市場反応モデル [データサイエンス、統計モデル]
市場反応モデルについて、教科書などをみると、唐突に下記の式が出てきます。
log(y) = b0 + b1*log(x1) + b2*x2 + ε
y: 販売点数
x1: 売価
x2: 陳列量(もしくは、陳列の有無)
この式の意味について調べました。
① 販売点数と売価について
目的変数log、説明変数logの関係になっています。
これは、価格弾力性を一定という条件があるのですが、この部分については、必ずしもlog-logの関係じゃなくてもOKです。
log(y) = b0 + b1*(x1)なら価格弾力性はb1*x1(すなわち説明変数の値で弾力性が変化する)
y = b0 + b1*log(x1) なら価格弾力性はb1/y(すなわち目的変数の値で弾力性が変化する)
y = b0 + b1*(x1) なら価格弾力性はb1*x/y(すなわち説明変数と目的変数の比で弾力性が変化する)
log(y) = b0 + b1*log(x1)なら価格弾力性はb1(すなわち説明変数が変化しても目的変数に与える影響は一定)
② 陳列量について
陳列実施の有無のダミー変数の場合、log(0) → -∞になるので、logは取れません。
陳列の有無ではなく、陳列量にする場合、
X2+1の対数を説明変数にすれば形式的には、logで表現できるます。
x1: 売価をいったん忘れると、
販売個数は必ず0以上なので、発生回数のモデルとして、ポアソン回帰モデルで表現できます。
ポアソン回帰モデルでは、平均(=分散)パラメータを構造化します。
Y ~Poisson(μ)
E(Y) = exp(b0 + b1*x1 + ...)
expなので、E(Y)は必ず0超
~まとめ~
log(y) = b0 + b1*log(x1) + b2*x2 + ε
y: 販売点数
x1: 売価
x2: 陳列量(もしくは、陳列の有無)
売価は、価格弾力性をb1とし、log-logの関係になっている。
それ以外の説明変数は、ポアソン回帰モデルで表現しているとすると理解しやすい。
log(y) = b0 + b1*log(x1) + b2*x2 + ε
y: 販売点数
x1: 売価
x2: 陳列量(もしくは、陳列の有無)
この式の意味について調べました。
① 販売点数と売価について
目的変数log、説明変数logの関係になっています。
これは、価格弾力性を一定という条件があるのですが、この部分については、必ずしもlog-logの関係じゃなくてもOKです。
log(y) = b0 + b1*(x1)なら価格弾力性はb1*x1(すなわち説明変数の値で弾力性が変化する)
y = b0 + b1*log(x1) なら価格弾力性はb1/y(すなわち目的変数の値で弾力性が変化する)
y = b0 + b1*(x1) なら価格弾力性はb1*x/y(すなわち説明変数と目的変数の比で弾力性が変化する)
log(y) = b0 + b1*log(x1)なら価格弾力性はb1(すなわち説明変数が変化しても目的変数に与える影響は一定)
② 陳列量について
陳列実施の有無のダミー変数の場合、log(0) → -∞になるので、logは取れません。
陳列の有無ではなく、陳列量にする場合、
X2+1の対数を説明変数にすれば形式的には、logで表現できるます。
x1: 売価をいったん忘れると、
販売個数は必ず0以上なので、発生回数のモデルとして、ポアソン回帰モデルで表現できます。
ポアソン回帰モデルでは、平均(=分散)パラメータを構造化します。
Y ~Poisson(μ)
E(Y) = exp(b0 + b1*x1 + ...)
