欠損値を含むレコードの処理 その1 欠測データの生成方法 [データサイエンス、統計モデル]
レコードの中に欠損値があることは、よくあります。
IBM SPSS Modelerでも欠損値がある場合、それを補正するノードは用意されているのですが、今回、欠測データ解析の講義を受けて、なるほど!と思ったことがあったので、まとめたいと思います。
基本、SPSS Modelerでシミュレーションしていきます。
欠測データ解析と言えば、Rubin(1976)があまりにも有名です。
欠損値を3つのタイプに分けることができます。
今、(X, Y)の2変量データ、Yに欠測があるとします。
・MCAR(Missing Completely At Random)
YにもXにも依存しない。
・MAR(Missing At Random)
Yには依存しないが、Xに依存する。
・MNAR(Missing Not At Random)
Yに依存する。
いろいろな方法がありますが、上手く行くのはMCARとMARの場合です。
まずは、欠測データ解析用のデータを作ります。
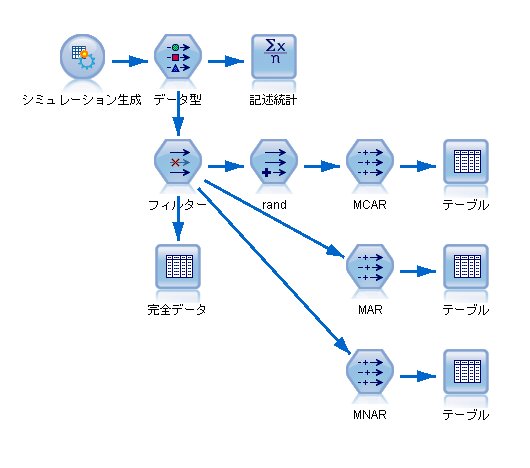
[入力]タブにあるシミュレーション生成ノードを使います。
2変数(x, y)はともに平均が125, 標準偏差が25, 相関は0.6とします。
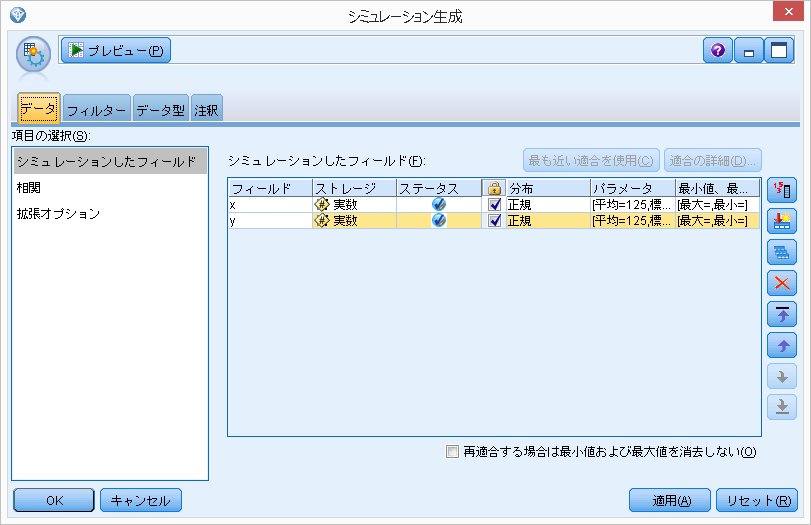
項目の選択
シミュレーションしたフィールド
ここで平均が125, 標準偏差が25を設定
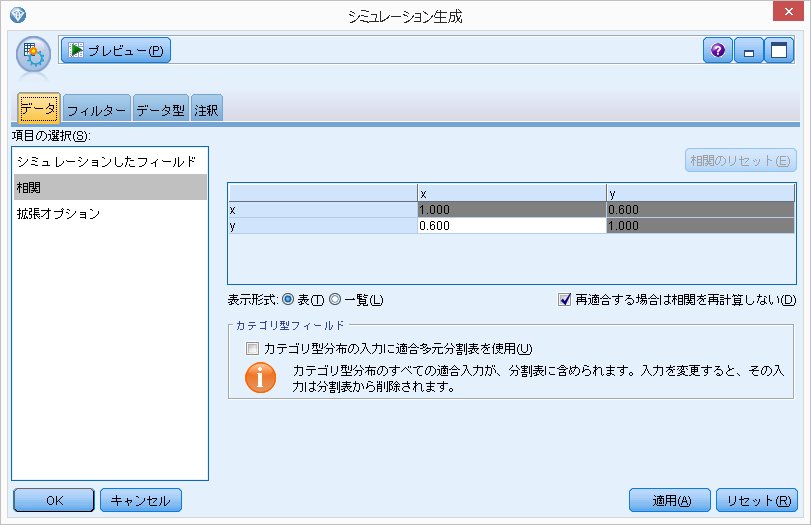
相関
ここで相関0.6を設定
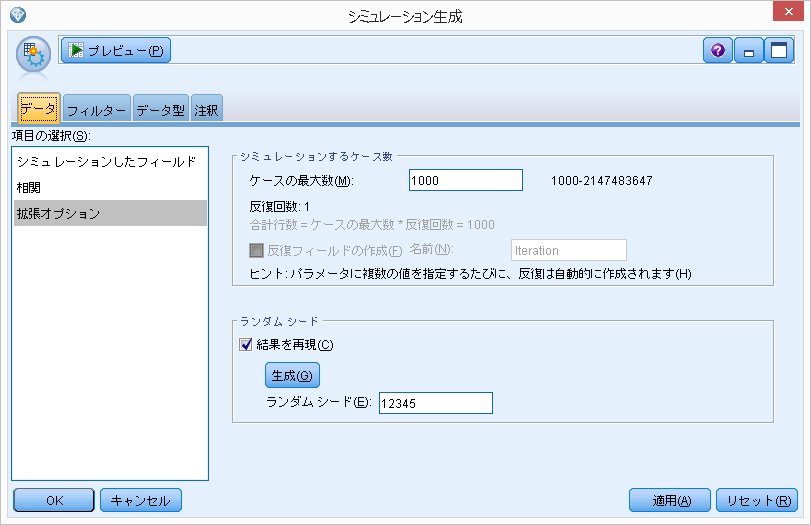
拡張オプション
発生させる乱数として1000個のデータを生成
ランダムシードを12345と設定
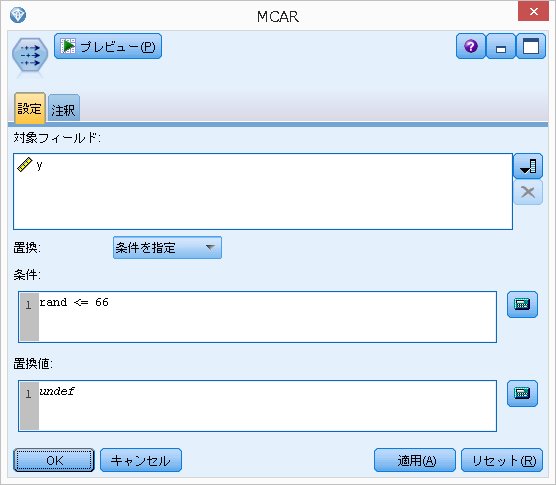
・MCAR(Missing Completely At Random)の作り方
randというフィールドを作成します。
random(100) と書くと、0 < x <= 100となります。
実際は、1から100までの100通りの乱数が生成されます。
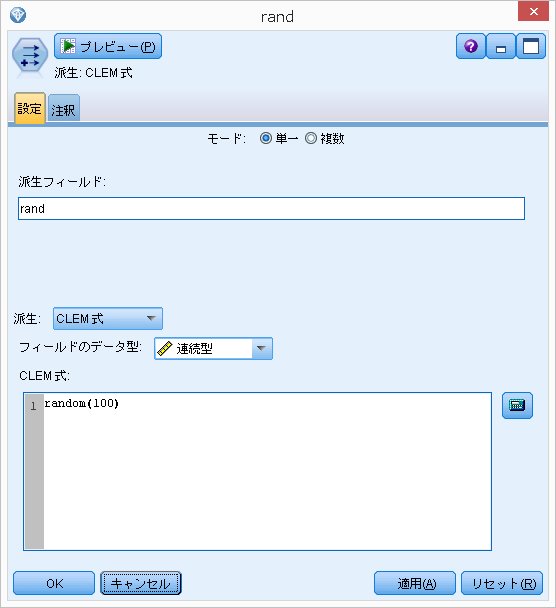
random0(100) と書くと、0 <= x <= 100となります。
