アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
複数回にわたり機械学習モデルを見ていきます。
今回は、決定木を使い予測モデルを構築していきたいと思います。
決定木といってもそのアルゴリズムを使うか、また、親枝葉や小枝葉の最小レコード数をどう設定するか?で分岐の様子が異なってきます。
まずは、デフォルトで木の停止規則を設定した場合は下記となります。
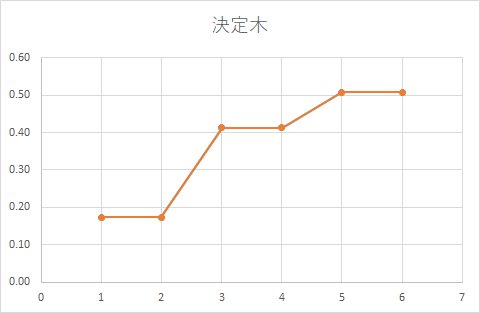
一本の線に見えますが、クーポンを配布した予測値とクーポンを配布しない予測値が同じ予測値となっています。
正しい集計結果は、こうでした。
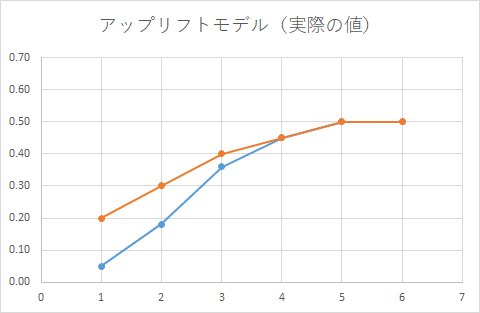
何が起こっているかといえば、予測変数の重要度を見ると、xの方がクーポンの特徴量より重要度が高いです。
そのため、まずは、xを使い木を成長していきます。
次に、クーポンの特徴量を使うかどうかです。
親枝葉や小枝葉の最小レコード数が大きい設定だったため、クーポンの変数を使うことができずに、木の成長が停止してしまいました。
それなら、親枝葉や小枝葉の最小レコード数を小さい値に設定してみてはどうだろうか?
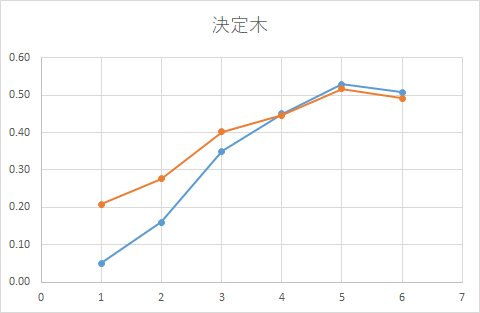
今度は、クーポンを配布した予測値とクーポンを配布しない予測値が別々に出てきました。
しかし、細かい分岐になってしまっており、x=4, 5, 6となるにつれ、予測値も微妙に変化しています。
また、x=5の方がx=6よりも大きな値になっています。
決定木は、xが増えるとyの値が単調に増えるとか減るといった制約を入れることができません。
感覚的には、決定木は細かいパラメータの設定は必要なものの、SVMほど変な予測値を出してこないイメージがあります。
使い方として、まず最初に決定木を使い、何が起こっているかを大枠で把握する。
その後で、もう少し精度の高い予測モデルを使用する、というアプローチが良い気がします。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
複数回にわたり機械学習モデルを見ていきます。
今回は、決定木を使い予測モデルを構築していきたいと思います。
決定木といってもそのアルゴリズムを使うか、また、親枝葉や小枝葉の最小レコード数をどう設定するか?で分岐の様子が異なってきます。
まずは、デフォルトで木の停止規則を設定した場合は下記となります。
一本の線に見えますが、クーポンを配布した予測値とクーポンを配布しない予測値が同じ予測値となっています。
正しい集計結果は、こうでした。
何が起こっているかといえば、予測変数の重要度を見ると、xの方がクーポンの特徴量より重要度が高いです。
そのため、まずは、xを使い木を成長していきます。
次に、クーポンの特徴量を使うかどうかです。
親枝葉や小枝葉の最小レコード数が大きい設定だったため、クーポンの変数を使うことができずに、木の成長が停止してしまいました。
それなら、親枝葉や小枝葉の最小レコード数を小さい値に設定してみてはどうだろうか?