expなので、E(Y)は必ず0超
~まとめ~
log(y) = b0 + b1*log(x1) + b2*x2 + ε
y: 販売点数
x1: 売価
x2: 陳列量(もしくは、陳列の有無)
売価は、価格弾力性をb1とし、log-logの関係になっている。
それ以外の説明変数は、ポアソン回帰モデルで表現しているとすると理解しやすい。
New Disney Vacation Club Tower At Disneyland Hotel [Disney / ディズニー]
ディズニーランド65周年に向けて、アナハイム(西海岸)に新しいDVC(ディズニーバケーションクラブ)のホテルができるそうです。
フロリダは日本からだと距離があり、直行便も少なく、日本人からはハードルが高いです。
カリフォルニア州のアナハイム(西海岸)だと日本からも比較的近いの行きやすい。
アナハイムのディズニーランドにもDVCのホテルがあるのですが、人気ででなかなか予約を取ることができません。
今回は、5階建てで350室ある大規模なホテルとなっています。
この新型コロナウィルスのタイミングで新しくここを買うには勇気がいりますが、お金持っている人だと販売と同時に買って完売となりそうな気もします。
フロリダは日本からだと距離があり、直行便も少なく、日本人からはハードルが高いです。
カリフォルニア州のアナハイム(西海岸)だと日本からも比較的近いの行きやすい。
アナハイムのディズニーランドにもDVCのホテルがあるのですが、人気ででなかなか予約を取ることができません。
今回は、5階建てで350室ある大規模なホテルとなっています。
この新型コロナウィルスのタイミングで新しくここを買うには勇気がいりますが、お金持っている人だと販売と同時に買って完売となりそうな気もします。
浦安市運動公園 その3 [よもやま日記]
千葉こどもの国 キッズダムに行こうと思っていたのですが、子供の月例テストとかやっている間に昼過ぎになってしまいました。
じゃぶじゃぶ池のオープンも少し先とのことで、予定を急遽変更して、浦安(舞浜)にある浦安市運動公園へ。
こちらの公園は、駐車場無料なのと、広場や遊具が充実しており、穴場的な公園です。
ディズニーシーの隣にある公園。
イクスピアリでお昼を食べて、しばらく遊んでいました。
2歳になった次男の運動能力も向上していて、前まで怖がっていた滑り台も一人で滑れるようになりました。
子供の成長は早いものです。

じゃぶじゃぶ池のオープンも少し先とのことで、予定を急遽変更して、浦安(舞浜)にある浦安市運動公園へ。
こちらの公園は、駐車場無料なのと、広場や遊具が充実しており、穴場的な公園です。
ディズニーシーの隣にある公園。
イクスピアリでお昼を食べて、しばらく遊んでいました。
2歳になった次男の運動能力も向上していて、前まで怖がっていた滑り台も一人で滑れるようになりました。
子供の成長は早いものです。
【時系列】広告効果をモデリングする 〜その1 ABテスト(t検定)〜 [時系列解析 / 需要予測]
まずはサンプルデータの作成から。
まずは、時系列データということを無視して、CMの期間の有無でt検定をやってみます。
CMの有無でABテストをしているイメージです。
p値は、1.531e-13となっており、非常に小さいですね。
なので、広告の有無で、統計的には差がありそうだということがわかります。
#データの準備
#売上データ
Sales <- c(19.76, 17.68, 17.56, 21.41, 21.04, 21.79, 24.08, 24.84, 18.57, 12.62,
31.72, 27.01, 26.48, 31.62, 27.79, 23.97, 30.20, 29.56, 28.87, 31.84,
19.65, 22.02, 20.28, 22.34, 24.79, 22.74, 20.29, 24.02, 22.96, 21.26,
19.83, 17.46, 22.49, 19.57, 28.46, 34.42, 28.80, 26.21, 28.29, 30.90,
29.58, 29.09, 27.17, 21.24, 18.11, 16.74, 18.18, 23.00, 18.52, 22.16,
15.70, 19.61)
#広告データ(キャンペーンデータ)
CM <- c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0)
# CMあり/なし期間別の統計量
# CMあり期間はSalesが高くなる
by(Sales, INDICES=CM, FUN=summary)
ts.plot(Sales, type="o", ylab="Sales")
まずは、時系列データということを無視して、CMの期間の有無でt検定をやってみます。
CMの有無でABテストをしているイメージです。
t.test(Sales ~ CM)
Welch Two Sample t-test
data: Sales by CM
t = -10.765, df = 41.172, p-value = 1.531e-13
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-10.063060 -6.884064
sample estimates:
mean in group 0 mean in group 1
20.61088 29.08444
p値は、1.531e-13となっており、非常に小さいですね。
なので、広告の有無で、統計的には差がありそうだということがわかります。
【時系列】広告効果をモデリングする 〜その2 簡単な線形回帰モデル〜 [時系列解析 / 需要予測]
シンプルに線形回帰モデルとして、
y(Sales) = b0 + b1 * x(CM) + ε
というモデルを作ってみるとどうなるか?
