【R】forecastのエラー、could not find function "auto.arima" [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
install.packages("forecast")
library(forecast)
を実行しても、時系列のauto.arimaが使えません。
【回答】
他の関数と被っている可能性があります。
forecast::auto.arima()
とすることで、forecastのauto.arimaを使うことができます。
(例)
arima.fit <- auto.arima(
data_name,
ic="aic",
trace=TRUE, # 試したモデルの表示
# max.p = 3, #AR degree
# max.q = 3 # MA degree
stepwise=FALSE,
approximation=FALSE,
num.cores=4
)
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
install.packages("forecast")
library(forecast)
を実行しても、時系列のauto.arimaが使えません。
【回答】
他の関数と被っている可能性があります。
forecast::auto.arima()
とすることで、forecastのauto.arimaを使うことができます。
(例)
arima.fit <- auto.arima(
data_name,
ic="aic",
trace=TRUE, # 試したモデルの表示
# max.p = 3, #AR degree
# max.q = 3 # MA degree
stepwise=FALSE,
approximation=FALSE,
num.cores=4
)
【R】密度関数、分位点、分位点に対する値、乱数生成 [データサイエンス、統計モデル]
【質問】
密度関数、分位点、分位点に対する値、乱数生成の求め方がわかりません。
【回答】
# d: density => 確率密度
# p: probability => 下側確率の値に対する分位点
# q: quantile => 分位点に対する値
# r: random => 乱数生成
# d$dist p$dist q$dist r$dist
# $dist = norm, binom, unif...etc
pとqは表裏一体と覚えておくと良いと思います。
正規分布の場合は、normを使います。
なので、
# dnorm: 確率密度
# pnorm: 下側確率の値に対する分位点
# qnorm: 分位点に対する値
# rnorm: 乱数生成
となりますね。
密度関数、分位点、分位点に対する値、乱数生成の求め方がわかりません。
【回答】
# d: density => 確率密度
# p: probability => 下側確率の値に対する分位点
# q: quantile => 分位点に対する値
# r: random => 乱数生成
# d$dist p$dist q$dist r$dist
# $dist = norm, binom, unif...etc
pとqは表裏一体と覚えておくと良いと思います。
正規分布の場合は、normを使います。
なので、
# dnorm: 確率密度
# pnorm: 下側確率の値に対する分位点
# qnorm: 分位点に対する値
# rnorm: 乱数生成
となりますね。
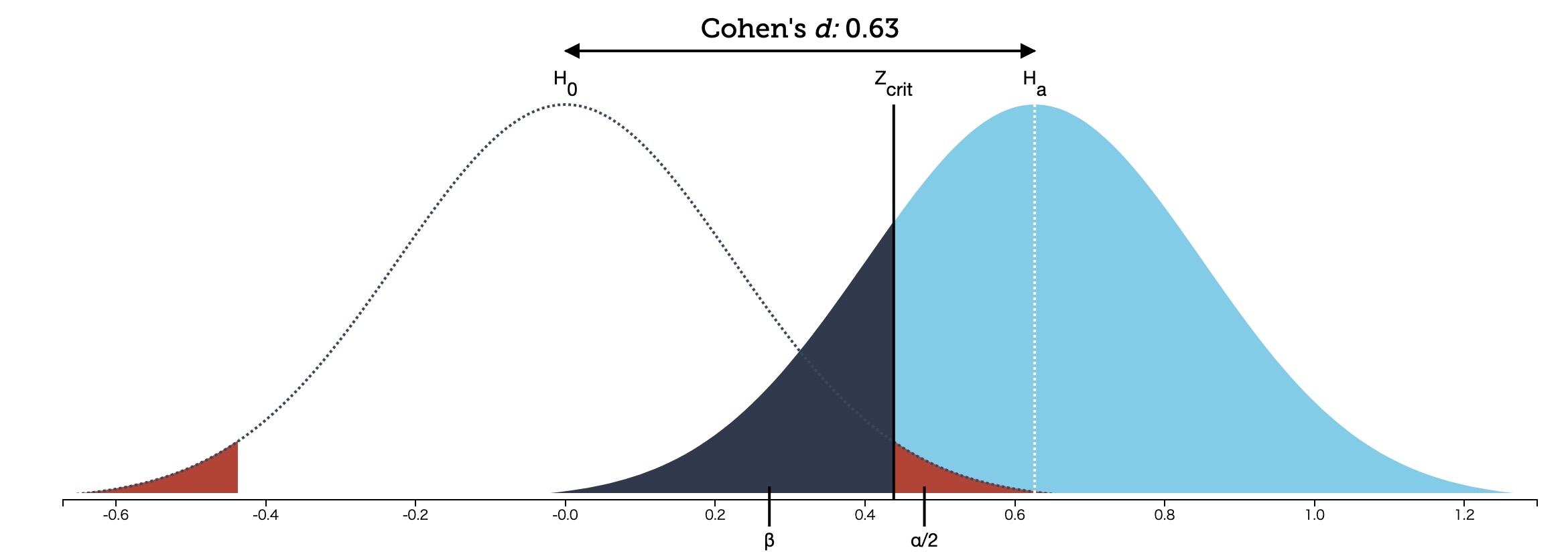
危険率(有意水準)αと検出力(1-β)を視覚的に理解する [データサイエンス、統計モデル]
概念(コンセプト)として分かっていても、実際の本質を理解していない人がほとんどだと思います。
ということで、確率の分布(面積)を使って理解するとどうなるか?
Understanding Statistical Power and Significance Testing
https://rpsychologist.com/d3/nhst/
ということで、確率の分布(面積)を使って理解するとどうなるか?
Understanding Statistical Power and Significance Testing
https://rpsychologist.com/d3/nhst/
[R]LightGBMを使った特徴量重要度の出し方 [データサイエンス、統計モデル]
pythonの資料は豊富に見つかるのですが、意外とRのLightGBMを使った方法が見つからなかったのでメモとして記載しておきます。
作成したモデル(モデル名:model)に対して、
lgb.importanceで重要度を計算してくれます