今度は、クーポンを配布した予測値とクーポンを配布しない予測値が別々に出てきました。
しかし、細かい分岐になってしまっており、x=4, 5, 6となるにつれ、予測値も微妙に変化しています。
また、x=5の方がx=6よりも大きな値になっています。
決定木は、xが増えるとyの値が単調に増えるとか減るといった制約を入れることができません。
感覚的には、決定木は細かいパラメータの設定は必要なものの、SVMほど変な予測値を出してこないイメージがあります。
使い方として、まず最初に決定木を使い、何が起こっているかを大枠で把握する。
その後で、もう少し精度の高い予測モデルを使用する、というアプローチが良い気がします。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例 [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
複数回にわたり機械学習モデルを見ていきます。
今回は、ニューラルネットワークを使い予測モデルを構築していきたいと思います。
いくつパラメータを変更して予測モデルを作りました。
■ モデル1
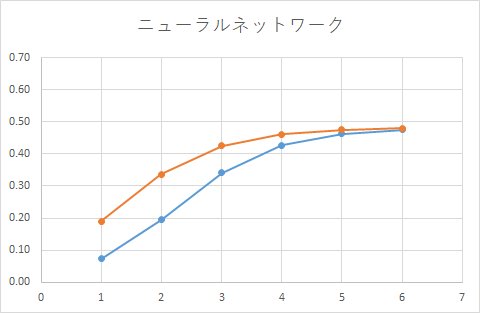
■ モデル2(ブースティング)
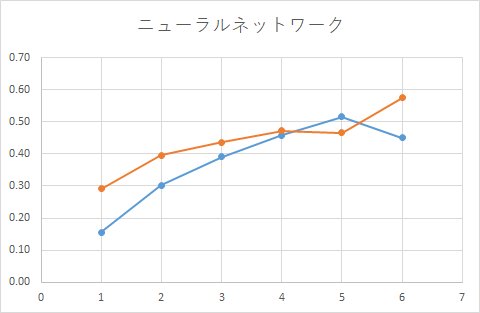
■ モデル3(バギング)
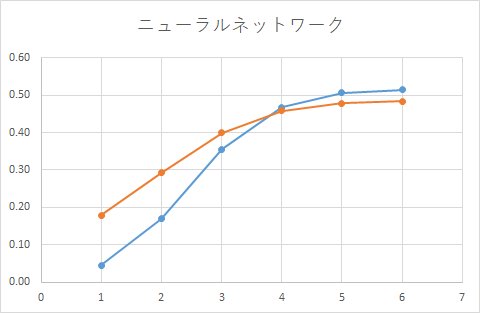
2つ目、3つ目は、ブースティンやバギングを行った予測モデルとなっています。
1つ目は、単純なモデルです。
皮肉なことに、1つ目の結果が実測値に一番近い結果となっています。
ここで、ゲインチャートを書いてみると、それぞれのモデルはほとんど同じ結果となっています。
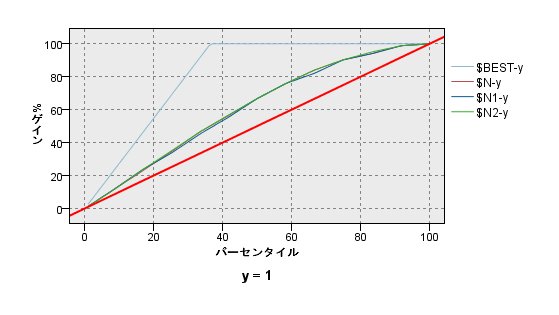
精度分析をしても、同じ結果となっています。
モデル AUC Gini
モデル1 0.672 0.344
モデル2 0.666 0.333
モデル3 0.675 0.350
しかし、実際どのように予測したかといった感度分析を行ってみると、それぞれ3つのモデルはけっこう違う予測モデルをしていることが分かります。
機械学習モデルを使ったアップリフトをモデルを使う場合、本来は、精度の比較だけでは物足りなくて、感度分析などを行い、どういう予測を行っているか、変な予測を行っていないかを行う必要があります。
また、精度は同程度であっても、それぞれ予測が間違えている個所は異なります。
どこを正確に予測出来ており、どこの予測が間違えているのかも合わせてチェックしていく必要がありそうです。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
複数回にわたり機械学習モデルを見ていきます。
今回は、ニューラルネットワークを使い予測モデルを構築していきたいと思います。
いくつパラメータを変更して予測モデルを作りました。
■ モデル1
■ モデル2(ブースティング)
■ モデル3(バギング)
2つ目、3つ目は、ブースティンやバギングを行った予測モデルとなっています。
1つ目は、単純なモデルです。
皮肉なことに、1つ目の結果が実測値に一番近い結果となっています。
ここで、ゲインチャートを書いてみると、それぞれのモデルはほとんど同じ結果となっています。
精度分析をしても、同じ結果となっています。
モデル AUC Gini
モデル1 0.672 0.344
モデル2 0.666 0.333
モデル3 0.675 0.350
しかし、実際どのように予測したかといった感度分析を行ってみると、それぞれ3つのモデルはけっこう違う予測モデルをしていることが分かります。
