階層ベイズの信頼区間を求める [階層ベイズ]
階層ベイズを使ったモデルを作成し、予測を行う際に、
予測値そのものは、普通に計算できます。
一方、統計モデルということで、予測値の信頼区間を出すにはどうすれば良いのか?が疑問でした。
ということで、指導教官の先生に確認したところ、以下の手順で信頼区間を計算するのが分かりやすいとのことでした。
1) MCMCの場合は、尤度が安定する前のステップを除去して使います。
具体的には、仮に、10万回シミュレーションしたとし、最初の8万回を捨てるとします。
残りの2万回を使って信頼区間を計算していきます。
2) 2万回の計算結果には、各イテレーションごとのβが保存されており、
かつ、観測変数 X も分かっています。
各イテレーションの β と x を使い、y を2万個出力する。
すると、2万個の y の分布が出来上がるので、両方の端を捨てた部分が信頼区間になる、とのことでした。
予測値そのものは、普通に計算できます。
一方、統計モデルということで、予測値の信頼区間を出すにはどうすれば良いのか?が疑問でした。
ということで、指導教官の先生に確認したところ、以下の手順で信頼区間を計算するのが分かりやすいとのことでした。
1) MCMCの場合は、尤度が安定する前のステップを除去して使います。
具体的には、仮に、10万回シミュレーションしたとし、最初の8万回を捨てるとします。
残りの2万回を使って信頼区間を計算していきます。
2) 2万回の計算結果には、各イテレーションごとのβが保存されており、
かつ、観測変数 X も分かっています。
各イテレーションの β と x を使い、y を2万個出力する。
すると、2万個の y の分布が出来上がるので、両方の端を捨てた部分が信頼区間になる、とのことでした。
階層ベイズで作成したパラメータのシミュレーションについて その2 [階層ベイズ]
里村先生の『マーケティング・モデル』をベースに、階層ベイズのモデルを作り、シミュレーションを行いました。
")
階層ベイズで作成したパラメータのシミュレーションについて その1
http://skellington.blog.so-net.ne.jp/2018-05-31
↑
こちらの続き
階層ベイズモデルを予測で使う場合についてです。
1) まず、階層ベイズモデルで予測した人の別の観測データを用いて予測をする場合。
つまり、MCMCで求めたベータを使える場合です。
2) 次に、階層ベイズモデルで用いなかった新しいIDに対して予測をする場合。
こちらは、個人ごとのベータは推定できていません。
なので、Delta(階層部分のパラメータ)から個人ごとのベータを推定する必要があります。
まず、階層部分のパラメータですが、
真の値(実際には不明)
[,1] [,2]
[1,] -2 1
[2,] -1 2
シミュレーションで求めた値
[,1] [,2]
[1,] -2.04 1.00
[2,] -1.03 2.00
ということで、非常に良い当てはまりになっています。
一方で、ベータの値を比較してみると、
1) 階層ベイズモデルで予測した人の別の観測データを用いて予測をする場合
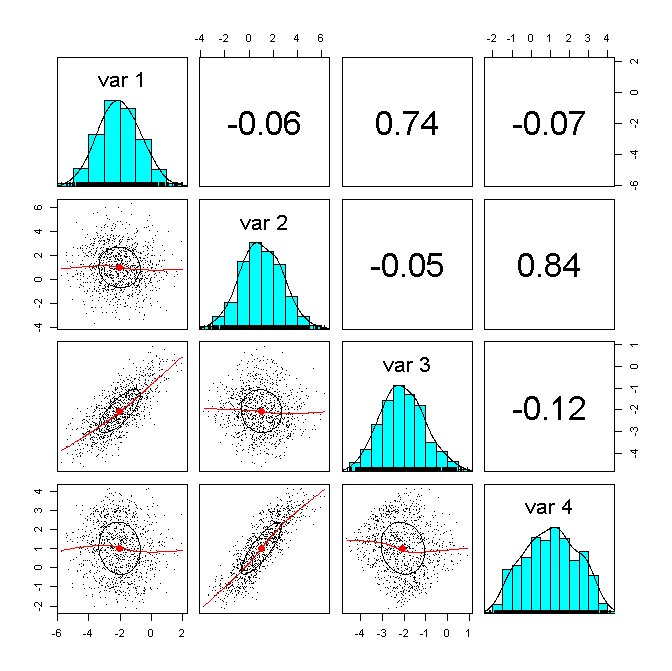
真のベータと強い相関があることが分かります。
つまり、良い予測をすることが分かりました。
2) 階層ベイズモデルで用いなかった新しいIDに対して予測をする場合
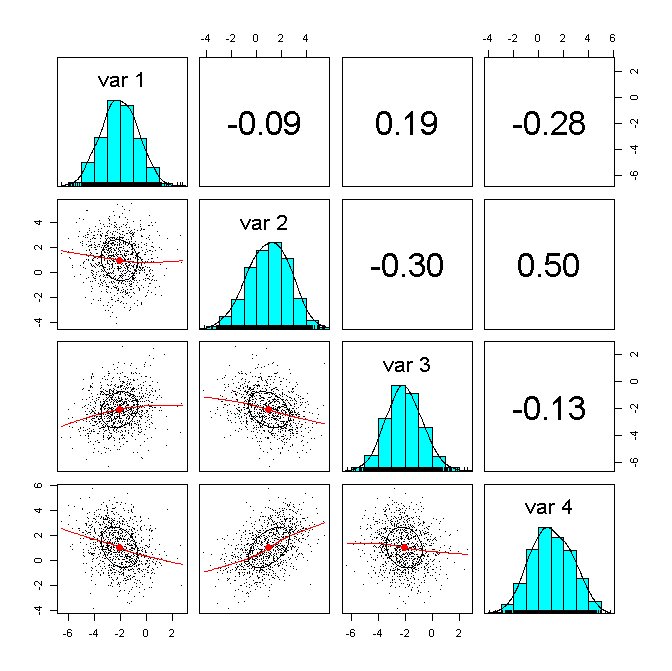
相関係数が低いです。
つまり、このままでは、良い予測ができないことが分かりました。
いくつか原因を考えてみると、観測モデルのベータを推定する際に階層モデルのパラメータに誤差を加えるのですが、この分散が大きいことが原因だと思われます。
実際は、全くの未知というわけではなく、未知のIDに対しても、それなりの情報を持っているわけで、この辺りの情報を上手くベイズ的に与えることができれば、良いかと思われますが、この辺りは、自分の限界なので、研究していきたいと思います。
マーケティング・モデル 第2版 (Rで学ぶデータサイエンス 13)
- 作者: 里村 卓也
- 出版社/メーカー: 共立出版
- 発売日: 2015/04/09
- メディア: 単行本
階層ベイズで作成したパラメータのシミュレーションについて その1
http://skellington.blog.so-net.ne.jp/2018-05-31
↑
こちらの続き
階層ベイズモデルを予測で使う場合についてです。
1) まず、階層ベイズモデルで予測した人の別の観測データを用いて予測をする場合。
つまり、MCMCで求めたベータを使える場合です。
2) 次に、階層ベイズモデルで用いなかった新しいIDに対して予測をする場合。
こちらは、個人ごとのベータは推定できていません。
なので、Delta(階層部分のパラメータ)から個人ごとのベータを推定する必要があります。
## 1) 階層ベイズモデルで予測した人の別の観測データを用いて予測をする場合
org.beta <- matrix(0,nrow=hh,ncol=nvar)
for (i in 1:hh) {
org.beta[i,] <- hhdata[[i]]$beta
}
z <- cbind(org.beta,beta.mean)
psych::pairs.panels(z, pch=".")