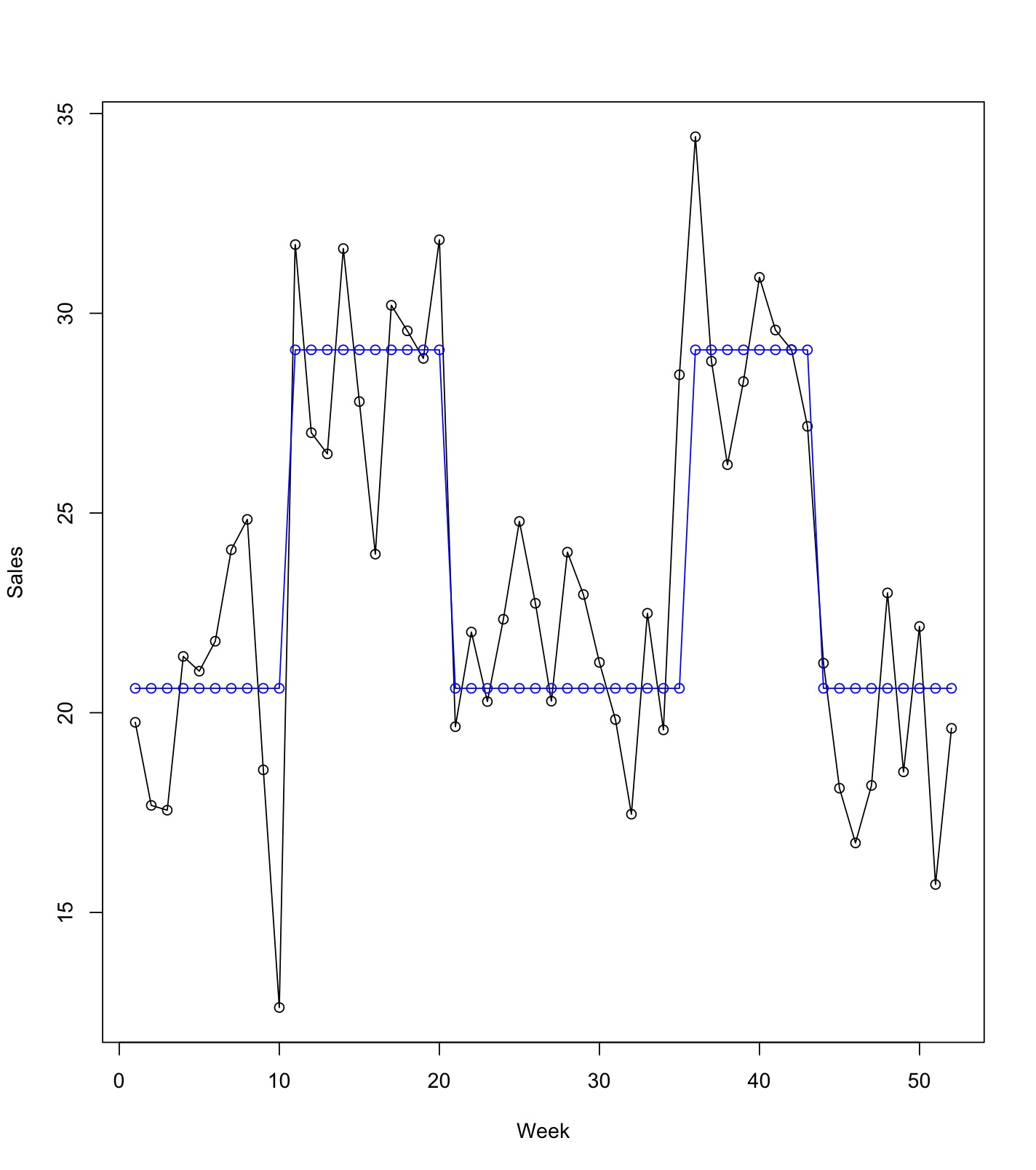
実測値と予測値をプロットしてみると単純な線形回帰モデルの限界が見えてきます。
目的変数(y:売上)のベースラインが少しずつ上がったり下がってりしているのですが、
線形回帰モデル
y(Sales) = b0 + b1 * x(CM) + ε
ベースライン(切片)は、どの時点でも b0 で与えられるため一定値となっています。
このベースライン(状態)を上手くモデルの中に取り入れるにはどうすれば良いかを考える必要がありそうですね。
〜過去の記事〜
【時系列】広告効果をモデリングする
その1 ABテスト(t検定)
https://skellington.blog.ss-blog.jp/2020-07-20
y(Sales) = b0 + b1 * x(CM) + ε
というモデルを作ってみるとどうなるか?
model.lm <- lm(Sales ~ CM)
summary(model.lm)
Call:
lm(formula = Sales ~ CM)
Residuals:
Min 1Q Median 3Q Max
-7.9909 -2.0493 -0.1044 1.8314 7.8491
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.6109 0.4925 41.85 < 2e-16 ***
CM 8.4736 0.8371 10.12 1.07e-13 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.872 on 50 degrees of freedom
Multiple R-squared: 0.672, Adjusted R-squared: 0.6655
F-statistic: 102.5 on 1 and 50 DF, p-value: 1.068e-13
# 実測値と予測値を重ねる
dat_predict <- predict(model.lm)
ts.plot(cbind(Sales, dat_predict), type="o",
col=c("black","blue"), xlab="Week", ylab="Sales")
実測値と予測値をプロットしてみると単純な線形回帰モデルの限界が見えてきます。
目的変数(y:売上)のベースラインが少しずつ上がったり下がってりしているのですが、
線形回帰モデル
y(Sales) = b0 + b1 * x(CM) + ε
ベースライン(切片)は、どの時点でも b0 で与えられるため一定値となっています。
このベースライン(状態)を上手くモデルの中に取り入れるにはどうすれば良いかを考える必要がありそうですね。
〜過去の記事〜
【時系列】広告効果をモデリングする
その1 ABテスト(t検定)
https://skellington.blog.ss-blog.jp/2020-07-20
【時系列】広告効果をモデリングする 〜その3 線形回帰モデルにラグを入れる〜 [時系列解析 / 需要予測]
本来は状態空間モデルを使ってベースラインの状態を推定するのが正しいアプローチだと思うのですが、線形回帰モデルでどこまでできるかやってみたいと思います。
シンプルな線形回帰モデルに1日前の売上を説明変数にしてモデルを作ります。
y(Sales) = b0 + b1 * x(CM) + b2 * Sales_1day + ε
この意味としては、
・売上の状態(ベースライン)は少しずつ変化していく
・その状態を観測することはできない
・今日の状態は昨日の状態に近いだろう
という思想になっています。
結果を見て気がついたのですが、このモデルだと上手くベースラインを見つけられません。
まず、lag_Salesのp値が1に近いです。
このことは、1日前の売上が分かったからと言って、今日の売上を説明する力は弱いとなっています。
