SPSS Clementine(PASWModeler)の文字コード設定 [データサイエンス、統計モデル]
今までは、SPSS Clementine(PASWModeler)でShift_JISの文字コードを扱うことが多かったのだが、サイトカタリストのデータを扱うようになってUTF-8の文字コードを扱う必要が出てきた。
サイトカタリストのraw dataは、UTF-8がデフォルトらしい。。。
そのままクレメンタインで読み込むと、文字化けを起こす。
回避方法としては、
1. いったん、raw dataの文字コードをShift_JISからUTF-8に変更する。
⇒ 面倒くさい。。。
2. SPSS Clementine(PASWModeler)の文字コードの設定を変更する。
がある。
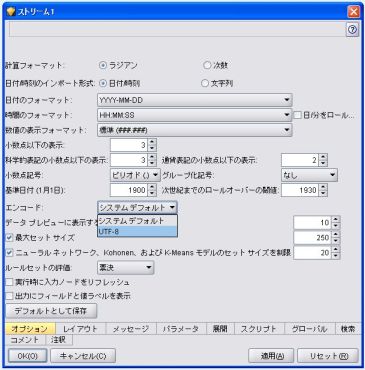
[ストリームのプロパティ]の[オプション]からエンコードを選択。
システムデフォルトをUTF-8に変更すれば、OKである。
では、次のような場合はどうすれば良いのだろうか?
あるテキストファイルは、Shift_JISの文字コードで作成されており、あるテキストファイルは、UTF-8で作成されている。
このような場合は、
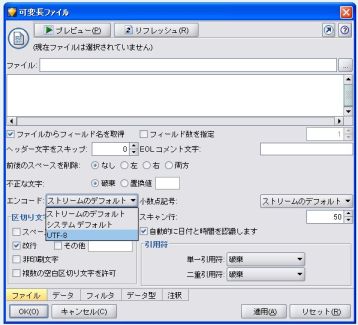
入力ノード(可変長ファイル)のエンコードの設定を変更すれば、複数の文字コードのテキストを同時に扱うことができる。
そもそも、文字コードはそろえておいた方が良いんだけどねぇ。。。
サイトカタリストのraw dataは、UTF-8がデフォルトらしい。。。
そのままクレメンタインで読み込むと、文字化けを起こす。
回避方法としては、
1. いったん、raw dataの文字コードをShift_JISからUTF-8に変更する。
⇒ 面倒くさい。。。
2. SPSS Clementine(PASWModeler)の文字コードの設定を変更する。
がある。
[ストリームのプロパティ]の[オプション]からエンコードを選択。
システムデフォルトをUTF-8に変更すれば、OKである。
では、次のような場合はどうすれば良いのだろうか?
あるテキストファイルは、Shift_JISの文字コードで作成されており、あるテキストファイルは、UTF-8で作成されている。
このような場合は、
入力ノード(可変長ファイル)のエンコードの設定を変更すれば、複数の文字コードのテキストを同時に扱うことができる。
そもそも、文字コードはそろえておいた方が良いんだけどねぇ。。。
2009-10-13 23:59
nice!(1)

