数理計画を使ったアトリビューションのシミュレーション [ログ / アクセス解析]
少し学会用の内容振り切っていましたが、実は、あれがベストだとは思っていません。
計算結果を見て、気がついた人もいるかと思いますが、Last Adに近い内容になっています。
他のデータを使ってもLast Adに近い結果になります。
考えてみれば当然で、キーワードの数って多いので、その遷移確率は小さいものになります。
遷移確率が小さいってことは、割り振られる貢献度も低い。
アシストに若干貢献度が移動する程度って考えた方が良いです。
今回のデータは、会員のデータなので出来なかったのですが、、、
では、何が理想か?を考えました。
本当のFirst Ad(サイトに初接触)
↓
購入時の商品を認知する(商品に初接触)
↓
購入のひとつ前(アシスト)
↓
購入する(アクション)
の4つに絞ります。
ここで、全部同じ軸でみようとすると、なんだかわけが分からなくなってしまいます。
また、アシストってのも、微妙な感じなので、思いきって無視!
すると、
・本当のFirst Ad(サイトに初接触)
と
・購入時の商品を認知する(商品に初接触)
・購入する(アクション)
に分けることができます。
・本当のFirst Ad(サイトに初接触)
⇒ こちらは、新規を獲得するという目的
・購入時の商品を認知する(商品に初接触)
・購入する(アクション)
⇒ こちらは、アクションというのが目的
この2つの軸のうち、新規を制約条件とし、数理計画として解いてはどうか?
そして、
・購入時の商品を認知する(商品に初接触)
・購入する(アクション)
の比率を 0 < α < 1 で変化をさせて、売り上げやリスクがどう変化していくのか?をシミュレーションしていく。
こんなアプローチって良いんじゃないかな?って最近思っています。
アトリビューションから最適化へ [ログ / アクセス解析]
OR学会の時は、主にアトリビューションを中心とした内容だったのだが、今回は、発表時間も5分増えたので、アトリビューションから最適化の話ができるそうだ。
最近、いろんなところでアトリビューションって声が聞こえてくるし、本も出版されている。
自分自身、今のアトリビューションの最新&最善の分析をぶつけてみたつもりだ。
さらに、アトリビューションを一つのモデルと考え、数学的な最適化も話せればと思う。
最適化し、シミュレーションまでびっしりの内容での発表予定です。

- 作者: 田中 弦
- 出版社/メーカー: インプレスジャパン
- 発売日: 2012/03/26
- メディア: 単行本(ソフトカバー)

- 作者: 高広 伯彦
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2012/03/30
- メディア: 単行本
データ解析コンペのフリー編 [ログ / アクセス解析]
アクセスログの分析って大きく分けて
1. 集客に関する分析
2. 導線やUIに関する分析
に分かれる。
実際に両方の分析をいろいろやってきたが、分かりやすい&インパクトが大きいのは、1の集客に関する分析だと思う。
2の導線やUIに関する分析は、だいたいがカスタマのリコメンドって話になりがちです。
ここで問題点があって、
リコメンドってのは、安易で分かりやすいのだが、実際に導入をしようとすると、IT部門との調整が面倒だったり、導入までに時間がかかったりする。
また、正直、世の中には安価で精度の良いリコメンドを提供する会社が多いです。
そういった会社の中には、長年の実績やノウハウがたまっているなか、あえて、内部で開発する工数を取り、一からリコメンドを導入するってのは、ハードルが高いのでは?とも思います。
逆に、集客部分の分析は、大きな開発もいらないので即時性が強く、アクション(購入)へのインパクトも大きい。
ということで、今回のフリー部門は、集客に関する分析でいこうかと思います。
流行りのアトリビューション分析をぶつけてみようかなぁ。
(´д`)
優良顧客分析の難しさ [ログ / アクセス解析]
場所は、慶應義塾大学の日吉キャンパス。
みんなの発表をみていると、顧客分析が多かった。
やはり、そこに目が行くだろうし、優良顧客の分析が云々…という展開。
その気持ちは分かるのだが、実際に企業や事業中で分析をし、施策に落とすってことを考えてみると、そこは意外と難しい。
改善出来たとしても、分析労力に対する貢献度は低いと思う。
だったら、いっそうのこと集客や流入キーワードの分析に振り切った方が実際に使える分析になるんじゃないだろうか?と思った。
ということで、今回の中間発表は、キーワードマーケティングがネタでした。
最終発表もたぶん同じ路線で行くと思う。
今週は、通常の分析に加え、コンペの分析をしたので、寝不足状態。。。
疲れた~。。。
ポイントサイト経由のヤフーリスティング [ログ / アクセス解析]
よくポイントサイトとかでウェブ検索でポイントゲットってものがある。