機械学習モデルを使ったアップリフトをモデルを使う場合、本来は、精度の比較だけでは物足りなくて、感度分析などを行い、どういう予測を行っているか、変な予測を行っていないかを行う必要があります。
また、精度は同程度であっても、それぞれ予測が間違えている個所は異なります。
どこを正確に予測出来ており、どこの予測が間違えているのかも合わせてチェックしていく必要がありそうです。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル [データサイエンス、統計モデル]
アップリフトモデルを作るコツと注意点をまとめたいと思います。
今回(最終回)は、階層ベイズロジットモデル。
まずは、結論から。
階層ベイズロジットモデルの予測結果。
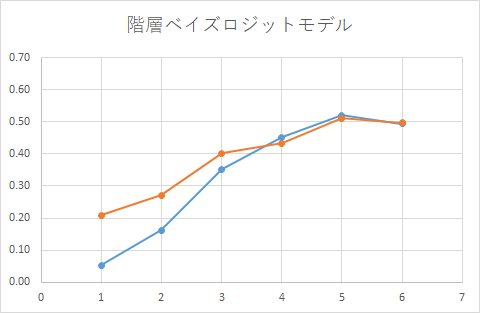
正しい集計結果は、こうでした。
ということで、かなり正確にアップリフト分を予測することが出来ています。
ただし、階層ベイズロジットモデルの欠点として、パラメータを推定ためのシミュレーションMCMCがやたら時間かかるという点です。
推定した後はそれほど時間はかからないのですが、変数の数が多いと1日くらい平気で時間がかかってしまいます。
この辺りは精度とパラメータの推定時間とのトレードオフなんだと思います。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
今回(最終回)は、階層ベイズロジットモデル。
まずは、結論から。
階層ベイズロジットモデルの予測結果。
正しい集計結果は、こうでした。
ということで、かなり正確にアップリフト分を予測することが出来ています。
ただし、階層ベイズロジットモデルの欠点として、パラメータを推定ためのシミュレーションMCMCがやたら時間かかるという点です。
推定した後はそれほど時間はかからないのですが、変数の数が多いと1日くらい平気で時間がかかってしまいます。
この辺りは精度とパラメータの推定時間とのトレードオフなんだと思います。
~その他の記事~
アップリフトモデルを作るコツと注意点
1. アップリフトモデルとは
https://skellington.blog.ss-blog.jp/2019-11-12
2. アップリフトモデルを作るコツと注意点2 単純なロジスティック回帰を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-13
3. アップリフトモデルを作るコツと注意点3 2つの予測モデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-14
4. アップリフトモデルを作るコツと注意点4 交互作用ありのモデルを使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-15
5. アップリフトモデルを作るコツと注意点5 機械学習のモデル(SVM)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-16
6. アップリフトモデルを作るコツと注意点6 機械学習のモデル(決定木)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-17
7. アップリフトモデルを作るコツと注意点7 機械学習のモデル(ニューラルネットワーク)を使う失敗例
https://skellington.blog.ss-blog.jp/2019-11-18
8. アップリフトモデルを作るコツと注意点8 階層ベイズロジットモデル
https://skellington.blog.ss-blog.jp/2019-11-19
昇仙峡 2019 仙娥滝でドーブル発見! [【旅行】中部]
「昇仙峡」に紅葉を見に行ってきました。
昇仙峡に行ったのは初めて。
