統計の「超」勉強法 [データサイエンス、統計モデル]
嫁が、daigoの超勉強法を動画を見て、子供の受験対策で何か活用できないか、と話題になった。
「超」勉強法の話を聞いていると、自分が統計を身につけた体験と結構似ていて、知らず知らずに自分も統計を「超」勉強法っぽい感じで学習していたようです。
せっかくなので、統計の「超」勉強法っぽいことを書きたいと思います。
まずは、基本原則から。
1. 「面白いことを勉強する」
統計を勉強する際に、推定と検定が割と教科書の最初に出てくるのですが、一番ややこしい部分です。
なので、さらっと流して、モデリング(回帰)から始めるのが良いかと思います。
中でも、自分が必要としているモデリングからやるのが良い。
面白いというよりかは、必要に迫られているからものすごく集中して身につけようとするから。
2.「全体から理解する」
統計の細かい数式を理解しようとすると、挫折します。
ただ、細かい数式を理解できると幅が出てくるので、最初はあまり細部を見なくて、何度か繰り返し学習していく中で少しずつ細部を理解していくのが良いかと思います。
全体を理解するってことですが、まずは感覚的に理解すること。
数式がわからない人にどうやったら理解してもらえるか?を考えると、「要は、こういうことなんだよね。」という例え話で理解すると良いかもしれません。
3.「8割までをやる」
よくある単元を完璧に理解するまで、先に進めない人がいます。
なかなか100%ってのはないので、7割から8割くらいで次に進むのが良いかと思います。
########################################
ここから先は、経験的に、自分が思う学習法として載せておきます。
########################################
4. 人に教える
人に教える、つまり、口に出して話すことで、意外とうろ覚えだったり、話している中で「どういう意味だっけ?」となります。
その部分について、徹底的に調べて理解する。
2,3の逆ですが、一つ一つ潰していくことで、7割〜8割を9割、10割りに近づけていく。
これをやらないと、いつまで経っても、8割のまま。
また、人に教えている中で、必ず質問がきます。
この質問が大切で、自分が気がつかなかった視点を教えている人から教えてもらうことができます。
当然、すぐにわからない部分もたくさんあるので、ここに関しても、再学習です。
5. 忘れたら覚える。
忘れる前に覚え直すことはあまり良くないらしい。
忘れてしまった!という後悔が記憶にいいらしいので、忘れたら覚え直すを繰り返すと頭に定着します。
6. 別の角度から見つめ直す。
同じ教科書からだと、同じ側からしか見えない。
いろいろな人の講義を聞いたり、いろいろな書物を読むことで、平面だったものが立体に見えてくる。
########################################
さらに上級者になるために
########################################
7. 真理の扉の先に真理の扉がある
もう、この部分に関しては、相当知識がついて、ほぼ完璧にわかっている!と思っていても、実は、まだまだ、自分はわかっていなかったって気がつく部分があります。
これが最後の真理の扉かなと思って開いたら、さらに、その奥に広い部屋があって、まだ、次の扉を開いていく。
そんな感覚です。
1.〜6.を繰り返していくと、世の中的にも相当できる人になっているかと思います。
そこで、驕れることなく、まだ、この先に、自分が知らない世界があるはずだという気持ちを忘れなければ、きっと、扉は向こうからやってくることでしょう。
「これを知る者はこれを好む者に如かず。これを好む者はこれを楽しむ者に如かず。」ってやつですかね。

「超」勉強法の話を聞いていると、自分が統計を身につけた体験と結構似ていて、知らず知らずに自分も統計を「超」勉強法っぽい感じで学習していたようです。
せっかくなので、統計の「超」勉強法っぽいことを書きたいと思います。
まずは、基本原則から。
1. 「面白いことを勉強する」
統計を勉強する際に、推定と検定が割と教科書の最初に出てくるのですが、一番ややこしい部分です。
なので、さらっと流して、モデリング(回帰)から始めるのが良いかと思います。
中でも、自分が必要としているモデリングからやるのが良い。
面白いというよりかは、必要に迫られているからものすごく集中して身につけようとするから。
2.「全体から理解する」
統計の細かい数式を理解しようとすると、挫折します。
ただ、細かい数式を理解できると幅が出てくるので、最初はあまり細部を見なくて、何度か繰り返し学習していく中で少しずつ細部を理解していくのが良いかと思います。
全体を理解するってことですが、まずは感覚的に理解すること。
数式がわからない人にどうやったら理解してもらえるか?を考えると、「要は、こういうことなんだよね。」という例え話で理解すると良いかもしれません。
3.「8割までをやる」
よくある単元を完璧に理解するまで、先に進めない人がいます。
なかなか100%ってのはないので、7割から8割くらいで次に進むのが良いかと思います。
########################################
ここから先は、経験的に、自分が思う学習法として載せておきます。
########################################
4. 人に教える
人に教える、つまり、口に出して話すことで、意外とうろ覚えだったり、話している中で「どういう意味だっけ?」となります。
その部分について、徹底的に調べて理解する。
2,3の逆ですが、一つ一つ潰していくことで、7割〜8割を9割、10割りに近づけていく。
これをやらないと、いつまで経っても、8割のまま。
また、人に教えている中で、必ず質問がきます。
この質問が大切で、自分が気がつかなかった視点を教えている人から教えてもらうことができます。
当然、すぐにわからない部分もたくさんあるので、ここに関しても、再学習です。
5. 忘れたら覚える。
忘れる前に覚え直すことはあまり良くないらしい。
忘れてしまった!という後悔が記憶にいいらしいので、忘れたら覚え直すを繰り返すと頭に定着します。
6. 別の角度から見つめ直す。
同じ教科書からだと、同じ側からしか見えない。
いろいろな人の講義を聞いたり、いろいろな書物を読むことで、平面だったものが立体に見えてくる。
########################################
さらに上級者になるために
########################################
7. 真理の扉の先に真理の扉がある
もう、この部分に関しては、相当知識がついて、ほぼ完璧にわかっている!と思っていても、実は、まだまだ、自分はわかっていなかったって気がつく部分があります。
これが最後の真理の扉かなと思って開いたら、さらに、その奥に広い部屋があって、まだ、次の扉を開いていく。
そんな感覚です。
1.〜6.を繰り返していくと、世の中的にも相当できる人になっているかと思います。
そこで、驕れることなく、まだ、この先に、自分が知らない世界があるはずだという気持ちを忘れなければ、きっと、扉は向こうからやってくることでしょう。
「これを知る者はこれを好む者に如かず。これを好む者はこれを楽しむ者に如かず。」ってやつですかね。
- 作者: メンタリストDaiGo
- 出版社/メーカー: 学研プラス
- 発売日: 2019/03/05
- メディア: Kindle版
jupyter notebookを使って機械学習のモデルを作成したい [データサイエンス、統計モデル]
ようやく、jupyter notebookで機械学習をするための環境が整いました。
初めてのPython入門みたいな書物は多いですが、入門すぎて読んでも使えなかった。
いくつか、つまずいたポイントを備忘録としてメモ。
1. データの準備
練習用のお試しだと、ローカルのcsvファイルを読み込んで、それを分析してという流れになりますが、企業のデータは、csvファイルを使っているわけではない。
おそらく、多くのデータは、データベース(google big queryなど)に入っています。
そこで、データベースから、ローカルマシンにデータを持ってくる必要があるのですが、セキュリティ認証の設定とか、そもそものPythonコードの書き方をどうするの?問題がありました。
2. ディレクトリの構成
sqlをPythonの中にベタ書きするのではなく、sqlなどのフォルダを作ってそこに書いておく。
そして、Pythonからクエリを読み込み、実行してデータを取得する、という自然な流れなのですが、ここも、少々面倒くさい。
MacにBigQueryAPIクライアントライブラリをインストール その4 pandas-gbqをインストールする
https://skellington.blog.ss-blog.jp/2021-01-28
↑
query_1 = read_query('/sqls/test.sql')
read_queryでsqlを変数に取り込んで、
data_frame = pd.read_gbq(query_1, PROJECT_ID)
read_gbqで実行する。
3. クラス定数の設定とか、初期化スクリプトの実行とか
このあたりの設定は、慣れると簡単ですが、最初は、何をどう設定すれば良いのか、???状態でした。w
初めてのPython入門みたいな書物は多いですが、入門すぎて読んでも使えなかった。
いくつか、つまずいたポイントを備忘録としてメモ。
1. データの準備
練習用のお試しだと、ローカルのcsvファイルを読み込んで、それを分析してという流れになりますが、企業のデータは、csvファイルを使っているわけではない。
おそらく、多くのデータは、データベース(google big queryなど)に入っています。
そこで、データベースから、ローカルマシンにデータを持ってくる必要があるのですが、セキュリティ認証の設定とか、そもそものPythonコードの書き方をどうするの?問題がありました。
2. ディレクトリの構成
sqlをPythonの中にベタ書きするのではなく、sqlなどのフォルダを作ってそこに書いておく。
そして、Pythonからクエリを読み込み、実行してデータを取得する、という自然な流れなのですが、ここも、少々面倒くさい。