ユーザにしてみれば、普通に検索をしているだけでポイントがもらえるのでどんどん検索をする。
ウェブサイトの運営をしている方から考えると、あまり自社のサービスの興味がない人がどんどん増えてしまうという変な状況が起こってしまう。
単に来るだけだと良いのだが、リスティング広告(クリック課金)に出向している場合、
1クリックが数百円から数千円の無駄金をヤフーに払っているという構造になっている。
アトリビューション、貢献度の割り振り先 [ログ / アクセス解析]
結婚式場を選んだり、住宅を選んだりする場合、それが高価な商品なわけで、すぐにアクションをするって人は少ない。
下記のように複数回流入したと考える。
X1 ⇒ X2 ⇒・・・⇒ XA ⇒・・・⇒ X(N-1) ⇒ XN
X1:初回流入
XA:初めて対称商品のページを観た
X(N-1):アクションの1つ前(いわゆる、アシスト)
XN:アクションした
アトリビューションにおける重み選択 [ログ / アクセス解析]
最近では、アトリビューション(attribution)という言葉が多い気がするが、少し前だと、LTVとかマルチセッションとかっていう人もけっこういた気がする。。。
以下、アトリビューションと書くことにするが、アトリビューションとは、
Aさん
1回目:リスティングで流入
2回目:バナーをクリックして流入
3回目:SEOで流入
そして、3回目にアクション(購入)をした
って場合に、通常の施策では、最後に(3回目)にアクションをした施策に貢献度として100を与える、というの一般的だったし、今でもその指標でみている企業は多いだろう。
(※ なぜかといえば、それが一番測定が楽だから。)
ただ、最近では、1回目や2回目の施策もなんらかの影響を与えているだろうし、コストも発生しているわけだから、3回目の貢献度を100とするんじゃなくて、1回目と2回目に少し貢献度を与えようよ。としているわけだが、、、
エラーページ【404ページ】の分析 [ログ / アクセス解析]
パターンとして、3つ考えられる。
【その1】社内ページからの遷移でリンク切れのもの
⇒ 基本社内ページからの遷移でリンクはないはずなのだが…
(ないというか、あってはいけない。)
が!実は、意外とあった。。。
その理由として、現在のページからのリンクはないが、削除をしていない古いページを検索エンジンが認識しており、
「検索流入 → 古いページ → リンク切れ」
というパターンだった。
こういう場合SEO対策的に、リダイレクトをかけるべきか、そのページは残しておいて、そこからのリンク先を修正するかになるだろう。
【その2】社外ページ(調整可能)からの遷移でリンク切れのもの
⇒ お願いをして、リンク切れのURLを変更してもらう。
【その3】社外ページ(調整不可能)からの遷移でリンク切れのもの
⇒ 掲示板とかブログとか、調整不可能なリンクなので、URLの変更はできない。
次に考えられるのは、404ページに遭遇することは仕方がないとして、遭遇した後、再検索/再訪問してもらえるような404ページに変更するも大切だ。
Twitterの分析、データ抽出 [ログ / アクセス解析]
そこで、つぶやきの数やら内容やらを分析して欲しいというオーダーが来ました。
(´・ω・`)
とりあえず、データを落としてこないと分析が始まらないので、TwitterのAPIを叩いてデータを取得をすることに。
"ゼクシィ"を含むツイートの最新100件をXML形式で取得するためには、
http://search.twitter.com/search.atom?q="ゼクシィ"&rpp=100
で持ってこれるんですが、そのまま日本語を打ち込むとエラーになります。
"ゼクシィ"をエンコードして、
http://search.twitter.com/search.atom?q=%E3%82%BC%E3%82%AF%E3%82%B7%E3%82%A3&rpp=100
としてあげれば、データを抽出することができます。
ちなみに、APIの制限があって、ひたすら叩きすぎるとエラーになってしまいます。
そこで、1分間に2,3回程度の割合でデータを取得していくというじみ~な作業。
http://search.twitter.com/search.atom?q=%E3%82%BC%E3%82%AF%E3%82%B7%E3%82%A3&rpp=100?page=1
http://search.twitter.com/search.atom?q=%E3%82%BC%E3%82%AF%E3%82%B7%E3%82%A3&rpp=100?page=2
面倒くさいのでプログラム書いちゃおうかと思ったけど、世の中ではすでにがっつりデータを持ってくることができるサービスもあったので、今回はそちらを利用することにしました。
実践的なアクセスログ解析 初級編 その3 [ログ / アクセス解析]
流入とランディングページの流入数とアクション率(数)が分かったとします。
・分かって、何が嬉しいか?
・その後、具体的な施策にどう展開するのが良いか?