一番手前にある駐車場に止めたのですが、滝やケーブルカーまでけっこう距離がありました。
馬車による移動もありますが、子連れだと厳しいかも。。。
混んでいてもそれなりに車の出し入れはあるようなので、真ん中か上の方の駐車場にするのが良いかと思います。
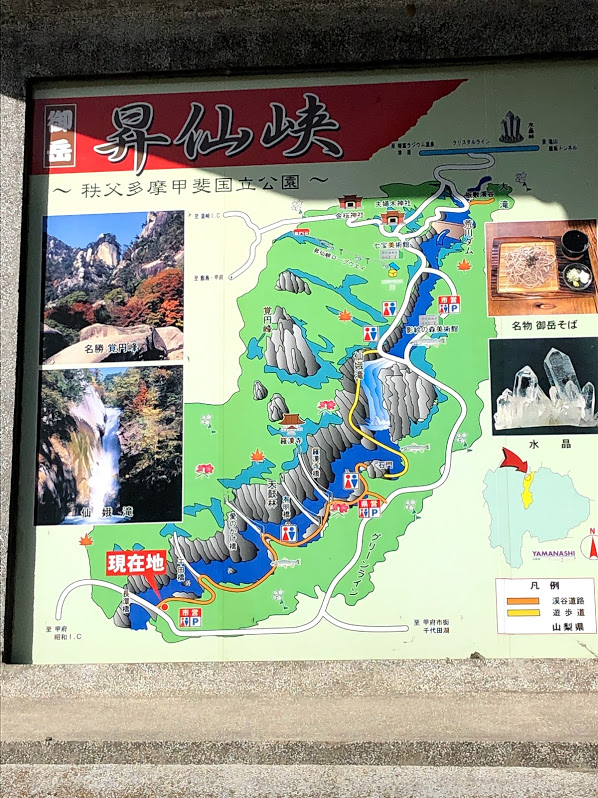

【ポケモンGO】ドーブルが実装されました。
入手方法はGoスナップショットを撮れば、ドーブルが紛れ込んでくるというものです。
何気なく仙娥滝でギャラドスの写真を撮ったら、ドーブルが写りこんでいましたw
ドーブル初ゲットです♪

昇仙峡に行ったのは初めて。
一番手前にある駐車場に止めたのですが、滝やケーブルカーまでけっこう距離がありました。
馬車による移動もありますが、子連れだと厳しいかも。。。
混んでいてもそれなりに車の出し入れはあるようなので、真ん中か上の方の駐車場にするのが良いかと思います。
【ポケモンGO】ドーブルが実装されました。
入手方法はGoスナップショットを撮れば、ドーブルが紛れ込んでくるというものです。
何気なく仙娥滝でギャラドスの写真を撮ったら、ドーブルが写りこんでいましたw
ドーブル初ゲットです♪
昇仙峡 2019 ロープウェイで弥三郎岳山頂へ [【旅行】中部]
「昇仙峡」に紅葉を見に行ってきました。
昇仙峡と弥三郎岳山頂との間を結ぶロープーウェイに乗り、弥三郎岳山頂へ。
山頂は、360度石の上で落ちたら死ぬ感じです。
ちゃんとした靴を履いていない場合、山頂を目指すのはやめた方が良いかもしれませんね。

昇仙峡と弥三郎岳山頂との間を結ぶロープーウェイに乗り、弥三郎岳山頂へ。
山頂は、360度石の上で落ちたら死ぬ感じです。
ちゃんとした靴を履いていない場合、山頂を目指すのはやめた方が良いかもしれませんね。
「ボジョレーヌーボ 2019」のキャッチコピー [ビール / ワイン / 日本酒 / 焼酎など]
「ボジョレーヌーボ 2019」のキャッチコピーですが、
【有望だが、生産者のテクニックが重要な年】
とのことでした。
サイトによったら
【凝縮した果実味と上品な酸味が味わえる】
と書かれています。
もうしばらくしたら、どれか一つに落ち着くんだと思います。
ちなみに2018年のキャッチコピーは
【しっかりとして味わい深く、同時になめらかで複雑】
【2017年、2015年、2009年と並び、珠玉のヴィンテージとして歴史に刻まれるでしょう】
でした。
まぁ、このキャッチコピーだけみていても、美味しいのか美味しくないのかわかりません。。。
また、価格帯もそれぞれありますし、ライトなボジョレーからコクありボジョレーまで様々。
なので、同じ年のボジョレーでもこっちのボジョレーは美味しいな、とかボジョレーはイマイチだな…となります。
自分にあうボジョレーが不明な場合は、ワイン専門店にいるソムリエさんに聞い見てるのが良いかと思います♪
【有望だが、生産者のテクニックが重要な年】
とのことでした。
サイトによったら
【凝縮した果実味と上品な酸味が味わえる】
と書かれています。
もうしばらくしたら、どれか一つに落ち着くんだと思います。
ちなみに2018年のキャッチコピーは
【しっかりとして味わい深く、同時になめらかで複雑】
【2017年、2015年、2009年と並び、珠玉のヴィンテージとして歴史に刻まれるでしょう】
でした。
まぁ、このキャッチコピーだけみていても、美味しいのか美味しくないのかわかりません。。。
また、価格帯もそれぞれありますし、ライトなボジョレーからコクありボジョレーまで様々。
なので、同じ年のボジョレーでもこっちのボジョレーは美味しいな、とかボジョレーはイマイチだな…となります。
自分にあうボジョレーが不明な場合は、ワイン専門店にいるソムリエさんに聞い見てるのが良いかと思います♪
鼻くそをほじる息子 [ファミリー]