## 2) 階層ベイズモデルで用いなかった新しいIDに対して予測をする場合
# 個人のβの平均値を計算(MCMCより)
beta.mean <- matrix(0,nrow=hh,ncol=nvar)
for(j in 1:nvar){
for(i in 1:hh){beta.mean[i,j] <- mean(betadraw[i,j,R0:R1])}
}
# 個人のβの平均値を計算2(階層部分より)
beta2.mean <- matrix(0,nrow=hh,ncol=nvar)
Delta2 <- matrix(apply(Deltadraw[R0:R1,],2,mean),nz,nvar)
for (i in 1:hh) {
beta2.mean[i,] <- t(Delta2)%*%Z[i,]+as.vector(t(chol(Vbeta))%*%rnorm(nvar))
}
# beta.mean と beta2.mean の散布図
x <- cbind(beta.mean,beta2.mean)
psych::pairs.panels(x, pch=".")
まず、階層部分のパラメータですが、
真の値(実際には不明)
[,1] [,2]
[1,] -2 1
[2,] -1 2
シミュレーションで求めた値
[,1] [,2]
[1,] -2.04 1.00
[2,] -1.03 2.00
ということで、非常に良い当てはまりになっています。
一方で、ベータの値を比較してみると、
1) 階層ベイズモデルで予測した人の別の観測データを用いて予測をする場合
真のベータと強い相関があることが分かります。
つまり、良い予測をすることが分かりました。
2) 階層ベイズモデルで用いなかった新しいIDに対して予測をする場合
相関係数が低いです。
つまり、このままでは、良い予測ができないことが分かりました。
いくつか原因を考えてみると、観測モデルのベータを推定する際に階層モデルのパラメータに誤差を加えるのですが、この分散が大きいことが原因だと思われます。
実際は、全くの未知というわけではなく、未知のIDに対しても、それなりの情報を持っているわけで、この辺りの情報を上手くベイズ的に与えることができれば、良いかと思われますが、この辺りは、自分の限界なので、研究していきたいと思います。
階層ベイズで作成したパラメータのシミュレーションについて その1 [階層ベイズ]
里村先生の『マーケティング・モデル』をベースに、階層ベイズのモデルを作り、シミュレーションを行いました。
コードは、教科書に載っていますし、共立出版のホームページからもダウンロードできます。
以下、里村先生のコードをベースに修正したものを載せていますが、
一部、教科書そのままだと、上手く動かない部分があるので修正しています。
(オリジナルのコードは、上記を参照してください。)
まずは、初期設定から。
階層部分のパラメータ(Delta)は、
> Delta
[,1] [,2]
[1,] -2 1
[2,] -1 2
で与えています。
続いて、シミュレーションデータの発生とロジットモデルの尤度関数を定義しています。
単純な二項ロジットなので、尤度関数も簡単です。
推定方法ですが、メトロポリス・ヘイスティングで推定しています。
シミュレーション回数は1万回。
1万回のシミュレーションなので、数分待てば、計算が終了します。
続けて、出てきた結果を確認。
ここまでは、オリジナルコードとほとんど同じです。
続けて、階層ベイズで作ったモデルを予測で使う場合、どうなるかです。
マーケティング・モデル 第2版 (Rで学ぶデータサイエンス 13)
- 作者: 里村 卓也
- 出版社/メーカー: 共立出版
- 発売日: 2015/04/09
- メディア: 単行本
コードは、教科書に載っていますし、共立出版のホームページからもダウンロードできます。
以下、里村先生のコードをベースに修正したものを載せていますが、
一部、教科書そのままだと、上手く動かない部分があるので修正しています。
(オリジナルのコードは、上記を参照してください。)
まずは、初期設定から。
## 階層ベイズ2項ロジットモデルの推定
library(bayesm)
library(psych) ## パラメータの散布図で使用
set.seed(1234)
nvar <- 2 ## ロジットモデルの説明変数の数
hh <- 1000 ## 個人数
nobs <- 10 ## 個人あたりの選択回数
nz <- 2 ## 個人属性の説明変数の数
Z <- matrix(c(rep(1,hh),runif(hh,min=-1,max=1)),hh,nz)
Delta <- matrix(c(-2,-1,1,2),nz,nvar)
iota <- matrix(1,nvar,1)
Vbeta <- diag(nvar)+.5*iota%*%t(iota)
階層部分のパラメータ(Delta)は、
> Delta
[,1] [,2]
[1,] -2 1
[2,] -1 2
で与えています。
続いて、シミュレーションデータの発生とロジットモデルの尤度関数を定義しています。
単純な二項ロジットなので、尤度関数も簡単です。
## シミュレーションデータの発生
hhdata=NULL
for (i in 1:hh) {
beta <- t(Delta)%*%Z[i,]+as.vector(t(chol(Vbeta))%*%rnorm(nvar))
X <- matrix(runif(nobs*nvar),nobs,nvar)
prob <- exp(X%*%beta)/(1+exp(X%*%beta))
unif <- runif(nobs,0,1)
y <- ifelse(unif < prob,1,0)
hhdata[[i]] <- list(y=y,X=X,beta=beta)
}
## 2項ロジットモデルの対数尤度関数の定義
loglike <- function(y, X, beta) {
p1 <- exp(X %*% beta)/(1 + exp(X %*% beta))
ll <- y * log(p1) + (1 - y) * log(1 - p1)
sum(ll)
}
推定方法ですが、メトロポリス・ヘイスティングで推定しています。
シミュレーション回数は1万回。
## ベイズ推定のための設定
R<- 10000
sbeta<- 1.5
keep<- 1
nhh <- length(hhdata)
nz <- ncol(Z)
nvar <- ncol(X)
## 事前分布のパラメータ
nu<- nvar+3
V<- nu * diag(rep(1,nvar))
ADelta <- 0.01 * diag(nz)
Deltabar <- matrix(rep(0, nz * nvar), nz, nvar)
## サンプリング結果の保存スペースの作成
Vbetadraw <- matrix(double(floor(R/keep) * nvar * nvar), floor(R/keep), nvar * nvar)
betadraw <- array(double(floor(R/keep) * nhh * nvar), dim = c(nhh, nvar, floor(R/keep)))
Deltadraw <- matrix(double(floor(R/keep) * nvar * nz), floor(R/keep), nvar * nz)
## 棄却率と対数尤度
reject <- array(0, dim = c(R/keep))
llike <- array(0, dim = c(R/keep))
## 初期値の設定
oldbetas <- matrix(double(nhh * nvar), nhh, nvar)
oldVbeta <- diag(nvar)
oldVbetai <- diag(nvar)
oldDelta <- matrix(double(nvar * nz), nz, nvar)
betad <- array(0, dim = c(nvar))
betan <- array(0, dim = c(nvar))
## 階層ベイズ2項ロジットモデルによる推定
for (iter in 1:R) {
rej <- 0
logl <- 0
# sV <- sbeta * oldVbeta # 里村先生のオリジナル
sV <- sbeta * V
root <- t(chol(sV))
## MH法による個人別betaのサンプリング
for (i in 1:nhh) {
betad <- oldbetas[i, ]
# betan <- betad + root %*% rnorm(nvar) # 里村先生のオリジナル
betan <- betad + root %*% rnorm(nvar) * 0.1