というゴール設計が出来ないと、分析してそれで終わりになってしまう。
いくつか、打ち手が考えられるが、例として流入数をX軸、コンバージョン率(アクション率)をY軸においてプロットしてみる。
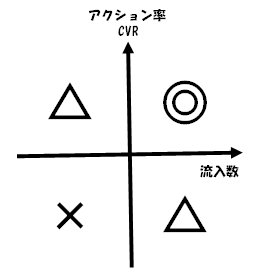
△をつけたのは、改善の余地があるって意味で、
1. コンバージョン率は良いが、流入数が悪い
⇒ 流入/集客を改善する。
SEO対策やリスティングで流入数アップを考える
2. 流入数は良いが、コンバージョン率が悪い
⇒ 導線/ランディングページを改善する。
これらを応用すれば、アクション数を伸ばすための戦略と課題を洗い出すことができると思います。
● 実践的なアクセスログ解析 初級編 その1
http://skellington.blog.so-net.ne.jp/2011-04-20
● 実践的なアクセスログ解析 初級編 その2
http://skellington.blog.so-net.ne.jp/2011-04-21
実践的なアクセスログ解析 初級編 その2 [ログ / アクセス解析]
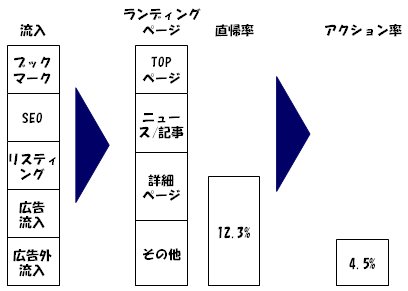
流入、ランディングページ、直帰率、アクション率などの全体的な流れから、少し具体的にサイトがどうなっているのか?を分析する。
例えば、流入をSEOからの流入ってどうなっているんだっけ?を見る場合、SEO流入の部分を100%グラフに変えて、集計してみると、
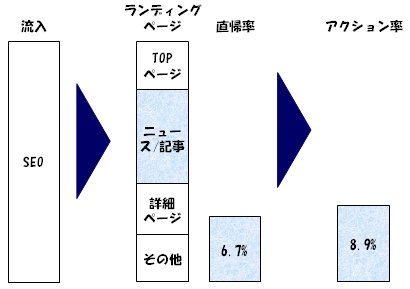
・「ニュース/記事」にランディングする割合が増えた
・直帰率が下がった
・アクション率が上がった
ということが一目でわかります。
同様にランディングページを100%にして、流入割合、直帰率、アクション率がどう変化するかをみることができます。
また、有効なのかアクション率を100%する場合です。
アクション率を起点にしているので、
流入⇒ランディングページ⇒アクションではなく、
アクション⇒ランディングページ⇒流入という逆引き分析が可能です。
つづく…
● 実践的なアクセスログ解析 初級編 その1
http://skellington.blog.so-net.ne.jp/2011-04-20
実践的なアクセスログ解析 初級編 その1 [ログ / アクセス解析]
・流入チャネルは?
・どこにランディングしているのか?
・直帰率は?
・アクション率は?
を一目で把握(診断)する。
あまり難しい指標を云々書く(描く)よりも、一目で分かるようなレポートが良い。
イメージとしては、こんな感じ
まずは、これで自分のサイト診断が出来る。
毎月とか毎週レポートすることで、実際の直帰率が下がったのか?とか、アクション率って上がっているんだっけ?ってことを把握することができるだろう。
続く…
SEO、自動順位チェックツールを作成 [ログ / アクセス解析]
せっかくなので、自分で作れないだろうか?って思ったところ、意外と簡単に作れそうだ。
作成手順としては、
1. ウォッチするキーワードを決める。
例えば、"結婚式場"だったとする。
2. GoogleやYahoo!でその検索結果ページをgetする。
http://www.google.co.jp/search?hl=ja&biw=904&bih=543&q=%E7%B5%90%E5%A9%9A%E5%BC%8F%E5%A0%B4&btnG=%E6%A4%9C%E7%B4%A2&aq=f&aqi=g10&aql=&oq=
↑
%E7%B5%90%E5%A9%9A%E5%BC%8F%E5%A0%B4 = 結婚式場
3. HTMLの構文解析で自社と競合の順位を取得する。
後は、複数キーワードに対応させて、これを毎日チェックするバッチプログラムを書けば終了。
ちなみにRubyでプログラムを書きました。
SEOのキーワード順位を考慮したリスティング広告の最適化を作るとより効率の良いものができそうですね。

- 作者: 高橋 征義
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2010/03/31
- メディア: 単行本
PrefixSpanアルゴリズム、アクセスログ分析への応用 [ログ / アクセス解析]
アクセスログの分析に使うことができて、
1. アクションをした/しない を分ける。
2. PrefixSpanで特徴のあるパターンを抽出する。
3. カイ二乗などを使ってアクションする人の遷移の特徴を把握する。
という分析ができます。
面白いのは、遷移が連続していなくてもOKで、
<a> → <b> → ... → <c> → <アクション>
というのが特徴的なパターンだった場合、
<a> → <b> → <c>