最近、鼻くそをほじることを覚えてしまった息子(1歳5か月)
ただ、実際に鼻くそを出しているわけではなく、鼻の中に指を入れてじっとしていました。
ちょうど鼻の孔と指のサイズがピッタリなんでしょうね。w
ただ、実際に鼻くそを出しているわけではなく、鼻の中に指を入れてじっとしていました。
ちょうど鼻の孔と指のサイズがピッタリなんでしょうね。w
映画『アナと雪の女王2』が公開! [テレビ / 映画]
映画『アナと雪の女王2』が公開されました。
当日、観ようと思ったら、前日からのネット予約で既にいっぱい。
夜19時からだったら、席が空いているとのことでした。
仕方ないので、「東京ガス:がすてなーに」で遊んでいました。


当日、観ようと思ったら、前日からのネット予約で既にいっぱい。
夜19時からだったら、席が空いているとのことでした。
仕方ないので、「東京ガス:がすてなーに」で遊んでいました。
- アーティスト:
- 出版社/メーカー: Universal Music =music=
- 発売日: 2019/11/22
- メディア: CD
Rのアソシエーションルールで、欲しい条件のデータを抽出する方法 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
アソシエーションルール(マーケットバスケット分析)を行うパッケージに apriori があります。
rules <- apriori(trans_dat, parameter=list(minlen=2, maxlen=3, support=0.2, confidence=0))
ルールの抽出は、inspect(rules) で抽出できますが、膨大なルールが出力される場合があります。
その際、自分が知りたい条件にマッチしたデータだけを抽出することができるか?
【回答】
例1: lift が 2.0以上のルールを抽出する方法
inspect(subset(rules, lift >= 2.0))
subset(inspect(rules), lift >= 2.0) ではないので、注意が必要です。
例2: ルールの文字列マッチの方法
「パン, コーヒー ⇒ 菓子」というルールを抽出したい場合
前提条件は、lhs に格納されます。
結果は、rhs に格納されます。
今、「前提条件として、パン かつ コーヒー を含む」
「結果として、菓子 を含む 」行を抽出したいので、
inspect(subset(res, subset = lhs %ain% c("パン", "コーヒー") & rhs %in% "菓子" ))
で抜き出すことができます。
参考までに、
%in%: 指定した文字列を含むルールを抽出
%ain%: 複数の文字列を指定し、それらを全て含むルールを抽出
%oin%: 複数の文字列を指定し、いずれかの文字列含むルールを抽出
上記の %ain% を %oin% に変更した場合は、
「前提条件として、パン または コーヒー を含む」かつ「結果として、菓子 を含む 」ルールが抽出されます。
inspect(subset(res, subset = lhs %oin% c("パン", "コーヒー") & rhs %in% "菓子" ))
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
アソシエーションルール(マーケットバスケット分析)を行うパッケージに apriori があります。
rules <- apriori(trans_dat, parameter=list(minlen=2, maxlen=3, support=0.2, confidence=0))
ルールの抽出は、inspect(rules) で抽出できますが、膨大なルールが出力される場合があります。
その際、自分が知りたい条件にマッチしたデータだけを抽出することができるか?