lognew <- loglike(hhdata[[i]]$y, hhdata[[i]]$X, betan)
logold <- loglike(hhdata[[i]]$y, hhdata[[i]]$X, betad)
logknew <- -0.5 * (t(betan) - Z[i, ] %*% oldDelta) %*% oldVbetai %*% (betan - t(Z[i, ] %*% oldDelta))
logkold <- -0.5 * (t(betad) - Z[i, ] %*% oldDelta) %*% oldVbetai %*% (betad - t(Z[i, ] %*% oldDelta))
alpha <- exp(lognew + logknew - logold - logkold)
if (alpha == "NaN")
alpha = -1
u <- runif(1)
if (u < alpha) {
oldbetas[i, ] <- betan
logl <- logl + lognew
}
else {
logl <- logl + logold
rej <- rej + 1
}
}
## 多変量回帰によるDeltaのギブスサンプリング(bayesmのrmultiregを利用)
out <- rmultireg(oldbetas, Z, Deltabar, ADelta, nu, V)
oldDelta <- out$B
oldVbeta <- out$Sigma
oldVbetai <- solve(oldVbeta)
## 現在までのサンプリング数の表示
if ((iter%%100) == 0) {
cat("繰り返し数", iter, fill = TRUE)
}
## keep回毎にサンプリング結果を保存
mkeep <- iter/keep
if (iter%%keep == 0){
Deltadraw[mkeep, ] <- as.vector(oldDelta)
Vbetadraw[mkeep, ] <- as.vector(oldVbeta)
betadraw[, , mkeep] <- oldbetas
llike[mkeep] <- logl
reject[mkeep] <- rej/nhh
}
}
1万回のシミュレーションなので、数分待てば、計算が終了します。
続けて、出てきた結果を確認。
## log-likelihoodのプロット
plot(llike,type="l",xlab="Iterations/10",ylab="",main="Log Likelihood")
## rejectのプロット
plot(reject,type="l",xlab="Iterations/10",ylab="", main="Rejection Rate of MH Algorithm")
## 平均パラメータのプロット
Deltas<-as.vector(Delta)
matplot(Deltadraw,type="l",xlab="Iterations/10",ylab="", main="Draw of Delta")
## burn-in 期間
R0<-floor(R/2)+1
R1=R
## Deltaの統計値
apply(Deltadraw[R0:R1,],2,mean)
rbind(Deltas,apply(Deltadraw[R0:R1,],2,quantile,probs=c(0.025,0.5,0.975)))
ここまでは、オリジナルコードとほとんど同じです。
続けて、階層ベイズで作ったモデルを予測で使う場合、どうなるかです。
階層ベイズのモデル比較 [階層ベイズ]
階層ベイズのモデル比較をまとめてみました。
(備忘録として)
【DIC】
1. 個人のβの平均値を計算
このβとデータを使って、再度、対数尤度(mean_para.loglike)を計算
mean_para.Deviance <- -2 * mean_para.loglike
2. 各MCMCの対数尤度の平均(mean.loglike)を計算
mean.Deviance <- -2 * mean.loglike
3. pD & DIC
pD <- mean.Deviance - mean_para.Deviance
DIC <- mean.Deviance + pD
pDは、AICでいうところの罰則項みたいなもの。
ただ、パラメータ数が増えても、pDが必ず増えない場合もある。
【log marginal density】
bayesmには、log marginal densityを計算する関数が用意されているので、それを使えば一発で答えが出ます。
# LMD(log marginal density)
LMD <- llike[-(1:mcmc_start)]
logMargDenNR(LMD)
【WAIC】
渡辺先生が提唱されている指標。
検証用に2つ作ってみました。
(値は、同じです。)
# WAIC 1
library("matrixStats")
log_lik <- llike[-(1:mcmc_start)]
dim(log_lik) <- if (length(dim(log_lik))==1) c(length(log_lik),1) else
c(dim(log_lik)[1], prod(dim(log_lik)[2:length(dim(log_lik))]))
S <- nrow(log_lik)
n <- ncol(log_lik)
lpd <- colMeans(log_lik)
p_waic <- colVars(log_lik) # 正規化後のデータの各列の分散
elpd_waic <- lpd - p_waic
waic <- -2*elpd_waic
# WAIC 2
lppd <- sum(colMeans(log_lik))
p_waic <- sum(apply(temp,2,var))
waic2 <- -2 * lppd + 2 * p_waic
【ホールドイン、ホールドアウト】
機械学習などでおなじみの、モデルを作っていないデータを使ってどれくらいの予測精度になるかという指標。
まぁ、分かりやすいですね。
(備忘録として)
【DIC】
1. 個人のβの平均値を計算
このβとデータを使って、再度、対数尤度(mean_para.loglike)を計算
mean_para.Deviance <- -2 * mean_para.loglike
2. 各MCMCの対数尤度の平均(mean.loglike)を計算
mean.Deviance <- -2 * mean.loglike
3. pD & DIC
pD <- mean.Deviance - mean_para.Deviance
DIC <- mean.Deviance + pD
pDは、AICでいうところの罰則項みたいなもの。
ただ、パラメータ数が増えても、pDが必ず増えない場合もある。
【log marginal density】
bayesmには、log marginal densityを計算する関数が用意されているので、それを使えば一発で答えが出ます。
# LMD(log marginal density)
LMD <- llike[-(1:mcmc_start)]
logMargDenNR(LMD)
【WAIC】
渡辺先生が提唱されている指標。
検証用に2つ作ってみました。
(値は、同じです。)
# WAIC 1
library("matrixStats")
log_lik <- llike[-(1:mcmc_start)]
dim(log_lik) <- if (length(dim(log_lik))==1) c(length(log_lik),1) else
c(dim(log_lik)[1], prod(dim(log_lik)[2:length(dim(log_lik))]))
S <- nrow(log_lik)
n <- ncol(log_lik)
lpd <- colMeans(log_lik)
p_waic <- colVars(log_lik) # 正規化後のデータの各列の分散
elpd_waic <- lpd - p_waic
waic <- -2*elpd_waic
# WAIC 2
lppd <- sum(colMeans(log_lik))
p_waic <- sum(apply(temp,2,var))
waic2 <- -2 * lppd + 2 * p_waic
【ホールドイン、ホールドアウト】
機械学習などでおなじみの、モデルを作っていないデータを使ってどれくらいの予測精度になるかという指標。
まぁ、分かりやすいですね。
階層ベイズのモデル比較、DICを実装 [階層ベイズ]
階層ベイズモデルのモデル比較をどうするか?