MacにBigQueryAPIクライアントライブラリをインストール その4 pandas-gbqをインストールする
https://skellington.blog.ss-blog.jp/2021-01-28
↑
query_1 = read_query('/sqls/test.sql')
read_queryでsqlを変数に取り込んで、
data_frame = pd.read_gbq(query_1, PROJECT_ID)
read_gbqで実行する。
3. クラス定数の設定とか、初期化スクリプトの実行とか
このあたりの設定は、慣れると簡単ですが、最初は、何をどう設定すれば良いのか、???状態でした。w
階層ベイズモデルの切片項の扱い [データサイエンス、統計モデル]
今、下記の様なモデルを考えたとします。
[観測モデル]
y=bo+b1*x1+b2*x2+b3*x3+b4*x4+ε
[階層モデル]
b0=a0+a1*z1+a2*z2+a3*z3+ε
b1=a0+a1*z1+a2*z2+a3*z3+ε
b2=a0+a1*z1+a2*z2+a3*z3+ε
b3=a0+a1*z1+a2*z2+a3*z3+ε
b4=a0+a1*z1+a2*z2+a3*z3+ε
ここで、zは、仮に血液型として、
z1:O型
z2:A型
z3:B型
z4:AB型
とします。
当初、観測モデルにも観測モデルにも切片項を入れていましたが、微妙にしっくりこない結果となります。
どうやら、両方に切片項が入っているとうまく収束しない問題があるらしい。
そこで、切片項は片方だけに入れるモデルに修正して、代わりに、z4を入れるモデルに変更しました。
通常は、観測部分に切片項を入れて、階層部分は入れない。
[観測モデル]
y=bo+b1*x1+b2*x2+b3*x3+b4*x4+ε
[階層モデル]
階層モデル
b0=a1*z1+a2*z2+a3*z3+a4*z4+ε
b1=a1*z1+a2*z2+a3*z3+a4*z4+ε
b2=a1*z1+a2*z2+a3*z3+a4*z4+ε
b3=a1*z1+a2*z2+a3*z3+a4*z4+ε
b4=a1*z1+a2*z2+a3*z3+a4*z4+ε
↑
こちらの修正したモデルの方が、感覚的にしっくりくるパラメータ推定となっていました。
[観測モデル]
y=bo+b1*x1+b2*x2+b3*x3+b4*x4+ε
[階層モデル]
b0=a0+a1*z1+a2*z2+a3*z3+ε
b1=a0+a1*z1+a2*z2+a3*z3+ε
b2=a0+a1*z1+a2*z2+a3*z3+ε
b3=a0+a1*z1+a2*z2+a3*z3+ε
b4=a0+a1*z1+a2*z2+a3*z3+ε
ここで、zは、仮に血液型として、
z1:O型
z2:A型
z3:B型
z4:AB型
とします。
当初、観測モデルにも観測モデルにも切片項を入れていましたが、微妙にしっくりこない結果となります。
どうやら、両方に切片項が入っているとうまく収束しない問題があるらしい。
そこで、切片項は片方だけに入れるモデルに修正して、代わりに、z4を入れるモデルに変更しました。
通常は、観測部分に切片項を入れて、階層部分は入れない。
[観測モデル]
y=bo+b1*x1+b2*x2+b3*x3+b4*x4+ε
[階層モデル]
階層モデル
b0=a1*z1+a2*z2+a3*z3+a4*z4+ε
b1=a1*z1+a2*z2+a3*z3+a4*z4+ε
b2=a1*z1+a2*z2+a3*z3+a4*z4+ε
b3=a1*z1+a2*z2+a3*z3+a4*z4+ε
b4=a1*z1+a2*z2+a3*z3+a4*z4+ε
↑
こちらの修正したモデルの方が、感覚的にしっくりくるパラメータ推定となっていました。
bayesmを使った階層ベイズモデル(線形回帰) [データサイエンス、統計モデル]
通常の重回帰分析を階層ベイズモデルに拡張するには、Rのbayesmを使うのが簡単です。
bayesmは、いろいろな階層モデルが用意されていますが、重回帰分析のモデルは
rhierLinearModel
となります。
MCMCの計算自体はとても簡単です。
階層モデルのパラメータDelta.meanと観測モデルのパラメータbeta.meanの行列計算が間違えるポイントかもしれません。
パラメータが2次元の行列なのと、さらに、MCMCごとのデータがあるので、3次元の構造となっています。
どこの軸を集計すると、良いのか、慣れるまで時間がかかるかもしれません。
[観測モデル]
y=bo+b1*x1+b2*x2+b3*x3+ε
[階層モデル]
b0=a1*z1+a2*z2+ε
b1=a1*z1+a2*z2+ε
b2=a1*z1+a2*z2+ε
簡単な使い方の例
library(bayesm)
R=20000
# 個人数
nreg <- length(member_id) # num of id
# Zは、階層モデル用のデータ
nz <- ncol(Z) # カラム数
# 観測モデル用のデータ
regdata=NULL
for (reg in 1:nreg) {
regdata[[reg]] <- list(y=y, X=X)
}
# MCMC
Data1 = list(regdata=regdata, Z=Z)
Mcmc1 = list(R=R, keep=1)
Mcmc_out = rhierLinearModel(Data=Data1, Mcmc=Mcmc1)
# Burn-In の設定
mcmc_start <- R/2
mcmc_end <- R
# パラメータの事後平均のデビアンス
for(j in 1:nvar_para){
for(i in 1:nreg){beta.mean[i,j] <- mean(Mcmc_out$betadraw[i, j, (mcmc_start:mcmc_end)])}
}
## 階層モデルのパラメータ
Delta.mean <- matrix(0, nz, nvar_para)
for(j in 1:nvar_para) {
for(i in 1:nz) {
Delta.mean[i,j] <- mean(Mcmc_out$Deltadraw[(mcmc_start:mcmc_end), i+(j-1)*nz])
}
}
Delta.mean
bayesmは、いろいろな階層モデルが用意されていますが、重回帰分析のモデルは
rhierLinearModel
となります。
MCMCの計算自体はとても簡単です。
階層モデルのパラメータDelta.meanと観測モデルのパラメータbeta.meanの行列計算が間違えるポイントかもしれません。
パラメータが2次元の行列なのと、さらに、MCMCごとのデータがあるので、3次元の構造となっています。
どこの軸を集計すると、良いのか、慣れるまで時間がかかるかもしれません。
[観測モデル]
y=bo+b1*x1+b2*x2+b3*x3+ε
[階層モデル]
b0=a1*z1+a2*z2+ε
b1=a1*z1+a2*z2+ε
b2=a1*z1+a2*z2+ε
簡単な使い方の例
library(bayesm)
R=20000
# 個人数
nreg <- length(member_id) # num of id
# Zは、階層モデル用のデータ
nz <- ncol(Z) # カラム数
# 観測モデル用のデータ
regdata=NULL
for (reg in 1:nreg) {
regdata[[reg]] <- list(y=y, X=X)
}
# MCMC
Data1 = list(regdata=regdata, Z=Z)
Mcmc1 = list(R=R, keep=1)
Mcmc_out = rhierLinearModel(Data=Data1, Mcmc=Mcmc1)
# Burn-In の設定
mcmc_start <- R/2
mcmc_end <- R
# パラメータの事後平均のデビアンス
for(j in 1:nvar_para){
for(i in 1:nreg){beta.mean[i,j] <- mean(Mcmc_out$betadraw[i, j, (mcmc_start:mcmc_end)])}
}
## 階層モデルのパラメータ
Delta.mean <- matrix(0, nz, nvar_para)
for(j in 1:nvar_para) {
for(i in 1:nz) {
Delta.mean[i,j] <- mean(Mcmc_out$Deltadraw[(mcmc_start:mcmc_end), i+(j-1)*nz])
}
}
Delta.mean
学生なら無料で使えるSASの統計ソフト [データサイエンス、統計モデル]
「sas university edition」で検索すると、学生なら無料で使えるSASのページが出てきます。
Free Statistical Software, SAS University Edition
https://www.sas.com/ja_jp/software/university-edition.html
一昔前は、SPSSが積極的に学生をターゲットに格安(無料?)でソフトウェアを提供していたイメージがありましたが、SASも無料で使えるっぽいです。
自分も学生なので、使ってみたい気持ちも山々ですが、今は、ちょっと忙しいので、落ち着いたらチャレンジしてみたいです。
今年、自分のスキルで伸ばしたい部分としては、Python、英語力、また、論文を書きたい。
Free Statistical Software, SAS University Edition
https://www.sas.com/ja_jp/software/university-edition.html
一昔前は、SPSSが積極的に学生をターゲットに格安(無料?)でソフトウェアを提供していたイメージがありましたが、SASも無料で使えるっぽいです。
自分も学生なので、使ってみたい気持ちも山々ですが、今は、ちょっと忙しいので、落ち着いたらチャレンジしてみたいです。
今年、自分のスキルで伸ばしたい部分としては、Python、英語力、また、論文を書きたい。
【R】エラー:is not writable Warning in install.packages [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
libraryをインストールする時に、この様なエラーがでました。
どうすれば良いでしょうか?
