事前分布自体が未知の場合の Empirical Bayes Approach [ベイズ統計量におけるパラメーターの推定]
事前分布自体が未知の場合の Empirical Bayes Approach
前回までだと、二項分布にしろ多項分布にしろ、 P の事前分布のパラメータは未知であるが、事前分布は、既知であると考えてきた。
では、事前分布が未知であるような場合、Empirical Bayes Approachは、どうなるであろうか?
↓
An Empirical Bayes Approach
事前分布自体が未知の場合、P をどのように推定するかを考える。
Binomial Kernelの場合、
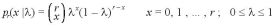
ここで、r は、試行の数を表す固定された正の整数とし、また、X は成功の数とする。
X の事前分布は未知とする。
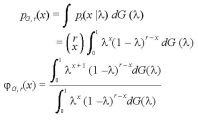
となる。
基本関係式は、
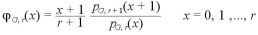
今、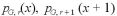 を推定する。
を推定する。
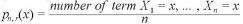
を考え、これは、n → ∞ で確率 1 で 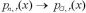 となる。
となる。
今、r 回の試行中、初めの (r - 1)回の試行の中で、成功の数を表す確率変数列 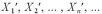 を考える。
を考える。
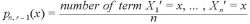
を考えると、これは、n → ∞ で確率 1 で 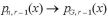 となる。
となる。
ゆえに、
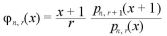
とおけば、これは、n → ∞ で確率 1 で
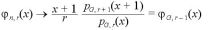
 の推定値として、平均自乗誤差を考えるときに、シミュレーションで求めることができる値として、
の推定値として、平均自乗誤差を考えるときに、シミュレーションで求めることができる値として、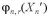 を取ることができる。
を取ることができる。
そして、これは、n → ∞ に関して
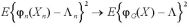
となる。
※ ここで、 に関して、
に関して、
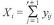
とし、また、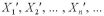 に関して、
に関して、
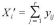
とした。
二項分布と多項分布の比較:ベイズ統計量 [ベイズ統計量におけるパラメーターの推定]
二項分布と多項分布の比較:ベイズ統計量
Bayes統計量による p の推定量の平均自乗誤差を計算すると
パラメータが既知のBayes統計量の平均自乗誤差は、
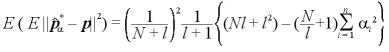
パラメータが未知のBayes統計量の平均自乗誤差は、
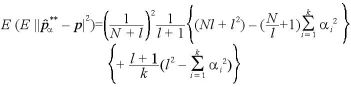
ここで、二項分布と多項分布の比較をしてみると、
I. モーメント法による推定量について
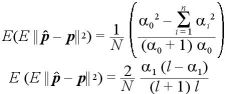
となり、二項分布の場合と一致する。
II. パラメータが既知のベイズ統計量について
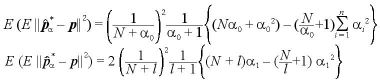
となり、二項分布の場合と一致する。
III. パラメータが未知の場合のベイズ統計量について
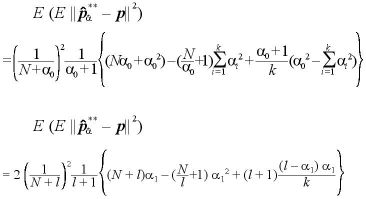
となり、二項分布の場合と一致する。
式の導出の計算は、省略したが、たぶん合っていると思います。w
間違っていたら、教えてください。(´д`)
モーメント法による推定量 [ベイズ統計量におけるパラメーターの推定]
モーメント法による推定量
 は無作為標本で、k 個の未知な母数
は無作為標本で、k 個の未知な母数 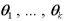 を持つ分布に従うものとする。
を持つ分布に従うものとする。
このとき、
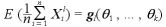
とおくと、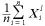 は、n が大きくなると
は、n が大きくなると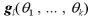 に近づく。
に近づく。
そこで、 に関する連立方程式を考える。
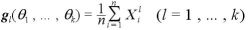
この方程式の解 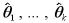 をモーメント法による の推定値という。
をモーメント法による の推定値という。
モーメント法を用い、p の推定量は、
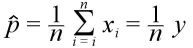
となる。
パラメータが未知の場合のベイズ統計量:ベータ分布から多項分布へ [ベイズ統計量におけるパラメーターの推定]
パラメータが未知の場合のベイズ統計量:ベータ分布から多項分布へ
朝、出勤して、ミーティング中に
お誕生日、おめでとうケーキが用意されていました。(@_@;
ケーキでは、モンブランが好きです!(・∀・)
みなさま、ありがとうございました。
さて、パラメータが未知の場合、ベータ分布から多項分布への拡張なのだが、
