芝浦みらいまちEXPO [住宅・インテリア]
「芝浦みらいまちEXPO」に行ってみました。
芝浦小学校体育館の中で行われる親子参加型のイベントです。
エコカーで遊んだり、新幹線の乗り物があったりしました。
エコなので新幹線も電気を使いません。
子供が乗って、大人は、すぐ横にある自転車で電気を発動させます。
ちょっとしたダイエットです。
後は、絵本を作ったり、お絵かきをしたりしました。
「みらいまちEXPO」ってほど、未来な感じは全くしませんでした…
親子でのんびりと工作をしたり、遊んだりできたのは、良かったです。
帰りは、ゆりかもめの駅まで歩いて帰りましたが、意外と遠かった。
芝浦小学校体育館の中で行われる親子参加型のイベントです。
エコカーで遊んだり、新幹線の乗り物があったりしました。
エコなので新幹線も電気を使いません。
子供が乗って、大人は、すぐ横にある自転車で電気を発動させます。
ちょっとしたダイエットです。
後は、絵本を作ったり、お絵かきをしたりしました。
「みらいまちEXPO」ってほど、未来な感じは全くしませんでした…
親子でのんびりと工作をしたり、遊んだりできたのは、良かったです。
帰りは、ゆりかもめの駅まで歩いて帰りましたが、意外と遠かった。
第63期王将戦リーグ 羽生三冠が全勝で挑戦へ [将棋]
第63期王将戦リーグの最終局が行われました。
羽生三冠は、後手で採用したのは、雁木。
もともと挑戦が決まっていたこともあるのか、少し変わった戦法でした。
王将戦七番勝負の第1局は来年1月12、13日に静岡県掛川市の掛川城・二の丸茶室で行われます。
羽生の王将戦登場は4期ぶり。
久々の渡辺王将・棋王(竜王は失冠)との対決も楽しみです。
▲7六歩 △8四歩 ▲6八銀 △3四歩 ▲6六歩
△6二銀 ▲5六歩 △5四歩 ▲4八銀 △4二銀
▲5八金右 △3二金 ▲7八金 △4一玉 ▲6九玉
△7四歩 ▲6七金右 △5三銀右 ▲5七銀右 △5二金
▲2六歩 △4四歩 ▲2五歩 △4三銀 ▲2四歩
△同 歩 ▲同 飛 △2三歩 ▲2八飛 △6四歩
▲1六歩 △1四歩 ▲4六歩 △8五歩 ▲7七角
△9四歩 ▲9六歩 △7三桂 ▲4八銀 △6二飛
▲8八角 △3一玉 ▲7九玉 △8二飛 ▲7七角
△6二飛 ▲4七銀 △4五歩 ▲同 歩 △9五歩
▲7五歩 △6三金 ▲1五歩 △同 歩 ▲1三歩
△7五歩 ▲1五香 △1四歩 ▲同 香 △1三桂
▲6五歩 △7七角成 ▲同金寄 △6五桂 ▲6七金寄
△9六歩 ▲9八歩 △1六歩 ▲1八歩 △7六歩
▲6六歩 △7七歩成 ▲同 桂 △7六歩 ▲6五歩
△7七歩成 ▲同 銀 △6五歩 ▲4四桂 △6六桂
▲同 金 △同 歩 ▲3二桂成 △同 銀 ▲4四桂
△同 銀 ▲同 歩 △6七歩成 ▲同 金 △7五桂
▲7六銀打 △3九角 ▲4三歩成 △2八角成 ▲3二と
△同 玉 ▲4四角 △4九飛 ▲6九歩 △7八歩
▲同 玉 △4七飛成 ▲3三銀 △4三玉 ▲6二角成
△6七桂成 ▲同 銀 △同 龍 ▲同 玉 △7五桂
▲5七玉 △6七金
まで112手で後手の勝ち
羽生三冠は、後手で採用したのは、雁木。
もともと挑戦が決まっていたこともあるのか、少し変わった戦法でした。
王将戦七番勝負の第1局は来年1月12、13日に静岡県掛川市の掛川城・二の丸茶室で行われます。
羽生の王将戦登場は4期ぶり。
久々の渡辺王将・棋王(竜王は失冠)との対決も楽しみです。
▲7六歩 △8四歩 ▲6八銀 △3四歩 ▲6六歩
△6二銀 ▲5六歩 △5四歩 ▲4八銀 △4二銀
▲5八金右 △3二金 ▲7八金 △4一玉 ▲6九玉
△7四歩 ▲6七金右 △5三銀右 ▲5七銀右 △5二金
▲2六歩 △4四歩 ▲2五歩 △4三銀 ▲2四歩
△同 歩 ▲同 飛 △2三歩 ▲2八飛 △6四歩
▲1六歩 △1四歩 ▲4六歩 △8五歩 ▲7七角
△9四歩 ▲9六歩 △7三桂 ▲4八銀 △6二飛
▲8八角 △3一玉 ▲7九玉 △8二飛 ▲7七角
△6二飛 ▲4七銀 △4五歩 ▲同 歩 △9五歩
▲7五歩 △6三金 ▲1五歩 △同 歩 ▲1三歩
△7五歩 ▲1五香 △1四歩 ▲同 香 △1三桂
▲6五歩 △7七角成 ▲同金寄 △6五桂 ▲6七金寄
△9六歩 ▲9八歩 △1六歩 ▲1八歩 △7六歩
▲6六歩 △7七歩成 ▲同 桂 △7六歩 ▲6五歩
△7七歩成 ▲同 銀 △6五歩 ▲4四桂 △6六桂
▲同 金 △同 歩 ▲3二桂成 △同 銀 ▲4四桂
△同 銀 ▲同 歩 △6七歩成 ▲同 金 △7五桂
▲7六銀打 △3九角 ▲4三歩成 △2八角成 ▲3二と
△同 玉 ▲4四角 △4九飛 ▲6九歩 △7八歩
▲同 玉 △4七飛成 ▲3三銀 △4三玉 ▲6二角成
△6七桂成 ▲同 銀 △同 龍 ▲同 玉 △7五桂
▲5七玉 △6七金
まで112手で後手の勝ち
うまい・やすい・ごゆっくり [マーケティング / 仕事]
吉野家が、「うまい・やすい・ごゆっくり」という新たな戦略商品として「牛すき鍋膳」を発売するらしい。
一方、くら寿司も高い品質のコーヒーを提供し始めた。
売り上げ = 1回あたりの客単価 × 席の数 × 1日当たりの回転数
と考えると、席の数は増やせないので、回転率を上げるか、客単価をあげるか。
回転率ではなく、客単価アップとして、コーヒーとか、牛すき鍋膳を提供しているのでしょう。
ここで、ふと思ったのが、なぜ、寿司でコーヒーなのか?と。
ちなみに、コーヒーの種類は、
・プレミアアイス珈琲
・プレミアアイスラテ
・プレミアホット珈琲
・プレミアホットラテ
の4種類。
寿司との親和性を考えるのなら、高級コーヒーでなく、高級なお茶でも良かったのでは?