'lib = "C:/Program Files/R/R-4.0.3/library"' is not writable Warning in install.packages :
【回答】
上記の情報から分かるのが、Windowsユーザということです。
また、書き込み権限がないので、バッケージのインストールができない、という警告になっています。
これは、R、もしくは、RStudioが一般ユーザとして動いており、管理者権限がない場合、パッケージをインストールするフォルダに書き込み権限がないというのが原因です。
回避方法として、一般ユーザではなく、管理者として、起動すれば解決できます。
R、もしくは、RStudioのアイコンを右クリックしてプロパティを開き、互換性タブの管理者として実行、にチェックをつけておくと良いです。
Rの場所ですが、Windows 64ビットマシンでインストールしている場合、多くの場合は下記にあります。
C:/Program Files/R/R-4.0.3/bin/x64/rgui.exe
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
libraryをインストールする時に、この様なエラーがでました。
どうすれば良いでしょうか?
'lib = "C:/Program Files/R/R-4.0.3/library"' is not writable Warning in install.packages :
【回答】
上記の情報から分かるのが、Windowsユーザということです。
また、書き込み権限がないので、バッケージのインストールができない、という警告になっています。
これは、R、もしくは、RStudioが一般ユーザとして動いており、管理者権限がない場合、パッケージをインストールするフォルダに書き込み権限がないというのが原因です。
回避方法として、一般ユーザではなく、管理者として、起動すれば解決できます。
R、もしくは、RStudioのアイコンを右クリックしてプロパティを開き、互換性タブの管理者として実行、にチェックをつけておくと良いです。
Rの場所ですが、Windows 64ビットマシンでインストールしている場合、多くの場合は下記にあります。
C:/Program Files/R/R-4.0.3/bin/x64/rgui.exe
MacにBigQueryAPIクライアントライブラリをインストール その4 pandas-gbqをインストールする [データサイエンス、統計モデル]
Colaboratory を使用するのではなく、ローカルPCにjupyter notebookを入れてBigQueryと連携しました。
pandas-gbqが入っているか確認。
pandas-gbqの表示が出てこないので、pandas-gbqをインストールする必要があります。
今度はpandas-gbqがインストールされていることが確認できました。
後は、テーブルを読み込むだけです。
pandas-gbqが入っているか確認。
$ pip list --format=columns | grep -i pandas
pandas 1.1.3
pandas-gbqの表示が出てこないので、pandas-gbqをインストールする必要があります。
# インストール
$ pip install pandas-gbq -U
# 確認
$ pip list --format=columns | grep -i pandas
pandas 1.1.3
pandas-gbq 0.14.1
今度はpandas-gbqがインストールされていることが確認できました。
後は、テーブルを読み込むだけです。
# pandasをインポート
import pandas as pd
data_frame = pd.read_gbq(query, 'project-id')
パス解析というマジックワード [データサイエンス、統計モデル]
【質問】
パス解析をする際に、1,0のバイナリデータを使っても問題ないでしょうか?
【回答】
説明変数に1,0のバイナリデータ(二項データ)がある場合は、特に問題なりませんが、目的変数部分にバイナリデータがあると統計的にはまずい。
通常、目的変数が正規分布しているときは、線形回帰分析を使います。
目的変数が、1,0のバイナリデータ(二項データ)の場合は、ロジスティック回帰分析を使います。
というのは、1,0のバイナリデータの場合、yの値が負の値をとったり、1超の値をとったりすることはないから。
おそらくこの部分で間違える人はいないのですが、パス解析という、なんだかなんでもよしなにやってくれそうな手法になると、このあたりのことを忘れてしまう人がいる様です。
パス解析は、複数の回帰モデルを同時に最尤推定するというものなので、個々に見れば、回帰分析をしていることがわかるかと思います。
では、実際には、目的変数が1,0のバイナリデータである場合、どうすれば良いか?
(1) そのままパス解析をする
(2) 同時推定ではなく、個々に回帰モデル(線形回帰やロジスティック回帰)を適用する
(3) 同時推定する尤度関数を書いて、それを最適化する
が考えられます。
(1)は、分析ソフトを使えば、それっぽい結果は出てくるものの、統計的にはNG。
(2)実践的には、こちらでOKっぽい。
(3)尤度関数を書ける人は、こちらで最尤推定するのがベスト。
ということで、まとめると
(1) <<< (2) < (3)
となります。
〜追記〜
MPLUSというソフトは、二値データの共分散構造分析(SEM)にも対応しているので、お金がある人は、"(4) MPLUSを買う" という選択肢もありです。
パス解析をする際に、1,0のバイナリデータを使っても問題ないでしょうか?
【回答】
説明変数に1,0のバイナリデータ(二項データ)がある場合は、特に問題なりませんが、目的変数部分にバイナリデータがあると統計的にはまずい。
通常、目的変数が正規分布しているときは、線形回帰分析を使います。
目的変数が、1,0のバイナリデータ(二項データ)の場合は、ロジスティック回帰分析を使います。
というのは、1,0のバイナリデータの場合、yの値が負の値をとったり、1超の値をとったりすることはないから。
おそらくこの部分で間違える人はいないのですが、パス解析という、なんだかなんでもよしなにやってくれそうな手法になると、このあたりのことを忘れてしまう人がいる様です。
パス解析は、複数の回帰モデルを同時に最尤推定するというものなので、個々に見れば、回帰分析をしていることがわかるかと思います。
では、実際には、目的変数が1,0のバイナリデータである場合、どうすれば良いか?
