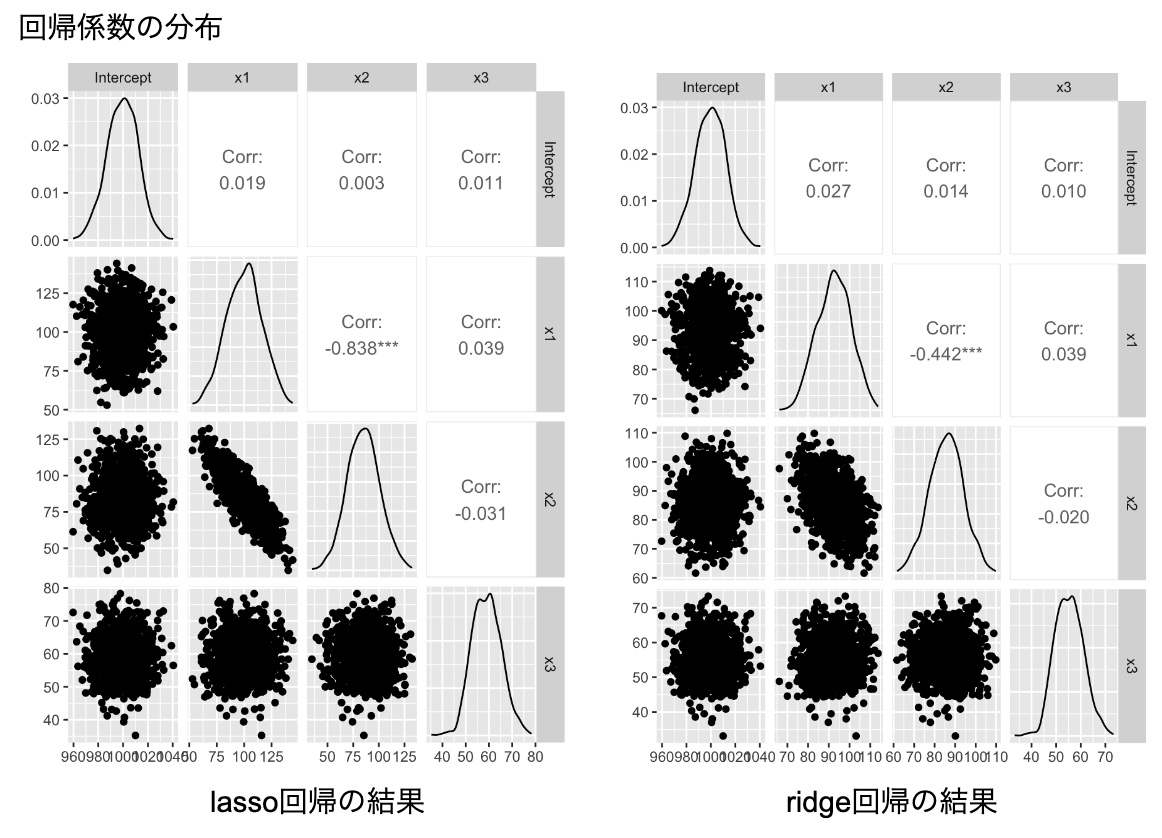
左の図はlassoの結果で、右の図がridge回帰の結果。
lasso回帰の方がridge回帰よりもx1とx2の(負の)相関は強い。
また、真のパラメータを再現できるわけではないですし、特に、ridge回帰の場合は、回帰係数が不安定になることを防ぐために、各回帰係数の値が小さく見積もられていることがわかります。
多重共線性が回避できたという感じはしなく、無難に線形回帰に近い結果が出てきているだけとも言えます。
ぱっと思いつくのは、lasso回帰とridge回帰かもしれません。
lassoにしろridge回帰にしろ、基本的にはデータドリブンなアプローチなので、仮説発見としては良いかもしれませんが、背景の構造が明確な場合は、想定通りの結果にならない可能性があります。
例えば、lassoは、よくスパースなデータに対しての変数選択として使われます。
ridgeも正則化をしている意味では、数学的には似ています。
多重共線性が起こっている場合、一般に逆行列が計算できない問題が発生するが、正則化を追加することにより,回帰係数が不安定になることを防いでいます。
左の図はlassoの結果で、右の図がridge回帰の結果。
lasso回帰の方がridge回帰よりもx1とx2の(負の)相関は強い。
また、真のパラメータを再現できるわけではないですし、特に、ridge回帰の場合は、回帰係数が不安定になることを防ぐために、各回帰係数の値が小さく見積もられていることがわかります。
多重共線性が回避できたという感じはしなく、無難に線形回帰に近い結果が出てきているだけとも言えます。
多重共線性の話 ~その6 多重共線性を回避する方法 [データサイエンス、統計モデル]
多重共線性があると、逆行列が求められないのが問題。
特に、完全な多重共線性の場合(ランク落ちしている場合)は、計算ができない。
そこで、通常の逆行列を拡張した一般逆行列(ムーア・ペンローズ逆行列)を導入することで、この問題を回避することができます。
通常の行列式による、回帰係数は、以下のように計算できます。
beta <- solve((t(X) %*% X)) %*% t(X) %*% y
これを一般逆行列(ムーア・ペンローズ逆行列)で書くと
beta <- ginv((t(X) %*% X)) %*% t(X) %*% y
となります。
通常のデータやランク落ちしない多重共線性の場合は、答えは一致します。
では、ランク落ちしている場合はどうなるか?