自分なりになぜ?(仮説)を考えてみた。
高級なコーヒー
・回転寿司で回っているデザートは洋物なので、コーヒーの方が合う
・誰もやってなかったので、話題性になる
高級なお茶
・そもそもお茶は、無料ってイメージがある。
・くら寿司の単価は安いので、あえて高いお茶を注文使用する顧客がいない?
後、コンビニのドリップコーヒーも流行っていますから、そのあたりも関係しているのかもしれません。
個人的には、洋物デザート&コーヒーよりも、和物デザート&抹茶の方が嬉しいですが…
==================== 追記 ====================
回転寿司で、ケーキなどの洋デザートが多い理由としては、ファミリー(子供連れ)やカップル層を狙っているんでしょうね。
==============================================
一方、くら寿司も高い品質のコーヒーを提供し始めた。
売り上げ = 1回あたりの客単価 × 席の数 × 1日当たりの回転数
と考えると、席の数は増やせないので、回転率を上げるか、客単価をあげるか。
回転率ではなく、客単価アップとして、コーヒーとか、牛すき鍋膳を提供しているのでしょう。
ここで、ふと思ったのが、なぜ、寿司でコーヒーなのか?と。
ちなみに、コーヒーの種類は、
・プレミアアイス珈琲
・プレミアアイスラテ
・プレミアホット珈琲
・プレミアホットラテ
の4種類。
寿司との親和性を考えるのなら、高級コーヒーでなく、高級なお茶でも良かったのでは?
自分なりになぜ?(仮説)を考えてみた。
高級なコーヒー
・回転寿司で回っているデザートは洋物なので、コーヒーの方が合う
・誰もやってなかったので、話題性になる
高級なお茶
・そもそもお茶は、無料ってイメージがある。
・くら寿司の単価は安いので、あえて高いお茶を注文使用する顧客がいない?
後、コンビニのドリップコーヒーも流行っていますから、そのあたりも関係しているのかもしれません。
個人的には、洋物デザート&コーヒーよりも、和物デザート&抹茶の方が嬉しいですが…
==================== 追記 ====================
回転寿司で、ケーキなどの洋デザートが多い理由としては、ファミリー(子供連れ)やカップル層を狙っているんでしょうね。
==============================================
コンビニのコーヒー [マーケティング / 仕事]
セブンイレブンなど各コンビニが挽きたてコーヒーに参入をしています。
そこには、ビジネスとして "美味しい" 何かがあるわけですが、その理由を考えてみました。
1. 利益率が高い!?
コンビニの商品は原価率が高く、薄利多売の商品が多い。
その中で、コーヒーは、原価が安いので、儲かる!?
と思っていましたが、コンビニによってその戦略は違うかもしれません。
セブンイレブンのコーヒーは、100円ですが、その原価率が意外に高いことが話題に上がっています。
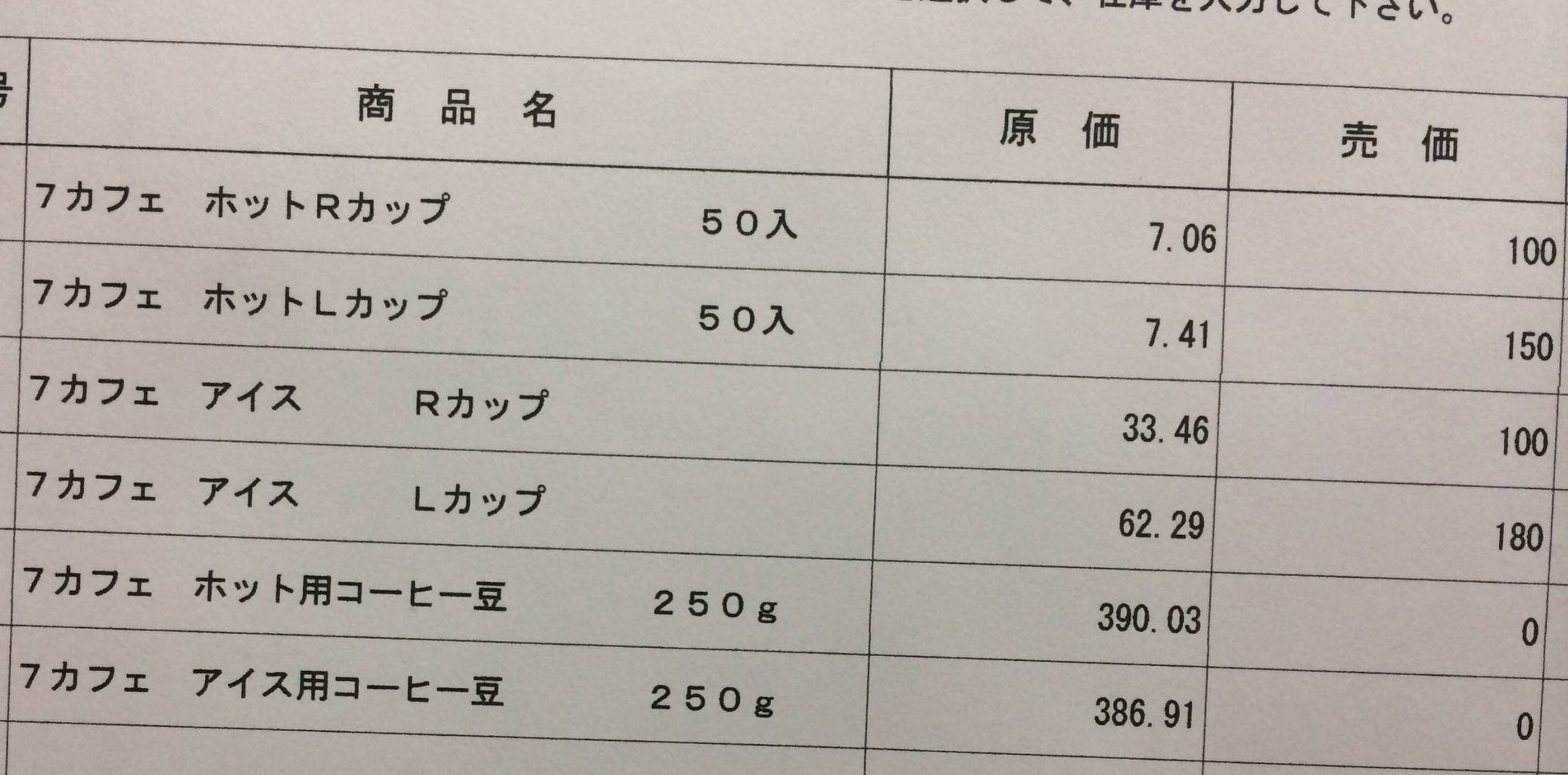
意外と良い豆を使っているようで、46.8円だとか。
原価率は、46.8%。
もしかして、単体では赤字かもしれません。
一方、ローソンだと180円。
同じ原価と仮定すると原価率は、23.4%です。