(1) そのままパス解析をする
(2) 同時推定ではなく、個々に回帰モデル(線形回帰やロジスティック回帰)を適用する
(3) 同時推定する尤度関数を書いて、それを最適化する
が考えられます。
(1)は、分析ソフトを使えば、それっぽい結果は出てくるものの、統計的にはNG。
(2)実践的には、こちらでOKっぽい。
(3)尤度関数を書ける人は、こちらで最尤推定するのがベスト。
ということで、まとめると
(1) <<< (2) < (3)
となります。
〜追記〜
MPLUSというソフトは、二値データの共分散構造分析(SEM)にも対応しているので、お金がある人は、"(4) MPLUSを買う" という選択肢もありです。
推論の誤差幅 [データサイエンス、統計モデル]
ビジネススキルの高い課題解決型データサイエンス人材の育成
https://techplay.jp/event/805013
こちらのイベントに参加してきました。
アスクルのデータを使ったデータ解析コンペみたいなものです。
2チームだけの発表でしたが、どちらのチームも時間がない中で、最大限のアウトプットが出せていた様に感じます。
樋口先生のコメントを聞いていて感じたのは、
「何かを予測する時に点推定するのではなく、幅を持って推定する」
実際に、事業の中で分析をしていても、MLを使ったり、単に集計したりで点推定しか出てこない場合があるのですが、マーケティングの人が使う場面において、少なくともこれくらい効果がありそう、あるいは、コストは上ぶれてもこれくらいだろう、といった指標があると助かります。
この辺りの幅を持った統計量は、統計モデル(ベイズモデル)ならではのアプローチかと思います。
https://techplay.jp/event/805013
こちらのイベントに参加してきました。
アスクルのデータを使ったデータ解析コンペみたいなものです。
2チームだけの発表でしたが、どちらのチームも時間がない中で、最大限のアウトプットが出せていた様に感じます。
樋口先生のコメントを聞いていて感じたのは、
「何かを予測する時に点推定するのではなく、幅を持って推定する」
実際に、事業の中で分析をしていても、MLを使ったり、単に集計したりで点推定しか出てこない場合があるのですが、マーケティングの人が使う場面において、少なくともこれくらい効果がありそう、あるいは、コストは上ぶれてもこれくらいだろう、といった指標があると助かります。
この辺りの幅を持った統計量は、統計モデル(ベイズモデル)ならではのアプローチかと思います。
MacにBigQueryAPIクライアントライブラリをインストール その3 PythonのBigQuery連携ライブラリを使う [データサイエンス、統計モデル]
Colaboratoryの準備ができたら、後は、BigQueryからデータを持ってきて分析するだけですが、これも簡単にもってこれます。
query = """
select
id
, date(created , 'Asia/Tokyo') as created_date
, price
from `*****.*****`
where date(created , 'Asia/Tokyo') between '2021-01-01' and '2021-01-07'
;
"""
import pandas as pd
data_frame = pd.read_gbq(query, 'project-id')
↑
このようにクエリを書いて、pd.read_gbqすると、Googleの認証画面が出てくるので、そこで認証が完了するとBigQueryからデータを持ってこれました。
簡単に始めるならこの方法が楽ですね。
query = """
select
id
, date(created , 'Asia/Tokyo') as created_date
, price
from `*****.*****`
where date(created , 'Asia/Tokyo') between '2021-01-01' and '2021-01-07'
;
"""
import pandas as pd
data_frame = pd.read_gbq(query, 'project-id')
↑
このようにクエリを書いて、pd.read_gbqすると、Googleの認証画面が出てくるので、そこで認証が完了するとBigQueryからデータを持ってこれました。
簡単に始めるならこの方法が楽ですね。
MacにBigQueryAPIクライアントライブラリをインストール 〜その2 Pythonの環境構築 [データサイエンス、統計モデル]
すぐにPythonを触ってみたいという場合は、Colaboratory(略称:Colab)がおすすめ。
Colaboratory へようこそ
https://colab.research.google.com/notebooks/intro.ipynb
Google Drive内に .ipynb という拡張子でColabノートブックが作成できます。
例えば、
seconds_in_a_day = 24 * 60 * 60
seconds_in_a_day
と打つと、計算実行してくれます。
Macの場合は、↑(Shift)+Enterで実行となります。
Googleスプレッドシートと同じ感覚で、変更がリアルタイムに伝わるので、同じnotebookを2台の端末でみるとペアプログラミングできます。
これはかなり便利!
Colaboratory へようこそ
https://colab.research.google.com/notebooks/intro.ipynb
Google Drive内に .ipynb という拡張子でColabノートブックが作成できます。
例えば、
seconds_in_a_day = 24 * 60 * 60
seconds_in_a_day
と打つと、計算実行してくれます。
Macの場合は、↑(Shift)+Enterで実行となります。
Googleスプレッドシートと同じ感覚で、変更がリアルタイムに伝わるので、同じnotebookを2台の端末でみるとペアプログラミングできます。
これはかなり便利!
MacにBigQueryAPIクライアントライブラリをインストール 〜その1pipのインストール [データサイエンス、統計モデル]
最初でつまづいたところ。
「zsh: command not found: pip」が出てきてしまった。
macにpipをインストールする方法
$ sudo easy_install pip
↑
こちらでインストールが完了。
きちんとインストールされているかの確認
$ which pip
/usr/local/bin/pip
無事にインストールできていました。
「zsh: command not found: pip」が出てきてしまった。
macにpipをインストールする方法
$ sudo easy_install pip
↑
こちらでインストールが完了。
きちんとインストールされているかの確認
$ which pip
/usr/local/bin/pip
無事にインストールできていました。
【R】ロジスティック回帰をした後の混同行列の出し方 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
ロジスティック回帰をした後、確率(予測)は出せるのですが、混同行列の出し方がわかりません。
【回答】
# ロジスティック回帰モデルを作成
# model.1 <- glm(y ~ x1 + x2, data=dat)
# 予測確率
glm_predict <- predict(model.1, type = "response")
ここまでは、簡単に出せるかと思います。
type = "response"
のオプションは忘れがちなので注意が必要です。
z = b0 + b1*x1 + b2 *x2 + … + bn*xn + ε
y = 1/(1+exp(-z))
とした時に、
predict(model.1, type = "response")
は、y(確率)を計算します。
predict(model.1)
は、zの値となります。
# 予測確率を予測値に変換(確率を0,1に変換)
predict_result <- as.numeric(glm_predict >= 0.5)
# 混同行列
# y: 実際の値
# predict_result: 予測値
xtabs(~y+predict_result, data=dat)
↑
こちらを使うことで、混同行列を計算することができます。
閾値として、0.5を設定しており、0.5以上だと1と予測し、0.5未満だと0と予測します。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
ロジスティック回帰をした後、確率(予測)は出せるのですが、混同行列の出し方がわかりません。
【回答】
# ロジスティック回帰モデルを作成
# model.1 <- glm(y ~ x1 + x2, data=dat)
# 予測確率
glm_predict <- predict(model.1, type = "response")
ここまでは、簡単に出せるかと思います。
type = "response"
のオプションは忘れがちなので注意が必要です。
z = b0 + b1*x1 + b2 *x2 + … + bn*xn + ε
y = 1/(1+exp(-z))
とした時に、
predict(model.1, type = "response")
は、y(確率)を計算します。
predict(model.1)
は、zの値となります。
# 予測確率を予測値に変換(確率を0,1に変換)
predict_result <- as.numeric(glm_predict >= 0.5)
# 混同行列
# y: 実際の値
# predict_result: 予測値
xtabs(~y+predict_result, data=dat)
↑
こちらを使うことで、混同行列を計算することができます。
閾値として、0.5を設定しており、0.5以上だと1と予測し、0.5未満だと0と予測します。
日本行動計量学会、状態空間モデルの講義 [データサイエンス、統計モデル]
日本行動計量学会、状態空間モデルの講義
第23回春の合宿セミナー
http://www.mayomi.org/bsj/spring23.html
時系列関連のセミナーはよく見かけますが、状態空間モデルを2日間というのはなかなか見ない。
コロナの影響でこのセミナーもオンラインで開催。
土日なので、ちょっと微妙なのですが、自分最近、状態空間モデルを使ったモデリングをする様になったので、参加したいと思います。
第23回春の合宿セミナー
http://www.mayomi.org/bsj/spring23.html
時系列関連のセミナーはよく見かけますが、状態空間モデルを2日間というのはなかなか見ない。
コロナの影響でこのセミナーもオンラインで開催。