また、係数の値も他と比べて小さく影響は少なそうです。
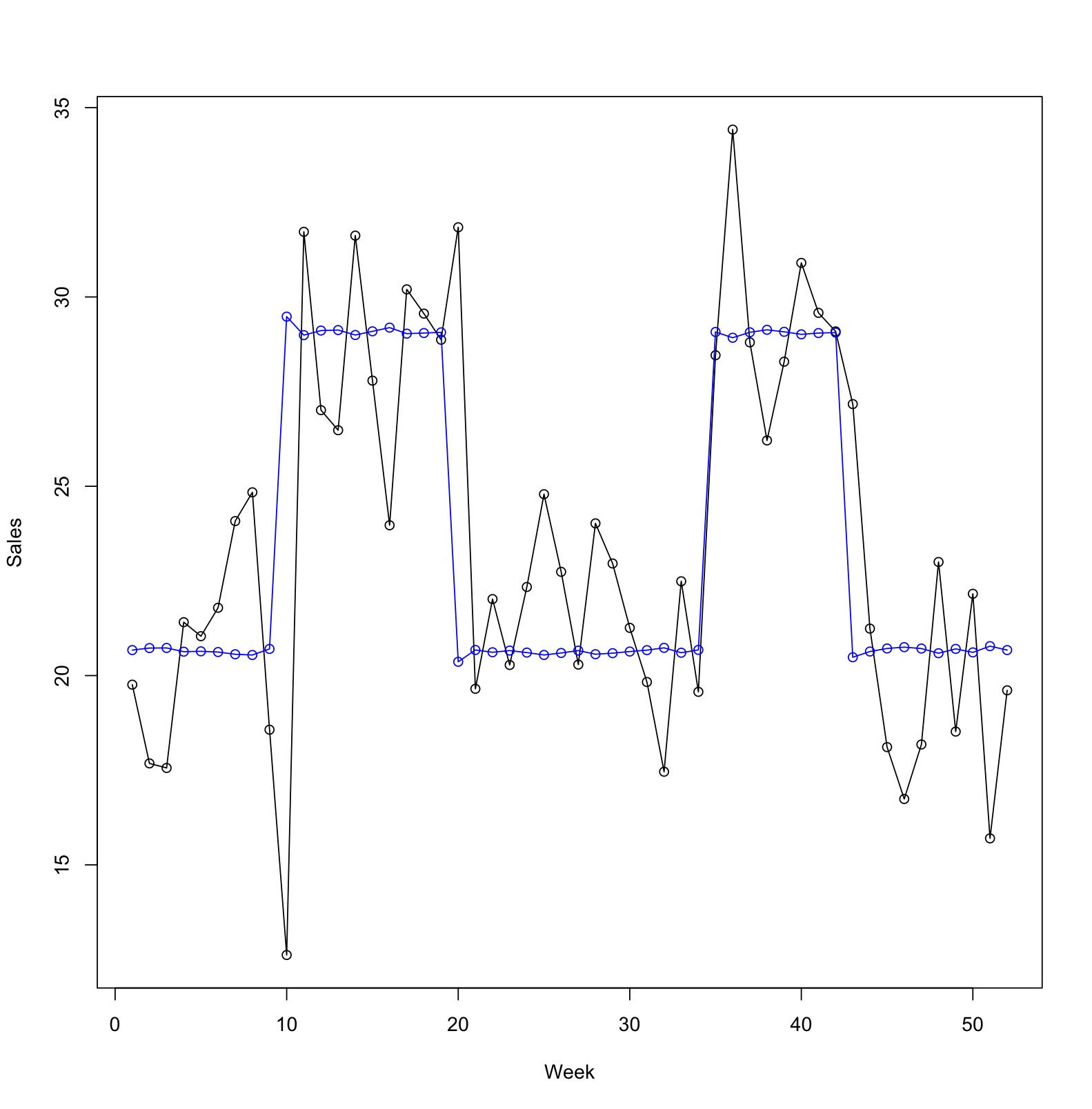
実測値と予測値のプロットを描いても、ラグを入れないシンプルな線形回帰モデルと大差はありませんね。
〜過去の記事〜
【時系列】広告効果をモデリングする
その1 ABテスト(t検定)
https://skellington.blog.ss-blog.jp/2020-07-20
その2 簡単な線形回帰モデル
https://skellington.blog.ss-blog.jp/2020-07-21
シンプルな線形回帰モデルに1日前の売上を説明変数にしてモデルを作ります。
y(Sales) = b0 + b1 * x(CM) + b2 * Sales_1day + ε
この意味としては、
・売上の状態(ベースライン)は少しずつ変化していく
・その状態を観測することはできない
・今日の状態は昨日の状態に近いだろう
という思想になっています。
# 1日前の売上データを作成する
df_sales <- data.frame(Sales, lag_Sales=lag(Sales), CM)
df_sales <- df_sales[-1,] # 1行目のNAを除外する
# y(Sales) = b0 + b1 * x(CM) + b2 * Sales_1day + ε
model.lm2 <- lm(Sales ~ CM + lag_Sales, data=df_sales)
summary(model.lm2)
dat_predict2 <- predict(model.lm2)
ts.plot(cbind(Sales, dat_predict2), type="o",
col=c("black","blue"), xlab="Week", ylab="Sales")
Call:
lm(formula = Sales ~ CM + lag_Sales, data = df_sales)
Residuals:
Min 1Q Median 3Q Max
-8.0836 -1.9773 0.0437 1.7893 7.7820
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 21.1791 2.4207 8.749 1.66e-11 ***
CM 8.6245 1.1534 7.478 1.37e-09 ***
lag_Sales -0.0256 0.1117 -0.229 0.82
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.927 on 48 degrees of freedom
Multiple R-squared: 0.6691, Adjusted R-squared: 0.6554
F-statistic: 48.54 on 2 and 48 DF, p-value: 2.961e-12
結果を見て気がついたのですが、このモデルだと上手くベースラインを見つけられません。
まず、lag_Salesのp値が1に近いです。
このことは、1日前の売上が分かったからと言って、今日の売上を説明する力は弱いとなっています。
また、係数の値も他と比べて小さく影響は少なそうです。
実測値と予測値のプロットを描いても、ラグを入れないシンプルな線形回帰モデルと大差はありませんね。
〜過去の記事〜
【時系列】広告効果をモデリングする
その1 ABテスト(t検定)
https://skellington.blog.ss-blog.jp/2020-07-20
その2 簡単な線形回帰モデル
https://skellington.blog.ss-blog.jp/2020-07-21
対応のある分散分析とMauchlyの球面性testについて [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rで対応のある分散分析のやり方を教えて欲しい。