がアクションする人の特徴的な遷移ということがいえます。
PrefixSpanアルゴリズムはそんなに難しいものでもないし、特徴を把握するためのカイ二乗の計算も簡単です。
ということで、IBM SPSS Modeler(旧Clementine)で実装できないだろうか?と思ったところ、意外と簡単に実装できてしまいましたw
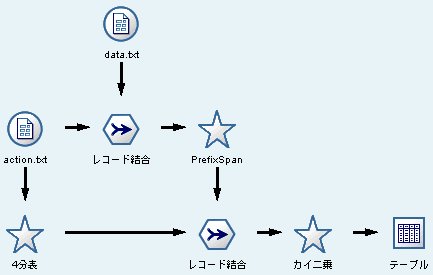
すごい計算量なので、大量のデータでの計算は難しいですが、通常規模なら実用に耐えれそうです。
というか、Hadoopへの実装もできるんじゃないだろうか。
むしろ、クレメンタインよりもきっと処理時間も早いのでHadoop実装がおススメだと思いました。
● PrefixSpan関連のリンク集
コーディングパターンの分析
http://sel.ist.osaka-u.ac.jp/research/codingpattern/index.html
PrefixSpan-rel -- a sequence pattern miner
http://prefixspan-rel.sourceforge.jp/
PrefixSpan - 機械学習の「朱鷺の杜Wiki」
http://ibisforest.org/index.php?PrefixSpan
フリーのツールでデータマイニング [ログ / アクセス解析]
少し前まで1ライセンス50万だったことを考えると、最近に高騰ぶりは驚かされる。
それに伴って機能とか格段に進化していれば良いんだけど、値段に見合った性能が向上しているか?といえば、ちょっと疑問だ。
そこでフリーのマイニングツールについて調べてみた。
Pentaho
http://www.pentaho.com/
Orange - Data Mining Fruitful & Fun
http://orange.biolab.si/
KNIME | Konstanz Information Miner
http://www.knime.org/
pig
http://pig.apache.org/
http://www.slideshare.net/xefyr/pig-making-hadoop-easy
(「米Yahooを中心に開発されたらしい)
Hadoopネタとして、こんなのもあります↓
http://hadoop-conference-japan-2011.eventbrite.com/
『Hadoopと分析統計ソフトKNIMEを用いた効率的データ活用』
Hadoopのおススメの本は、こちら。

- 作者: 太田 一樹
- 出版社/メーカー: 翔泳社
- 発売日: 2011/01/28
- メディア: 大型本
IBM SPSS Modeler: シーケンスノードでモデリング [ログ / アクセス解析]
webサイトでアクションをする人の行動を分析していて、アクションするまでの行動の順番を分析していた。
通常のアソシエーションとかを使うと順番が考慮されない。
ここで役に立つのがシーケンスノード。
そのままノードにデータを流し込むと、
(特にアクセスログデータの場合)
重すぎて時間がかかってしまうのと、いろいろなルールが出てきすぎて分析しずらい。
そこで、いったん、アクションページを踏んだ人で条件抽出を行う。
すると、必ずどんな人も
ページA → ページB → アクション
となるので、信頼度が100%となる。
つまり、シーケンスノードのオプションである
最小ルール確信度(%)を100%とかに設定すれば、
このアクションページを結果に含むルールが抽出できる。
後は、前提条件のルールを見て、余計なルールを破棄すれば、終了。
※ 検索用タグ
IBM SPSS Modeler、Clementine、クレメンタイン
oracleにログデータをインサートして分析 [ログ / アクセス解析]
昨年は、oracleをインストールしたところで止まっていたのだが、
そこにデータを流し込んで、IBM SPSS ModelerやMicrosoft Accessから
アクセスして分析できるようにした。
オラクルの設定がけっこう面倒くさいねぇ。。。
こういうのってオラクルのスペシャリストがいれば、サクッとインストールとかできるんだろうけど、あいにく自力でトラブルを解決しなければならないので大変だった。
良い勉強にはなったけど。
これで単純な集計は、各個人でやってもらえるようになると、こちらも助かるのだが…
競合分析のかぶり率 [ログ / アクセス解析]
・PV数
・UU数
・直帰率
などなどは、普通に集計する基礎情報だ。
どこが強みとか弱みとかも、分析していくうちにわかってくる。
最近、上記以外にも見るべき指標があるなぁって感じる。
それは、カスタマのかぶり率。
例えば、どこかと提携するとか考える場合、
あらかじめかぶり率を計算しておくと