lgb.plot.importanceで重要度の可視化をしてくれます。
#モデリング
model <- lightgbm(data = dtrain,
nrounds = *****,
min_data_in_leaf = *****,
learning_rate = *****,
params = ***** );
#重要度の作成
tree_imp <- lgb.importance(model, percentage = TRUE)
#重要度の可視化
lgb.plot.importance(tree_imp, top_n = 5L, measure = "Gain")
作成したモデル(モデル名:model)に対して、
lgb.importanceで重要度を計算してくれます
lgb.plot.importanceで重要度の可視化をしてくれます。
#モデリング
model <- lightgbm(data = dtrain,
nrounds = *****,
min_data_in_leaf = *****,
learning_rate = *****,
params = ***** );
#重要度の作成
tree_imp <- lgb.importance(model, percentage = TRUE)
#重要度の可視化
lgb.plot.importance(tree_imp, top_n = 5L, measure = "Gain")
【R】select 使われていない引数 エラー [データサイエンス、統計モデル]
Rでパイプ演算子(pipe)を使っている時に起こったエラーです。
select( ) を使っていると、使われていない引数というエラーが出てきました。
iris %>>% select( )
または、iris %>% select( )
といった際に出てきました。
調べたところ、MASSの中にもselectというものがあるので、MASSライブラリーも呼び出していると関数名がバッティングしてエラーが起こっていたみたいです。
明示的に
dplyr::select
と書くことでエラーが解消されると思います。
select( ) を使っていると、使われていない引数というエラーが出てきました。
iris %>>% select( )
または、iris %>% select( )
といった際に出てきました。
調べたところ、MASSの中にもselectというものがあるので、MASSライブラリーも呼び出していると関数名がバッティングしてエラーが起こっていたみたいです。
明示的に
dplyr::select
と書くことでエラーが解消されると思います。
【R】をバッチ実行する方法 その2 引数を受ける方法 [データサイエンス、統計モデル]
【R】をバッチ実行する方法
https://skellington.blog.ss-blog.jp/2021-04-26
↑
こちらの続き
引数をつける場合は、
args <- commandArgs(trailingOnly = TRUE)
で引数を受けることができます。
例えば、引数によってモデルを分岐するやり方がこちら。
Rscript iris_predict.r 1 ← 1番目のモデルの結果を出力
Rscript iris_predict.r ← それ以外(2番目のモデルの結果を出力)
# irisを使った線形回帰モデル
model <- lm(Sepal.Length~., data=iris)
out <- predict(model)
model2 <- lm(Sepal.Length~Species, data=iris)
out2 <- predict(model2)
args <- commandArgs(trailingOnly = TRUE)
mode <- 0
if ( !is.na(args[1]) ) { mode <- as.integer(args[1]); }
if ( mode == 1 ) {
write.table(out, file = "/Users/rlsuu120061/Desktop/out.txt",
sep = ',', quote=F, row.names=F, col.names=F)
} else {
write.table(out2, file = "/Users/rlsuu120061/Desktop/out.txt",
sep = ',', quote=F, row.names=F, col.names=F)
}
https://skellington.blog.ss-blog.jp/2021-04-26
↑
こちらの続き
引数をつける場合は、
args <- commandArgs(trailingOnly = TRUE)
で引数を受けることができます。
例えば、引数によってモデルを分岐するやり方がこちら。