通常のglmなどのモデルでは、AICやBICといった基準がありますが、階層ベイズにはAIC, BICを直接適用することはできません。
Deviance Information Criterion(以下、DIC)を使ってモデル比較をすることができます。
以下、その実装方法。
1) Burn-In以降のパラメータを抽出します。
必要なのは、イテレーションごとに、個人ごとのβと対数尤度を保存。
DIC = mean.Deviance + pD
pD <- mean.Deviance - mean_para.Deviance
Deviance = -2 log p(y|θ) の定義はこちら(↓)。
mean.Deviance
各イテレーションごとに保存しておいた対数尤度の平均から計算します。
mean_para.Deviance
イテレーションごとに、個人ごとのβの平均値を計算。
この平均値とデータから、再度、尤度を計算します。
通常のglmなどのモデルでは、AICやBICといった基準がありますが、階層ベイズにはAIC, BICを直接適用することはできません。
Deviance Information Criterion(以下、DIC)を使ってモデル比較をすることができます。
以下、その実装方法。
1) Burn-In以降のパラメータを抽出します。
必要なのは、イテレーションごとに、個人ごとのβと対数尤度を保存。
DIC = mean.Deviance + pD
pD <- mean.Deviance - mean_para.Deviance
Deviance = -2 log p(y|θ) の定義はこちら(↓)。
mean.Deviance
各イテレーションごとに保存しておいた対数尤度の平均から計算します。
mean_para.Deviance
イテレーションごとに、個人ごとのβの平均値を計算。
この平均値とデータから、再度、尤度を計算します。
普通の回帰ではなく、階層ベイズを使う利点 [階層ベイズ]
階層ベイズで変数が多くなると、計算時間が多くなってしまうので、
なんとか変数選択できないか?と考えました。
例えば、
1. まず、最初に、通常の回帰を行い、有意でないパラメータをみつける
2. 有意な変数のみ、階層ベイズの変数として使用する
というのは、どうかと思いました。
自分の先生に確認したところ、
『階層ベイズは、個人ごとのパラメータを推定できるのが利点。
つまり、普通の回帰(平均的にみれば)では、有意でないかもしれないけど、
ごく少数の人には有効な変数を発見できる。
』
とのことでした。
なるほど、、、
階層ベイズで、個人の異質性を表現することができますが、それは、普通の回帰分析では有意な変数でもある人にとって見れば有意でないし、
また、その逆で、有意でない変数もある人にとって見れば、すごく効いてくる変数かもしれない。
個人ごとのβのパラメータのヒストグラムです。
図1:βの平均値は、-0.224
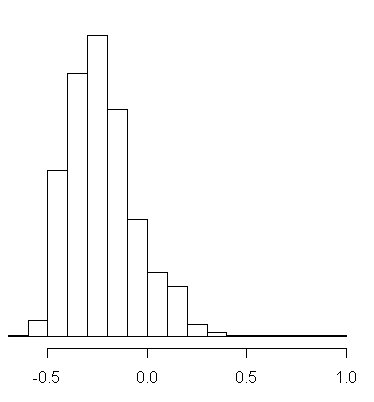
図1は、きれいな正規分布に近い形をしています。
よく見ると、個人ごとに幅はあり、プラスの効果になっている人もいれば、マイナスの効果になっている人もいます。
図2:βの平均値は、0.008
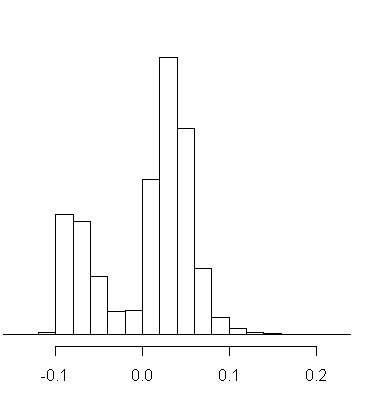
図2は、明らかに二つのタイプの人がいることが分かります。
プラスに効く人とマイナスに効く人。
そして、平均値は、ちょうど二つの谷の0.008となっています。
通常の回帰分析では、このβの効果は、0.008と判断してしまうところですが、
実際は、0.008という平均の値を持っている人は、ほとんどいなくて、
よりマイナスか、よりプラスかのどちらか極端の値を持っている人だけとなります。
なんとか変数選択できないか?と考えました。
例えば、
1. まず、最初に、通常の回帰を行い、有意でないパラメータをみつける
2. 有意な変数のみ、階層ベイズの変数として使用する
というのは、どうかと思いました。
自分の先生に確認したところ、
『階層ベイズは、個人ごとのパラメータを推定できるのが利点。
つまり、普通の回帰(平均的にみれば)では、有意でないかもしれないけど、
ごく少数の人には有効な変数を発見できる。
』
とのことでした。
なるほど、、、
階層ベイズで、個人の異質性を表現することができますが、それは、普通の回帰分析では有意な変数でもある人にとって見れば有意でないし、
また、その逆で、有意でない変数もある人にとって見れば、すごく効いてくる変数かもしれない。
個人ごとのβのパラメータのヒストグラムです。
図1:βの平均値は、-0.224
図1は、きれいな正規分布に近い形をしています。
よく見ると、個人ごとに幅はあり、プラスの効果になっている人もいれば、マイナスの効果になっている人もいます。
図2:βの平均値は、0.008
図2は、明らかに二つのタイプの人がいることが分かります。
プラスに効く人とマイナスに効く人。
そして、平均値は、ちょうど二つの谷の0.008となっています。
通常の回帰分析では、このβの効果は、0.008と判断してしまうところですが、
実際は、0.008という平均の値を持っている人は、ほとんどいなくて、
よりマイナスか、よりプラスかのどちらか極端の値を持っている人だけとなります。
階層ベイズ2項ロジットモデルの推定 [階層ベイズ]
階層ベイズ2項ロジットモデルの推定をする際に、よく使われるのが R のパッケージの "bayesm" でしょうか。
rhierBinLogit / rhierMnlRwMixture という関数を使います。
ただ、細かい設定をしたい場合は、尤度関数を書く必要があります。
## 2項ロジットモデルの対数尤度関数の定義
loglike <- function(y, X, beta) {
u <- X %*% beta
p <- exp(u)/(1 + exp(u))
ll <- y * log(p) + (1 - y) * log(1 - p)
sum(ll)
}
↑
尤度関数はこうなります。
尤度関数を自由に扱うことができれば、ここから Nested Logit に拡張したり、いろいろな分析をすることができるのですが、少しプログラムをいじると、急に動かなくなるのが難しいところ。。。
その場合は、原理原則に戻って、丁寧にプログラムを作っていく必要がありますね。。。
なかなか動かないプログラムが、上手く動くようになった瞬間が、一番目の醍醐味ですね。
二番目の醍醐味は、シミュレーションした結果から、何かマーケティング的に面白い知見を得られた瞬間。
苦労が多ければ多いほど、成功したときに喜びは大きい。
rhierBinLogit / rhierMnlRwMixture という関数を使います。
ただ、細かい設定をしたい場合は、尤度関数を書く必要があります。
## 2項ロジットモデルの対数尤度関数の定義
loglike <- function(y, X, beta) {
u <- X %*% beta
p <- exp(u)/(1 + exp(u))
ll <- y * log(p) + (1 - y) * log(1 - p)
sum(ll)
}
↑
尤度関数はこうなります。
尤度関数を自由に扱うことができれば、ここから Nested Logit に拡張したり、いろいろな分析をすることができるのですが、少しプログラムをいじると、急に動かなくなるのが難しいところ。。。
その場合は、原理原則に戻って、丁寧にプログラムを作っていく必要がありますね。。。
なかなか動かないプログラムが、上手く動くようになった瞬間が、一番目の醍醐味ですね。
二番目の醍醐味は、シミュレーションした結果から、何かマーケティング的に面白い知見を得られた瞬間。
苦労が多ければ多いほど、成功したときに喜びは大きい。