・カスタマがかぶっている(両方のサイトを併用する人が多い)
⇒ あまり提携するメリットはない。
・カスタマがかぶっていない
⇒ 新規カスタマを取り込むチャンスがある。
ということがわかる。
A社と提携するか、B社と提携するかを考えたときに、
A社の方が大きいから、なんとなく良いんじゃない?って意志決定をする前に、
どれだけ新しいユーザ層を取り込めるのか?という視点で意思決定をするのも良いんじゃないだろうか。

入門 ウェブ分析論~アクセス解析を成果につなげるための新・基礎知識~
- 作者: 小川 卓
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2010/10/01
- メディア: 単行本
競合サイトを分析する [ログ / アクセス解析]
アクセスログツールを入れて分析するとか、大量の生データをガリガリ分析するとか。
これだけで、しばらくは楽しく分析できる。
自社サイトを分析していて、次に思うことが競合などの他社サイトでのカスタマの動きだ。
これも単にPV数を比較するとか、併用率を比較してみよう、となると簡単にできるのだが、どこなく内容が薄い。
内容が薄いので、そこから出てきた示唆に対しての具体的な施策が打てない。
深い内容の分析をするためには、
・URLパラメータの解読
・競合と自社の特性
を繰り返し細かく分析していくことが大切だと思った。
何か難しい数学や統計のテクニックなどは、ほとんど必要なく、
(むしろ、それに頼りすぎると技術に溺れてしまう)
じみち~な作業の方が大切で、苦労した分分析結果も良いものが出来たと思う。
そして、次の作業として、この結果を分かりやすい資料に変換していく。
グラフひとつで印象や伝わり方が大きく変わるから、これも気が抜けない。
分析で分かったことをチームに共有すると、次の分析のネタが出てきたり、新たな課題が議論されたりと、分析はネバーエンディングストーリーとなっていくわけだが、、、(苦笑
こうして、今まで解らなかったことが少しずつ解明できていければと思う今日この頃。
アクセスログ分析 [ログ / アクセス解析]
その続きとして、今回は、ネットのログを使った分析勉強会を実施する予定。
元々、3月くらいに作ったのだが、今回、大幅にリニューアルをした。
実際の生のログデータを素材にしているので、親和性も高く、
けっこう良いものが出来たんじゃないかなぁって思う☆
さて、芸能人の結婚特集|ゼクシィnet
http://zexy.net/contents/geinoujin/
がオープンしました。
芸能人やスポーツ選手などの結婚時事ネタが集まったサイトになっているようです。
カスタマの流入を長期視点で考えてみると [ログ / アクセス解析]
この場合、アクションした時の流入施策に目がいってしまうのだが、本当は、初期流入やら途中の流入ってのにも光を当たる必要があるのではないだろうか?
マイクロソフトが提案している、Engagement Mapping(エンゲージメント・マッピング)の資料には、
TV放送を見て知っている、雑誌の一面に載っていた、あるいは、DMなどであらかじめ知っている商品があったとする。次に、クーポンを切り抜き、スーパーに買い物に行き、店員に「○○という商品はどこですか?」と尋ねる。スーパーのその店員は、笑いながら「5列目にあります。」と答えたとすると‥ この時、往来のモデルでは、スーパーの店員が100%の功績を持っていってしまうことになる。
確かに、スーパーの店員にお金を払うってのは、感覚的におかしい。
TVのCMやら雑誌に広告費を払うべきなのだが、ネットの世界では、きちんと測定できていないとか、そもそもどう配分するんだっけ?ってのがわからないので、結局測定しやすい最後の流入にお金を払いましょうってことになっているのが現状。
Engagement Mapping(エンゲージメント・マッピング)では、上記のことを実現できますよ~ってうたっているものの、実際どうやっているかは不明だったりする。
マイクロソフトのアルゴリズムは、よく分からないのでなので、だったら、自分たちで作ってみようってことで、作ってみました。
よくよく分析すると、上で書いていることってのは、
・短期的にみて効率の良い施策
・長期的にみて効率の良い施策
って部分に分けることができて、○○の施策(リスティングのキーワードとか)は、短期的にも長期的にも良いでしょうとか、▲▲は、短期的にも長期的にも全然だめですね~といったことがいえる。
ちなみに、あるカスタマがアクションをする際に、1つだけの施策で完結する場合って一般的に25%くらいといわれています。
75%の人は、いろいろな施策によって来訪するので、その施策と施策の遷移もきちんと考慮する必要があるでしょう。
Adobe、Web解析のOmniture買収で合意 [ログ / アクセス解析]