Rscript iris_predict.r 1 ← 1番目のモデルの結果を出力
Rscript iris_predict.r ← それ以外(2番目のモデルの結果を出力)
# irisを使った線形回帰モデル
model <- lm(Sepal.Length~., data=iris)
out <- predict(model)
model2 <- lm(Sepal.Length~Species, data=iris)
out2 <- predict(model2)
args <- commandArgs(trailingOnly = TRUE)
mode <- 0
if ( !is.na(args[1]) ) { mode <- as.integer(args[1]); }
if ( mode == 1 ) {
write.table(out, file = "/Users/rlsuu120061/Desktop/out.txt",
sep = ',', quote=F, row.names=F, col.names=F)
} else {
write.table(out2, file = "/Users/rlsuu120061/Desktop/out.txt",
sep = ',', quote=F, row.names=F, col.names=F)
}
【R】をバッチ実行する方法 [データサイエンス、統計モデル]
SPSS Modelerとかだと、バッチ実行するやり方はModeler Batchとか、CADSなどの方法があります。
Rでバッチ実行する方法はどうするか?
1. WindowsにしろMACにしろ、黒いターミナルを立ち上げます。
2. Rscript iris_predict.r
(iris_predict.r は、実行したいRです。)
# iris_predict.rの中身
model <- lm(Sepal.Length~., data=iris)
out <- predict(model)
out
write.table(out, file = "out.txt", sep = ',', quote=F, row.names=F, col.names=F)
# out.txt(出力されるファイル)
5.00478801897843
4.75684354978416
4.77309694623839
4.8893568348465
5.05437691281729
となります。
やっていることは単純なのですが、これを応用すれば、Rでモデルを作って自動バッチなども作成できますね。
Rでバッチ実行する方法はどうするか?
1. WindowsにしろMACにしろ、黒いターミナルを立ち上げます。
2. Rscript iris_predict.r
(iris_predict.r は、実行したいRです。)
# iris_predict.rの中身
model <- lm(Sepal.Length~., data=iris)
out <- predict(model)
out
write.table(out, file = "out.txt", sep = ',', quote=F, row.names=F, col.names=F)
# out.txt(出力されるファイル)
5.00478801897843
4.75684354978416
4.77309694623839
4.8893568348465
5.05437691281729
となります。
やっていることは単純なのですが、これを応用すれば、Rでモデルを作って自動バッチなども作成できますね。
【R】エラー:コネクションを開くことができません [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
パッケージをインストールしようとすると、コネクションを開くことができません というエラーが表示されます。
どうすれば良いでしょうか?
【回答】
会社などのパソコンだと、管理者権限がないとダウンロードできなかったり、フォルダにアクセスできない場合があります。
そんな場合は、いったん、パッケージをzipファイルを用意(ダウンロード)します。
例えば、forecastというパッケージだと、下記からダウンロードできます。
https://cran.r-project.org/web/packages/forecast/
続いて、Rのメニュー「パッケージ」から「install package(s) from local files…」を選択します。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
パッケージをインストールしようとすると、コネクションを開くことができません というエラーが表示されます。
どうすれば良いでしょうか?
