欠損値を含むレコードの処理 その3 リストワイズ削除 [データサイエンス、統計モデル]
リストワイズ削除とは、一つでも欠損があったら全部のレコードを削除するという方法になります。
なんだかもったいない気もします。。。
リストワイズ削除をすると、どのような影響になるのか、SPSS Modelerで検証します。
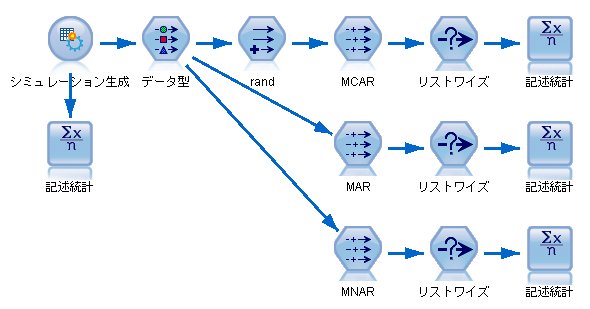
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:126 ○
yの標準偏差:25.2 ○
xとyの相関:0.557 ○
[MAR]
yの平均:141 ×(高すぎる)
yの標準偏差:22.8 ×(低い)
xとyの相関:0.380 ×(低い)
[MNAR]
yの平均:152 ×(高すぎる)
yの標準偏差:14.2 ×(低すぎる)
xとyの相関:0.401 ×(低い)
xとyが完全ランダムの場合のみyの平均もyの標準偏差も同じになっていますが、
MARやMNARの場合は上手く復元できません。
特にxとyの相関係数は、切断効果により小さくなってしまいます。
リストワイズは手っ取り早いのですが、単純にデータを削除すると、平均や標準偏差など得られた結果がおかしい場合があるので注意が必要ですね。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
なんだかもったいない気もします。。。
リストワイズ削除をすると、どのような影響になるのか、SPSS Modelerで検証します。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:126 ○
yの標準偏差:25.2 ○
xとyの相関:0.557 ○
[MAR]
yの平均:141 ×(高すぎる)
yの標準偏差:22.8 ×(低い)
xとyの相関:0.380 ×(低い)
[MNAR]
yの平均:152 ×(高すぎる)
yの標準偏差:14.2 ×(低すぎる)
xとyの相関:0.401 ×(低い)
xとyが完全ランダムの場合のみyの平均もyの標準偏差も同じになっていますが、
MARやMNARの場合は上手く復元できません。
特にxとyの相関係数は、切断効果により小さくなってしまいます。
リストワイズは手っ取り早いのですが、単純にデータを削除すると、平均や標準偏差など得られた結果がおかしい場合があるので注意が必要ですね。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20