bayesmのcheeseを使ったモデリング、その4~階層ベイズを使った線形回帰モデル [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-10
目的変数:VOLUME(販売数量)
観測モデルの説明変数:DISP(陳列の有無), log_PRICE(販売価格のlog), 切片
階層モデル:切片のみ
RETAILERごとに説明変数のβ(係数)を求めることができます。
本当は、RETAILERに関する情報(土地情報, 店舗数)などを追加で用意できると、それらの特徴ごとに、βの傾向を把握することができます。
例えば、地方都市だと、陳列の有無が重要であるとか。
今回の cheese にはそのような情報が含まれていないので、切片のみのモデルとなっています。
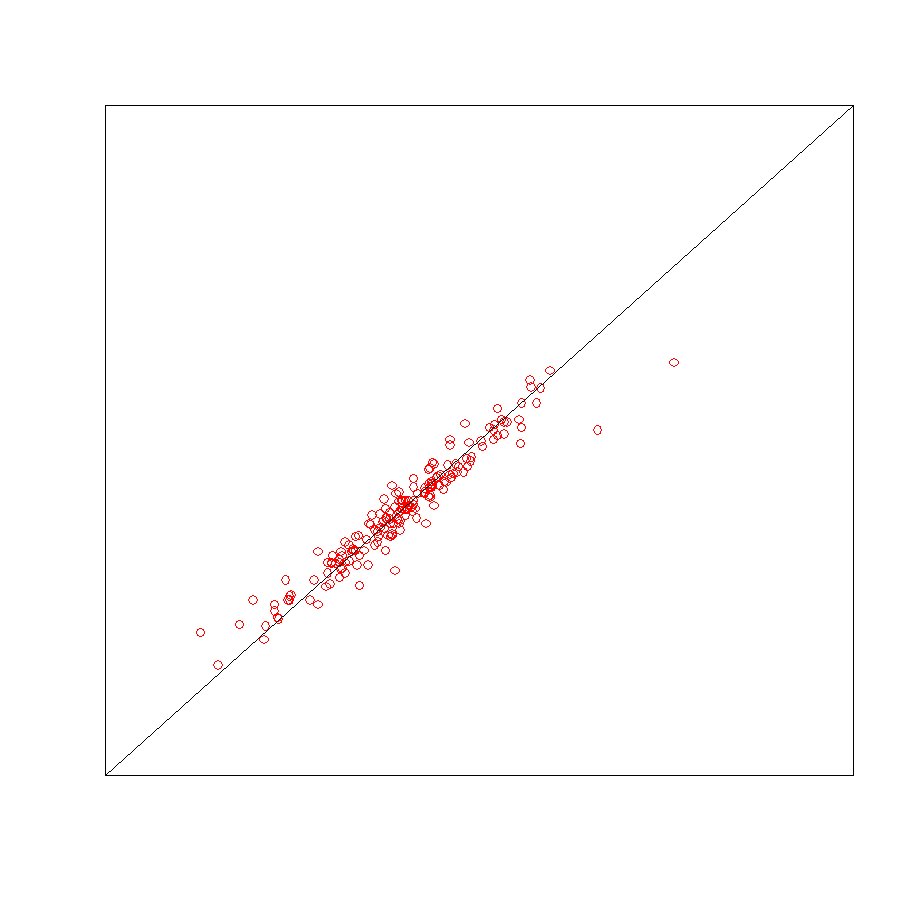
【推定結果と実際の値の散布図】
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-10
目的変数:VOLUME(販売数量)
観測モデルの説明変数:DISP(陳列の有無), log_PRICE(販売価格のlog), 切片
階層モデル:切片のみ
RETAILERごとに説明変数のβ(係数)を求めることができます。
本当は、RETAILERに関する情報(土地情報, 店舗数)などを追加で用意できると、それらの特徴ごとに、βの傾向を把握することができます。
例えば、地方都市だと、陳列の有無が重要であるとか。
今回の cheese にはそのような情報が含まれていないので、切片のみのモデルとなっています。
【推定結果と実際の値の散布図】
bayesmのcheeseを使ったモデリング、その3~機械学習のアプローチ [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル
作成したモデルは、ニューラルネットワーク、決定木(CHAID)です。
通常の線形回帰モデル:0.098
フラグ化した線形回帰モデル:0.705
ニューラルネットワーク:0.816
決定木(CHAID):0.705
フラグ化した線形回帰モデルと決定木の精度が、ほぼ同等となりました。
ニューラルネットワークの精度が、頭一つ抜けていいますね。
決定木がどのように予測をしたか分析してみると、
第一階層は、RETAILERごとにざっくりと分類します。
第二階層以下は、DISPとlog_PRICEで切っていきます。
DISPは、{0, 1}のデータなので、問題ないのですが、
log_PRICEは、連続値のデータが入っています。
そのため、決定木でざっくりと切ってしまうと、その区切りの予測値は全部同じ値になってしまうため、細かい予測値を出すことができません。
このあたりが、ニューラルネットワークより精度が劣る一つの原因になっていると思われます。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル
作成したモデルは、ニューラルネットワーク、決定木(CHAID)です。
通常の線形回帰モデル:0.098
フラグ化した線形回帰モデル:0.705
ニューラルネットワーク:0.816
決定木(CHAID):0.705
フラグ化した線形回帰モデルと決定木の精度が、ほぼ同等となりました。
ニューラルネットワークの精度が、頭一つ抜けていいますね。
決定木がどのように予測をしたか分析してみると、
第一階層は、RETAILERごとにざっくりと分類します。
第二階層以下は、DISPとlog_PRICEで切っていきます。
DISPは、{0, 1}のデータなので、問題ないのですが、
log_PRICEは、連続値のデータが入っています。
そのため、決定木でざっくりと切ってしまうと、その区切りの予測値は全部同じ値になってしまうため、細かい予測値を出すことができません。
このあたりが、ニューラルネットワークより精度が劣る一つの原因になっていると思われます。
bayesmのcheeseを使ったモデリング、その2~RETAILERをフラグ化した線形回帰モデル [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル ← 今回
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
通常の線形回帰モデルでは、個々のRETAILERの特性を上手く吸収できずに、いまいちな結果に終わりました。
「個々のRETAILERごとに反応が変わるならば、RETAILERフラグを作ってはどうだろうか?」
ということでRETAILERをフラグ化してみます。
【推定結果と実際の値の散布図】
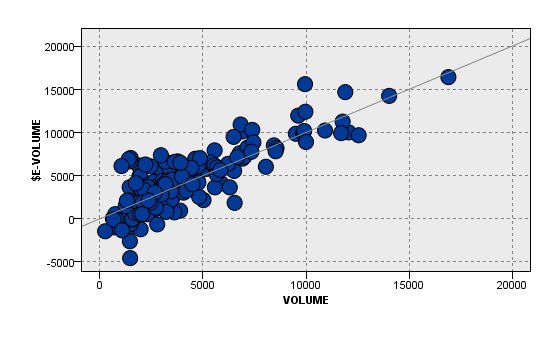
【推定結果と実際の値のピアソンの積率相関係数】
0.705
(通常の回帰モデルの場合は、0.098)
ということで、大幅に精度が上がりました。
RETAILERでフラグ化を行うということは、
説明変数
・切片 → RETAILERごとに異なる
・DISP → 共通の値
・log_PRICE → 共通の値
となっています。
階層ベイズを使った線形回帰モデルでは、切片だけでなくDISPやlog_PRICEもRETAILERごとに異質性を計算することができます。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル ← 今回
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
通常の線形回帰モデルでは、個々のRETAILERの特性を上手く吸収できずに、いまいちな結果に終わりました。
「個々のRETAILERごとに反応が変わるならば、RETAILERフラグを作ってはどうだろうか?」
ということでRETAILERをフラグ化してみます。
【推定結果と実際の値の散布図】
【推定結果と実際の値のピアソンの積率相関係数】
0.705
(通常の回帰モデルの場合は、0.098)
ということで、大幅に精度が上がりました。
RETAILERでフラグ化を行うということは、
説明変数
・切片 → RETAILERごとに異なる
・DISP → 共通の値
・log_PRICE → 共通の値
となっています。
階層ベイズを使った線形回帰モデルでは、切片だけでなくDISPやlog_PRICEもRETAILERごとに異質性を計算することができます。
bayesmのcheeseを使ったモデリング、その1~通常の線形回帰モデル [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
write.table(cheese, "cheese.txt", sep="\t", quote=F, col.names=T, row.names=F, append=F)
↑
いったん、ローカルにテキストファイルとして吐き出して、いろいろなモデルを作っていきます。
モデルは、SPSS Modelerを使用。
cheese のデータ概要ですが、全部で5,555レコード。
IDとなる、RETAILER数は、88社で、RETAILERをIDとすると、同じRETAILERのデータが複数存在します。
階層ベイズを使って線形回帰モデルを行っていくのですが、同じRETAILERでデータが、だいたい60レコード存在します。
5,555レコードあるのですが、
モデル作成用:5,359レコード
モデル検証用:176レコード
にランダムに分けます。
モデル検証用として、RETAILER 88社から2レコードずつ、合計176レコード取っておきます。
まずは、階層ベイズを使わないで、普通に線形回帰をしたらどうなるか?
