欠損値を含むレコードの処理 その4 平均値代入 [データサイエンス、統計モデル]
リストワイズ削除は、データを削除するのでもったいない感じがします。
そこで、平均値で代入してみてはどうか?という発想です。
まずは、結果から。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:127 ○
yの標準偏差:14.5 ×(低い)
xとyの相関:0.322 ×(低い)
[MAR]
yの平均:141 ×(高い)
yの標準偏差:13.2 ×(低い)
xとyの相関:0.111 ×(低い)
[MNAR]
yの平均:152 ×(高い)
yの標準偏差:7.99 ×(低い)
xとyの相関:0.194 ×(低い)
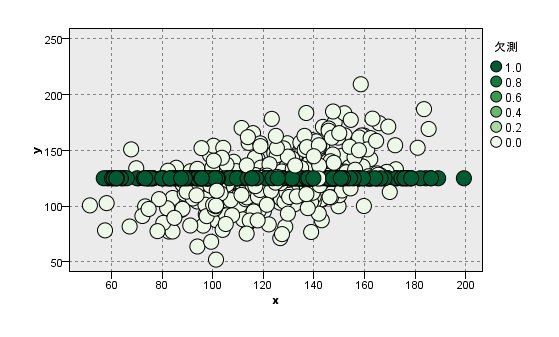
なぜ、このような事が起こっているのか散布図を書いてみます。
[MCAR]の場合
平均値は真値に近いです。
これは、xとyが完全にランダムであるから。
しかし、yの値を一定の値にしてしまっているために
yの標準偏差が低くなったり、xとyの相関も低くなったりします。
CRT Treeを使った欠測処理で、CRTが分岐せずに全部同じ値になっていることと同様の結果ですね。
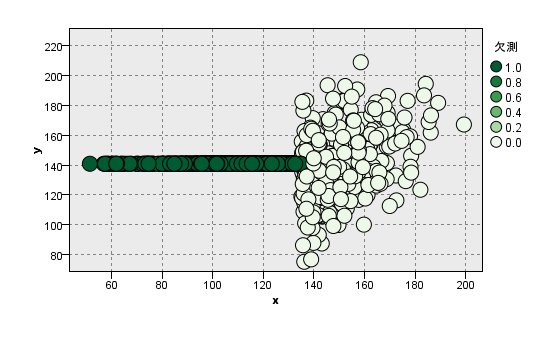
[MAR]の場合(x <= 135を欠損させる)
yの平均が高くなる理由ですが、xとyが相関があります。
欠測している個所は、欠損していない箇所よりも平均値が低くなっているはずです。
しかし、欠損していない個所の平均値で欠損箇所を埋めてしまっているために平均値が低くなってしまいます。
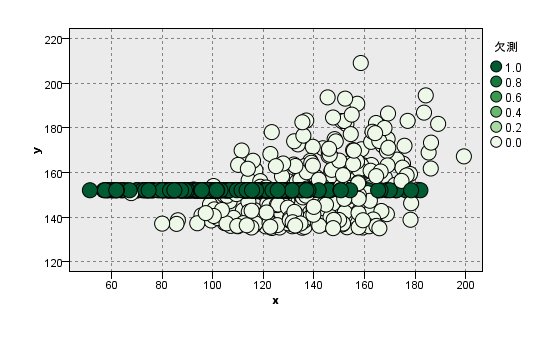
[MNAR]の場合(y <= 135を欠損させる)
MARよりもさらに平均値が高いです。
今回は、低いyの値を欠損させているにもかかわらず、高いyの値で補完していることが原因です。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その3 リストワイズ削除
http://skellington.blog.so-net.ne.jp/2016-12-21
そこで、平均値で代入してみてはどうか?という発想です。
まずは、結果から。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:127 ○
yの標準偏差:14.5 ×(低い)
xとyの相関:0.322 ×(低い)
[MAR]
yの平均:141 ×(高い)
yの標準偏差:13.2 ×(低い)
xとyの相関:0.111 ×(低い)
[MNAR]
yの平均:152 ×(高い)
yの標準偏差:7.99 ×(低い)
xとyの相関:0.194 ×(低い)
なぜ、このような事が起こっているのか散布図を書いてみます。
[MCAR]の場合
平均値は真値に近いです。
これは、xとyが完全にランダムであるから。
しかし、yの値を一定の値にしてしまっているために
yの標準偏差が低くなったり、xとyの相関も低くなったりします。
CRT Treeを使った欠測処理で、CRTが分岐せずに全部同じ値になっていることと同様の結果ですね。
[MAR]の場合(x <= 135を欠損させる)
yの平均が高くなる理由ですが、xとyが相関があります。
欠測している個所は、欠損していない箇所よりも平均値が低くなっているはずです。
しかし、欠損していない個所の平均値で欠損箇所を埋めてしまっているために平均値が低くなってしまいます。
[MNAR]の場合(y <= 135を欠損させる)
MARよりもさらに平均値が高いです。
今回は、低いyの値を欠損させているにもかかわらず、高いyの値で補完していることが原因です。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その3 リストワイズ削除
http://skellington.blog.so-net.ne.jp/2016-12-21

