アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
前回までは、ロジスティック回帰を使う場合、どのようにモデルを予測していて、実際はどうなっているか、の乖離を見てきました。
これから、複数回にわたり機械学習モデルを見ていきます。
まずは、サポートベクターマシン(英: support vector machine, SVM)から。
正しい集計結果は、こうでした。
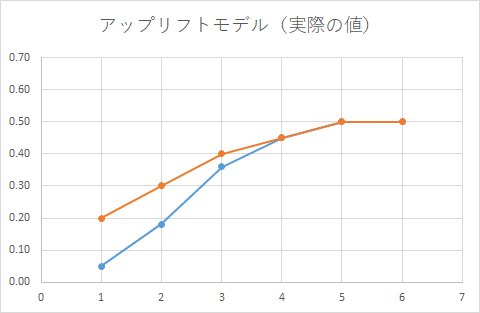
SVMは、カーネルタイプによってどのように判別するか変わってきます。
線形、RBF、多項式、Sigmoidがあります。
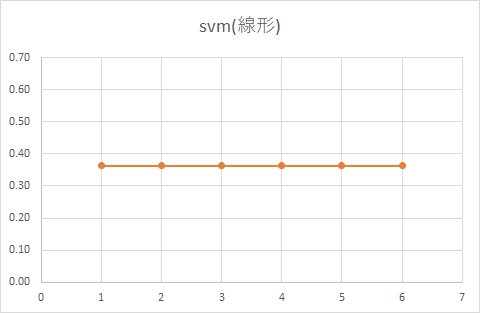
■ 線形
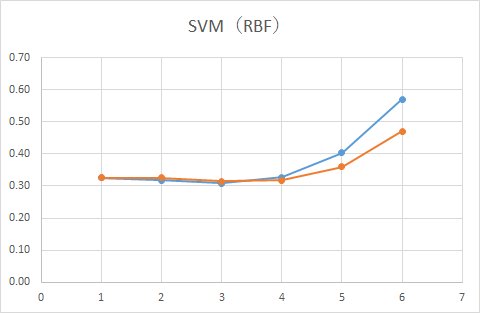
■ RBF
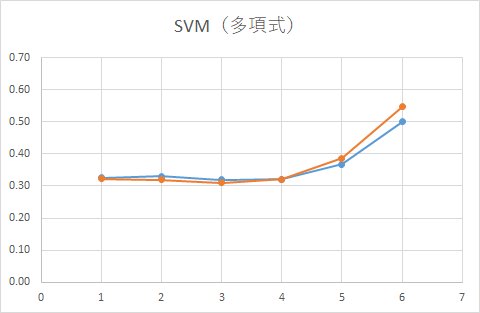
■ 多項式
■ Sigmoid
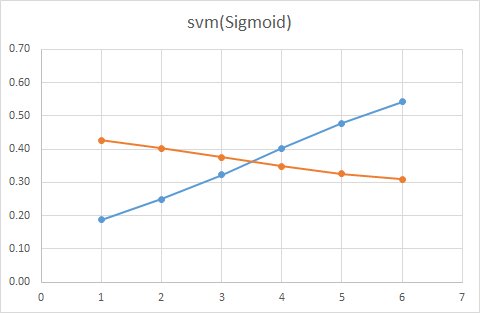
SVMでは「マージン最大化」という方法で線を引きます。
境界からもっとも近いベクトルとの距離を計算することで、パラメータを推定する速度が速いのが特徴なのですが、一方で、統計モデルなどと違い判別する境界以外に存在するデータの密度はみていません。
データが密集している部分はそれなりに離れているけど、
境界部分の距離が近いような場合ですと上手く予測できないのが欠点です。
例えば、SVM(線形)を見てみると、データ量が多い場合は、クーポンをもらった人ももらわなかった人も同じ確率であることが分かります。
試しに、12000人のサンプルサイズから10%だけサンプルした1200人でモデルを作った場合どうなるか見てみます。
データが発生するパラメータは同じですが、データ量が少なくなっているため、境界部分近くのデータも減少し、境界がはっきりするためどこも同じ確率といった金太郎飴状態は解消されるはずです。
■ 線形(利用するデータをランダムに10%だけ抽出)
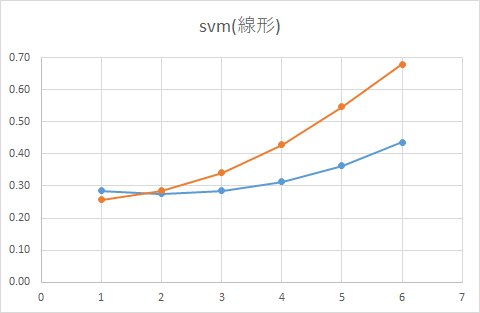
実際に予測した結果がこちら。
確かにクーポンをもらった人ともらわなかった人の確率は異なりますが、実際の集計結果とは程遠い結果になってしまっています。
また、統計的には、データ数をワザと減らすアプローチは正しいアプローチとは言えません。
信頼区間が拡大し、精度が低下するからです。
いずれにしろ、サポートベクターマシン(英: support vector machine, SVM)で作成したアップリフトモデルは、実際の値をずいぶんかけ離れた予測値になっていることがわかりました。
もっとパラメータをチューニングすれば別の結果になっていくと思いますが、実際に運用することを考えると、SVMを使ってのアップリフトモデルの運用は厳しい気がします。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
前回までは、ロジスティック回帰を使う場合、どのようにモデルを予測していて、実際はどうなっているか、の乖離を見てきました。
これから、複数回にわたり機械学習モデルを見ていきます。
まずは、サポートベクターマシン(英: support vector machine, SVM)から。
正しい集計結果は、こうでした。
SVMは、カーネルタイプによってどのように判別するか変わってきます。
線形、RBF、多項式、Sigmoidがあります。
■ 線形
■ RBF
■ 多項式
■ Sigmoid
SVMでは「マージン最大化」という方法で線を引きます。
境界からもっとも近いベクトルとの距離を計算することで、パラメータを推定する速度が速いのが特徴なのですが、一方で、統計モデルなどと違い判別する境界以外に存在するデータの密度はみていません。
データが密集している部分はそれなりに離れているけど、
境界部分の距離が近いような場合ですと上手く予測できないのが欠点です。
例えば、SVM(線形)を見てみると、データ量が多い場合は、クーポンをもらった人ももらわなかった人も同じ確率であることが分かります。
試しに、12000人のサンプルサイズから10%だけサンプルした1200人でモデルを作った場合どうなるか見てみます。
データが発生するパラメータは同じですが、データ量が少なくなっているため、境界部分近くのデータも減少し、境界がはっきりするためどこも同じ確率といった金太郎飴状態は解消されるはずです。
■ 線形(利用するデータをランダムに10%だけ抽出)
実際に予測した結果がこちら。
確かにクーポンをもらった人ともらわなかった人の確率は異なりますが、実際の集計結果とは程遠い結果になってしまっています。
また、統計的には、データ数をワザと減らすアプローチは正しいアプローチとは言えません。
信頼区間が拡大し、精度が低下するからです。
いずれにしろ、サポートベクターマシン(英: support vector machine, SVM)で作成したアップリフトモデルは、実際の値をずいぶんかけ離れた予測値になっていることがわかりました。
もっとパラメータをチューニングすれば別の結果になっていくと思いますが、実際に運用することを考えると、SVMを使ってのアップリフトモデルの運用は厳しい気がします。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19