また、Mauchlyの球面性testについても教えて欲しい。
【回答】
通常、分散分析と言えば、対応なしの分散分析が一般的ですが、同じ郡について調査をする場合があり、その場合は、対応ありの分散分析となります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rで対応のある分散分析のやり方を教えて欲しい。
また、Mauchlyの球面性testについても教えて欲しい。
【回答】
通常、分散分析と言えば、対応なしの分散分析が一般的ですが、同じ郡について調査をする場合があり、その場合は、対応ありの分散分析となります。
# サンプルデータの準備
a1<- c(63,58,64,58,77,66,52,64,49,66)
a2<- c(64,64,68,61,56,71,64,65,85,75)
a3<- c(59,87,79,71,65,65,65,71,74,58)
a4<- c(83,79,65,67,80,72,80,75,72,84)
bunsan1<-data.frame(A=factor(c(rep("a1",10),
rep("a2",10),rep("a3",10),rep("a4",10))),y=c(a1,a2,a3,a4))
bunsan2<-data.frame(A= factor(c(rep("a1",10),
rep("a2",10), rep("a3",10), rep("a4",10))),No= factor(rep(1:10, 4)),y=c(a1,a2,a3,a4))
# 作図
boxplot(y~A,data=bunsan1,col="lightblue")
# 対応なしの分散分析
model1 <- aov(y~A, data=bunsan1)
summary(model1)
# 対応ありの分散分析
model2 <- (aov(y ~ A+No, bunsan2))
summary(model2)
# Mauchly’s sphericity test
# https://biostats.w.uib.no/test-for-sphericity-mauchly-test/
dat <- xtabs(y~No+A, bunsan2)
mauchly.test(lm(dat ~ 1), X = ~ 1)
# p-value = 0.694 なので分散に差があるとは言えない
千葉こどもの国 キッズダム〜ライセンスカート [ファミリー]
長男が「千葉こどもの国 キッズダム」に行きたいとずっと言っていました。
ライセンスカートというのがあり、講習会を受けると一人でゴーカートに乗れるアトラクションです。

小さい時は親と一緒でしか乗れなかったゴーカートですが、最近になって一人で運転できるようになりました。
そりゃ、一人で運転したいだろうな、ということで、久々のキッズダム。
すっかり人は戻って、それなりに混んでいました。
次男は、砂場を見つけて大喜び。
砂場に寝っ転がったり、埋まったりして楽しんだようですが、その後、砂の処理が大変でした・・・

ライセンスカートというのがあり、講習会を受けると一人でゴーカートに乗れるアトラクションです。
小さい時は親と一緒でしか乗れなかったゴーカートですが、最近になって一人で運転できるようになりました。
そりゃ、一人で運転したいだろうな、ということで、久々のキッズダム。
すっかり人は戻って、それなりに混んでいました。
次男は、砂場を見つけて大喜び。
砂場に寝っ転がったり、埋まったりして楽しんだようですが、その後、砂の処理が大変でした・・・
横浜・八景島シーパラダイス〜アクアリゾーツ [ファミリー]
横浜・八景島シーパラダイス〜アクアリゾーツ
http://www.seaparadise.co.jp/aquaresorts/
かな〜り前に八景島シーパラダイス行った記憶はあるのですが、久々のシーパラでした。