y <- 1000 + 100*x1 + 80*x2 + 60*x3 + 100*e
という場合、
- lmの結果:多重共線性が起こっている片方の回帰係数がNAとなる
- 行列計算の場合:逆行列が計算できないので、「システムは正確に特異です」となる
- 一般逆行列の場合:x1=100, x2=80だが、x1, x2で二等分した値になる
(x1 ≒ x2 ≒ 90)
特に、完全な多重共線性の場合(ランク落ちしている場合)は、計算ができない。
そこで、通常の逆行列を拡張した一般逆行列(ムーア・ペンローズ逆行列)を導入することで、この問題を回避することができます。
通常の行列式による、回帰係数は、以下のように計算できます。
beta <- solve((t(X) %*% X)) %*% t(X) %*% y
これを一般逆行列(ムーア・ペンローズ逆行列)で書くと
beta <- ginv((t(X) %*% X)) %*% t(X) %*% y
となります。
通常のデータやランク落ちしない多重共線性の場合は、答えは一致します。
では、ランク落ちしている場合はどうなるか?
y <- 1000 + 100*x1 + 80*x2 + 60*x3 + 100*e
という場合、
- lmの結果:多重共線性が起こっている片方の回帰係数がNAとなる
- 行列計算の場合:逆行列が計算できないので、「システムは正確に特異です」となる
- 一般逆行列の場合:x1=100, x2=80だが、x1, x2で二等分した値になる
(x1 ≒ x2 ≒ 90)
多重共線性の話 ~その7 階層ベイズ [データサイエンス、統計モデル]
階層ベイズ回帰モデル
定式化
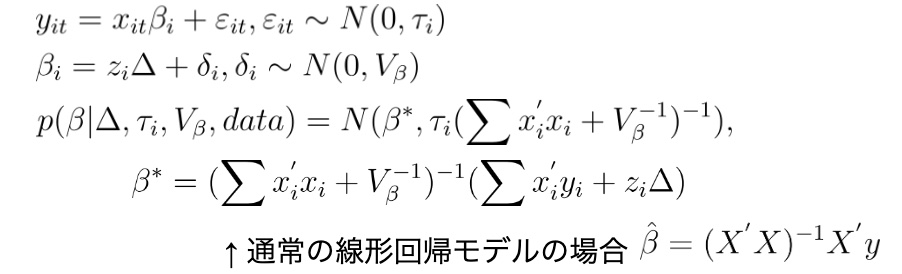
ridge回帰の正則化と同様のことが起こっているため、ベイズモデルは多重共線性を気にしなくても問題なさそうである。
実際のデータでシミュレーションをすると。
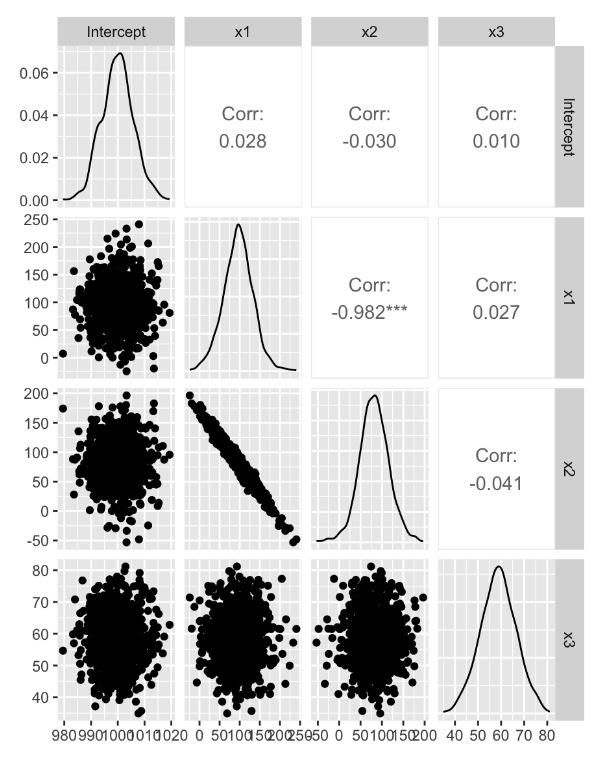
【多重共線性が起こっているデータ(ランク落ちではない)】
結果は、シミュレーションデータを再現できているものの、x1,x2の係数の相関は、かなりつよい結果となっている
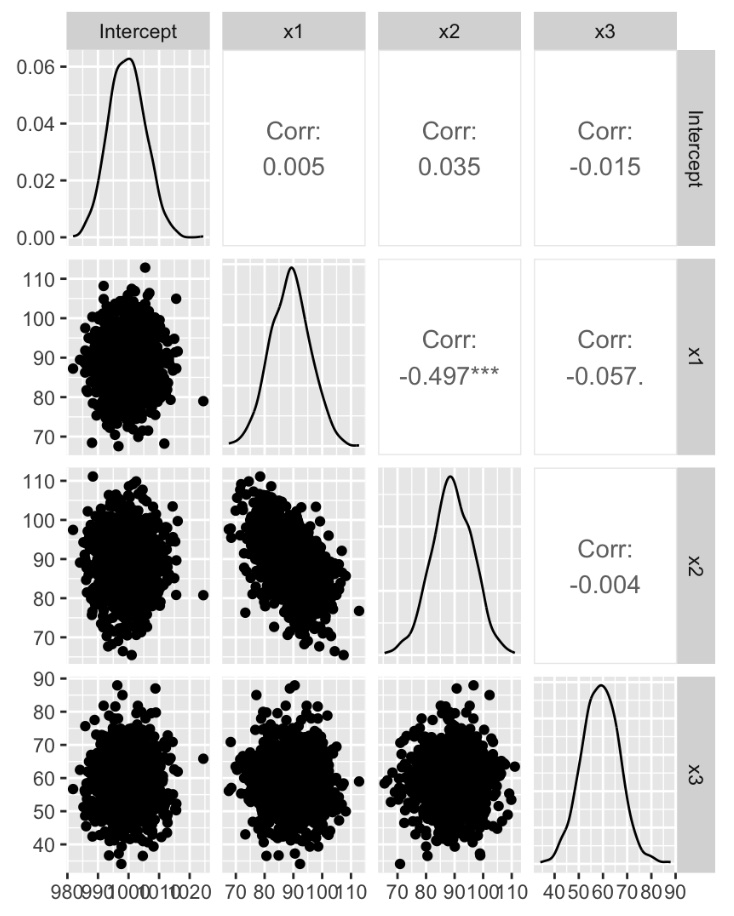
【完全多重共線性が起こっているデータ(ランク落ち)】
一般逆行列の場合と同様に、x1, x2で二等分した値になる
定式化
ridge回帰の正則化と同様のことが起こっているため、ベイズモデルは多重共線性を気にしなくても問題なさそうである。
実際のデータでシミュレーションをすると。
【多重共線性が起こっているデータ(ランク落ちではない)】
結果は、シミュレーションデータを再現できているものの、x1,x2の係数の相関は、かなりつよい結果となっている