土日なので、ちょっと微妙なのですが、自分最近、状態空間モデルを使ったモデリングをする様になったので、参加したいと思います。
ビジネススキルの高い課題解決型データサイエンス人材の育成 [データサイエンス、統計モデル]
ビジネススキルの高い課題解決型データサイエンス人材の育成
https://techplay.jp/event/805013
アスクルのデータを使ったコンテストが行われ、その発表会があるみたいです。
申し込んだ時点で、若干、席に余裕がありました。
オンラインでやってくれるのはありがたいですね。
https://techplay.jp/event/805013
アスクルのデータを使ったコンテストが行われ、その発表会があるみたいです。
申し込んだ時点で、若干、席に余裕がありました。
オンラインでやってくれるのはありがたいですね。
統計学Ⅲ:多変量データ解析法 [データサイエンス、統計モデル]
統計学Ⅲ:多変量データ解析法
https://lms.gacco.org/courses/course-v1:gacco+ga082+2021_01/about
統計検定2級程度の知識が学習できる講座(しかも無料)です。
対面授業ではないので、質疑応答ができないなどあるのですが、無料でここまで学習できるというのは良いかと思います。
各学習の最後に用意されているテストは、なかなか良い問題。
本当にわかっていないと解けない問題なので、そのあたりにいるデータサイエンティストっぽい人だと間違えると思います。
しっかりと基礎をつけたいと言う人向けの講座ですね。
https://lms.gacco.org/courses/course-v1:gacco+ga082+2021_01/about
統計検定2級程度の知識が学習できる講座(しかも無料)です。
対面授業ではないので、質疑応答ができないなどあるのですが、無料でここまで学習できるというのは良いかと思います。
各学習の最後に用意されているテストは、なかなか良い問題。
本当にわかっていないと解けない問題なので、そのあたりにいるデータサイエンティストっぽい人だと間違えると思います。
しっかりと基礎をつけたいと言う人向けの講座ですね。
年収が高いプログラミング言語はR? [データサイエンス、統計モデル]
2020年のプログラミング言語/年代別平均年収、20~40代で「R」がもっとも高い傾向に
https://codezine.jp/article/detail/13428
この表を見て、「R」が使える様になると年収が上がるか?といえば、おそらくそうではない。
因果が逆で、データサイエンス系の人が使っている言語が「R」や「Python」で年収が高いのが正解だと思います。
ただ、「R」と「Python」を比較すると「R」がやや高い。
その理由として、
・「R」を使っている人が少ないので、誤差の可能性がある
・最近、MLといえば、Pythonなので、Pythonを使う人が爆増している
(年収が低い人が増えている)
気がします。
いずれにしても、まだまだデータサイエンスの人材って不足しているので、高単価の傾向は続きそうですね。
https://codezine.jp/article/detail/13428
この表を見て、「R」が使える様になると年収が上がるか?といえば、おそらくそうではない。
因果が逆で、データサイエンス系の人が使っている言語が「R」や「Python」で年収が高いのが正解だと思います。
ただ、「R」と「Python」を比較すると「R」がやや高い。
その理由として、
・「R」を使っている人が少ないので、誤差の可能性がある
・最近、MLといえば、Pythonなので、Pythonを使う人が爆増している
(年収が低い人が増えている)
気がします。
いずれにしても、まだまだデータサイエンスの人材って不足しているので、高単価の傾向は続きそうですね。
R Studioを複数画面で起動する方法 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
RStudioでは複数のRスクリプトを実行したいです。
Working Directoryが違ったり、オブジェクトが複数になり大変です。
どうすれば良いでしょうか?
【回答】
RStudioのソフトを複数起動すれば解決できます。
MACの場合
1.ターミナルを起動する
2.以下のコマンドを打つ
open -n /Applications/RStudio.app
RStudioが複数起動できるので、並行して作業できるかと思います。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
RStudioでは複数のRスクリプトを実行したいです。
Working Directoryが違ったり、オブジェクトが複数になり大変です。
どうすれば良いでしょうか?
【回答】
RStudioのソフトを複数起動すれば解決できます。
MACの場合
1.ターミナルを起動する
2.以下のコマンドを打つ
open -n /Applications/RStudio.app
RStudioが複数起動できるので、並行して作業できるかと思います。
t検定の自由度が整数にならない? [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales)
t検定の自由度は、20-1=19で19のはずですが、自由度が13.324となってしまいます。
【回答】
自由度ですが、
A.sales と B.sales ごとに平均値の縛りがあるため、
(10-1) + (10-1) = 18
が正しいです。
var.equal=T のオプションを付けて、t.test(A.sales, B.sales, var.equal=T) とするとdf=18となります。
var.equal=T
等分散を仮定している
→自由度は18
var.equal=F
等分散を仮定していない(ウェルチのt検定)
→自由度は13.324
Rはデフォルトで、Welchのt検定(ウェルチのt検定)となるので、
と自由度が13.324となっています。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales)
t検定の自由度は、20-1=19で19のはずですが、自由度が13.324となってしまいます。
【回答】
自由度ですが、
A.sales と B.sales ごとに平均値の縛りがあるため、
(10-1) + (10-1) = 18
が正しいです。
var.equal=T のオプションを付けて、t.test(A.sales, B.sales, var.equal=T) とするとdf=18となります。
var.equal=T
等分散を仮定している
→自由度は18
var.equal=F
等分散を仮定していない(ウェルチのt検定)
→自由度は13.324
Rはデフォルトで、Welchのt検定(ウェルチのt検定)となるので、
> t.test(A.sales, B.sales)
Welch Two Sample t-test
data: A.sales and B.sales
t = -2.2088, df = 13.324, p-value = 0.04528
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-781.368266 -9.631734
sample estimates:
mean of x mean of y
1171.5 1567.0
と自由度が13.324となっています。
分析者の落とし穴 [データサイエンス、統計モデル]
ここ最近感じていることを徒然なるままに。
例えば、ある精度が求められる分析プロジェクトがあったとします。
通常の(古典的な)方法だと、それなりに頑張った結果、精度が〇〇くらいとなりました。
データサイエンティスト(分析者)自身が、もっと精度が伸びるんじゃないかと思っていたり、事業側(依頼者側)がこの精度だと使えないのでもう少し精度が欲しいと依頼する場合もあったりします。
予測精度はある種のゲームみたいなもので、もっと別の手法を適用すれば精度が良くなるんじゃないか、もっと最新の手法を適用してみてはどうだろうという妄想に取りつかれてしまう。
実際に、上手く行く場合もあるが、個人的には劇的に精度が向上する場合はあまりなく、やたら計算時間がかかったり、その瞬間は精度が向上しても長期的に見るとむしろ悪化していたりするケースが多い。
そして、分析者はモデルが陳腐化したので別の新しいモデルにチャレンジしましょうとなる。
常に新しいモデルにチャレンジすることが正解ではなく、現状の限界を知ったうえで、どうしても高い精度を求めるのか、あるいはその限界を受け入れこれくらいの精度で何ができるのかを見直すというプロセスも必要だろう。
しかし、分析者はどうしても前者にチャレンジしがちであるが、冷静になって本当にやりたいことってなんだったっけと振り替えてみると意外と後者で解決するケースも多いと思う。
いかに難しいアルゴリズムを適用できるかがデータサイエンティストの能力ではなく、総合的に分析全体を設計できる能力が本来の企業によって大切なことだと思う今日この頃。
例えば、ある精度が求められる分析プロジェクトがあったとします。
通常の(古典的な)方法だと、それなりに頑張った結果、精度が〇〇くらいとなりました。
データサイエンティスト(分析者)自身が、もっと精度が伸びるんじゃないかと思っていたり、事業側(依頼者側)がこの精度だと使えないのでもう少し精度が欲しいと依頼する場合もあったりします。
予測精度はある種のゲームみたいなもので、もっと別の手法を適用すれば精度が良くなるんじゃないか、もっと最新の手法を適用してみてはどうだろうという妄想に取りつかれてしまう。
実際に、上手く行く場合もあるが、個人的には劇的に精度が向上する場合はあまりなく、やたら計算時間がかかったり、その瞬間は精度が向上しても長期的に見るとむしろ悪化していたりするケースが多い。
そして、分析者はモデルが陳腐化したので別の新しいモデルにチャレンジしましょうとなる。
常に新しいモデルにチャレンジすることが正解ではなく、現状の限界を知ったうえで、どうしても高い精度を求めるのか、あるいはその限界を受け入れこれくらいの精度で何ができるのかを見直すというプロセスも必要だろう。
しかし、分析者はどうしても前者にチャレンジしがちであるが、冷静になって本当にやりたいことってなんだったっけと振り替えてみると意外と後者で解決するケースも多いと思う。
いかに難しいアルゴリズムを適用できるかがデータサイエンティストの能力ではなく、総合的に分析全体を設計できる能力が本来の企業によって大切なことだと思う今日この頃。
RによるPCA(主成分分析) [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
prcomp(dat, scale=TRUE) と prcomp(dat, scale.=TRUE) の違いは何でしょうか?