目的変数:VOLUME
説明変数:DISP, log_PRICE
↑
もともとのデータは、PRICEが入っているのですが、ここではlog変換を行ってlog_PRICEを説明変数としています。
分析結果は、こんな感じ。
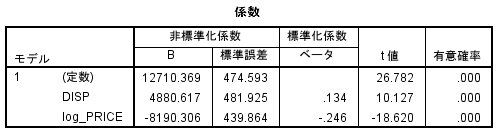
DSIP, log_PRICE ともに有意となっています。
DISP(陳列)した方が売れますし、PRICE(価格)が高くなると売れなくなります。
納得の結果ですね。
ただ、R2は、0.088とそれほど高くありません。
推定結果と実際の値を比較してみても、上手く予想できていないことがよくわかります。
【推定結果と実際の値の散布図】
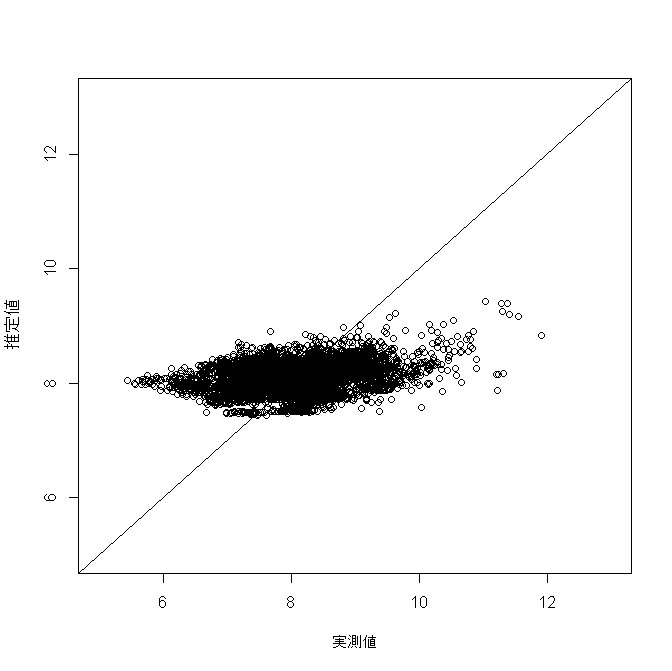
【推定結果と実際の値のピアソンの積率相関係数】
0.098
ということで、ここから工夫をしていくわけですが、
1. 通常の線形回帰モデル ← 今、ココ
2. RETAILER をフラグ化した線形回帰モデル
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
とモデリングしていきます。
write.table(cheese, "cheese.txt", sep="\t", quote=F, col.names=T, row.names=F, append=F)
↑
いったん、ローカルにテキストファイルとして吐き出して、いろいろなモデルを作っていきます。
モデルは、SPSS Modelerを使用。
cheese のデータ概要ですが、全部で5,555レコード。
IDとなる、RETAILER数は、88社で、RETAILERをIDとすると、同じRETAILERのデータが複数存在します。
階層ベイズを使って線形回帰モデルを行っていくのですが、同じRETAILERでデータが、だいたい60レコード存在します。
5,555レコードあるのですが、
モデル作成用:5,359レコード
モデル検証用:176レコード
にランダムに分けます。
モデル検証用として、RETAILER 88社から2レコードずつ、合計176レコード取っておきます。
まずは、階層ベイズを使わないで、普通に線形回帰をしたらどうなるか?
目的変数:VOLUME
説明変数:DISP, log_PRICE
↑
もともとのデータは、PRICEが入っているのですが、ここではlog変換を行ってlog_PRICEを説明変数としています。
分析結果は、こんな感じ。
DSIP, log_PRICE ともに有意となっています。
DISP(陳列)した方が売れますし、PRICE(価格)が高くなると売れなくなります。
納得の結果ですね。
ただ、R2は、0.088とそれほど高くありません。
推定結果と実際の値を比較してみても、上手く予想できていないことがよくわかります。
【推定結果と実際の値の散布図】
【推定結果と実際の値のピアソンの積率相関係数】
0.098
ということで、ここから工夫をしていくわけですが、
1. 通常の線形回帰モデル ← 今、ココ
2. RETAILER をフラグ化した線形回帰モデル
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
とモデリングしていきます。
マーケティング・データ分析の基礎 [階層ベイズ]
里村先生の本を2冊買いました。
本当は、下の二冊目を買おうとしたのですが、間違えて一冊目を買ってしまいました
(^^;
買われる方はご注意を。
『マーケティング・データ分析の基礎』
")
こちらの本は、Rの基本的な操作方法が中心となっています。
後半、階層クラスモデルやロジットモデルの話が出てきます。
Rの使い方に慣れてない方は、こちらの本から読まれると良いと思います。
『マーケティング・モデル』
最尤法による推定から、階層ベイズモデルまで話が展開されています。
マーケティングで階層ベイズを使いたい人はこちらの本がとても参考になると思います。
本当は、下の二冊目を買おうとしたのですが、間違えて一冊目を買ってしまいました
(^^;
買われる方はご注意を。
『マーケティング・データ分析の基礎』
マーケティング・データ分析の基礎 (シリーズ Useful R 3)
- 作者: 里村 卓也
- 出版社/メーカー: 共立出版
- 発売日: 2014/10/24
- メディア: 単行本
こちらの本は、Rの基本的な操作方法が中心となっています。
後半、階層クラスモデルやロジットモデルの話が出てきます。
Rの使い方に慣れてない方は、こちらの本から読まれると良いと思います。
『マーケティング・モデル』
マーケティング・モデル 第2版 (Rで学ぶデータサイエンス 13)
- 作者: 里村 卓也
- 出版社/メーカー: 共立出版
- 発売日: 2015/04/09
- メディア: 単行本
最尤法による推定から、階層ベイズモデルまで話が展開されています。
マーケティングで階層ベイズを使いたい人はこちらの本がとても参考になると思います。
ビックデータの落とし穴 [階層ベイズ]
4月から、新しい授業が始まりましたが、「なるほど!」と思える事も多く、備忘録として残しておきます。
【ビックデータの落とし穴】
「データの動的構造と多変量因果構造の同時モデル」が難しい。
偶然の相関の問題。
1万検定を行うと100個くらい1%有意になるものが発生する。
統計的有意性症候群になってはダメ。
構造が不均一(質の悪いデータ)
階層ベイズ、潜在クラスを使うことで色々なことが分かってくる。
SVMやNNは、ブラックボックス?
回帰構造不均一性をデータから学習するから精度が良い。
一方、階層ベイズは、この人にはこの人には効くが、別の人には説明変数が効くということを表現することができる。
樹形モデル(決定木)は、ニューラルネットワークに比べたら精度は悪いが、人間にとって非常に理解しやすい。
【AI(機械学習)と統計モデルの棲み分け】
機械学習(AI):目的に対する最適化をスピーディーに作ることが出来る。
ただ、色々なところで、おかしなことが起こっていることを認識すること。
統計モデル:人の知識を利用する。
構造を表現、モデリングすることで、マーケティング施策に役立つ。
ベストパフォーマンスだけでなく、ワーストパフォーマンスも理解して使うこと。
【研究について重要な事】
1.目的
個性・着想
2. 手段
技術力・創造力
3. 評価
実験の計画
【ビックデータの落とし穴】
「データの動的構造と多変量因果構造の同時モデル」が難しい。
偶然の相関の問題。
1万検定を行うと100個くらい1%有意になるものが発生する。
統計的有意性症候群になってはダメ。
構造が不均一(質の悪いデータ)
階層ベイズ、潜在クラスを使うことで色々なことが分かってくる。
SVMやNNは、ブラックボックス?