http://blog.so-net.ne.jp/Minky/archive/20070912
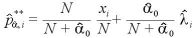
今、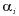 を推定するために、新たに多項分布からの独立な確率変数として、
を推定するために、新たに多項分布からの独立な確率変数として、 を抽出する。
を抽出する。
ここで、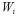 をDirichlet分布とする。
をDirichlet分布とする。
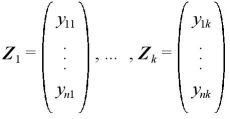
ここで、モーメント法による推定量は、
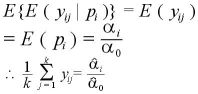
となる。
今、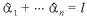 という条件をつけると、
という条件をつけると、
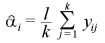
ゆえに、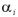 が未知の Empirical Bayes 統計量は、
が未知の Empirical Bayes 統計量は、
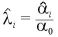
として、
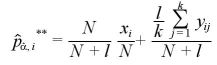
となる。
ただし、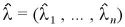 とする。
とする。
パラメータが既知の場合のベイズ統計量:ベータ分布から多項分布へ [ベイズ統計量におけるパラメーターの推定]
パラメータが既知の場合のベイズ統計量:ベータ分布から多項分布へ
以前に、ベータ分布のパラメータが既知の場合のベイズ統計量を考えたことがあるが
http://blog.so-net.ne.jp/Minky/2007-09-07
今度は、ベータ分布から多項分布へ拡張した場合にどうなるかを考える。
 をパラメータ
をパラメータ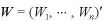 が未知な値を持つ多項分布からの独立な確率変数とし、W の事前分布として Dirichlet分布 を仮定する。W の事前確率密度関数 ξ は、
が未知な値を持つ多項分布からの独立な確率変数とし、W の事前分布として Dirichlet分布 を仮定する。W の事前確率密度関数 ξ は、
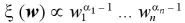
である。Wの事後分布密度関数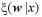 は、
は、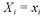 のとき、
のとき、
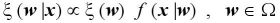
であるので、
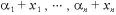
ゆえに、上式は、パラメータ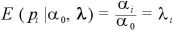 を持つ Dirichlet分布 となる。
を持つ Dirichlet分布 となる。
Dirichletの p の期待値は、
(Prior Mean)
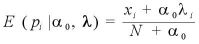
(Posterior Mean)
となる。
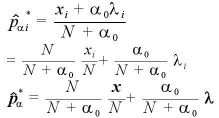
となる。
ただし、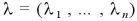 とする。
とする。
多項分布とDirichlet分布 [ベイズ統計量におけるパラメーターの推定]
多項分布とDirichlet分布
多項分布とDirichlet分布の関係は、二項分布とベータ分布の関係に似ている。
二項分布を多次元に拡張した場合、次元を n 次元にした場合を考える。
前回同様に、パラメータが既知の場合のベイズ統計量と、パラメータが未知の場合のベイズ統計量を計算したいと思うが、まずは、分布の復習から。
★ 多項分布とは
1回の回の試行で互いに排反な事象 の起こる確率がそれぞれ
の起こる確率がそれぞれ
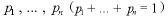
とし、この試行を N 回独立に繰り返すときの起こる確率をそれぞれ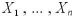 とする。
とする。
また、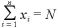 としたとき、その確率密度分布は、
としたとき、その確率密度分布は、
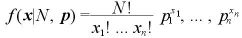
となって、平均、分散、共分散は、
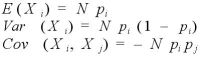
となる。
★ Dirichlet分布とは
ベータ分布の多次元化としてして、Dirichlet分布を考える。
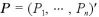 をパラメーター
をパラメーター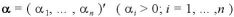 を持つ確率変数とすると、その確率密度関数は、
を持つ確率変数とすると、その確率密度関数は、
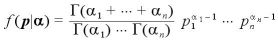
となる。ここで は、ガンマ関数を表す。平均、分散、共分散は、
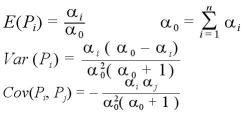
サンプル数が多い場合の精度比較 [ベイズ統計量におけるパラメーターの推定]
サンプル数が多い場合の精度比較
標本数が多い場合
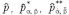
について、
I.