【回答】
ピリオドありとなしの違いですが、英語のヘルプを見ても両方ありました。
ということで、
1. scale = FALSE と scale. = FALSE
2. scale = TRUE と scale. = TRUE
の結果を調べみましたが、どちらも同じ結果となっています。
ちなみに、scale = TRUEの意味ですが、cmとかmみたいに単位が揃っていない場合に、正規化(標準化)するという意味です。
単位が揃っている場合は、FALSEで良いのですが、揃っていない場合は、値が大きいものに引っ張られてしまいますので、TRUEにしておく必要があります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
prcomp(dat, scale=TRUE) と prcomp(dat, scale.=TRUE) の違いは何でしょうか?
【回答】
ピリオドありとなしの違いですが、英語のヘルプを見ても両方ありました。
ということで、
1. scale = FALSE と scale. = FALSE
2. scale = TRUE と scale. = TRUE
の結果を調べみましたが、どちらも同じ結果となっています。
ちなみに、scale = TRUEの意味ですが、cmとかmみたいに単位が揃っていない場合に、正規化(標準化)するという意味です。
単位が揃っている場合は、FALSEで良いのですが、揃っていない場合は、値が大きいものに引っ張られてしまいますので、TRUEにしておく必要があります。
r - 言語設定を変更する方法 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rで、日本語と英語を切り替えるにはどうすれば良いですか?
【回答】
確かに、エラー表示とかは、日本語じゃなくて英語でエラーを出してもらった方が何かと検索しやすいです。
インストールしたときに、日本語になっている場合は、コンソールに下記のコマンドを打ち込むと英語表記になります。
Sys.setenv(LANG = "en")
> a
エラー: オブジェクト 'a' がありません
> Sys.setenv(LANG = "en")
> a
Error: object 'a' not found
> Sys.setenv(LANG = "ja")
> a
エラー: オブジェクト 'a' がありません
> Sys.setenv(LANG = "fr")
> a
Erreur : objet 'a' introuvable
このように、フランス語にも変更できました。w
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rで、日本語と英語を切り替えるにはどうすれば良いですか?
【回答】
確かに、エラー表示とかは、日本語じゃなくて英語でエラーを出してもらった方が何かと検索しやすいです。
インストールしたときに、日本語になっている場合は、コンソールに下記のコマンドを打ち込むと英語表記になります。
Sys.setenv(LANG = "en")
> a
エラー: オブジェクト 'a' がありません
> Sys.setenv(LANG = "en")
> a
Error: object 'a' not found
> Sys.setenv(LANG = "ja")
> a
エラー: オブジェクト 'a' がありません
> Sys.setenv(LANG = "fr")
> a
Erreur : objet 'a' introuvable
このように、フランス語にも変更できました。w
【状態空間モデル】ローカルレベルモデル(stan) [データサイエンス、統計モデル]
R stanを使ってローカルレベルモデルの話。
ローカルレベルモデルは、最もシンプルな(基本的な)モデル。
広告効果とかを入れる場合は、そういった変数を入れる必要があるのですが、今回は、シンプルに外部変数なしのバージョンです。
ローカルレベルの構造は、
状態モデル:x(t) = x(t-1) + sd_w(t)
観測モデル:y(t) = x(t) + sd_v(t)
で表されるモデル。
これを階層ベイズモデルの枠組みで解くことになるので、stanで実装すると、下記のようになります。
#### stanのmodel部分 ####
model {
for(i in 2:T) {
x[i] ~ normal(x[i-1], sd_w);
}
for(i in 1:T) {
y[i] ~ normal(x[i], sd_v);
}
}
########################
試しに、サンプルデータで実行すると、こんな感じ。
トレンドはなんとなくなぞっていますが、広告(CM)の効果とか無視されているのがわかるかと思います。
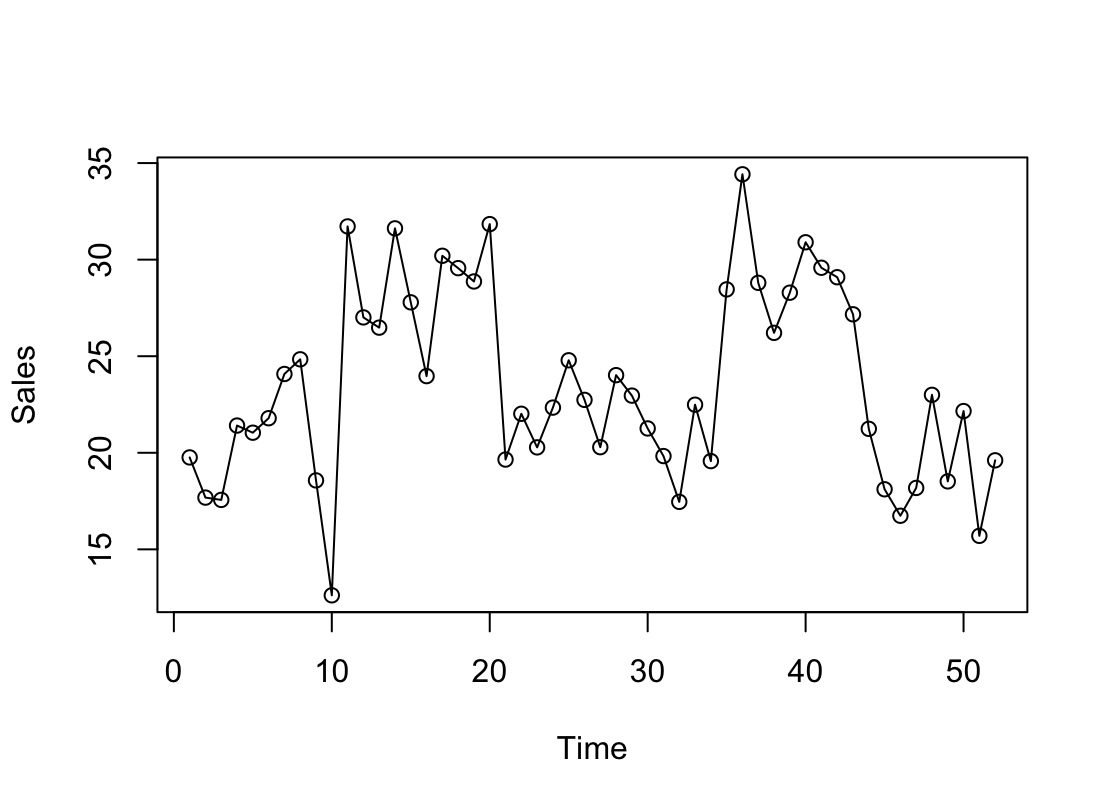
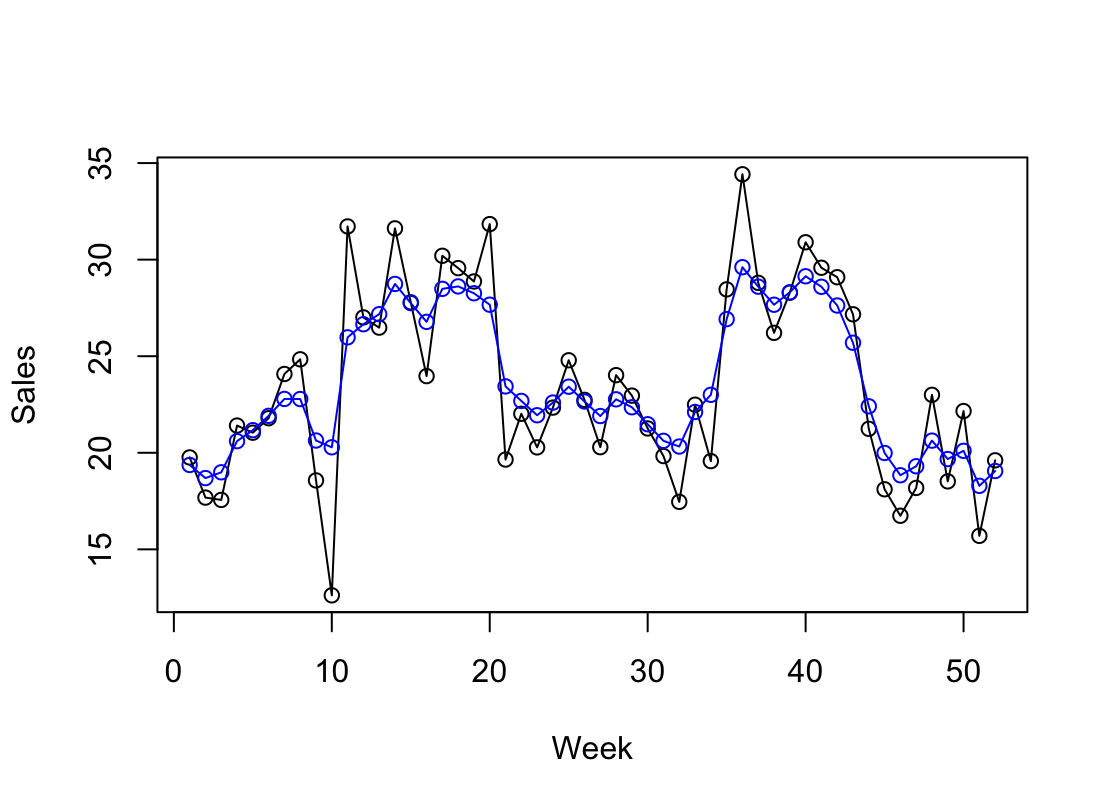
ローカルレベルモデルは、最もシンプルな(基本的な)モデル。
広告効果とかを入れる場合は、そういった変数を入れる必要があるのですが、今回は、シンプルに外部変数なしのバージョンです。
ローカルレベルの構造は、
状態モデル:x(t) = x(t-1) + sd_w(t)
観測モデル:y(t) = x(t) + sd_v(t)
で表されるモデル。
これを階層ベイズモデルの枠組みで解くことになるので、stanで実装すると、下記のようになります。
#### stanのmodel部分 ####
model {
for(i in 2:T) {
x[i] ~ normal(x[i-1], sd_w);
}
for(i in 1:T) {
y[i] ~ normal(x[i], sd_v);
}
}
########################
試しに、サンプルデータで実行すると、こんな感じ。
トレンドはなんとなくなぞっていますが、広告(CM)の効果とか無視されているのがわかるかと思います。
確率密度と確率の関係 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
正規分布の場合、x=0の確率密度は、0.3989となります。この確率密度は確率のことですか?