水族館はかなり壮大です。
チケットがあると、再入場もできるので、外のアトラクションで遊んだり、夜のナイトショーを観るために再入園したりできます。
アコヤガイから真珠を取り出してアクセサリーを作るイベントやっていました。
おもちゃのネックレスとかは持っているのですが、初めての本物(?)のアクセサリーを自分で作るという貴重な体験ができました♪
http://www.seaparadise.co.jp/aquaresorts/
かな〜り前に八景島シーパラダイス行った記憶はあるのですが、久々のシーパラでした。
水族館はかなり壮大です。
チケットがあると、再入場もできるので、外のアトラクションで遊んだり、夜のナイトショーを観るために再入園したりできます。
アコヤガイから真珠を取り出してアクセサリーを作るイベントやっていました。
おもちゃのネックレスとかは持っているのですが、初めての本物(?)のアクセサリーを自分で作るという貴重な体験ができました♪
横浜・八景島シーパラダイス〜アトラクション [ファミリー]
横浜・八景島シーパラダイス〜アトラクション
http://www.seaparadise.co.jp/pleasureland/
水族館(アクアリゾーツ)で遊んだ後は、アトラクションに移動しました。
残念ながら、激しい雨が降ったり止んだりで中止のアトラクションも多いです。
また、落雷の影響でほぼ全てのアトラクションがストップ。
どうしようかと思っていましたが、3時過ぎあたりから、少しずつアトラクションが再開しました。
絶叫系に乗ったり、迷路にチャレンジしたりと雨の合間を塗ってそれなりに楽しむことができましたが、基本的には、晴れていた方が楽しめると思います。
クライミングも楽しうそうでしたが、雨のため中止。
クライミングは次回にチャレンジですね。


http://www.seaparadise.co.jp/pleasureland/
水族館(アクアリゾーツ)で遊んだ後は、アトラクションに移動しました。
残念ながら、激しい雨が降ったり止んだりで中止のアトラクションも多いです。
また、落雷の影響でほぼ全てのアトラクションがストップ。
どうしようかと思っていましたが、3時過ぎあたりから、少しずつアトラクションが再開しました。
絶叫系に乗ったり、迷路にチャレンジしたりと雨の合間を塗ってそれなりに楽しむことができましたが、基本的には、晴れていた方が楽しめると思います。
クライミングも楽しうそうでしたが、雨のため中止。
クライミングは次回にチャレンジですね。
【SAOコラボ第2弾】ぼくの英雄【超究極】(アドミニストレータ)をクリア! [ゲーム]
アドミニストレータは絶望的な強さでしたが、なんとかクリアできました。
20回くらい挑戦してなんとか勝てました。
クリアしたパーティーは
1. 胡蝶しのぶ(獣神化)
2. エクリプス(獣神化)
3. 胡蝶しのぶ(獣神化)
4. キリト(獣神化)
です。
やはりキリトが強いですが、1体しか持っていません。
残りの3キャラをどうするか?
胡蝶しのぶ
エクリプス
シャーロックホームズ
で悩みましたが、結局、胡蝶しのぶを2体入れることにしました。
胡蝶しのぶを2体入れることで、雑魚処理とパネル合わせが楽になります。
ボスは基本的に、エクリプスかキリトで削ります。
個人的に、一番のポイントは、キリトに速必殺のLを付けること。
第3ステージに登場する中ボス(ソードゴーレム)ですが、即死ターンが7ターンと短いです。
なので、キリトのSSで片付けるのが一番安全。
ここでキリトのSSを使っても最終ステージまでにSSは貯まると思うので、惜しみなく使いましょう。
20回くらい挑戦してなんとか勝てました。
クリアしたパーティーは
1. 胡蝶しのぶ(獣神化)
2. エクリプス(獣神化)
3. 胡蝶しのぶ(獣神化)
4. キリト(獣神化)
です。
やはりキリトが強いですが、1体しか持っていません。
残りの3キャラをどうするか?