II.
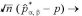
III.
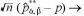
の漸近分布を考える。
I.について
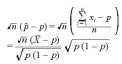
n が大きい場合は、中心極限定理より、
平均 0、分散 p(1 - p) の正規分布 N(0, p(1 - p)) になる。
II.について
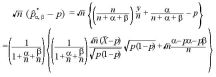
n が大きい場合は、中心極限定理より、
平均 0、分散 p(1 - p) の正規分布 N(0, p(1 - p)) になる。
III.について
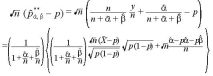
n が大きい場合は、中心極限定理より、
平均 0、分散 p(1 - p) の正規分布 N(0, p(1 - p)) になる。
ということで、前回の予想通り、I, II, IIIは、サンプル数が多くなるとどれも同じ分布に収束する。
リスクの評価 [ベイズ統計量におけるパラメーターの推定]
リスクの評価
今まで、考えた統計量は、
I.モーメント法による の推定量の平均自乗誤差
II.パラメータが既知のベイズ統計量の平均自乗誤差
III. パラメータが未知のベイズ統計量の平均自乗誤差
それぞれの統計量に対し統計量 との平均自乗誤差を考える。
I.モーメント法による の推定量の平均自乗誤差
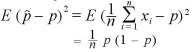
さらに期待値を取ると
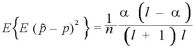
II.パラメータが既知のベイズ統計量の平均自乗誤差
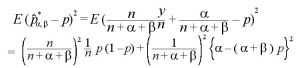
さらに期待値を取ると
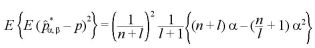
III. パラメータが未知のベイズ統計量の平均自乗誤差
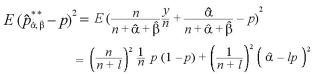
さらに期待値を取ると
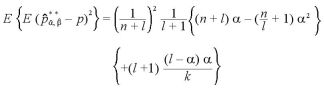
予想として、I、II、IIIは、サンプル数が多くなるとどれも同じ分布に収束するだろう。
サンプル数が小さいときは、上記のように個々に分布を考える必要がある。
パラメータが未知の場合のベイズ統計量 [ベイズ統計量におけるパラメーターの推定]
パラメータが未知の場合のベイズ統計量は、
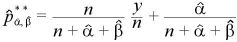
と置くことができる。
問題は、α, βをどのようにして推定するか?
新たに、
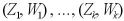
をベルヌーイ分布からの独立な確率変数を抽出する。
各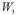 はベータ分布とする。
はベータ分布とする。
推定する方法は色々あるだろうが、モーメント法による推定量を考える。
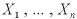
は無作為標本で、k個の未知な母数

を持つ分布に従うものとする。
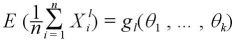
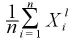
は、n が大きくなると
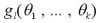
に近づく。
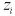 のモーメント法による推定量は、
のモーメント法による推定量は、
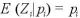
より
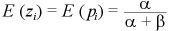
つまり、
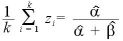
(1次のモーメント)
これで、2次のモーメントを求めることができれば、連立方程式を解くことにより、
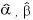
を求めることができるのだが、の1次のモーメントも2次のモーメントも
(1次のモーメント)
(2次のモーメント)
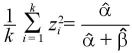
となって、一般に、の n次のモーメントも
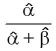
となるので、
をモーメント法では、同時に推定することはできない。
例えば、ここで
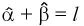
という条件をいれると、
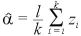
α, βが未知の場合のベイズ統計量は、
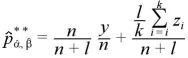
と求めることができる。
パラメータが既知の場合のベイズ統計量 [ベイズ統計量におけるパラメーターの推定]
Wの事前分布としてベータ分布と仮定する。
ここで、ベータ分布とする理由は、
1) 比較的事後分布を導くことが容易である。
2) α と β の母数の選び方により、分布の形が様々となり、多様な事前分布を表すことができる。
3) 母数α、β の解釈が容易である。
母数α、β の定め方は、どのような事象の生起確率を問題にしているかによって異なる。