【回答】
確率密度は、連続型確率変数で使われる概念となります。
特定の値に対しての確率密度というのはあまり意味がなく、Xがa以上b以下となる確率は、〇〇となるという言い方をして、始めて意味が出てきます。
Xがa以上b以下となる確率を計算する際に、確率密度をaからbまで積分した値を求めるとそれが確率となります。
正規分布の場合は、-∞から0まで積分した値は、0.5(確率)となります。
Rで計算する場合、確率密度はdnorm、確率はpnormで計算できます。
(例)
x=0の確率密度は?
> dnorm(0)
[1] 0.3989423
xが-∞から0となる確率は?
> pnorm(0)
[1] 0.5
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
正規分布の場合、x=0の確率密度は、0.3989となります。この確率密度は確率のことですか?
【回答】
確率密度は、連続型確率変数で使われる概念となります。
特定の値に対しての確率密度というのはあまり意味がなく、Xがa以上b以下となる確率は、〇〇となるという言い方をして、始めて意味が出てきます。
Xがa以上b以下となる確率を計算する際に、確率密度をaからbまで積分した値を求めるとそれが確率となります。
正規分布の場合は、-∞から0まで積分した値は、0.5(確率)となります。
Rで計算する場合、確率密度はdnorm、確率はpnormで計算できます。
(例)
x=0の確率密度は?
> dnorm(0)
[1] 0.3989423
xが-∞から0となる確率は?
> pnorm(0)
[1] 0.5
Rで文字列を読み込むときの型変換について [データサイエンス、統計モデル]
Rのバージョンを新しくしたら、read.tableで読み込んだ型がバージョンによって違うことが起こっていました。
古いバージョンだと、文字列を自動的にfactor型にしていたようですが、最近のバージョンだと自動的にfactor型にしないようです。
この問題を回避するには、stringsAsFactorsを付ければよくて、
■ 文字列を自動的にfactor型にしない
実行結果
■ 文字列を自動的にfactor型にする
実行結果
ちなみに、chr型で読み込んでも、後からas.factorで変換できます。
wine_dat["colour"] <- as.factor(wine_dat$colour)
古いバージョンだと、文字列を自動的にfactor型にしていたようですが、最近のバージョンだと自動的にfactor型にしないようです。
この問題を回避するには、stringsAsFactorsを付ければよくて、
■ 文字列を自動的にfactor型にしない
wine_dat <- read.table(file=csvPATH1, header=T, sep=",", stringsAsFactors=F)
str(wine_dat)
実行結果
$ colour : chr "WHITE" "WHITE" "WHITE" "WHITE" ...
$ ROLE : chr "TRAIN" "TRAIN" "TRAIN" "TRAIN" ...
■ 文字列を自動的にfactor型にする
wine_dat <- read.table(file=csvPATH1, header=T, sep=",", stringsAsFactors=T)
str(wine_dat)
実行結果
$ colour : Factor w/ 2 levels "RED","WHITE": 2 2 2 2 2 2 2 2 2 2 ...
$ ROLE : Factor w/ 3 levels "TEST","TRAIN",..: 2 2 2 2 2 1 2 3 3 2 ...
ちなみに、chr型で読み込んでも、後からas.factorで変換できます。
wine_dat["colour"] <- as.factor(wine_dat$colour)
Rのアソシエーション分析で新しい項目が追加 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rのaprioriを実行したところ、coverageという項目がありますが、この計算方法は何ですか?
【回答】
自分のR(古いバージョン)だとcoverageという項目がなく、ちょっと焦りましたが・・・
これまで出力されていた指標
lhs, rhs, support, confidence, lift, count
support:支持度
confidence:確信度
lift:リフト
新たに、coverageが追加されています。
調べてみると、意外と簡単な計算でした。
A⇒Bのcoverageの計算方法は
P(A) = n(A) / N(全体の人数)
で計算できます。
例えば、「オムツを買う → ビールを買う」というルールを考える場合、
1000人中、オムツを買った人の人数を100人とすると、
N:1000
n(A)=100
よって、coverageは、100/1000=0.1となります。
ビールを買うという右側のルールは見ていないことに注意です。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rのaprioriを実行したところ、coverageという項目がありますが、この計算方法は何ですか?
【回答】
自分のR(古いバージョン)だとcoverageという項目がなく、ちょっと焦りましたが・・・
これまで出力されていた指標
lhs, rhs, support, confidence, lift, count
support:支持度
confidence:確信度
lift:リフト
新たに、coverageが追加されています。
調べてみると、意外と簡単な計算でした。
A⇒Bのcoverageの計算方法は
P(A) = n(A) / N(全体の人数)
で計算できます。
例えば、「オムツを買う → ビールを買う」というルールを考える場合、
1000人中、オムツを買った人の人数を100人とすると、
N:1000
n(A)=100
よって、coverageは、100/1000=0.1となります。
ビールを買うという右側のルールは見ていないことに注意です。
P値と信頼区間 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
検定をして、p値が0.05より小さい場合、AとBの信頼区間が重なるという意味で、0.05より大きい場合は、AとBの信頼区間が重ならないという意味でしょうか?
【回答】
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales)
> t.test(A.sales, B.sales)
Welch Two Sample t-test
data: A.sales and B.sales
t = -2.2088, df = 13.324, p-value = 0.04528
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-781.368266 -9.631734
sample estimates:
mean of x mean of y
1171.5 1567.0
↑「AとBの平均値は異なる」となります。
AとBの信頼区間を求めると
> t.test(A.sales) → 989円~1354円
> t.test(B.sales) → 1206円~1928円
となり信頼区間がかぶっています。
この意味ですが、Aの平均値は1171.5なので、分布の端っこである1354円付近になる確率は小さい。同様に、Aの平均値は1567.0なので、分布の端っこである1206円付近になる確率は小さい。小さい確率が同時に起こる可能性はかなり低い。
ということで、信頼区間が少し被っても、p値が0.05以下になるケースがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
検定をして、p値が0.05より小さい場合、AとBの信頼区間が重なるという意味で、0.05より大きい場合は、AとBの信頼区間が重ならないという意味でしょうか?