ローソンは、コーヒー単体で儲けを出そうとしており、セブンイレブンは、コーヒーを呼び水(目玉商品)として考え、集客用の商品として考えているのでしょう。
缶コーヒーの値段は、120円くらい。
あまり美味しくないし、体にも悪い物質が多い。
一方、スタバなどの美味しいけど、コーヒーは高い。
だったら、値段を缶コーヒーより安くして、スタバ並みに美味しいコーヒーを提供することで、集客アップを考えているのかもしれません。
近くのローソンより少し遠いかもしれないけど、セブンイレブンでコーヒーを買おう、という人もいるのではないでしょうか。
その他の理由を調べてみると、
2. ロス率が低い
生鮮食品は、廃棄処分する可能性があるが、コーヒーの廃棄は 0 に近い。
3. 女性客の取り込み
セブンイレブンのコーヒーは、残念ながらカフェラテがありません。
一方、ローソンやファミリーマートは、カフェラテを提供しています。
女性客の集客を意識しているのかもしれません。
個人的には、カフェラテが好きです…
仮面ライダー鎧武 (ガイム) 変身ベルト [ファミリー]
もうすぐクリスマスですね。
昨日、うちの家もクリスマスツリーを出しました。
ということで、サンタクロースのプレゼント!
そろそろ何にしようか決めないと。
ずっとプラレールで遊んでいるし、ディズニーリゾートラインのモノレールが欲しいって言っていました。

が、ここにきて、急に仮面ライダー鎧武 (ガイム) の変身ベルトが欲しいと言い出した。
幼稚園での影響なんでしょうか。
 変身ベルト DX戦極ドライバー 仮面ライダー鎧武&バロンセット")
まぁ、そんなに高くないだろうって調べてみたら、7500円くらいする!
しかも、スイカとか、イチゴとかのオプションも1個1200円くらい。
 DXスイカロックシード")
 DXマンゴーロックシード")
これって、子どもの心理をうまくついていますね。
コンプガチャの応用でしょうか。。。
前作の魔法使いの仮面ライダーウィザードも、次から次へと指輪を作っていましたね。
正確な数は不明ですが、10種類以上はあるんじゃないでしょうか。
今度のフルーツオプションも、どれだけ出てくるのか財布の中が心配です。
ちなみに、「仮面ライダー 鎧武/ガイム ロックシードケース 32個収納可能」って収納ケースもありました。

32個も発売するんかい!!! \('jjj')/ じぇ!じぇ!じぇ!
しかし、最近の子供番組ってオモチャありきで制作している感じが強いですね。
プリキュアにしろ、戦隊もの(獣電戦隊キョウリュウジャー)にしろ。
昨日、うちの家もクリスマスツリーを出しました。
ということで、サンタクロースのプレゼント!
そろそろ何にしようか決めないと。
ずっとプラレールで遊んでいるし、ディズニーリゾートラインのモノレールが欲しいって言っていました。
TOMY プラレール限定車両 ディズニーリゾート『ハピネスイヤー30周年』 ディズニーリゾートライン
- 出版社/メーカー: TDR
- メディア: おもちゃ&ホビー
が、ここにきて、急に仮面ライダー鎧武 (ガイム) の変身ベルトが欲しいと言い出した。
幼稚園での影響なんでしょうか。
仮面ライダー鎧武 (ガイム) 変身ベルト DX戦極ドライバー 仮面ライダー鎧武&バロンセット
- 出版社/メーカー: バンダイ
- メディア: おもちゃ&ホビー
まぁ、そんなに高くないだろうって調べてみたら、7500円くらいする!