胡蝶しのぶ
エクリプス
シャーロックホームズ
で悩みましたが、結局、胡蝶しのぶを2体入れることにしました。
胡蝶しのぶを2体入れることで、雑魚処理とパネル合わせが楽になります。
ボスは基本的に、エクリプスかキリトで削ります。
個人的に、一番のポイントは、キリトに速必殺のLを付けること。
第3ステージに登場する中ボス(ソードゴーレム)ですが、即死ターンが7ターンと短いです。
なので、キリトのSSで片付けるのが一番安全。
ここでキリトのSSを使っても最終ステージまでにSSは貯まると思うので、惜しみなく使いましょう。
Tokyo Beer Paradise by Primus(東京ビアパラダイス)八重洲 [グルメ / クッキング]
Tokyo Beer Paradise by Primus
https://tokyobeerparadise.owst.jp/
久々に、ここで飲んできました。
ベルギービールは美味しいのですが、1杯が高い。
ここは珍しくベルギービールの飲み放題があります。
90分とやや短めですが、いろいろな種類のビールをたくさん飲めるはありがたいですね。
新型コロナウィルスの影響で、自分たち以外に誰も人がいなくて、経営的に大丈夫かな・・・と思ってしまいます。
ランチも美味しいお店なので、頑張って乗り越えて欲しいものです。
https://tokyobeerparadise.owst.jp/
久々に、ここで飲んできました。
ベルギービールは美味しいのですが、1杯が高い。
ここは珍しくベルギービールの飲み放題があります。
90分とやや短めですが、いろいろな種類のビールをたくさん飲めるはありがたいですね。
新型コロナウィルスの影響で、自分たち以外に誰も人がいなくて、経営的に大丈夫かな・・・と思ってしまいます。
ランチも美味しいお店なので、頑張って乗り越えて欲しいものです。
平均値の差の検定~サンプルサイズが大きい場合 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
下記の問題は、どう解けばいいか?
20代(300人)の購入額の平均:15000円, 標準偏差5000円
30代(400人)の購入額の平均:12000円, 標準偏差4000円
【回答】
この手の問題(平均値の差の検定)の場合、よくt検定を使って解きます。
サンプルサイズが小さい場合(通常だと10とか20くらいのサンプルサイズ)は、t検定を使うのですが、サンプルサイズが大きい場合(目安として100程度)は、z検定を使うことになります。
z検定ってあまり聞きなれない言葉かもしれませんが、要は標準正規分布に持ち込んで検定をすることができます。
帰無仮説H0:差がない
対立仮設H1:差がある
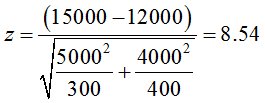
今回の問題だと、検定統計量zは、8.54となります。
α=0.05で両側検定をするので、
z(α/2)=z(0.025)=1.96
今回、8.54は、1.96に比べて、かなり大きい数字となっています。
つまり、違いがないと仮定した場合(帰無仮説H0)、そのような値が出る確率はかなり低く、対立仮設H1を採択します。
つまり、平均値の差は違いがあると考えた方が良いとなります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
下記の問題は、どう解けばいいか?
20代(300人)の購入額の平均:15000円, 標準偏差5000円
30代(400人)の購入額の平均:12000円, 標準偏差4000円
【回答】
この手の問題(平均値の差の検定)の場合、よくt検定を使って解きます。
サンプルサイズが小さい場合(通常だと10とか20くらいのサンプルサイズ)は、t検定を使うのですが、サンプルサイズが大きい場合(目安として100程度)は、z検定を使うことになります。
z検定ってあまり聞きなれない言葉かもしれませんが、要は標準正規分布に持ち込んで検定をすることができます。
帰無仮説H0:差がない
対立仮設H1:差がある
今回の問題だと、検定統計量zは、8.54となります。
α=0.05で両側検定をするので、
z(α/2)=z(0.025)=1.96
今回、8.54は、1.96に比べて、かなり大きい数字となっています。
つまり、違いがないと仮定した場合(帰無仮説H0)、そのような値が出る確率はかなり低く、対立仮設H1を採択します。
つまり、平均値の差は違いがあると考えた方が良いとなります。
平均値の差の検定~サンプルサイズが小さい場合(等分散の場合) [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
下記の問題は、どう解けばいいか?
