欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理 [データサイエンス、統計モデル]
IBM SPSS Modelerには欠損値検査が付いています。
(手法としては、全部、微妙なのであまり使わない方が良さそうです。)
[データ検査]ノードというものがあります。
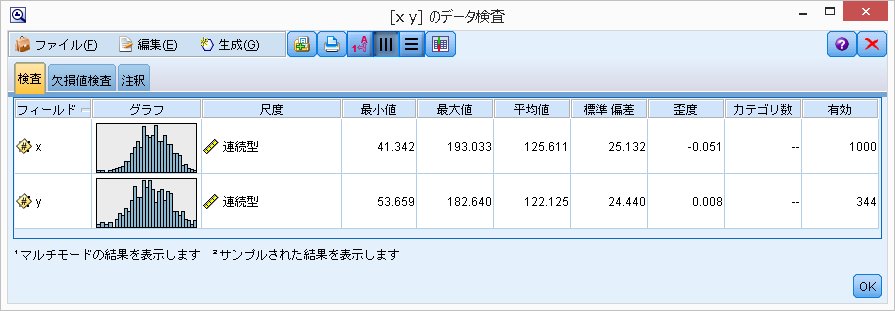
実行すると、このようなアウトプットが出てきます。
欠損値検査タブをクリックすると、どのようなアルゴリズムで欠損値を補完するかを選択することができます。
用意されているのは、下記の4種類。
1. 固定値
2. 無作為
3. 式(回帰式)
4. アルゴリズム(CRT)
1.~3.は、また、別の機会に調べるとして、まずは、4.のアルゴリズムから。
元々、データマイニングツールということもあり、補完するアルゴリズムは決定木のCRT(CA&RT)になっています。
なんで、CARTかといえば、classification and regression treesの名前の通り、
分類と回帰の両方を扱えます。
つまり、名義変数の補完の場合はclassification、連続値の補完としてregressionを使うことができるかです。
一見、上手く行きそうですが、細かく見ていくとおかしなことが起こっています。
今回、xとyは、相関0.600の関係になるようにサンプリングしています。
欠測を与える前のxとy値は0.592となっています。
欠測データを補完した際にxとyの相関も0.600(0.592)付近になることが期待されるのですが、0.315という結果になっていました。
出来上がったモデルを見ると、下図のようになっています。
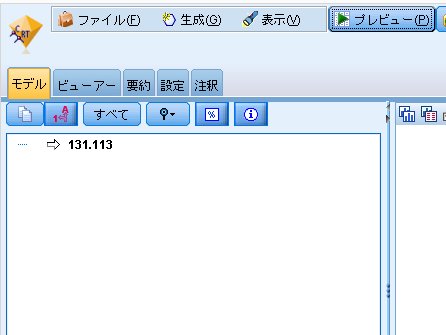
つまり、欠損データ部分にすべて同じ値を埋めましょう、ということを意味しています。
次に、散布図を書いてみると、このようになります。
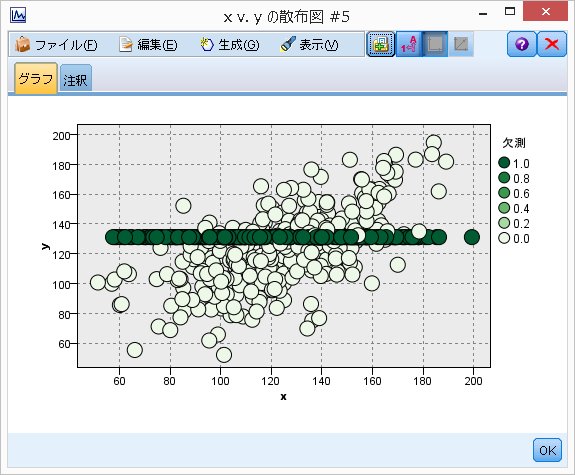
緑色の部分が欠損値のデータを補完した部分になります。
このようにすべて同じ値で埋めてしまうため、xとyの相関が0.315と低い値になってしまいました。
次にランダムシードを変更して実行すると、今度は、木が分岐し、散布図は下図のようになっています。
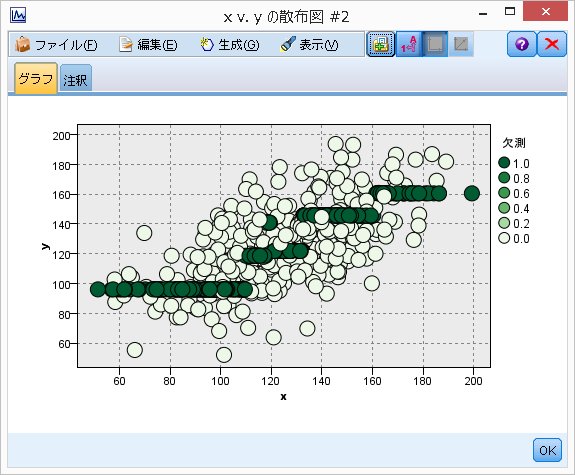
先ほど違ってすべて同じ値ではないのですが、やはり多くの個所を一つの値で置換していることがわかります。
また、別の問題として、C&RTを使って分岐するということは、
ちょっとした決定木の分岐の違いによって補完される値が変わってしまいます。
その結果、相関係数の値が実行するたびに大きく変化することも問題です。
ということで、一見、もっともらしいアルゴリズム(CRT)で置換しているように見えますが、細かく見ていくと、変なことが起こっているので、この置換方法はやめた方が良いように思えます。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
(手法としては、全部、微妙なのであまり使わない方が良さそうです。)
[データ検査]ノードというものがあります。
実行すると、このようなアウトプットが出てきます。
欠損値検査タブをクリックすると、どのようなアルゴリズムで欠損値を補完するかを選択することができます。
用意されているのは、下記の4種類。
1. 固定値
2. 無作為
3. 式(回帰式)
4. アルゴリズム(CRT)
1.~3.は、また、別の機会に調べるとして、まずは、4.のアルゴリズムから。
元々、データマイニングツールということもあり、補完するアルゴリズムは決定木のCRT(CA&RT)になっています。
なんで、CARTかといえば、classification and regression treesの名前の通り、
分類と回帰の両方を扱えます。
つまり、名義変数の補完の場合はclassification、連続値の補完としてregressionを使うことができるかです。
一見、上手く行きそうですが、細かく見ていくとおかしなことが起こっています。
今回、xとyは、相関0.600の関係になるようにサンプリングしています。
欠測を与える前のxとy値は0.592となっています。
欠測データを補完した際にxとyの相関も0.600(0.592)付近になることが期待されるのですが、0.315という結果になっていました。
出来上がったモデルを見ると、下図のようになっています。
つまり、欠損データ部分にすべて同じ値を埋めましょう、ということを意味しています。
次に、散布図を書いてみると、このようになります。
緑色の部分が欠損値のデータを補完した部分になります。
このようにすべて同じ値で埋めてしまうため、xとyの相関が0.315と低い値になってしまいました。
次にランダムシードを変更して実行すると、今度は、木が分岐し、散布図は下図のようになっています。
先ほど違ってすべて同じ値ではないのですが、やはり多くの個所を一つの値で置換していることがわかります。
また、別の問題として、C&RTを使って分岐するということは、
ちょっとした決定木の分岐の違いによって補完される値が変わってしまいます。
その結果、相関係数の値が実行するたびに大きく変化することも問題です。
ということで、一見、もっともらしいアルゴリズム(CRT)で置換しているように見えますが、細かく見ていくと、変なことが起こっているので、この置換方法はやめた方が良いように思えます。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19

