「データ解析のための統計モデリング入門」8章 二項分布の乱数を発生させる [階層ベイズ]
「データ解析のための統計モデリング入門」8章 MCMCとメトロポリス法について。
")
この本に書かれているアプローチを IBM SPSS Modeler(旧称クレメンタイン)でできないか?と思いやってみることにした。
まず、二項分布の乱数を発生させる必要があります。
IBM SPSS Modelerには、二項分布の乱数を直接発生させる関数はないので、いくつかのノードを組み合わせて作ることにします。
この本には、生存確率 0.45625 に従う各植物個体8個の種子の生死を調べています。
それを20個体調べています。
教科書のデモデータ
Rで二項乱数を発生させる場合
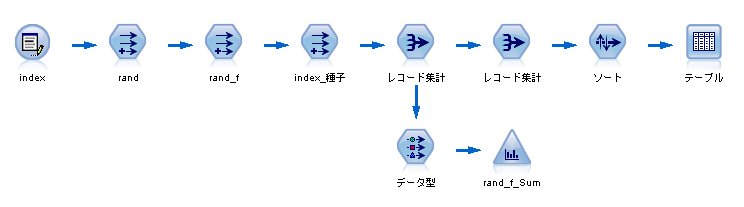
これを、IBM SPSS Modeler(旧称クレメンタイン)で発生させる場合のステップ
1. 入力データを160個用意する(20×8)
2. 0から1までの乱数を発生させる
random(1.0)
3. 各レコードに対し、生死を判別する
if rand <= 0.45625 then 1 else 0 endif
4. 8個の種子グループ(index_種子)を作成する
(index - 1) div 8
5. レコード集計をする
→ 160レコードを20レコードに集計
これで、二項分布の乱数を発生させることができました。
試しに1万個のレコードから 10000 ÷ 8 = 1250 個の乱数を発生させてみると、
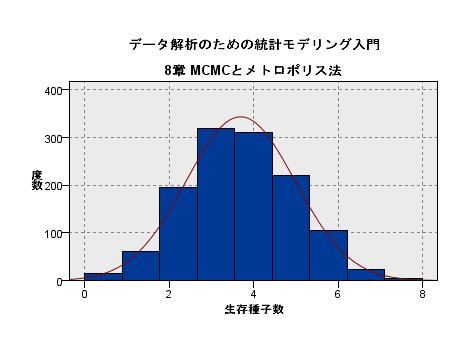
こんなグラフになりました。
データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
- 作者: 久保 拓弥
- 出版社/メーカー: 岩波書店
- 発売日: 2012/05/19
- メディア: 単行本
この本に書かれているアプローチを IBM SPSS Modeler(旧称クレメンタイン)でできないか?と思いやってみることにした。
まず、二項分布の乱数を発生させる必要があります。
IBM SPSS Modelerには、二項分布の乱数を直接発生させる関数はないので、いくつかのノードを組み合わせて作ることにします。
この本には、生存確率 0.45625 に従う各植物個体8個の種子の生死を調べています。
それを20個体調べています。
教科書のデモデータ
data <- c(4,3,4,5,5,2,3,1,4,0,1,5,5,6,5,4,4,5,3,4)
Rで二項乱数を発生させる場合
rbinom(20, 8, 0.45625)
これを、IBM SPSS Modeler(旧称クレメンタイン)で発生させる場合のステップ
1. 入力データを160個用意する(20×8)
2. 0から1までの乱数を発生させる
random(1.0)
3. 各レコードに対し、生死を判別する
if rand <= 0.45625 then 1 else 0 endif
4. 8個の種子グループ(index_種子)を作成する
(index - 1) div 8
5. レコード集計をする
→ 160レコードを20レコードに集計
これで、二項分布の乱数を発生させることができました。
試しに1万個のレコードから 10000 ÷ 8 = 1250 個の乱数を発生させてみると、
こんなグラフになりました。