まったく事前知識のない事象の生起確率ならば、α = 1、β = 1、すなわち、0≦ p ≦ 1 のどの値も同等に起こりやすいとすることができる。
また、コインを投げる簡単な実験の場合ならば、予想される p のあたいは0.5のまわりに集中する。
あるいは、イカサマコインなどで、表が出やすいという印象を持っているならば、α = 3、β = 2という事前分布が設定できる。
あるいは、事前の知識を無視し、中立的な事前分布を設定することもできる。
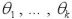
に関する連立方程式を考える。
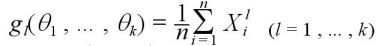
この方程式の解
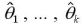
をモーメント法による
の推定値という。
モーメント法を用い p の推定量は、
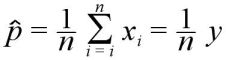
となる。
パラメータが既知の場合のベイズ統計量

をパラメータ W が未知な値を持つベルヌーイ分布からの独立な確率変数とし、 W の事前分布としてベータ分布と仮定する。
W の事前確率密度関数 ξ は、
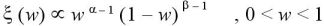
そして、W の事後分布密度関数
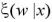
は、X = x のとき、
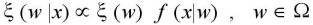
であるので、
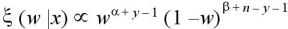
ここで、
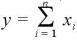
とする。
この式は、パラメータ α + y と β + n - y を持つベータ分布となっている。
ここでベータ分布の p の期待値は、
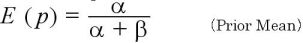
であることより、
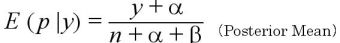
となる。
今、上の式によって得られたベイズ統計量を
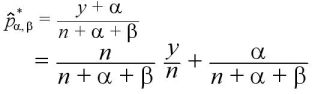
とする。
ここら辺りまでは、引っ張ってくれば色々な文献で見つけることができる。
次の課題としては、パラメータが未知の場合のベイズ統計量の場合。
そもそも、パラメータが未知の場合の方が多いのではないだろうか?
いくつかの分布 その1 [ベイズ統計量におけるパラメーターの推定]
いくつかの分布 その1
ベルヌーイ分布
離散型確率変数Xが1と0の2つの値しかとらない分布を考える。
成功を X = 1、失敗を X = 0と表し、成功の確率を p とする。
そのとき、X の分布は、次式によって表される。
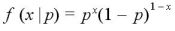
重要な仮定は…
毎回の確率事象が同一で、かつ独立であること
コイン投げで考えると、以前に表・裏のどちらがどのように出たかに拘らず、毎回の表・裏の出る確率が同じ決まった値になっていることである。
二項分布
n 回のベルヌーイ試行が、成功の確率pが変化することなく、互いに独立に行われるとする。
個々の結果が生起する確率は、成功が x 回、失敗が ( n - x) 回であれば、
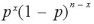
で表される。今、成功の回数を確率変数 X としてその分布を求めてみる。
成功の回数が x 回の標本点は
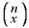
とおりあるので、x の分布は、
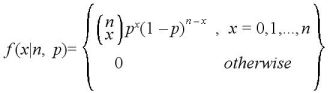
と表現できる。このとき、平均と分散は、
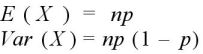
ベータ分布
有限区間に集中している連続分布は、基準化することによって単位区間 ( 0, 1 ) 上の分布として扱うことができる。
パラメーターα, β(α > 0, β > 0)を持つ確率変数とすると、その確率密度関数は、
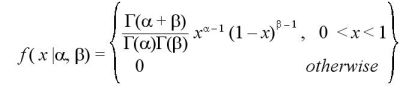
となる。ここで、
は、ガンマ関数を表す。
平均と分散は、
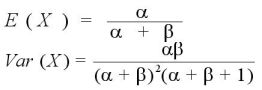
パラメータが既知の場合のベイズ統計量 [ベイズ統計量におけるパラメーターの推定]
統計的推論の目的として、
1. データに基づいて母数に関する知識を深めること
2. まだ観測されていない将来のデータを推定すること
が考えられる。
今、なんからの観測がされたとすると、上記に対する知識(精度)が深まったと考えられる。
今回、Xを二項分布とし、その事前分布がベータ分布と考える。
今、 p を推定する方法として、
1. モーメント法による推定
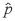
2. ベイズ的アプローチによる推定
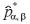
などがあげられる。
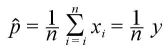
ベイズ的アプローチによる推定につきまとう問題点として、パラメータが既知として計算されている。
パラメータが未知の場合、
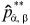
は、どのように計算されるか?