20代(30人)の購入額の平均:15000円, 標準偏差5000円
30代(40人)の購入額の平均:12000円, 標準偏差5000円
【回答】
前回の問題に似ているのですが、サンプルサイズが小さいので、z検定に持ち込むことができません。
そこで、サンプルサイズが小さい場合の検定としては、t検定を使うことになります。
t検定は、二種類あって、等分散の場合と、そうでない場合に分けられます。
今回は、等分散の場合。
帰無仮説H0:差がない
対立仮設H1:差がある
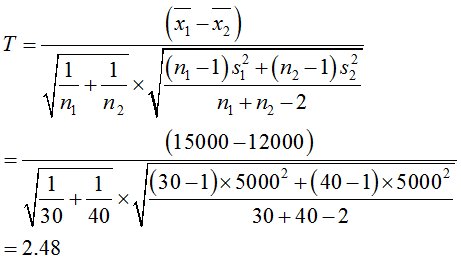
検定統計量は、2.48
自由度は(n1+n2-2)なので68となります。
t(68, 0.025) = 1.995
※ Rだと、qt(0.975, 68)で計算できます。
つまり、T=2.48 > 1.995なので、H0を棄却し、H1を採択します。
この場合は、差があると考えます。
■ 関連するページ
平均値の差の検定~サンプルサイズが大きい場合
https://skellington.blog.ss-blog.jp/
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
下記の問題は、どう解けばいいか?
20代(30人)の購入額の平均:15000円, 標準偏差5000円
30代(40人)の購入額の平均:12000円, 標準偏差5000円
【回答】
前回の問題に似ているのですが、サンプルサイズが小さいので、z検定に持ち込むことができません。
そこで、サンプルサイズが小さい場合の検定としては、t検定を使うことになります。
t検定は、二種類あって、等分散の場合と、そうでない場合に分けられます。
今回は、等分散の場合。
帰無仮説H0:差がない
対立仮設H1:差がある
検定統計量は、2.48
自由度は(n1+n2-2)なので68となります。
t(68, 0.025) = 1.995
※ Rだと、qt(0.975, 68)で計算できます。
つまり、T=2.48 > 1.995なので、H0を棄却し、H1を採択します。
この場合は、差があると考えます。
■ 関連するページ
平均値の差の検定~サンプルサイズが大きい場合
https://skellington.blog.ss-blog.jp/
平均値の差の検定~サンプルサイズが小さい場合(非等分散の場合) [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
下記の問題は、どう解けばいいか?
20代(30人)の購入額の平均:15000円, 標準偏差5000円
30代(40人)の購入額の平均:12000円, 標準偏差3000円
【回答】
t検定で等分散を仮定できない場合は、ウェルチのt検定を使います。
まずは、等分散の検定から。
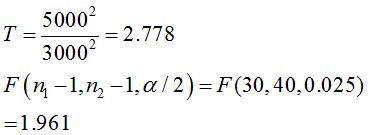
検定統計量Tは、2.778
F値1.961より検定統計量Tが大きいので、H0が棄却され、2つの母分散は異なると考えます。
つまり、非等分散となり、ウェルチのt検定を使います。
以下、ウェルチのt検定の進め方。
帰無仮説H0:差がない
対立仮設H1:差がある
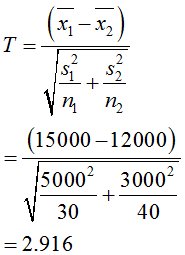
検定統計量は、2.916
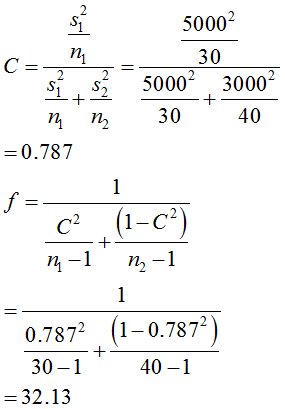
自由度は32.13となります。
t(32.13, 0.025) = 2.036
※ Rだと、qt(0.975, 32.13)で計算できます。
つまり、T=2.916 > 2.036なので、H0を棄却し、H1を採択します。
この場合は、差があると考えます。
■ 関連するページ
平均値の差の検定~サンプルサイズが大きい場合
https://skellington.blog.ss-blog.jp/
平均値の差の検定~サンプルサイズが小さい場合(等分散の場合)
https://skellington.blog.ss-blog.jp/2020-07-30
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
下記の問題は、どう解けばいいか?
20代(30人)の購入額の平均:15000円, 標準偏差5000円
30代(40人)の購入額の平均:12000円, 標準偏差3000円
【回答】
t検定で等分散を仮定できない場合は、ウェルチのt検定を使います。
まずは、等分散の検定から。
検定統計量Tは、2.778
F値1.961より検定統計量Tが大きいので、H0が棄却され、2つの母分散は異なると考えます。
つまり、非等分散となり、ウェルチのt検定を使います。
以下、ウェルチのt検定の進め方。
帰無仮説H0:差がない
対立仮設H1:差がある
検定統計量は、2.916
自由度は32.13となります。
t(32.13, 0.025) = 2.036
※ Rだと、qt(0.975, 32.13)で計算できます。
つまり、T=2.916 > 2.036なので、H0を棄却し、H1を採択します。
この場合は、差があると考えます。
■ 関連するページ
平均値の差の検定~サンプルサイズが大きい場合
https://skellington.blog.ss-blog.jp/
平均値の差の検定~サンプルサイズが小さい場合(等分散の場合)
https://skellington.blog.ss-blog.jp/2020-07-30