【完全多重共線性が起こっているデータ(ランク落ち)】
一般逆行列の場合と同様に、x1, x2で二等分した値になる
t検定と線形回帰分析の対応 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
t検定と線形回帰分析の対応が分かりません。
【回答】
一変数の場合、それぞれの結果を比較することで、回帰分析の結果の一部がt検定の結果と一致していることが確認できます。
t検定で検定しても良いのですが、統計モデルを作る方がより分析に広がりが出て来ます。
# t.test()
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales, var=T)
# t = -2.2088, df = 18, p-value = 0.04039
# lm
sales <- c(A.sales, B.sales)
campaign.B <- c(rep(0,length(A.sales)), rep(1,length(B.sales)))
df <- as.data.frame(cbind(sales, campaign.B))
model.lm <- lm(sales~campaign.B, data=df)
summary(model.lm)
# campaign.B 395.5 179.1 2.209 0.0404 *
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
t検定と線形回帰分析の対応が分かりません。
【回答】
一変数の場合、それぞれの結果を比較することで、回帰分析の結果の一部がt検定の結果と一致していることが確認できます。
t検定で検定しても良いのですが、統計モデルを作る方がより分析に広がりが出て来ます。
# t.test()
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales, var=T)
# t = -2.2088, df = 18, p-value = 0.04039
# lm
sales <- c(A.sales, B.sales)
campaign.B <- c(rep(0,length(A.sales)), rep(1,length(B.sales)))
df <- as.data.frame(cbind(sales, campaign.B))
model.lm <- lm(sales~campaign.B, data=df)
summary(model.lm)
# campaign.B 395.5 179.1 2.209 0.0404 *
正確多重共線性データに対するマハラノビスの距離 [データサイエンス、統計モデル]
多重共線性のデータを考える。