【回答】
会社などのパソコンだと、管理者権限がないとダウンロードできなかったり、フォルダにアクセスできない場合があります。
そんな場合は、いったん、パッケージをzipファイルを用意(ダウンロード)します。
例えば、forecastというパッケージだと、下記からダウンロードできます。
https://cran.r-project.org/web/packages/forecast/
続いて、Rのメニュー「パッケージ」から「install package(s) from local files…」を選択します。
主成分分析と因子分析で正規化が必要か? [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
主成分分析と因子分析で正規化が必要か?
【回答】
まず、主成分分析と因子分析で何を元に計算されているかですが、
主成分分析:分散共分散行列
因子分析:相関行列
となっています。
主成分分析では分散共分散行列を使うため、単位の影響を受けてしまいます。
なので、単位が1000倍近くあると(gとkgみたいに)何かと問題になりやすい。
一方で、因子分析では相関行列を使っているため、標準化は必須ではないです。
パッケージのlavaanを使っていると、
lavaan WARNING: some observed variances are (at least) a factor 1000 times larger than others; use varTable(fit) to investigate
という警告文が出てくる場合があります。
モデル1とモデル2(100倍したもの)でモデルを作って比較すると、CFI、RMSEA、SRMRなどは同じ値になっていることが確認できるかと思います。
一方で、データそのものの値を使うAICなどは値が当然変わっています。
データが違うので、AICではモデル1とモデル2の比較は比較できません。
係数を見てみると、100倍したモデル2では、係数も100倍となっています。
########################################
library(lavaan)
library(psych)
#分析前にNA(欠測)を含む個体(対象者)を除外する
#リストワイズ削除
bfi2<-na.omit(bfi[ , c("A1", "A2", "A3", "A4", "A5", "gender")])
#変数に名前を付ける
colnames(bfi2)<-c("a1","a2","a3","a4","a5","gender")
bfi2_100 <- bfi2
bfi2_100$a1 <- bfi2_100$a1 * 100
#分析モデル 1
model <- '
A =~ a1 + a2 + a3 + a4 + a5
a1 ~~ a1;a2 ~~ a2;a3 ~~ a3;a4 ~~ a4;a5 ~~ a5
A ~~ 1*A
'
fit1 <- lavaan(model, data=bfi2)
summary(fit1, standardized=T, fit.measures = TRUE)
#分析モデル 2
fit2 <- lavaan(model, data=bfi2_100)
summary(fit2, standardized=T, fit.measures = TRUE)
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
主成分分析と因子分析で正規化が必要か?
【回答】
まず、主成分分析と因子分析で何を元に計算されているかですが、
主成分分析:分散共分散行列
因子分析:相関行列
となっています。
主成分分析では分散共分散行列を使うため、単位の影響を受けてしまいます。
なので、単位が1000倍近くあると(gとkgみたいに)何かと問題になりやすい。
一方で、因子分析では相関行列を使っているため、標準化は必須ではないです。
パッケージのlavaanを使っていると、
lavaan WARNING: some observed variances are (at least) a factor 1000 times larger than others; use varTable(fit) to investigate
という警告文が出てくる場合があります。
モデル1とモデル2(100倍したもの)でモデルを作って比較すると、CFI、RMSEA、SRMRなどは同じ値になっていることが確認できるかと思います。
一方で、データそのものの値を使うAICなどは値が当然変わっています。
データが違うので、AICではモデル1とモデル2の比較は比較できません。
係数を見てみると、100倍したモデル2では、係数も100倍となっています。
########################################
library(lavaan)
library(psych)
#分析前にNA(欠測)を含む個体(対象者)を除外する
#リストワイズ削除
bfi2<-na.omit(bfi[ , c("A1", "A2", "A3", "A4", "A5", "gender")])
