アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
これから複数回にわたり、失敗例を紹介していきます。

↑
こちらの本の9章に『Uplift Modelingによるマーケティング資源の効率化』という章があります。
その9.4章 2つの予測モデルを利用したUplift Modelingをみると、ターゲティング群とコントロール群でロジスティック回帰モデルを作成し、その差分(比率)をみることで効果を測定できるという考えです。
コントロール(C)、ターゲティング群(T)として
C:低&T:低 ⇒ 無関心
C:低&T:高 ⇒ 説得可能(クーポン付与対象者)
C:高&T:低 ⇒ 天邪鬼(???)
C:高&T:高 ⇒ 鉄板(クーポンコストが無駄)
クーポンもらわないと購買意欲高いのに、もらったら購買意欲が下がるような天邪鬼っているのだろうか?
コントロールとターゲティングのマトリックスで考えると、そういう可能性も考えられるわけですが、ビジネス感覚(マーケティングの感覚)として、ホンマか???と思ってしまいます。
まぁ、この方法に沿ってモデルを作成すると、そういう天邪鬼となってしまう群が出てくることも確かです。
結論から書けば、ちょっとした予測モデルのさじ加減で、クーポンをもらった方が購買確率が下がる人が出てきてしまう。
しかし、本当に購買意欲が下がるのかといえば、それは間違い。
単に予測モデルの作り方が間違えているだけ、というのが結論です。
実際に、二つのモデルを作るやり方をしてみると…
2つのロジスティック回帰モデルを作成するやり方
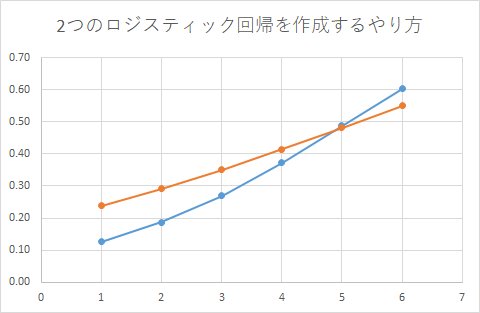
確かに、x=6の付近では、ターゲティンググループの方が購買確率が高くなっていますね。
天邪鬼なのでしょうか?
正しい集計結果は、こうでした。
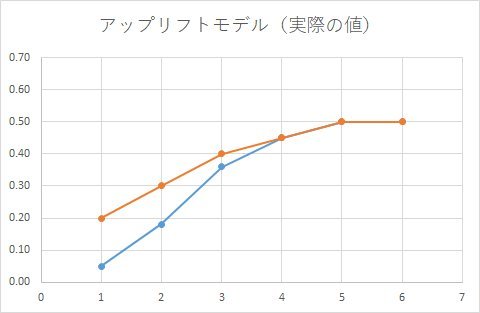
前回の「単純なロジスティック回帰を使う失敗例」と同様に随分と間違えたモデルになっています。
なぜ、このような結果になってしまったのか、問題点を整理します。
下のグラフが実際のデータ。
オレンジ色と青色を独立に最尤推定しています。
そこで推定されたモデルはそれぞれのデータでフィットするようになっているので、ある変数で見た時に、その値(βの係数)がターゲティンググループの方が必ず大きくなる!というような制約をいれているわけではないです。
なので、たまたま逆転してしまう個所が出てくるのは当然。
変数の数が増えてくるとこういう個所がどんどん出てきます。
では、逆転しているのは、係数による微妙なところだから、差はなし(0と置換)として良いのでしょうか?
予測モデルを、特定の部分(x=6)だけ0にしてしまうのも良くないです。
都合が悪い部分を、恣意的にいじってしまうとなぜ悪いか?
勝手に値を置換してしまうと、クーポンのコストを予測する時に問題が出てきます。
実際のyの平均値は、こうなっています。
> mean(subset(df, p==1)$y)
[1] 0.3875
> mean(subset(df, p==0)$y)
[1] 0.341
コントロール群の期待確率の平均は、0.341
ターゲティング群の期待確率の平均は、0.3875
つまり、1000円のクーポンをターゲティング群に付与すると平均で387.5円のクーポンのコストが発生することを意味しています。
予測モデル自体は微妙な統計モデルになっていますが、それでも予測モデルの期待確率の平均を計算すると、
[予測モデルの]コントロール群の期待確率の平均は、0.341
[予測モデルの]ターゲティング群の期待確率の平均は、0.3875
となっており、全体の平均値は正しいです。
しかし、天邪鬼のセグメントの予測値が都合が悪いからといって、0置換してしまうと、その部分の確率がゆがめられてしまい、コストの計算もゆがめられたもの担ってしまいます。
企業は、クーポンなどを配布する際にそれをマーケティングコストとして扱い、その予算を管理しています。
今回のマーケティング施策では、○○円のコストを使うという精度の高い予測が必要ですが、そのコスト予測がおかしなことになってしまう問題点があります。
ということで、「2つの予測モデルを利用したUplift Modeling」をまとめると、
・2つの予測モデルを別々に作ってしまうと本来はいないはずの天邪鬼セグメントが発生してしまう
・天邪鬼の確率(コントロールの方が確率が高いセグメント)を恣意的に置換するのは、コストを予測するという点においてベースライン(平均値)において誤差が生じる
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
これから複数回にわたり、失敗例を紹介していきます。
- 作者: 有賀 康顕
- 出版社/メーカー: オライリージャパン
- 発売日: 2018/01/16
- メディア: 単行本(ソフトカバー)
↑
こちらの本の9章に『Uplift Modelingによるマーケティング資源の効率化』という章があります。
その9.4章 2つの予測モデルを利用したUplift Modelingをみると、ターゲティング群とコントロール群でロジスティック回帰モデルを作成し、その差分(比率)をみることで効果を測定できるという考えです。
コントロール(C)、ターゲティング群(T)として
C:低&T:低 ⇒ 無関心
C:低&T:高 ⇒ 説得可能(クーポン付与対象者)
C:高&T:低 ⇒ 天邪鬼(???)