【回答】
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
t.test(A.sales, B.sales)
> t.test(A.sales, B.sales)
Welch Two Sample t-test
data: A.sales and B.sales
t = -2.2088, df = 13.324, p-value = 0.04528
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-781.368266 -9.631734
sample estimates:
mean of x mean of y
1171.5 1567.0
↑「AとBの平均値は異なる」となります。
AとBの信頼区間を求めると
> t.test(A.sales) → 989円~1354円
> t.test(B.sales) → 1206円~1928円
となり信頼区間がかぶっています。
この意味ですが、Aの平均値は1171.5なので、分布の端っこである1354円付近になる確率は小さい。同様に、Aの平均値は1567.0なので、分布の端っこである1206円付近になる確率は小さい。小さい確率が同時に起こる可能性はかなり低い。
ということで、信頼区間が少し被っても、p値が0.05以下になるケースがあります。
ウェルチのt検定 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
検定の多重性について。
t検定を行う前に、等分散性の検定を行ってから検定を行いますが、この手順も検定の多重性に当たるでしょうか?
【回答】
等分散性の検定 → t検定と2回検定をしているので、検定の多重性にあたります。
最近では、「最初からWelchのt検定をしましょう。」というのが一般的です。
Rでウェルチのt検定をする方法ですが、オプションでvar.equal=Fを付けるとウェルチのt検定となります。
t.test(group1, group2, var.equal=F)
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
検定の多重性について。
t検定を行う前に、等分散性の検定を行ってから検定を行いますが、この手順も検定の多重性に当たるでしょうか?
【回答】
等分散性の検定 → t検定と2回検定をしているので、検定の多重性にあたります。
最近では、「最初からWelchのt検定をしましょう。」というのが一般的です。
Rでウェルチのt検定をする方法ですが、オプションでvar.equal=Fを付けるとウェルチのt検定となります。
t.test(group1, group2, var.equal=F)
【R】e1071を使った潜在クラス分析(LCA)~ソフトクラスタリング [データサイエンス、統計モデル]
Rを使って潜在クラス分析(Latent Class Analysis)をしました。
潜在クラス分析は、ハードクラスタリングと言われているものとソフトクラスタリングと言われているものがあります。
今回は、Rのパッケージe1071を使ったソフトクラスタリングの方法について。
【使い方の例】
### 2次元データの例(クラス数は2) ###
# データの作成
x <- rbind(matrix(rnorm(100, sd=0.3), ncol=2),
matrix(rnorm(100, mean=1, sd=0.3), ncol=2))
# 潜在クラスの計算
cl <- cmeans(x, 2, 20, verbose=TRUE, method="cmeans", m=2)
print(cl)
# ソフトクラスタリングの結果
cl$membership[,]
# ハードクラスタリングの結果
cl$cluster
### 3次元データの例(クラス数は6) ###
x <- rbind(matrix(rnorm(150, sd=0.3), ncol=3),
matrix(rnorm(150,mean=1,sd=0.3),ncol=3),
matrix(rnorm(150,mean=2,sd=0.3),ncol=3))
# 潜在クラスの計算
cl <- cmeans(x, 6, 20, verbose=TRUE, method="cmeans")
print(cl)
# ソフトクラスタリングの結果
cl$membership[,]
# ハードクラスタリングの結果
cl$cluster
~ 参考記事 ~
【R】e1071を使った潜在クラス分析(LCA)~ハードクラスタリング
https://skellington.blog.ss-blog.jp/2020-09-02
潜在クラス分析は、ハードクラスタリングと言われているものとソフトクラスタリングと言われているものがあります。
今回は、Rのパッケージe1071を使ったソフトクラスタリングの方法について。
【使い方の例】
### 2次元データの例(クラス数は2) ###
# データの作成
x <- rbind(matrix(rnorm(100, sd=0.3), ncol=2),
matrix(rnorm(100, mean=1, sd=0.3), ncol=2))
# 潜在クラスの計算
cl <- cmeans(x, 2, 20, verbose=TRUE, method="cmeans", m=2)
print(cl)
# ソフトクラスタリングの結果
cl$membership[,]
# ハードクラスタリングの結果
cl$cluster
### 3次元データの例(クラス数は6) ###
x <- rbind(matrix(rnorm(150, sd=0.3), ncol=3),
matrix(rnorm(150,mean=1,sd=0.3),ncol=3),
matrix(rnorm(150,mean=2,sd=0.3),ncol=3))
# 潜在クラスの計算
cl <- cmeans(x, 6, 20, verbose=TRUE, method="cmeans")
print(cl)
# ソフトクラスタリングの結果
cl$membership[,]
# ハードクラスタリングの結果
cl$cluster
~ 参考記事 ~
【R】e1071を使った潜在クラス分析(LCA)~ハードクラスタリング
https://skellington.blog.ss-blog.jp/2020-09-02
【R】e1071を使った潜在クラス分析(LCA)~ハードクラスタリング [データサイエンス、統計モデル]
Rを使って潜在クラス分析(Latent Class Analysis)をしました。
潜在クラス分析は、ハードクラスタリングと言われているものとソフトクラスタリングと言われているものがあります。
ハードクラスタリングとソフトクラスタリングの違いですが、
ハードクラスタリング:各レコードが属しているクラスタは1つ。
ソフトクラスタリング:1,0で割り当てられるのではなく、確率で割り当てられる。
潜在クラス分析をする上でRでは色々なパッケージが用意されていますが、e1071を使った潜在クラス分析を行いたいと思います。
【オプション】
lca(x, k, niter=100, matchdata=FALSE, verbose=FALSE)
x:データ
k:LCAに使用されるクラスの数
niter:イテレーションの回数
matchdata:predict関数を使う場合はFALSE
verbose:イテレーションごとのアウトプットを出力
k(クラス数)はあらかじめ与える必要があるので注意が必要です。
潜在クラス分析のクラス数を決定する上でAICやBICが用いられますが、e1071ではBICしか計算されません。
【使い方の例】
# データの作成
# レコードの前半(1~500)は、type1に属しており、後半(501~1000)は、type2に属しています
type1 <- c(0.8, 0.8, 0.2, 0.2)
type2 <- c(0.2, 0.2, 0.8, 0.8)
x <- matrix(runif(4000), nr=1000)
x[1:500,] <- t(t(x[1:500,]) < type1) * 1
x[501:1000,] <- t(t(x[501:1000,]) < type2) * 1
# 潜在クラスの計算
l <- lca(x, 2, niter=5)
print(l)
summary(l)
p <- predict(l, x)
table(p, c(rep(1,500),rep(2,500)))
新しいデータに対する予測ですが、predict関数を使って予測することができます。
predict(l, x)
predict(作成した潜在クラスモデル, 予測したいデータ)
潜在クラス分析は、ハードクラスタリングと言われているものとソフトクラスタリングと言われているものがあります。
ハードクラスタリングとソフトクラスタリングの違いですが、
ハードクラスタリング:各レコードが属しているクラスタは1つ。
ソフトクラスタリング:1,0で割り当てられるのではなく、確率で割り当てられる。
潜在クラス分析をする上でRでは色々なパッケージが用意されていますが、e1071を使った潜在クラス分析を行いたいと思います。
【オプション】
lca(x, k, niter=100, matchdata=FALSE, verbose=FALSE)
x:データ
k:LCAに使用されるクラスの数
niter:イテレーションの回数
matchdata:predict関数を使う場合はFALSE
verbose:イテレーションごとのアウトプットを出力
k(クラス数)はあらかじめ与える必要があるので注意が必要です。
潜在クラス分析のクラス数を決定する上でAICやBICが用いられますが、e1071ではBICしか計算されません。
【使い方の例】
# データの作成
# レコードの前半(1~500)は、type1に属しており、後半(501~1000)は、type2に属しています
type1 <- c(0.8, 0.8, 0.2, 0.2)
type2 <- c(0.2, 0.2, 0.8, 0.8)
x <- matrix(runif(4000), nr=1000)
x[1:500,] <- t(t(x[1:500,]) < type1) * 1
x[501:1000,] <- t(t(x[501:1000,]) < type2) * 1
# 潜在クラスの計算
l <- lca(x, 2, niter=5)
print(l)
summary(l)
p <- predict(l, x)
table(p, c(rep(1,500),rep(2,500)))
新しいデータに対する予測ですが、predict関数を使って予測することができます。
predict(l, x)
predict(作成した潜在クラスモデル, 予測したいデータ)