しかも、スイカとか、イチゴとかのオプションも1個1200円くらい。
- 出版社/メーカー: バンダイ
- メディア: おもちゃ&ホビー
- 出版社/メーカー: バンダイ
- メディア: おもちゃ&ホビー
これって、子どもの心理をうまくついていますね。
コンプガチャの応用でしょうか。。。
前作の魔法使いの仮面ライダーウィザードも、次から次へと指輪を作っていましたね。
正確な数は不明ですが、10種類以上はあるんじゃないでしょうか。
今度のフルーツオプションも、どれだけ出てくるのか財布の中が心配です。
ちなみに、「仮面ライダー 鎧武/ガイム ロックシードケース 32個収納可能」って収納ケースもありました。
仮面ライダー 鎧武/ガイム ロックシードケース 32個収納可能
- 出版社/メーカー:
- メディア:
32個も発売するんかい!!! \('jjj')/ じぇ!じぇ!じぇ!
しかし、最近の子供番組ってオモチャありきで制作している感じが強いですね。
プリキュアにしろ、戦隊もの(獣電戦隊キョウリュウジャー)にしろ。
秘密保護法案に対する報道について [時事 / ニュース]
秘密保護法、今日にも成立しそうな勢いですね。
この手のニュースに対して、あまりブログに書かなかったんですが、テレビや新聞の報道をみていると、う~ん、と思える内容が多いです。
報道ステーションなんか、毎日、番組開始から、反対!反対!こんなに反対している人がいるんだぞ!というニュースを流しまくっています。
それっぽい新聞社も反対ばっかりです。
自分が見た中でまともな意見を書いている記事は1社だけでした。
マスコミって軸がないように感じていましたが、秘密保護法案に関しては、軸がブレていないようです。
視聴者や読者が期待していることは、何が何でも反対!こんなに悪いことがあるんだぞ!という半ば脅しにも思えるニュースの報道ではありません。
しかも、それがかなり偏った事例を持ち出したりしているあたり、なんだか興ざめも良いところです。
反対を連呼しすぎることで、むしろ、賛成派を増殖しているのではないでしょうか?
秘密保護法案の良いところ、悪いところをきちんと提示をし、反対をするならここが反対ということをいわないと何も議論がはじまりません。
とにかく、必死過ぎです。。。
この手のニュースに対して、あまりブログに書かなかったんですが、テレビや新聞の報道をみていると、う~ん、と思える内容が多いです。
報道ステーションなんか、毎日、番組開始から、反対!反対!こんなに反対している人がいるんだぞ!というニュースを流しまくっています。
それっぽい新聞社も反対ばっかりです。
自分が見た中でまともな意見を書いている記事は1社だけでした。
マスコミって軸がないように感じていましたが、秘密保護法案に関しては、軸がブレていないようです。
視聴者や読者が期待していることは、何が何でも反対!こんなに悪いことがあるんだぞ!という半ば脅しにも思えるニュースの報道ではありません。
しかも、それがかなり偏った事例を持ち出したりしているあたり、なんだか興ざめも良いところです。
反対を連呼しすぎることで、むしろ、賛成派を増殖しているのではないでしょうか?
秘密保護法案の良いところ、悪いところをきちんと提示をし、反対をするならここが反対ということをいわないと何も議論がはじまりません。
とにかく、必死過ぎです。。。
データ解析コンペの中間スコア [データサイエンス、統計モデル]
データ解析コンペの中間スコアを提出する日でした。
スコア自体の計算に時間がかかりました。
今回の手法は、協調フィルタリングといった手法ではなく、カスタマと商品の属性の関係を元にモデリングを行うという手法を使っています。
過去の経験から、協調フィルタリングやアソシエーションルールをベースにしたものより、良い精度がでると思うのですが、計算する範囲をうまく抑えてあげないと、数億レコードとか数十億レコードと一気にレコード数が増えてしまうので注意が必要です。
出来としては、50%くらい。
最終発表に向けて、どこまで精度を上げることができるか。
それは、どこまで分析に時間をさけるかでしょうか。
スコア自体の計算に時間がかかりました。
今回の手法は、協調フィルタリングといった手法ではなく、カスタマと商品の属性の関係を元にモデリングを行うという手法を使っています。
過去の経験から、協調フィルタリングやアソシエーションルールをベースにしたものより、良い精度がでると思うのですが、計算する範囲をうまく抑えてあげないと、数億レコードとか数十億レコードと一気にレコード数が増えてしまうので注意が必要です。
出来としては、50%くらい。
最終発表に向けて、どこまで精度を上げることができるか。
それは、どこまで分析に時間をさけるかでしょうか。
ドライヤー壊れる [健康 / ビューティー]
ドライヤーを使っていたら、強い静電気?みたいなものが発生し、ショートしたようだ。
嫌な臭いの煙がモクモクと。
火事とか、大きな被害には至りませんでしたが、この時期、部屋が乾燥しているので、注意が必要ですね。。。
そのドライヤーは、捨てることにしました。
Amazonとか価格.comでレビューをみていると、パナソニックの製品がよさそう。
安くてコストパフォーマンスの良い製品もありましたが、安全に使える良いドライヤーを選びました。
ということで、購入したドライヤーは、これです。

嫌な臭いの煙がモクモクと。
火事とか、大きな被害には至りませんでしたが、この時期、部屋が乾燥しているので、注意が必要ですね。。。
そのドライヤーは、捨てることにしました。
Amazonとか価格.comでレビューをみていると、パナソニックの製品がよさそう。
安くてコストパフォーマンスの良い製品もありましたが、安全に使える良いドライヤーを選びました。
ということで、購入したドライヤーは、これです。
Panasonic ヘアードライヤー ナノケア 白 EH-NA95-W
- 出版社/メーカー: パナソニック
- メディア: ホーム&キッチン
ダイナース プレミアムカード [マネー]
ダイナース プレミアムカードという年会費が激しく高いクレジットカードがあります。
年会費相当分のサービスがあるものの、その中でも個人的に興味があるのは、ポイント!