C:高&T:高 ⇒ 鉄板(クーポンコストが無駄)
クーポンもらわないと購買意欲高いのに、もらったら購買意欲が下がるような天邪鬼っているのだろうか?
コントロールとターゲティングのマトリックスで考えると、そういう可能性も考えられるわけですが、ビジネス感覚(マーケティングの感覚)として、ホンマか???と思ってしまいます。
まぁ、この方法に沿ってモデルを作成すると、そういう天邪鬼となってしまう群が出てくることも確かです。
結論から書けば、ちょっとした予測モデルのさじ加減で、クーポンをもらった方が購買確率が下がる人が出てきてしまう。
しかし、本当に購買意欲が下がるのかといえば、それは間違い。
単に予測モデルの作り方が間違えているだけ、というのが結論です。
実際に、二つのモデルを作るやり方をしてみると…
# モデルの作成(シンプルなロジスティック回帰を2つ作る)
# データの作成
df_t <- rbind(df_1t, df_2t, df_3t, df_4t, df_5t, df_6t)
df_c <- rbind(df_1c, df_2c, df_3c, df_4c, df_5c, df_6c)
fit.2t <- glm(y~x, family = binomial, data = df_t)
fit.2c <- glm(y~x, family = binomial, data = df_c)
df.fit.2t <- data.frame(df_t, response=predict(fit.2t, type="response"))
df.fit.2c <- data.frame(df_c, response=predict(fit.2c, type="response"))
with(df.fit.2t, by(response, INDICES=x, FUN=mean))
with(df.fit.2c, by(response, INDICES=x, FUN=mean))
2つのロジスティック回帰モデルを作成するやり方
確かに、x=6の付近では、ターゲティンググループの方が購買確率が高くなっていますね。
天邪鬼なのでしょうか?
正しい集計結果は、こうでした。
前回の「単純なロジスティック回帰を使う失敗例」と同様に随分と間違えたモデルになっています。
なぜ、このような結果になってしまったのか、問題点を整理します。
下のグラフが実際のデータ。
オレンジ色と青色を独立に最尤推定しています。
そこで推定されたモデルはそれぞれのデータでフィットするようになっているので、ある変数で見た時に、その値(βの係数)がターゲティンググループの方が必ず大きくなる!というような制約をいれているわけではないです。
なので、たまたま逆転してしまう個所が出てくるのは当然。
変数の数が増えてくるとこういう個所がどんどん出てきます。
では、逆転しているのは、係数による微妙なところだから、差はなし(0と置換)として良いのでしょうか?
予測モデルを、特定の部分(x=6)だけ0にしてしまうのも良くないです。
都合が悪い部分を、恣意的にいじってしまうとなぜ悪いか?
勝手に値を置換してしまうと、クーポンのコストを予測する時に問題が出てきます。
実際のyの平均値は、こうなっています。
> mean(subset(df, p==1)$y)
[1] 0.3875
> mean(subset(df, p==0)$y)
[1] 0.341
コントロール群の期待確率の平均は、0.341
ターゲティング群の期待確率の平均は、0.3875
つまり、1000円のクーポンをターゲティング群に付与すると平均で387.5円のクーポンのコストが発生することを意味しています。
予測モデル自体は微妙な統計モデルになっていますが、それでも予測モデルの期待確率の平均を計算すると、
[予測モデルの]コントロール群の期待確率の平均は、0.341
[予測モデルの]ターゲティング群の期待確率の平均は、0.3875
となっており、全体の平均値は正しいです。
しかし、天邪鬼のセグメントの予測値が都合が悪いからといって、0置換してしまうと、その部分の確率がゆがめられてしまい、コストの計算もゆがめられたもの担ってしまいます。
企業は、クーポンなどを配布する際にそれをマーケティングコストとして扱い、その予算を管理しています。
今回のマーケティング施策では、○○円のコストを使うという精度の高い予測が必要ですが、そのコスト予測がおかしなことになってしまう問題点があります。
ということで、「2つの予測モデルを利用したUplift Modeling」をまとめると、
・2つの予測モデルを別々に作ってしまうと本来はいないはずの天邪鬼セグメントが発生してしまう
・天邪鬼の確率(コントロールの方が確率が高いセグメント)を恣意的に置換するのは、コストを予測するという点においてベースライン(平均値)において誤差が生じる
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19