米Adobe Systemsと米Omnitureは15日、AdobeがOmnitureを約18億ドルで買収することで最終合意したと発表した。Adobeは、 Omnitureの発行済み普通株式を1株21.50ドルの現金で公開買い付けする。過去30日間のOmniture株の平均終値に45%を上乗せした額となる。
Adobeのコンテンツ制作ツールとOmnitureのWeb解析技術を組み合わせることで、コンテンツやオンラインサービスを効果的に収益に結び付けられるようにしていく考えだ。
買収により、OmnitureはAdobeの新しい事業部門となり、OmnitureのJosh James CEOが同部門の上級副社長に就く予定。
え?(・∀・)
あのOmnitureがAdobeに買収されたか…
朝から衝撃の事実ですた。
SPSSもIBMに買収されたし、最近なにやら騒がしいですねぇ。
スモールワールド・ネットワーク [ログ / アクセス解析]
実際にデータマイニングとかの世界もそうだと思う。
俺 - 知人A - 知人Aの知人B
ってのを考えたとき、
俺 - 知人A:距離1
俺の知人Aの知人B:距離2
とする。
アメリカでは、だいたい距離6でつながっているってのが実験でわかったらしい。
つまり、
自分 - 自分の知人1 - 自分の知人2 - ・・・ - 自分の知人6
でほぼ、アメリカは繋がっている。
データマイニングとか、データ解析の世界ってもっと小さく、距離って2とか3くらいじゃないだろうか?w
さて、上記は、言葉の概念であるが、定量的な定義としては
関心の範囲にある頂点数 n を徐々に増やすとき、平均距離が
L = O(log n)
であることとなっている。
スモールワールドと呼ばれているネットワークにおいて、L = O(log n)以外の性質としては、クラスター性ってのがある。
Lが小さく、クラスター係数が高いものを、スモールワールド・ネットワークといい、色々な研究がされている。
Googleを支える技術 ~巨大システムの内側の世界 [ログ / アクセス解析]
普通に出勤。
ほとんど人いないし、みんな帰りも早いです。(笑
今日は、会社の人と飲み。
特に予約もしてなかったけど、GW中なのですんなり入れました。
今日、一緒に飲んだ人は、群馬から1時間くらいかけて新幹線通勤しているそうです。
時々、話には聞くのだが、実際に通勤している人は初めてです。
なんかリッチな感じがします。(´`)
さて、今日購入した本は、これ。
")
Googleを支える技術 ‾巨大システムの内側の世界 (WEB+DB PRESSプラスシリーズ)
- 作者: 西田 圭介
- 出版社/メーカー: 技術評論社
- 発売日: 2008/03/28
- メディア: 単行本(ソフトカバー)
内容紹介
たとえば、ふだんなにげなく行っているWeb検索。
背後には、想像以上に膨大な計算、多数のコンピュータの働きがあります。
本書では、論文やWebなどで公開されているパブリックな情報をもとに、Googleの基盤システムについて技術的な側面から解説を試みています。
世界規模のシステムにおける『分散ストレージ』『大規模データ処理』『運用コスト』など注目の話題を盛り込み、学部生をはじめ初学者の方々にもお読みいただけるように基礎知識から平易に説明します。
データ解析コンペ 最終発表(金鉱掘蔵) [ログ / アクセス解析]
データ解析コンペ 最終発表(金鉱掘蔵)
社会人チームの第1回目、2回目の合同発表。
3月12日に3回目があって、そこで順位が決まります。
アクセスログ解析と言えば、「集客」、「銅線」の2つにつきると思います。
コンペでも、この2つがメインのテーマ。
金鉱掘蔵チームのネタとしては、リスティング広告とキーワード検索を中心とした「集客」をテーマに、時系列分析も取り入れて発表しました。
学問ちっくな発表からマーケティング寄りな発表まで色々なチームがありました。
一番、マーケティングよりの発表だったんではと思います。
アクセスログ解析とキーワード広告の最適化 [ログ / アクセス解析]
NET&COM 2006 FORUMに行ってきました。
・マイニング技術を活用したログデータの有効利用
http://expo.nikkeibp.co.jp/netcom/forum/F2.shtml
数理システムの方が発表されていました。
スクリプトを使って生ログから分析できるデータを作るようです。
後は、マイニングツールの出番。
Web Mining for Clementineの機能に近いです。
ただ、Event化みたいなことはしてくれません。
User IDは、ふってくれる様ですが、Visit IDみたいなものは、ありませんでした。
UserよりもVisitの方が大切だと思うのですが・・・