おそらくクレジットカードの中で一番マイレージがたまるカードだと思います。
プレミアムカードを調べてみると、
・通常のダイナースプレミアムカード
・ANA ダイナース プレミアムカード
の2種類のカードがありました。
それぞれ、違いを比較してみると、、、
こうして比較してみると、ダイナースプレミアム(プロパーカード)とANAダイナースプレミアムとの年会費の差額は、21,000円です。
ただ、ダイナースプレミアムカードでANAのマイルに交換したい場合は、年間8万マイルという制限に達してしまいそうです。
リセットのタイミングが12/21なので、その前後で上手く調整すれば、2年に1回だけ年会費を払えば良い計算になります。
となると、差額は、
21,000円 - (6,300円 ÷ 2)← 2年に1回だけ年会費を払う
= 17,850円
一方、ANAダイナースプレミアムは、
・ANAのマイル1万マイル
・8万マイル制限がない
・ANAカードマイルプラス提携店は、さらにダブルマイル
搭乗ボーナスマイル
が付いてきます。
となると、ANAを利用する人は、ダイナースプレミアム(プロパーカード)より、ANAダイナースプレミアムの方がよさそうですし、JALを利用する人、もしくは、海外の航空会社のマイレージを利用する人は、ダイナースプレミアム(プロパーカード)の方が良さそうです。
ただ、JALのマイルを貯めるのでしたら、JALダイナースカードが良いかと思います。
※ こちらは、プレミアムがなく、通常のダイナースカードという扱いになります。
年会費相当分のサービスがあるものの、その中でも個人的に興味があるのは、ポイント!
おそらくクレジットカードの中で一番マイレージがたまるカードだと思います。
プレミアムカードを調べてみると、
・通常のダイナースプレミアムカード
・ANA ダイナース プレミアムカード
の2種類のカードがありました。
それぞれ、違いを比較してみると、、、
| 名前 | ダイナースプレミアムカード | ANA ダイナース プレミアムカード |
| 年会費 | 10万5000円 | 12万6000円 |
| 入会ボーナスマイル | 【特になし】 | 10,000マイル |
| 年間更新ボーナスマイル | 【特になし】 | 10,000マイル |
| マイレージプログラム | 全日本空輸 アメリカン航空 アリタリア-イタリア航空 大韓航空 デルタ航空 タイ国際航空 ユナイテッド航空 |
全日本空輸 (ANAマイレージクラブ) |
| 年間参加料 | 6,300円 | 【特になし】 |
| 年間加算ポイントの制限 | 無制限 ※ただし、ANAのマイルには年間(12/21~翌年12/20)8万マイルまで交換可能 |
無制限 |
こうして比較してみると、ダイナースプレミアム(プロパーカード)とANAダイナースプレミアムとの年会費の差額は、21,000円です。
ただ、ダイナースプレミアムカードでANAのマイルに交換したい場合は、年間8万マイルという制限に達してしまいそうです。
リセットのタイミングが12/21なので、その前後で上手く調整すれば、2年に1回だけ年会費を払えば良い計算になります。
となると、差額は、
21,000円 - (6,300円 ÷ 2)← 2年に1回だけ年会費を払う
= 17,850円
一方、ANAダイナースプレミアムは、
・ANAのマイル1万マイル
・8万マイル制限がない
・ANAカードマイルプラス提携店は、さらにダブルマイル
搭乗ボーナスマイル
が付いてきます。
となると、ANAを利用する人は、ダイナースプレミアム(プロパーカード)より、ANAダイナースプレミアムの方がよさそうですし、JALを利用する人、もしくは、海外の航空会社のマイレージを利用する人は、ダイナースプレミアム(プロパーカード)の方が良さそうです。
ただ、JALのマイルを貯めるのでしたら、JALダイナースカードが良いかと思います。
※ こちらは、プレミアムがなく、通常のダイナースカードという扱いになります。
R+Pythonというアプローチ [データサイエンス、統計モデル]
最近のデータ解析の流行として、R言語が増えてきています。
実際に、世界で使われるツールとして、No1らしいです。
フリーのツールってことも大きいかと思います。
そして、実際にkaggleやKDD cupをみていると、R+Pythonというアプローチが多いですね。
R言語に関しては、自分自身でも使っているのですが、Pythonに関しては使ったことがなかったです。
C言語、perl、ruby、phpなどは、使ったことがあります。
せっかくなので、Pythonも勉強してみよう!ってことで、この本を買いました。

Amazonでの口コミも良かったですし、「まったくのゼロからでも大丈夫」という安心感もあります。
読んでみると、、、激しく簡単でした。
「まったくのゼロ」というのは、プログラミングに関して、まったくのゼロの人向けって意味な気がします。
なんらかの言語をやったことがある人には、少し物足りないかもしれません。
オブジェクト指向とかが初めての人やもう一度復習してみたい人も良いかも。
それ以外の人だと、おそらく、こちらの方がよさげ。


実際に、世界で使われるツールとして、No1らしいです。
フリーのツールってことも大きいかと思います。
そして、実際にkaggleやKDD cupをみていると、R+Pythonというアプローチが多いですね。