回帰構造不均一性をデータから学習するから精度が良い。
一方、階層ベイズは、この人にはこの人には効くが、別の人には説明変数が効くということを表現することができる。
樹形モデル(決定木)は、ニューラルネットワークに比べたら精度は悪いが、人間にとって非常に理解しやすい。
【AI(機械学習)と統計モデルの棲み分け】
機械学習(AI):目的に対する最適化をスピーディーに作ることが出来る。
ただ、色々なところで、おかしなことが起こっていることを認識すること。
統計モデル:人の知識を利用する。
構造を表現、モデリングすることで、マーケティング施策に役立つ。
ベストパフォーマンスだけでなく、ワーストパフォーマンスも理解して使うこと。
【研究について重要な事】
1.目的
個性・着想
2. 手段
技術力・創造力
3. 評価
実験の計画
一般化線形モデル、階層ベイズ、状態空間モデル [階層ベイズ]
久保先生による応用統計の集中講義がありました。
授業は、こちらの本がベースとなっています。
")
こちらの本では、階層ベイズまでとなっていますが、授業では状態空間モデルまでの説明がありました。
この本もそうですし、授業もそうだったのですが、後半急激に加速していく感じがします。
前半部分は付いてこれる人は多数いると思うのですが、後半の章に進むにつれて付いてこれる人は半減期的になっているんじゃないでしょうか。(^^;
こういう場合は、自分でいろんな事例を試してみると理解が深まると思います。
授業は、こちらの本がベースとなっています。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
こちらの本では、階層ベイズまでとなっていますが、授業では状態空間モデルまでの説明がありました。
この本もそうですし、授業もそうだったのですが、後半急激に加速していく感じがします。
前半部分は付いてこれる人は多数いると思うのですが、後半の章に進むにつれて付いてこれる人は半減期的になっているんじゃないでしょうか。(^^;
こういう場合は、自分でいろんな事例を試してみると理解が深まると思います。
「データ解析のための統計モデリング入門」8章 メトロポリス法 [階層ベイズ]
「データ解析のための統計モデリング入門」8章 MCMCとメトロポリス法について。
ふらふら試行錯誤からメトロポリス法へ
1. ある初期値からスタートする。(例:q = 0.30)
2. 0.01、あるいは、-0.01だけ変化させる。
3. 対数尤度が改善されれば、その値を採用し、そうでない場合は、元の値を採用する。
↑
ふらふら試行錯誤の場合
3. ある一定の確率 r で、値が悪くても新しい値を採用する
↑
ふらふら試行錯誤からメトロポリス法へ
r = L(q新)/L(q)
(例)
元 q = 0.30, -46.378
新 q_new = 0.290, -47.619
r = exp(-47.619 + 46.378) = 0.289
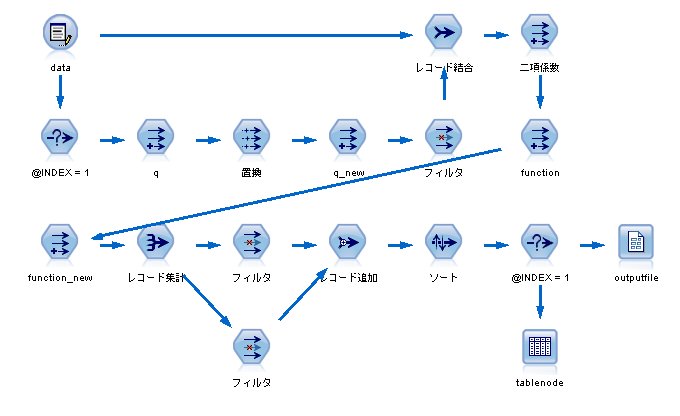
【r】というノードを作成しています。
min(1, exp(function_new_Sum - function_Sum))
同時に【rand】という乱数を発生させ、r の値と比較することで、
"ある一定の確率 r で、値が悪くても新しい値を採用する"
という状態を作ることができます。
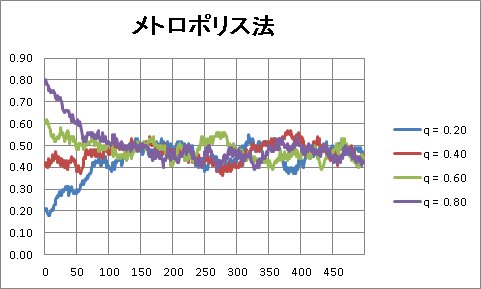
シミュレーションの結果は、こちら。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
ふらふら試行錯誤からメトロポリス法へ
1. ある初期値からスタートする。(例:q = 0.30)
2. 0.01、あるいは、-0.01だけ変化させる。
↑
ふらふら試行錯誤の場合
3. ある一定の確率 r で、値が悪くても新しい値を採用する
↑
ふらふら試行錯誤からメトロポリス法へ
r = L(q新)/L(q)
(例)
元 q = 0.30, -46.378
新 q_new = 0.290, -47.619
r = exp(-47.619 + 46.378) = 0.289
【r】というノードを作成しています。
min(1, exp(function_new_Sum - function_Sum))
同時に【rand】という乱数を発生させ、r の値と比較することで、
"ある一定の確率 r で、値が悪くても新しい値を採用する"
という状態を作ることができます。
シミュレーションの結果は、こちら。
「データ解析のための統計モデリング入門」8章 ふらふら試行錯誤 [階層ベイズ]
「データ解析のための統計モデリング入門」8章 MCMCとメトロポリス法について。
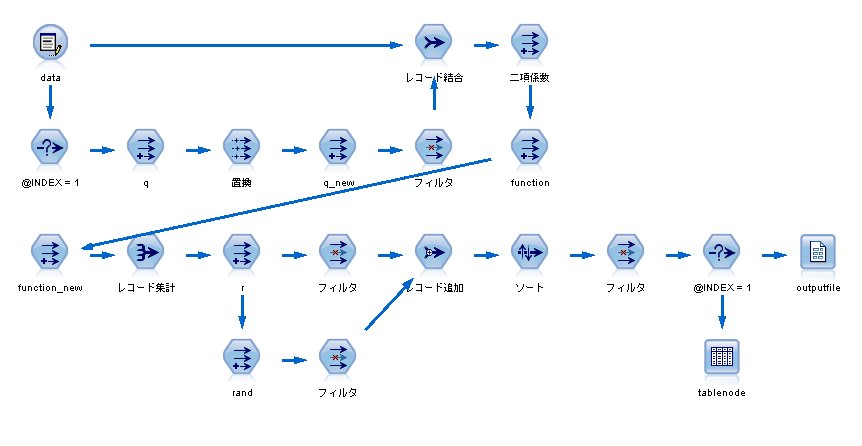
まずは、対数尤度を計算するストリームを作る必要があります。
対数尤度の計算式は、
となるのですが、あらかじめ、二項係数を作っておく必要があります。
【二項係数】
尤度を計算するノードとして、
function
data * log(q) + (8 - data) * log(1 - q) + log(二項係数)
function_new
data * log(q_new) + (8 - data) * log(1 - q_new) + log(二項係数)
各レコードの値を計算し、最後に集計をすれば、完成です。
完成したストリームはこちら。
スクリプトは、
q = 0.30 とした場合、
-46.378
となります。
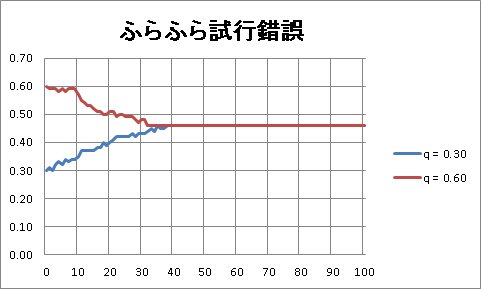
ふらふら試行錯誤のロジックとして、
1. ある初期値からスタートする。(例:q = 0.30)
2. 0.01、あるいは、-0.01だけ変化させる。
3. 対数尤度が改善されれば、その値を採用し、そうでない場合は、元の値を採用する。
これをストリームで書いて、後は、100回ほどループをさせれば、OK!