推定量の良さとして、平均自乗誤差が考えられるが、
1. モーメント法による統計量
2. パラメータが既知のベイズ統計量
3. パラメータが未知のベイズ統計量
の3つの統計量に対して、平均自乗誤差は、どのように計算されるか?
●事前分布と事後分布の定義●
ベイズの定理によれば母数 w とデータ x との間に次のような関係が存在する。

事前分布は、実験によってデータを得る以前の知識を反映し、事後分布は、事前の知識に加えてデータによって学習した知識を反映する。
確率論や統計学の歴史 [ベイズ統計量におけるパラメーターの推定]
ベイズ統計量におけるパラメーターの推定の話、第2回目。
まず、確率論や統計学の目的とは?
原因があって、結果があるが原因が複雑な場合は、偶然の現象として考えます。
ここで、偶然と思われる現象というのは、
・ある商品を購入する/購入しない確率
・犬が歩いたら、棒にあたる確率
・双子が生まれる確率
など。
こういった偶然から法則性を見つけ、部分から全体を推定するのが、確率・統計の目的です。

そもそも、確率論の歴史は、賭けに始まりました。
※ガウスは『誤差論』の中で、最小2乗法を展開しました。
正規分布が「誤差分布」とか「ガウス分布」とよばれるのはこのため。
【始まり】
パスカルとフェルマーの往復書簡の中で、サイコロゲームの解析を行い、順列・組み合わせ論を展開しています。
2項分布はその中に登場。
↓
ベルヌーイ、ラグランジュ、ポアソン、などを経て、ラプラス(『確率の解析的理論』)によって古典的確率論が完成しました。
↓(現代的確率論)
ボレル、ルベーグらによる測度論に置いています。
測度とは長さや面積といった概念を数学的に厳密に定式化すること。
【統計学の発展】
18世紀の数学者ベイズによって発展。
標本から確率分布の性質を求める「統計的推測」について考えました。
ベイズ統計量におけるパラメーターの推定 [ベイズ統計量におけるパラメーターの推定]
ベイズ統計量におけるパラメーターの推定
昔のパワーポイントを整理してたら、「ベイズ統計量におけるパラメーターの推定」なるものが出てきた。
こんなことを考えていたんだなぁと、しみじみ。
昔、↓のブログを見たことがある。
(y+1)/(n+2) instead of y/n
http://www.stat.columbia.edu/~cook/movabletype/archives/2007/05/y1n2_instead_of.html
ざっと、要約すると、ある確率を求めるときに、例えば、レスポンス率などを求めるときに、
100人に送って、30人が反応したとすると、
30 / 100 = 0.300
と考えるよりも、
31 / 102 = 0.303...
と推定するという話。
なんで、y/n ではなく、 (y+1)/(n+2) なのか?
これは、2項分布の Posterior Mean が (y+α)/(n+α+β)で、α=1, β=1 した値である。
α=1, β=1が何を表しているかといえば、事前分布(ベータ分布)が一様分布であることを表している。
もう少し詳しく書くと、ベータ分布のpの期待値は
(Prior Mean)
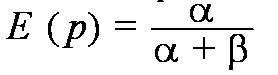
(Posterior Mean)
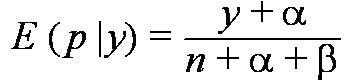
となって、上の式から得られたベイズ統計量は
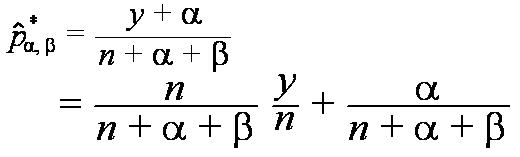
となる。
事前分布と事後分布が同じベータ分布となっているご利益は、また別の機会にでも。