実際は、0から100までの101通りの乱数が生成されます。
通常は、randomを使うことが多いかと思われます。
YにもXにも依存しない。
つまり、randの値が66以下の場合にデータを欠損させます。
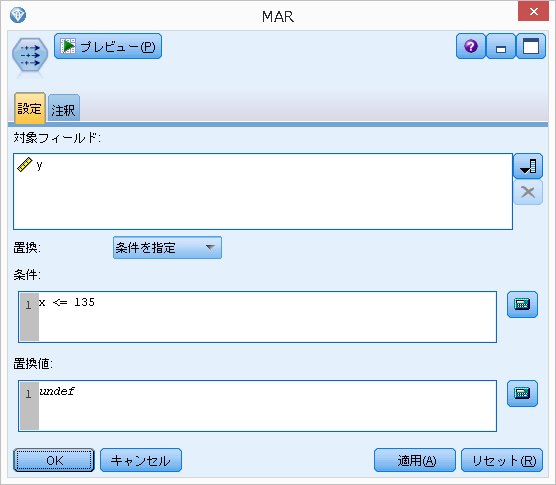
・MAR(Missing At Random)の作り方
Yには依存しないが、Xに依存する。
つまり、x <= 135 の場合に、yの値を欠損させます。
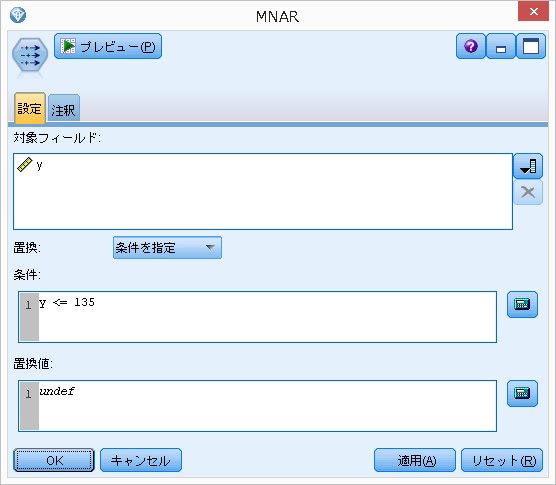
・MNAR(Missing Not At Random)
Yに依存する。
つまり、y <= 135 の場合に、yの値を欠損させます。
以下、欠測データを補完した場合にどうなるかをシミュレーションしていきます。
ちなみに、このデータは、相関は0.6で作っているので、y = a x + b という単回帰を考えた場合、回帰係数は0.6となるはずです。
完全データで線形回帰を行った場合、
y = 0.5962 * x + 50.83
となりました。
確かに、回帰係数は 0.6 となっています。
欠測データじゃないので、当然の結果と言えば当然の結果ですが。。。(^^;
欠測データがある場合、
・そのレコードを削除する
・平均値や最頻値などの固定値で置換する
・回帰などのアルゴリズムを使う
が考えられます。
SPSS Staticsでは、Missing Valuesを購入すれば、EMアルゴリズムで推定したり
多重代入を使って置換することができるようです。
SPSS Modelerに搭載されているアルゴリズムは、C&RT Treeが使えます。
IBM SPSS Modelerでも欠損値がある場合、それを補正するノードは用意されているのですが、今回、欠測データ解析の講義を受けて、なるほど!と思ったことがあったので、まとめたいと思います。
基本、SPSS Modelerでシミュレーションしていきます。
欠測データ解析と言えば、Rubin(1976)があまりにも有名です。
欠損値を3つのタイプに分けることができます。
今、(X, Y)の2変量データ、Yに欠測があるとします。
・MCAR(Missing Completely At Random)
YにもXにも依存しない。
・MAR(Missing At Random)
Yには依存しないが、Xに依存する。
・MNAR(Missing Not At Random)