35回くらいで、最大値 0.46 に張り付いているのがわかります。
初期値を 0.30 にしても、0.60 にしても同じ結果になります。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
まずは、対数尤度を計算するストリームを作る必要があります。
対数尤度の計算式は、
data * log(q) + (8 - data) * log(1 - q) + log(二項係数)
となるのですが、あらかじめ、二項係数を作っておく必要があります。
【二項係数】
# Rの場合は、choose(8, x)
if data = 0 then 1
elseif data = 1 then 8
elseif data = 2 then 28
elseif data = 3 then 56
elseif data = 4 then 70
elseif data = 5 then 56
elseif data = 6 then 28
elseif data = 7 then 8
elseif data = 8 then 1
else -1 endif
尤度を計算するノードとして、
function
data * log(q) + (8 - data) * log(1 - q) + log(二項係数)
function_new
data * log(q_new) + (8 - data) * log(1 - q_new) + log(二項係数)
各レコードの値を計算し、最後に集計をすれば、完成です。
完成したストリームはこちら。
スクリプトは、
var x
set x = 0.0
for I from 1 to 100
execute 'outputfile'
execute 'tablenode'
set x = value:tablenode.output at 1 1
set q.formula_expr = x
endfor
q = 0.30 とした場合、
-46.378
となります。
ふらふら試行錯誤のロジックとして、
1. ある初期値からスタートする。(例:q = 0.30)
2. 0.01、あるいは、-0.01だけ変化させる。
3. 対数尤度が改善されれば、その値を採用し、そうでない場合は、元の値を採用する。
これをストリームで書いて、後は、100回ほどループをさせれば、OK!
35回くらいで、最大値 0.46 に張り付いているのがわかります。
初期値を 0.30 にしても、0.60 にしても同じ結果になります。
「データ解析のための統計モデリング入門」8章 二項分布の乱数を発生させる [階層ベイズ]
「データ解析のための統計モデリング入門」8章 MCMCとメトロポリス法について。
この本に書かれているアプローチを IBM SPSS Modeler(旧称クレメンタイン)でできないか?と思いやってみることにした。
まず、二項分布の乱数を発生させる必要があります。
IBM SPSS Modelerには、二項分布の乱数を直接発生させる関数はないので、いくつかのノードを組み合わせて作ることにします。
この本には、生存確率 0.45625 に従う各植物個体8個の種子の生死を調べています。
それを20個体調べています。
教科書のデモデータ
Rで二項乱数を発生させる場合
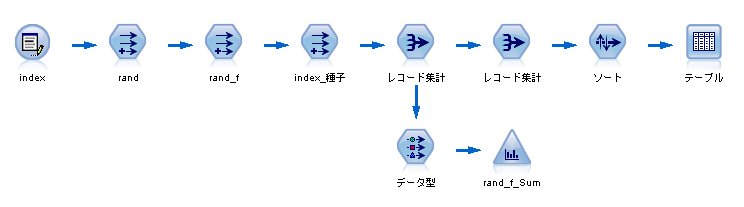
これを、IBM SPSS Modeler(旧称クレメンタイン)で発生させる場合のステップ
1. 入力データを160個用意する(20×8)
2. 0から1までの乱数を発生させる
random(1.0)
3. 各レコードに対し、生死を判別する
if rand <= 0.45625 then 1 else 0 endif
4. 8個の種子グループ(index_種子)を作成する
(index - 1) div 8
5. レコード集計をする
→ 160レコードを20レコードに集計
これで、二項分布の乱数を発生させることができました。
試しに1万個のレコードから 10000 ÷ 8 = 1250 個の乱数を発生させてみると、
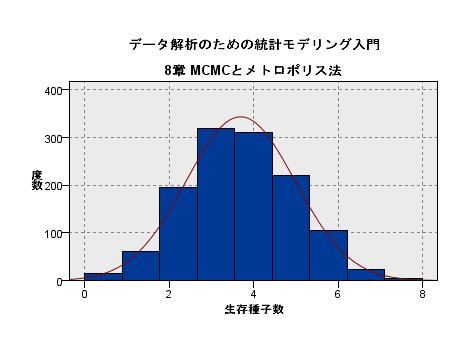
こんなグラフになりました。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
この本に書かれているアプローチを IBM SPSS Modeler(旧称クレメンタイン)でできないか?と思いやってみることにした。
まず、二項分布の乱数を発生させる必要があります。
IBM SPSS Modelerには、二項分布の乱数を直接発生させる関数はないので、いくつかのノードを組み合わせて作ることにします。
この本には、生存確率 0.45625 に従う各植物個体8個の種子の生死を調べています。
それを20個体調べています。
教科書のデモデータ
data <- c(4,3,4,5,5,2,3,1,4,0,1,5,5,6,5,4,4,5,3,4)
Rで二項乱数を発生させる場合
rbinom(20, 8, 0.45625)
これを、IBM SPSS Modeler(旧称クレメンタイン)で発生させる場合のステップ
1. 入力データを160個用意する(20×8)
2. 0から1までの乱数を発生させる
random(1.0)
3. 各レコードに対し、生死を判別する
if rand <= 0.45625 then 1 else 0 endif
4. 8個の種子グループ(index_種子)を作成する
(index - 1) div 8
5. レコード集計をする
→ 160レコードを20レコードに集計
これで、二項分布の乱数を発生させることができました。
試しに1万個のレコードから 10000 ÷ 8 = 1250 個の乱数を発生させてみると、
こんなグラフになりました。
データ解析のための統計モデリング入門 [階層ベイズ]
最近、読み進めている本があります。
非常に解りやすい本でオススメです。
Rを使ってGLM、GLMM、階層ベイズモデルを解りやすく説明しています。
Rを使う人を想定して書かれているので、実際にRをインストールして、読み進めていくのが良いかと思います。
分析をする際に統計モデルなんて不要だ、Modeler(Clementine)で十分だと思っている人も多いかと思います。
実際に、数理モデルを構築しなくても、クロス集計でたいていのことは解りますし。。。
とはいえ、知っていて損をすることはないですし、分析の流れとして、
クロス集計 → 決定木などの機械学習 → 数理モデル → 最適化
といった流れが良いんじゃないだろうか?とも思います。
また、最近、IBM SPSS Modelerのノードの中にもGLMやGLMMが実装されています。
このノード何の役に立つんだっけ?って場合にもこの本が良い参考書になりそうです。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
非常に解りやすい本でオススメです。
Rを使ってGLM、GLMM、階層ベイズモデルを解りやすく説明しています。
Rを使う人を想定して書かれているので、実際にRをインストールして、読み進めていくのが良いかと思います。
分析をする際に統計モデルなんて不要だ、Modeler(Clementine)で十分だと思っている人も多いかと思います。
実際に、数理モデルを構築しなくても、クロス集計でたいていのことは解りますし。。。
とはいえ、知っていて損をすることはないですし、分析の流れとして、
クロス集計 → 決定木などの機械学習 → 数理モデル → 最適化
といった流れが良いんじゃないだろうか?とも思います。
また、最近、IBM SPSS Modelerのノードの中にもGLMやGLMMが実装されています。
このノード何の役に立つんだっけ?って場合にもこの本が良い参考書になりそうです。