Web Mining for Clementineの簡易版って感じですね。
後は、キーワード広告最適化の話しをしていました・・・
えぇー!(;∀;)
時代は、統計解析/データマイニングから最適化へと進歩しているのでしょうか。
近年、データマイニングは、飛躍的な進歩を遂げ、いろんな人が口にするようになってきています。
しかし、最適化に関しては、これから伸びていく気がします。
その最先端を走れるように頑張りたいですね♪
_,, 、、 .. _
,. '" ``` ‐-,
/ /,~、``' ヽ
/ 〈 ,.へ、._ ヽ
| 〃ヽ //\..._`フノ
| {(`、| |. `ヽ===ii`, ヽ
.| .| { 〈| | / ヽ / ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
| ヽ ヽ| | / __,ヽ .| Webサイトのデータマイニング
ヽ. / ヽ | | _了´ ∠ ■Webサイトの問題点の抽出
/ヽw'゛ },,,| 厶 | ■キーワード広告の最適化
./ \ ` 、 〈 \__________
/~` ‐- 、__ \ ` - ..、._〉
 ̄~` ‐- 、 {
テキストマイニングとベイジアンネットの融合の可能性 [ログ / アクセス解析]
SPSS Keywordsに、アクセスログ解析の応用編が掲載されました。
その原稿のHTML版がSPSSのWebページにアップされています。
http://www.spss.co.jp/labo/ttips/06/index.html
現在、第3回目(最終回)として、テキストマイニングの原稿を執筆中です。
通常のテキストマイニング事例だけではなく、
ISFIならではのことができないか?って考えました。
そこで、テキストマイニングに最近、流行っているベイジアンネットを融合させました。
性別・年齢などのデモグラフィック情報と、テキストのトピックを結びつけ
どういう属性の人がどういうことを考え、それをどう評価するのか?についてです。
詳しくは、第3回Keywordsをご覧ください。
おそらく、12月予定です。
アクセスログ解析とテキストマイニング ~SPSS、Keywords~ [ログ / アクセス解析]
SPSSの季刊誌Keywordsに3回連載が予定されています。
現在、2回目の原稿ができました。
第1回目の原稿は、SPSS社のWebサイトにも掲載されています。
http://www.spss.co.jp/labo/ttips/05/index.html
webサイトということで、図はjpgが基本になっているため
若干、図が読みづらくなっています。
(´・ω・`)
第2回の発送は、9月中旬~下旬らしいです。
アクセスログ解析の話は、2回で終わりです。
最後の3回目は、Clementineを使ったテキストマイニングになっています。
ネタ的には価格.comのテキストデータを使いテキストマイニングをする予定です。
Weblog(ウェブログ)解析 入門その4 ~ロボット君の行動パターン~ [ログ / アクセス解析]
Weblog(ウェブログ)解析 入門その4 ~ロボット君の行動パターン~
Webを徘徊するロボット君たちがたくさん存在します。
有名なロボット君といえば、Googlebotでしょうか。
名前が、Googleっぽいですが、Googleのロボットです。
その他にもYahoo!やMSNなどなど。
これらのロボット君は良心的で、
「私は、どこどこのロボットです。」
と名乗ってホームページをせっせとかき集めていきます。
働きアリみたいなもんです。
これとは逆に、
「私は、インターネットエクスプローラーです。」
と、一見、PCユーザーのように変装してやってくるたちの悪いロボット君もいます。
では、ISFIのページはどうなっているんでしょうか?
ロボットくさいものは、ロボットだとして集計すると
このようになります。

意外とロボットって多いんですね。
また、携帯電話などのMobileからアクセスしてくれているユーザーも若干まじっています。
もう少しMobileユーザーが増えれば、Mobile対応のページを作るのも良いかも知れません。
ここで、話が少し変わります。
以前のWebページでは、ユーザーは、まずTOPページに訪れ、
その次に、商品説明や会社説明など、そのリンクをたどっていき
自分の欲しい情報のページにたどり着くってのが一般的でした。
データマイニングの決定木に似ているのかもしれません。
木のTOPから、深く掘り下げていき目的の場所に到達する!
しかし、最近のユーザーは、Googleなどの検索エンジンを使って
直接、欲しい情報のページにやって来ます。
以前の様に『ユーザーは、TOPページから来る!』ということはなくなりました。
ISFIの入口ページは、どうなっているでしょうか?