Yに依存する。
いろいろな方法がありますが、上手く行くのはMCARとMARの場合です。
まずは、欠測データ解析用のデータを作ります。
[入力]タブにあるシミュレーション生成ノードを使います。
2変数(x, y)はともに平均が125, 標準偏差が25, 相関は0.6とします。
項目の選択
シミュレーションしたフィールド
ここで平均が125, 標準偏差が25を設定
相関
ここで相関0.6を設定
拡張オプション
発生させる乱数として1000個のデータを生成
ランダムシードを12345と設定
・MCAR(Missing Completely At Random)の作り方
randというフィールドを作成します。
random(100) と書くと、0 < x <= 100となります。
実際は、1から100までの100通りの乱数が生成されます。
random0(100) と書くと、0 <= x <= 100となります。
実際は、0から100までの101通りの乱数が生成されます。
通常は、randomを使うことが多いかと思われます。
YにもXにも依存しない。
つまり、randの値が66以下の場合にデータを欠損させます。
・MAR(Missing At Random)の作り方
Yには依存しないが、Xに依存する。
つまり、x <= 135 の場合に、yの値を欠損させます。
・MNAR(Missing Not At Random)
Yに依存する。
つまり、y <= 135 の場合に、yの値を欠損させます。
以下、欠測データを補完した場合にどうなるかをシミュレーションしていきます。
ちなみに、このデータは、相関は0.6で作っているので、y = a x + b という単回帰を考えた場合、回帰係数は0.6となるはずです。
完全データで線形回帰を行った場合、
y = 0.5962 * x + 50.83
となりました。
確かに、回帰係数は 0.6 となっています。
欠測データじゃないので、当然の結果と言えば当然の結果ですが。。。(^^;
欠測データがある場合、
・そのレコードを削除する
・平均値や最頻値などの固定値で置換する
・回帰などのアルゴリズムを使う
が考えられます。
SPSS Staticsでは、Missing Valuesを購入すれば、EMアルゴリズムで推定したり
多重代入を使って置換することができるようです。
SPSS Modelerに搭載されているアルゴリズムは、C&RT Treeが使えます。