【回答】
例1: lift が 2.0以上のルールを抽出する方法
inspect(subset(rules, lift >= 2.0))
subset(inspect(rules), lift >= 2.0) ではないので、注意が必要です。
例2: ルールの文字列マッチの方法
「パン, コーヒー ⇒ 菓子」というルールを抽出したい場合
前提条件は、lhs に格納されます。
結果は、rhs に格納されます。
今、「前提条件として、パン かつ コーヒー を含む」
「結果として、菓子 を含む 」行を抽出したいので、
inspect(subset(res, subset = lhs %ain% c("パン", "コーヒー") & rhs %in% "菓子" ))
で抜き出すことができます。
参考までに、
%in%: 指定した文字列を含むルールを抽出
%ain%: 複数の文字列を指定し、それらを全て含むルールを抽出
%oin%: 複数の文字列を指定し、いずれかの文字列含むルールを抽出
上記の %ain% を %oin% に変更した場合は、
「前提条件として、パン または コーヒー を含む」かつ「結果として、菓子 を含む 」ルールが抽出されます。
inspect(subset(res, subset = lhs %oin% c("パン", "コーヒー") & rhs %in% "菓子" ))
ポアソン検定:ポアソンのλを検定したい [データサイエンス、統計モデル]
購入割合(1 or 0)の検定は、prop.testを使うことができますし、
体重や身長といった量的データの検定は、t.testを使うことができます。
今回は、少し特殊なポアソン検定について。
身長や体重といった連続量ではなく、0, 1, 2といった回数データ(カウントデータ、そしてその数はそれほど多くない)に対してどういった検定を行えば良いか?
ぱっと思いつくのは、ポアソン分布に従っているので、そのλ(平均値)が二つのグループで異なるかどうかを検定したい、となります。
まず、ポアソン分布はパラメータがλしかありません。
平均も分散もλという強い縛りがあるので、実データでなかなか再現することはなかなかないです。
実際は分散が平均よりもはるかに大きな過分散状態になっている場合が多いのではないでしょうか。
かりに、平均も分散もそれなりに等しいデータだったとして以下ポアソン検定についての説明をしていきます。
TG1:ターゲットグループの成功回数
CG1:コントロールグループの成功回数
TG2:ターゲットグループの試行回数
CG2:コントロールグループの試行回数
とします。
つまり、10人いて、一人が複数回、購入し合計30回の購入があったとします。
この時、TG1=30, TG2=10となります。
# ポアソン検定
poisson.test(c(TG1, CG1), c(TG1, CG1), alternative = "greater", conf.level = 0.95)
alternativeのオプションは、両側検定("two.sided")か片側検定("less", "greater")となります。
何も指定しない場合、デフォルトは、両側検定。
conf.levelは信頼区間を設定できます。
体重や身長といった量的データの検定は、t.testを使うことができます。
今回は、少し特殊なポアソン検定について。
身長や体重といった連続量ではなく、0, 1, 2といった回数データ(カウントデータ、そしてその数はそれほど多くない)に対してどういった検定を行えば良いか?
ぱっと思いつくのは、ポアソン分布に従っているので、そのλ(平均値)が二つのグループで異なるかどうかを検定したい、となります。
まず、ポアソン分布はパラメータがλしかありません。
平均も分散もλという強い縛りがあるので、実データでなかなか再現することはなかなかないです。
実際は分散が平均よりもはるかに大きな過分散状態になっている場合が多いのではないでしょうか。
かりに、平均も分散もそれなりに等しいデータだったとして以下ポアソン検定についての説明をしていきます。
TG1:ターゲットグループの成功回数
CG1:コントロールグループの成功回数
TG2:ターゲットグループの試行回数
CG2:コントロールグループの試行回数
とします。
つまり、10人いて、一人が複数回、購入し合計30回の購入があったとします。
この時、TG1=30, TG2=10となります。
# ポアソン検定
poisson.test(c(TG1, CG1), c(TG1, CG1), alternative = "greater", conf.level = 0.95)
alternativeのオプションは、両側検定("two.sided")か片側検定("less", "greater")となります。
何も指定しない場合、デフォルトは、両側検定。
conf.levelは信頼区間を設定できます。
gmailで添付し忘れ [よもやま日記]
最近、so-netのメールから、gmailに変更したのですが、gmailがなかなかすごい!
