アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
これから複数回にわたり、失敗例を紹介していきます。
まずは、簡単に思いつく方法から。
広告の効果を特徴量に入れて、ロジスティック回帰モデルを作てみたらどうだろうか?
具体的な数式はこうなります。
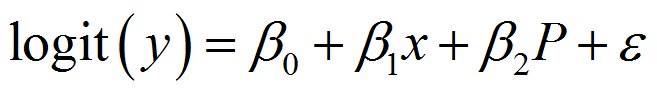
広告(クーポンの効果)を変数に入れているので、クーポンをもらったときともらわなかった時の差分を計算することが出来そうです。
具体的な差分の方法としては、こうなります。
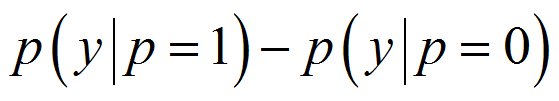
作成したロジスティック回帰モデルに、P=1(クーポン付与)とP=0(クーポン非付与)の値を入れます。
P=1は、クーポンをもらった時の状態
P=0は、クーポンをもらっていない時の状態
なんだか上手くいきそうな気がしますが、感度分析(実際にどのように予測しているか)をしてみると、下記になります。
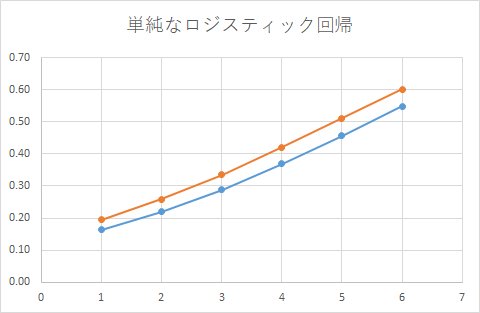
正しいモデルは、こうでした。
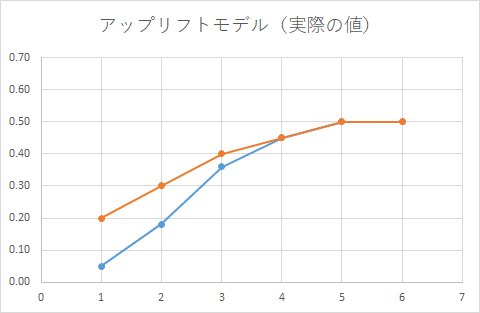
随分と間違えたモデルになっています。
その理由を知るために、どういうモデルを作ったのか?を考えると
広告の効果は、一律にβ2 * P で表現してしまっているところにあります。
もともとのアップリフトモデルの思想としては、人によって広告の感度が違う。
その人の異質性(クーポン感度の違い)をモデル化したい、でした。
しかし、実際に作っているモデル(ロジットモデル)は、全員同じパラメータβ3で表現してしまっています。
ということで、シンプルなロジスティック回帰モデルを作成するだけでは、人ごとの広告の効果を正しく測定することはできません。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
これから複数回にわたり、失敗例を紹介していきます。
まずは、簡単に思いつく方法から。
広告の効果を特徴量に入れて、ロジスティック回帰モデルを作てみたらどうだろうか?
具体的な数式はこうなります。
広告(クーポンの効果)を変数に入れているので、クーポンをもらったときともらわなかった時の差分を計算することが出来そうです。
# モデルの作成(シンプルなロジスティック回帰)
fit.1 <- glm(y~x+p, family = binomial, data = df)
df.fit.1 <- data.frame(df, response=predict(fit.1, type="response"))
with(subset(df.fit.1, p==1), by(response, INDICES=x, FUN=mean))
with(subset(df.fit.1, p==0), by(response, INDICES=x, FUN=mean))
具体的な差分の方法としては、こうなります。
作成したロジスティック回帰モデルに、P=1(クーポン付与)とP=0(クーポン非付与)の値を入れます。
P=1は、クーポンをもらった時の状態
P=0は、クーポンをもらっていない時の状態
なんだか上手くいきそうな気がしますが、感度分析(実際にどのように予測しているか)をしてみると、下記になります。
正しいモデルは、こうでした。
随分と間違えたモデルになっています。
その理由を知るために、どういうモデルを作ったのか?を考えると
広告の効果は、一律にβ2 * P で表現してしまっているところにあります。
もともとのアップリフトモデルの思想としては、人によって広告の感度が違う。
その人の異質性(クーポン感度の違い)をモデル化したい、でした。
しかし、実際に作っているモデル(ロジットモデル)は、全員同じパラメータβ3で表現してしまっています。
ということで、シンプルなロジスティック回帰モデルを作成するだけでは、人ごとの広告の効果を正しく測定することはできません。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19