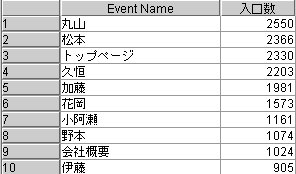
この結果をみると、トップページを入口としてアクセスしてくる人もいますが、
それよりもブログを入口としてアクセスしてくる人が多いことがわかります。
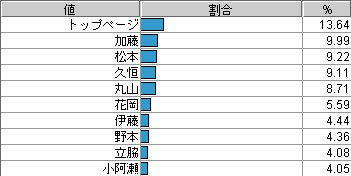
入口ではなく、見られているページ数では、TOPページが一番多くなります。
(上記の数値では、ロボットやロボットっぽいものは省いた数値です。)
では、ここでロボット君の動きをみてみましょう。
ロボット君がどの様にページを見ているか?/収集していくのか?です。
仮説として、二つのことが考えられます。
1.TOPページから巡回している
2.よく更新される/リンクされているページから巡回している
これは、ロボットとはっきり解るものだけを集めてきました。
これを見ると、2.のパターンだと思われます。
テキストマイニングでは、辞書作りはとても大切な作業です。
このアクセスログ解析においても、正確にアクセスログの分析を行うのであれば
ロボット辞書なるものを作る必要がありそうですね。
Weblog(ウェブログ)解析 入門その3 ~1ページだけしか見られないEventは?~ [ログ / アクセス解析]
Weblog(ウェブログ)解析 入門その3 ~1ページだけしか見られないEventは?~
アクセスログ分析の第3回目です。
前回、Eventというものでwebページを定義することにいたしました。
では、具体的に各種集計を行っていきましょう。
どういうページが見られているのか?を分析していきましょう。
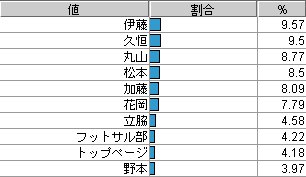
まずは、Event Categoryから。
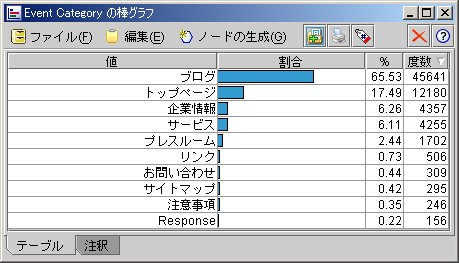
やはり、ブログ系のページが多いようです。
もう少し、詳細にEvent Nameでみてみましょう。
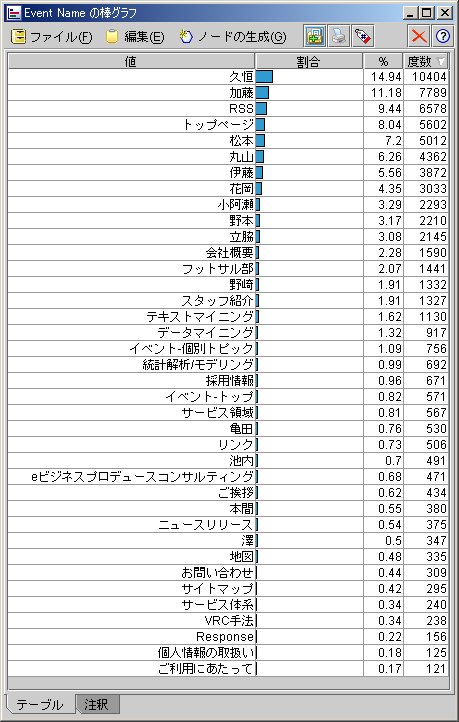
次に、1ページだけ見て帰るページはどういうページかを分析しましょう。
必ずしも、「1ページだけ見て帰る = 悪いページ」ということはありません。
ただ、ECサイトとかですと、1ページだけみて帰るページがほとんどの場合
ちょっとサイト作りに問題がある!ってことが考えられます。
ISFIページ全体で見ると、直帰率は、14.6%とそれほど高くありません。
トップページの直帰率も14.8%となっています。
トップページの直帰率が40%や50%を超える企業も多いかと思いますが、
この数字は、まずますのサイト構成といえるのではないでしょうか?
では、ここでリフトという概念を持ち込んでみましょう。
ここでリフトの定義を
実測値
リフト = -----------
期待度数
とします。
つまり、1前後だと、期待通り、通常通りの平均得点という意味で
1よりも高くなればなるほど、(低くなればなるほど)
そこに差があるということになります。
今回の場合は、リフト値が、1よりも高いと他のページよりも直帰する率が高く
1よりも小さいと他のページよりも直帰する率が低いと言えるでしょう。
では、Event Category別、Event Name別に分析しましょう。
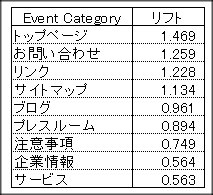
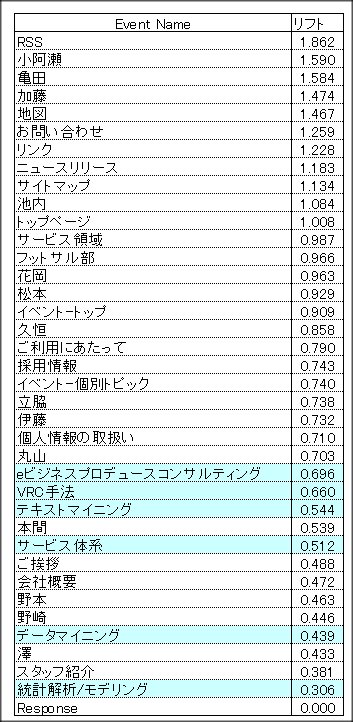
こうしてみると、データマイニング系のページはよく見られていることが解ります。
さらに、深く分析を行うのであれば、どういうキーワードで弊社に訪れたのかと
マッチングさせることで、より詳細なアクセスログ解析ができると思われます。
続く...