「○○を添付します。」とメールで書いて、実際に添付し忘れたことって何度かあります。
気が付いて送りなおす時もあれば、先方から添付されてませんよ!と連絡が来るときも。w
今日、gmailを使っていて、「○○を添付します。」と書いておきながら、添付していなくてそのまま「送信」ボタンを押したのですが、なんと!
「添付します。」とありますが、何も添付されていないけど、大丈夫ですか?的な注意メッセージがgmailで出てきました。
ルールベース化何かで実装しているんでしょうけど、これは便利な機能だな!って思いました。
流行りの言葉で言うなら、「賢いAIだな・・・」ってことになるんでしょうけど。w
「○○を添付します。」とメールで書いて、実際に添付し忘れたことって何度かあります。
気が付いて送りなおす時もあれば、先方から添付されてませんよ!と連絡が来るときも。w
今日、gmailを使っていて、「○○を添付します。」と書いておきながら、添付していなくてそのまま「送信」ボタンを押したのですが、なんと!
「添付します。」とありますが、何も添付されていないけど、大丈夫ですか?的な注意メッセージがgmailで出てきました。
ルールベース化何かで実装しているんでしょうけど、これは便利な機能だな!って思いました。
流行りの言葉で言うなら、「賢いAIだな・・・」ってことになるんでしょうけど。w
Audi a4の2年目点検 [自動車 / バイク]
2年前に購入したAudi A4ですが、なんだかんだともうすぐ2年になります。
初回のパッケージに入っていたので、点検費用とかは無料。
来年で3年になるので、いよいよ車検となります。
別のブログとか見ていると、20万超えとか、けっこうな値段するみたいですが、安全のために仕方がないとことですかね。。。
そういえば、我が家では子供が増えてきたのでスライド式のバンタイプにしようか迷っています。
Audiにはバンタイプがないので、なぜ出さないか聞いたところ・・・
ヨーロッパでは、日本で流行っているバンは貨物車両扱いだそうで、
安全面を考慮して、一般車で設定されている速度よりもずっと遅い制限速度が設定されているとか。
日本だと、四角い箱の車が、ガタガタ言わせながら高速道路を爆走している姿が見られますが、本当は危ないんだとか。
自分も高速道路を運転していて、後ろから煽ってくる車はだいたいそれ系統ではあります。
実際に、高速道路などで事故をした場合、Audiの場合は、むち打ちなどになるかもしれないものの、死亡事故に直結するような大事故にならないように設計されているらしい。
一方で、箱型の車(ワゴンタイプ)は、重大事故にすぐ直結します。
特に3列目とかに乗っていて、後ろから突っ込まれたら、かなり危ないですしね。
また、安全面の検査ですが、Audiやボルボは実際にダミーを座らせた実験を行って検証しているそうです。
国産車は、基本、コンピューターで解析をしているだけなので、どこまで安全かは未知数。
街乗りだったら、ボックスタイプでも良いけど、長距離の高速運転はやめた方が良いですよ、と言われました。。。w
初回のパッケージに入っていたので、点検費用とかは無料。
来年で3年になるので、いよいよ車検となります。
別のブログとか見ていると、20万超えとか、けっこうな値段するみたいですが、安全のために仕方がないとことですかね。。。
そういえば、我が家では子供が増えてきたのでスライド式のバンタイプにしようか迷っています。
Audiにはバンタイプがないので、なぜ出さないか聞いたところ・・・
ヨーロッパでは、日本で流行っているバンは貨物車両扱いだそうで、
安全面を考慮して、一般車で設定されている速度よりもずっと遅い制限速度が設定されているとか。
日本だと、四角い箱の車が、ガタガタ言わせながら高速道路を爆走している姿が見られますが、本当は危ないんだとか。
自分も高速道路を運転していて、後ろから煽ってくる車はだいたいそれ系統ではあります。
実際に、高速道路などで事故をした場合、Audiの場合は、むち打ちなどになるかもしれないものの、死亡事故に直結するような大事故にならないように設計されているらしい。
一方で、箱型の車(ワゴンタイプ)は、重大事故にすぐ直結します。
特に3列目とかに乗っていて、後ろから突っ込まれたら、かなり危ないですしね。
また、安全面の検査ですが、Audiやボルボは実際にダミーを座らせた実験を行って検証しているそうです。