R言語に関しては、自分自身でも使っているのですが、Pythonに関しては使ったことがなかったです。
C言語、perl、ruby、phpなどは、使ったことがあります。
せっかくなので、Pythonも勉強してみよう!ってことで、この本を買いました。
- 作者: 辻 真吾
- 出版社/メーカー: 技術評論社
- 発売日: 2010/04/24
- メディア: 大型本
Amazonでの口コミも良かったですし、「まったくのゼロからでも大丈夫」という安心感もあります。
読んでみると、、、激しく簡単でした。
「まったくのゼロ」というのは、プログラミングに関して、まったくのゼロの人向けって意味な気がします。
なんらかの言語をやったことがある人には、少し物足りないかもしれません。
オブジェクト指向とかが初めての人やもう一度復習してみたい人も良いかも。
それ以外の人だと、おそらく、こちらの方がよさげ。
- 作者: Mark Lutz
- 出版社/メーカー: オライリージャパン
- 発売日: 2009/02/26
- メディア: 大型本
- 作者: Alex Martelli
- 出版社/メーカー: オライリー・ジャパン
- 発売日: 2007/06/26
- メディア: 大型本
商用ツールか、フリーのツールか [データサイエンス、統計モデル]
「R+Pythonというアプローチ」という記事を書きましたが、
http://skellington.blog.so-net.ne.jp/2013-12-10
自分自身の分析が
R+Pythonというアプローチ
に移行したというわけではないです。
いくつかのコンペティション(国内や海外)に出たり、日々の業務の中で、数多くのモデリングを行い、単に精度やマーケティング思考のやりやすさ、安定性を考えた場合、
IBM SPSS Modeler(旧称クレメンタイン)
がベストだと思っています。
(※ IBMの回し者ではないです…)
もちろん、個人や学生の人にとって見れば、価格が高すぎるので、そこが問題点であり、R+Pythonが流行ってきている理由もそこにあります。
"精度"ということを考えた場合、最新の手法や様々な手法が豊富なRの方に軍配が上がるように思えるのですが、意外とSPSS Modelerも悪くない、というか、むしろ精度が高い場合が多いように感じます。
おそらく、単なるアルゴリズム云々という話ではなく、きちんとした特徴量(説明変数)を作れれば、あまり、アルゴリズムや手法には差がなくなってくるのではないか?と。
そして、アルゴリズムの豊富さという意味では、昔に比べ、IBM SPSS Modelerも十分に良いノードがそろってきていると思います。
なので、主としては、IBM SPSS Modelerを使い、気分転換として、R+Pythonを使うのが、今のところ自分自身の中でのベストアプローチですね。
http://skellington.blog.so-net.ne.jp/2013-12-10
自分自身の分析が
R+Pythonというアプローチ
に移行したというわけではないです。
いくつかのコンペティション(国内や海外)に出たり、日々の業務の中で、数多くのモデリングを行い、単に精度やマーケティング思考のやりやすさ、安定性を考えた場合、
IBM SPSS Modeler(旧称クレメンタイン)
がベストだと思っています。
(※ IBMの回し者ではないです…)
もちろん、個人や学生の人にとって見れば、価格が高すぎるので、そこが問題点であり、R+Pythonが流行ってきている理由もそこにあります。
"精度"ということを考えた場合、最新の手法や様々な手法が豊富なRの方に軍配が上がるように思えるのですが、意外とSPSS Modelerも悪くない、というか、むしろ精度が高い場合が多いように感じます。
おそらく、単なるアルゴリズム云々という話ではなく、きちんとした特徴量(説明変数)を作れれば、あまり、アルゴリズムや手法には差がなくなってくるのではないか?と。
そして、アルゴリズムの豊富さという意味では、昔に比べ、IBM SPSS Modelerも十分に良いノードがそろってきていると思います。
なので、主としては、IBM SPSS Modelerを使い、気分転換として、R+Pythonを使うのが、今のところ自分自身の中でのベストアプローチですね。
SEXY LITTLE NUMBERS、データサイエンティストに学ぶ「分析力」 [データサイエンス、統計モデル]
データサイエンティストに学ぶ「分析力」を読んでみた。
自分の業界と違う部分もあるし、取得しているデータも違いますし、そもそも、取得できない項目もあります。
しかし、同じ分析やCRMを自分のサイトでするとしたら、どうするか?ということを考えながら、読み進めてみると、意外と似たようなアプローチをすることも出来るんじゃないか?って思いながら読んでいました。

ビッグデータ(big data)に対抗する意味での "SEXY LITTLE NUMBERS" というタイトルなんでしょうけど、、w
個人的には、割と良い本だと思いました。
ただ、本を読むだけでなく、実際に、やってみるってことも大切ですね。
自分の業界と違う部分もあるし、取得しているデータも違いますし、そもそも、取得できない項目もあります。
しかし、同じ分析やCRMを自分のサイトでするとしたら、どうするか?ということを考えながら、読み進めてみると、意外と似たようなアプローチをすることも出来るんじゃないか?って思いながら読んでいました。
