多重共線性の話 〜その1 一般的な問題点 [よもやま日記]
参考にした本
")
説明変数の中に相関が強い変数が含まれると両者の識別が難しくなる
・係数の標準誤差が大きくなる
・t値が小さくなる → 係数が有意になりにくくなる(※ 後で実験を行う)
・係数が理論から予想される値と大きく乖離することがある
・個別係数のt値が小さいにも関わらず、決定係数が大きくなる
・データのわずかな変動や観測期間の変更などで係数が大きく変化する
シミュレーションデータを使った実験
実験1: 多重共線性でない独立なデータを300レコード発生させ、回帰分析を行う
- 出版社/メーカー: 有斐閣
- 発売日: 2009/03/01
- メディア: 単行本
説明変数の中に相関が強い変数が含まれると両者の識別が難しくなる
・係数の標準誤差が大きくなる
・t値が小さくなる → 係数が有意になりにくくなる(※ 後で実験を行う)
・係数が理論から予想される値と大きく乖離することがある
・個別係数のt値が小さいにも関わらず、決定係数が大きくなる
・データのわずかな変動や観測期間の変更などで係数が大きく変化する
シミュレーションデータを使った実験
実験1: 多重共線性でない独立なデータを300レコード発生させ、回帰分析を行う
# オブザベーション数
N <- 300
# 多重共線性が起こっていないデータ
set.seed(123)
x1 <- rnorm(N)
x2 <- rnorm(N)
x3 <- rnorm(N)
e <- rnorm(N)
y <- 1000 + 100*x1 + 80*x2 + 60*x3 + 100*e
df.1 <- data.frame(x1, x2, x3, e, y)
# lm model
model_lm <- lm(y~x1+x2+x3, data=df.1)
summary(model_lm)
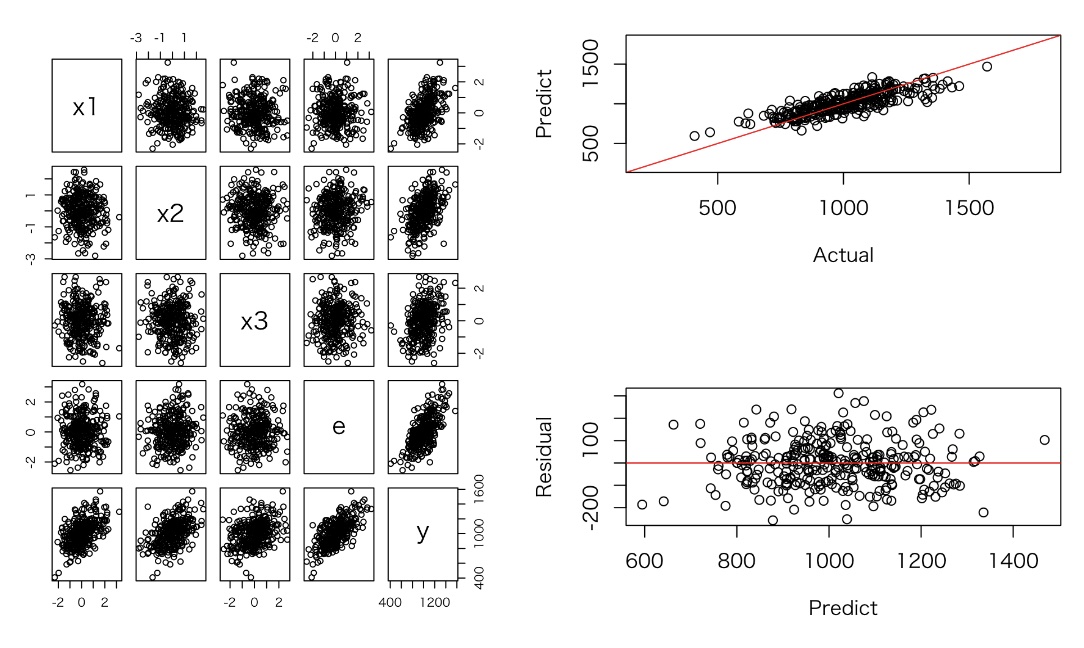
## 予測値と実測値プロット
plot(df.1$y, predict(model_lm), xlab="Actual", ylab="Predict", xlim=c(200,1800), ylim=c(200,1800))
abline(0, 1, col="red")
## 残差プロット
plot(predict(model_lm), resid(model_lm), xlab="Predict", ylab="Residual")
abline(0, 0, col="red")
結果は、シミュレーションデータを再現できている
> summary(model_lm)
Call:
lm(formula = y ~ x1 + x2 + x3, data = df.1)
Residuals:
Min 1Q Median 3Q Max
-256.535 -71.289 0.933 56.108 311.957
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1002.441 5.874 170.65 <2e-16 ***
x1 102.728 6.234 16.48 <2e-16 ***
x2 91.891 5.961 15.41 <2e-16 ***
x3 64.558 5.700 11.33 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 101.7 on 296 degrees of freedom
Multiple R-squared: 0.6617, Adjusted R-squared: 0.6583
F-statistic: 193 on 3 and 296 DF, p-value: < 2.2e-16


コメント 0