x1, x2, x3, x4, x5は、独立の正規分布
x_sum = x1 + x2 + x3 + x4 + x5
x1, x2 ,x3, x4, x5は、多重共線性が起こっていないが、x_sumを混ぜたデータは多重共線性が
起こっている。
データA:x1, x2, x3, x4, x5
データB:x1, x2, x3, x4, x5, x_sum
それぞれに、マハラノビスの距離、一般逆行列を使ったマハラノビスの距離を適用するとどうなるか?
# 実験1:多重共線性が起こっていないデータに通常の方法でmdを計算する
# 実験2:多重共線性が起こっているデータに通常の方法でmdを計算する
# 実験3:多重共線性が起こっていないデータに一般逆行列を使いmdを計算する
# 実験4:多重共線性が起こっているデータに一般逆行列を使いmdを計算する
実験2は、逆行列が計算できないのでエラーとなる。
一方で、実験1,3,4は同じ答えとなる。
つまり、逆行列を一般逆行列に拡張しても結果は同じ。
x1, x2, x3, x4, x5は、独立の正規分布
x_sum = x1 + x2 + x3 + x4 + x5
x1, x2 ,x3, x4, x5は、多重共線性が起こっていないが、x_sumを混ぜたデータは多重共線性が
起こっている。
データA:x1, x2, x3, x4, x5
データB:x1, x2, x3, x4, x5, x_sum
それぞれに、マハラノビスの距離、一般逆行列を使ったマハラノビスの距離を適用するとどうなるか?
# 実験1:多重共線性が起こっていないデータに通常の方法でmdを計算する
# 実験2:多重共線性が起こっているデータに通常の方法でmdを計算する
# 実験3:多重共線性が起こっていないデータに一般逆行列を使いmdを計算する
# 実験4:多重共線性が起こっているデータに一般逆行列を使いmdを計算する
実験2は、逆行列が計算できないのでエラーとなる。
一方で、実験1,3,4は同じ答えとなる。
つまり、逆行列を一般逆行列に拡張しても結果は同じ。
岸田首相、1兆円増税 [時事 / ニュース]
国民負担ではなく、法人税をあげて防衛費と言っていますが・・・
法人税が上がると、給料は上がりにくくなるので、結局は、個人負担につながります。
その前に、馬鹿げたコロナ対策費をなんとかしたら良いのではないか?
コロナ予備費の「11兆円」が行方不明とか。
今はm中国すらしていない無料PCR検査所費用数億円とか。
ちなみに、増税自体には反対ではないですが・・・。
法人税が上がると、給料は上がりにくくなるので、結局は、個人負担につながります。
その前に、馬鹿げたコロナ対策費をなんとかしたら良いのではないか?
コロナ予備費の「11兆円」が行方不明とか。
今はm中国すらしていない無料PCR検査所費用数億円とか。
ちなみに、増税自体には反対ではないですが・・・。