- 作者: ディミトリ・マークス
- 出版社/メーカー: 日経BP社
- 発売日: 2013/02/28
- メディア: 単行本
ビッグデータ(big data)に対抗する意味での "SEXY LITTLE NUMBERS" というタイトルなんでしょうけど、、w
個人的には、割と良い本だと思いました。
ただ、本を読むだけでなく、実際に、やってみるってことも大切ですね。
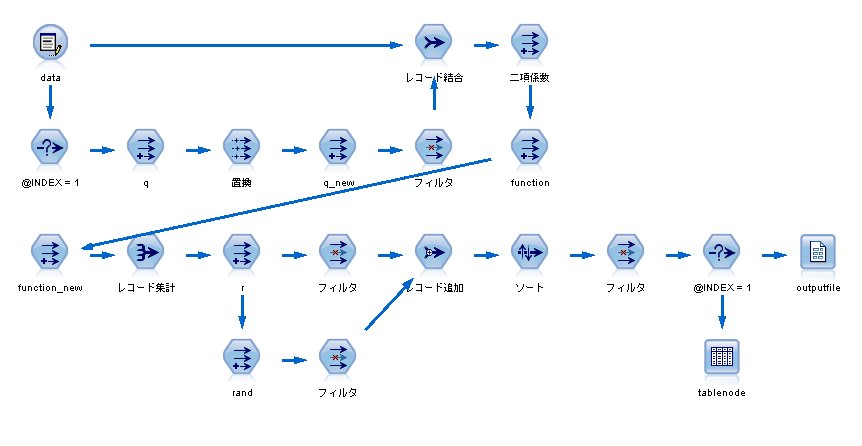
「データ解析のための統計モデリング入門」8章 二項分布の乱数を発生させる [階層ベイズ]
「データ解析のための統計モデリング入門」8章 MCMCとメトロポリス法について。
")
この本に書かれているアプローチを IBM SPSS Modeler(旧称クレメンタイン)でできないか?と思いやってみることにした。
まず、二項分布の乱数を発生させる必要があります。
IBM SPSS Modelerには、二項分布の乱数を直接発生させる関数はないので、いくつかのノードを組み合わせて作ることにします。
この本には、生存確率 0.45625 に従う各植物個体8個の種子の生死を調べています。
それを20個体調べています。
教科書のデモデータ
Rで二項乱数を発生させる場合
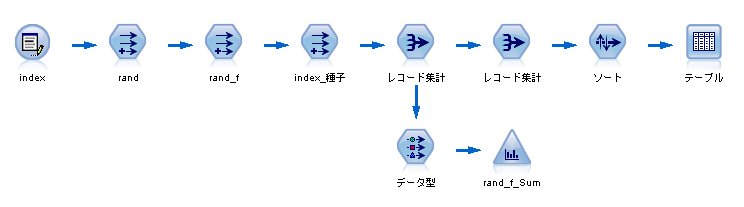
これを、IBM SPSS Modeler(旧称クレメンタイン)で発生させる場合のステップ
1. 入力データを160個用意する(20×8)
2. 0から1までの乱数を発生させる
random(1.0)
3. 各レコードに対し、生死を判別する
if rand <= 0.45625 then 1 else 0 endif
4. 8個の種子グループ(index_種子)を作成する
(index - 1) div 8
5. レコード集計をする
→ 160レコードを20レコードに集計
これで、二項分布の乱数を発生させることができました。
試しに1万個のレコードから 10000 ÷ 8 = 1250 個の乱数を発生させてみると、
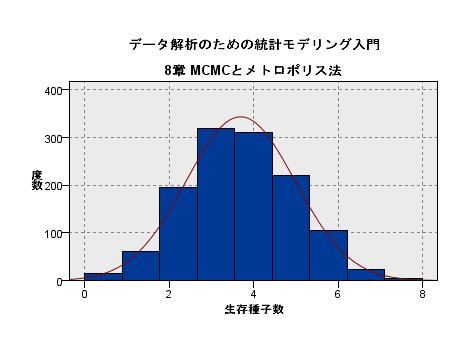
こんなグラフになりました。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
この本に書かれているアプローチを IBM SPSS Modeler(旧称クレメンタイン)でできないか?と思いやってみることにした。
まず、二項分布の乱数を発生させる必要があります。
IBM SPSS Modelerには、二項分布の乱数を直接発生させる関数はないので、いくつかのノードを組み合わせて作ることにします。
この本には、生存確率 0.45625 に従う各植物個体8個の種子の生死を調べています。
それを20個体調べています。
教科書のデモデータ
data <- c(4,3,4,5,5,2,3,1,4,0,1,5,5,6,5,4,4,5,3,4)
Rで二項乱数を発生させる場合
rbinom(20, 8, 0.45625)
これを、IBM SPSS Modeler(旧称クレメンタイン)で発生させる場合のステップ
1. 入力データを160個用意する(20×8)
2. 0から1までの乱数を発生させる
random(1.0)
3. 各レコードに対し、生死を判別する
if rand <= 0.45625 then 1 else 0 endif
4. 8個の種子グループ(index_種子)を作成する
(index - 1) div 8
5. レコード集計をする
→ 160レコードを20レコードに集計
これで、二項分布の乱数を発生させることができました。
試しに1万個のレコードから 10000 ÷ 8 = 1250 個の乱数を発生させてみると、
こんなグラフになりました。
「データ解析のための統計モデリング入門」8章 ふらふら試行錯誤 [階層ベイズ]
「データ解析のための統計モデリング入門」8章 MCMCとメトロポリス法について。
まずは、対数尤度を計算するストリームを作る必要があります。
対数尤度の計算式は、
となるのですが、あらかじめ、二項係数を作っておく必要があります。
【二項係数】
尤度を計算するノードとして、
function
data * log(q) + (8 - data) * log(1 - q) + log(二項係数)
function_new
data * log(q_new) + (8 - data) * log(1 - q_new) + log(二項係数)
各レコードの値を計算し、最後に集計をすれば、完成です。
完成したストリームはこちら。
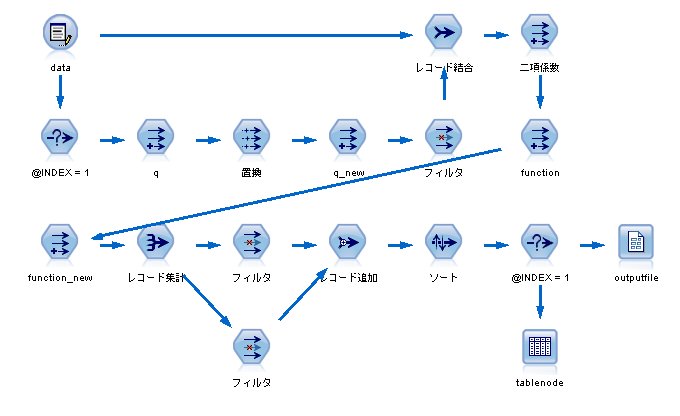
スクリプトは、
q = 0.30 とした場合、
-46.378
となります。
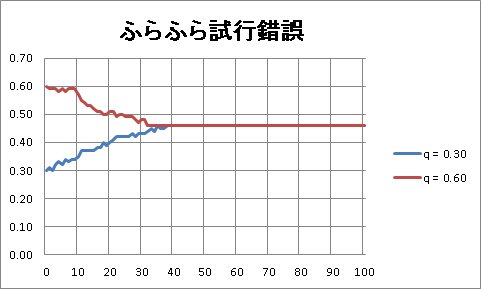
ふらふら試行錯誤のロジックとして、
1. ある初期値からスタートする。(例:q = 0.30)
2. 0.01、あるいは、-0.01だけ変化させる。
3. 対数尤度が改善されれば、その値を採用し、そうでない場合は、元の値を採用する。
これをストリームで書いて、後は、100回ほどループをさせれば、OK!