国産車は、基本、コンピューターで解析をしているだけなので、どこまで安全かは未知数。
街乗りだったら、ボックスタイプでも良いけど、長距離の高速運転はやめた方が良いですよ、と言われました。。。w
ショッピングサイト決済時だけ偽画面 [マネー]
ショッピングサイト決済時だけ偽画面 クレジット情報を盗む
https://www3.nhk.or.jp/news/html/20191202/k10012198271000.html
これまでの手口として、銀行などの偽メールから、本物そっくりの偽サイトに誘導させて、銀行の暗証番号とかクレジットカード情報を盗む手口が多かったように思えます。
最近は、手口が巧妙化していて、ショッピングサイト決済時だけ偽画面に誘導。
さすがに、これをやられたら、気が付けないな。。。という印象です。
実際に、決済だけ他サイトに飛ばす決済も多く、その飛ばされた先が本物なのか偽物なのか、かなり難しい状況です。
オンラインショッピング以外の普段使いでも、瞬時にカード番号とか暗記してカード情報を盗める特殊能力を持った人もいるみたいだし。
そんなことを考えていると、街中での決済はIDとかSuicaなどで決済するのが安全だし、中小のオンラインショッピングなどは、極力利用しない。
利用する場合は、捨てても良いクレジットカードを利用する、とかって方針になっていくんでしょうかね。。。
https://www3.nhk.or.jp/news/html/20191202/k10012198271000.html
これまでの手口として、銀行などの偽メールから、本物そっくりの偽サイトに誘導させて、銀行の暗証番号とかクレジットカード情報を盗む手口が多かったように思えます。
最近は、手口が巧妙化していて、ショッピングサイト決済時だけ偽画面に誘導。
さすがに、これをやられたら、気が付けないな。。。という印象です。
実際に、決済だけ他サイトに飛ばす決済も多く、その飛ばされた先が本物なのか偽物なのか、かなり難しい状況です。
オンラインショッピング以外の普段使いでも、瞬時にカード番号とか暗記してカード情報を盗める特殊能力を持った人もいるみたいだし。
そんなことを考えていると、街中での決済はIDとかSuicaなどで決済するのが安全だし、中小のオンラインショッピングなどは、極力利用しない。
利用する場合は、捨てても良いクレジットカードを利用する、とかって方針になっていくんでしょうかね。。。
スタジオアリスとスタジオマリオの比較 [ファミリー]
長男が1/2成人式、長女が七五三ってことで、写真撮影をしてきました。
いつもはスタジオマリオを使っていますが、予約がいっぱいで撮れなかったので、スタジオアリスで撮ってきました。
初めてスタジオアリスを使ってみて、スタジオマリオとずいぶんと違う印象です。
その違いをまとめました。
購入した写真の元データについて
スタジオマリオ:購入した写真と同時に受け取り可能
スタジオアリス:撮影してから1年後の受け取り可能
スタジオ内での個人カメラについて
スタジオマリオ:動画撮影は常時可能。
スタジオアリス:静止画の撮影は、撮影時以外なら可能。
着替えから撮影の流れ
スタジオマリオ:基本的にはその時間は1家族のみ。撮影時間が短い。長くても2時間くらい。
スタジオアリス:いろいろな家族が入り乱れて撮影。待合スペースが短いし、撮影時間が長い。4時間くらいかかった。
撮影料
スタジオマリオ:ちょっと割高。
スタジオアリス:ちょっと格安。


いつもはスタジオマリオを使っていますが、予約がいっぱいで撮れなかったので、スタジオアリスで撮ってきました。
初めてスタジオアリスを使ってみて、スタジオマリオとずいぶんと違う印象です。
その違いをまとめました。
購入した写真の元データについて
スタジオマリオ:購入した写真と同時に受け取り可能
スタジオアリス:撮影してから1年後の受け取り可能
スタジオ内での個人カメラについて
スタジオマリオ:動画撮影は常時可能。
スタジオアリス:静止画の撮影は、撮影時以外なら可能。
着替えから撮影の流れ
スタジオマリオ:基本的にはその時間は1家族のみ。撮影時間が短い。長くても2時間くらい。
スタジオアリス:いろいろな家族が入り乱れて撮影。待合スペースが短いし、撮影時間が長い。4時間くらいかかった。
撮影料
スタジオマリオ:ちょっと割高。
スタジオアリス:ちょっと格安。