35回くらいで、最大値 0.46 に張り付いているのがわかります。
初期値を 0.30 にしても、0.60 にしても同じ結果になります。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
まずは、対数尤度を計算するストリームを作る必要があります。
対数尤度の計算式は、
data * log(q) + (8 - data) * log(1 - q) + log(二項係数)
となるのですが、あらかじめ、二項係数を作っておく必要があります。
【二項係数】
# Rの場合は、choose(8, x)
if data = 0 then 1
elseif data = 1 then 8
elseif data = 2 then 28
elseif data = 3 then 56
elseif data = 4 then 70
elseif data = 5 then 56
elseif data = 6 then 28
elseif data = 7 then 8
elseif data = 8 then 1
else -1 endif
尤度を計算するノードとして、
function
data * log(q) + (8 - data) * log(1 - q) + log(二項係数)
function_new
data * log(q_new) + (8 - data) * log(1 - q_new) + log(二項係数)
各レコードの値を計算し、最後に集計をすれば、完成です。
完成したストリームはこちら。
スクリプトは、
var x
set x = 0.0
for I from 1 to 100
execute 'outputfile'
execute 'tablenode'
set x = value:tablenode.output at 1 1
set q.formula_expr = x
endfor
q = 0.30 とした場合、
-46.378
となります。
ふらふら試行錯誤のロジックとして、
1. ある初期値からスタートする。(例:q = 0.30)
2. 0.01、あるいは、-0.01だけ変化させる。
3. 対数尤度が改善されれば、その値を採用し、そうでない場合は、元の値を採用する。
これをストリームで書いて、後は、100回ほどループをさせれば、OK!
35回くらいで、最大値 0.46 に張り付いているのがわかります。
初期値を 0.30 にしても、0.60 にしても同じ結果になります。
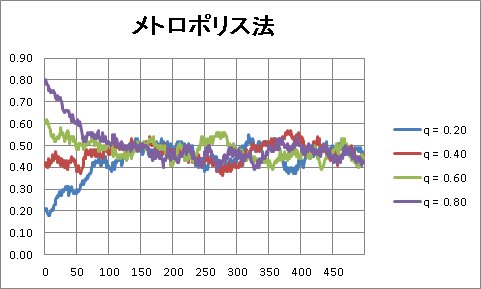
「データ解析のための統計モデリング入門」8章 メトロポリス法 [階層ベイズ]
「データ解析のための統計モデリング入門」8章 MCMCとメトロポリス法について。
ふらふら試行錯誤からメトロポリス法へ
1. ある初期値からスタートする。(例:q = 0.30)
2. 0.01、あるいは、-0.01だけ変化させる。
3. 対数尤度が改善されれば、その値を採用し、そうでない場合は、元の値を採用する。
↑
ふらふら試行錯誤の場合
3. ある一定の確率 r で、値が悪くても新しい値を採用する
↑
ふらふら試行錯誤からメトロポリス法へ
r = L(q新)/L(q)
(例)
元 q = 0.30, -46.378
新 q_new = 0.290, -47.619
r = exp(-47.619 + 46.378) = 0.289
【r】というノードを作成しています。
min(1, exp(function_new_Sum - function_Sum))
同時に【rand】という乱数を発生させ、r の値と比較することで、
"ある一定の確率 r で、値が悪くても新しい値を採用する"
という状態を作ることができます。
シミュレーションの結果は、こちら。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
ふらふら試行錯誤からメトロポリス法へ
1. ある初期値からスタートする。(例:q = 0.30)
2. 0.01、あるいは、-0.01だけ変化させる。
↑
ふらふら試行錯誤の場合
3. ある一定の確率 r で、値が悪くても新しい値を採用する
↑
ふらふら試行錯誤からメトロポリス法へ
r = L(q新)/L(q)
(例)
元 q = 0.30, -46.378
新 q_new = 0.290, -47.619
r = exp(-47.619 + 46.378) = 0.289
【r】というノードを作成しています。
min(1, exp(function_new_Sum - function_Sum))
同時に【rand】という乱数を発生させ、r の値と比較することで、
"ある一定の確率 r で、値が悪くても新しい値を採用する"
という状態を作ることができます。
シミュレーションの結果は、こちら。
「博多ほたる」(麻布十番店) [データサイエンス、統計モデル]
今日は、ここで忘年会でした。
「博多ほたる」(麻布十番店)
http://tabelog.com/tokyo/A1307/A130702/13133270/
http://www.hotpepper.jp/strJ001012128/
以前、とあるセミナーで昔の同僚の人と偶然に会いました。
そして、朝野煕彦先生との忘年会があると聞き、急きょ、参加をさせてもらうことに。

朝野先生といえば、自分自身、数多くの統計関連の本を読ませてもらっています。
せっかくなので、サインもらえば良かったですかね…(^^;
ちなみに、来年の1月くらいにビッグデータを元にした新しい本も出版されるとか。
こちらも楽しみです。
朝野煕彦先生の書籍は(↓)
")
")
")
")
「博多ほたる」(麻布十番店)
http://tabelog.com/tokyo/A1307/A130702/13133270/
http://www.hotpepper.jp/strJ001012128/
以前、とあるセミナーで昔の同僚の人と偶然に会いました。
そして、朝野煕彦先生との忘年会があると聞き、急きょ、参加をさせてもらうことに。
朝野先生といえば、自分自身、数多くの統計関連の本を読ませてもらっています。
せっかくなので、サインもらえば良かったですかね…(^^;
ちなみに、来年の1月くらいにビッグデータを元にした新しい本も出版されるとか。
こちらも楽しみです。
朝野煕彦先生の書籍は(↓)
- 作者: 朝野 煕彦
- 出版社/メーカー: 講談社
- 発売日: 2000/10/10
- メディア: 単行本(ソフトカバー)
- 作者: 朝野 煕彦
- 出版社/メーカー: 講談社
- 発売日: 2005/12/20
- メディア: 単行本(ソフトカバー)
最新マーケティング・サイエンスの基礎 (KS社会科学専門書)
- 作者: 朝野 煕彦
- 出版社/メーカー: 講談社
- 発売日: 2010/12/07
- メディア: 単行本(ソフトカバー)
マーケティング・リサーチ工学 (シリーズ・マーケティング・エンジニアリング)
- 作者: 朝野 煕彦
- 出版社/メーカー: 朝倉書店
- 発売日: 2000/12
- メディア: 単行本