#変数に名前を付ける
colnames(bfi2)<-c("a1","a2","a3","a4","a5","gender")
bfi2_100 <- bfi2
bfi2_100$a1 <- bfi2_100$a1 * 100
#分析モデル 1
model <- '
A =~ a1 + a2 + a3 + a4 + a5
a1 ~~ a1;a2 ~~ a2;a3 ~~ a3;a4 ~~ a4;a5 ~~ a5
A ~~ 1*A
'
fit1 <- lavaan(model, data=bfi2)
summary(fit1, standardized=T, fit.measures = TRUE)
#分析モデル 2
fit2 <- lavaan(model, data=bfi2_100)
summary(fit2, standardized=T, fit.measures = TRUE)
確率のエッセンス [データサイエンス、統計モデル]
パスカルとかラプラスとかってどんな人だろうと思い、何気なくアマゾンで検索していると、この本を見つけました。
")
基本的には、確率や場合分けの考え方の本なのですが、所々に過去の数学者たちの話が出てきます。
難しい数式はほとんど出てこないので、気楽に読むことができました。
久々に高校数学(確率や場合分け)に触れて懐かしい気分です。
確率のエッセンス ~大数学者たちと魔法のテクニック~ (知りたい! サイエンス)
- 作者: 岩沢 宏和
- 出版社/メーカー: 技術評論社
- 発売日: 2013/10/29
- メディア: 単行本(ソフトカバー)
基本的には、確率や場合分けの考え方の本なのですが、所々に過去の数学者たちの話が出てきます。
難しい数式はほとんど出てこないので、気楽に読むことができました。
久々に高校数学(確率や場合分け)に触れて懐かしい気分です。
【R】lavaanを使った多母集団同時分析 [データサイエンス、統計モデル]
共分散構造分析で多母集団同時分析をする方法について。
通常は、単一の母集団からサンプリングされたと仮定しますが、実際は、様々な集団(セグメント)を感がる必要があります。
性別の違い、年代の違いなど。
ただ、各セグメントごとにデータを分けてしまうと、サンプルサイズが小さくなってしまいます。
そこで、登場するのが多母集団同時分析です。
全体の構造は同じとみて、ここのセグメントごとに、係数を微調整するイメージです。
lavaanで多母集団同時分析をするには、
group = "*****"
で設定することができます。
# 分析モデル 1
通常の共分散構造分析
# 分析モデル 2
多母集団同時分析
########################################
library(lavaan)
library(psych)
#分析前にNA(欠測)を含む個体(対象者)を除外する
#リストワイズ削除
bfi2<-na.omit(bfi[ , c("A1", "A2", "A3", "A4", "A5", "gender")])
#変数に名前を付ける
colnames(bfi2)<-c("a1","a2","a3","a4","a5","gender")
#分析モデル 1
model <- '
A =~ a1 + a2 + a3 + a4 + a5
a1 ~~ a1;a2 ~~ a2;a3 ~~ a3;a4 ~~ a4;a5 ~~ a5
A ~~ 1*A
'
fit1 <- lavaan(model, data=bfi2)
summary(fit1, standardized=T, fit.measures = TRUE)
#分析モデル 2
fit2 <- lavaan(model, data=bfi2, group = "gender")
summary(fit2, standardized=T, fit.measures = TRUE)
########################################
通常は、単一の母集団からサンプリングされたと仮定しますが、実際は、様々な集団(セグメント)を感がる必要があります。
性別の違い、年代の違いなど。
ただ、各セグメントごとにデータを分けてしまうと、サンプルサイズが小さくなってしまいます。
そこで、登場するのが多母集団同時分析です。
全体の構造は同じとみて、ここのセグメントごとに、係数を微調整するイメージです。
lavaanで多母集団同時分析をするには、
group = "*****"
で設定することができます。
# 分析モデル 1
通常の共分散構造分析
# 分析モデル 2
多母集団同時分析
########################################
library(lavaan)
library(psych)
#分析前にNA(欠測)を含む個体(対象者)を除外する
#リストワイズ削除
bfi2<-na.omit(bfi[ , c("A1", "A2", "A3", "A4", "A5", "gender")])
#変数に名前を付ける
colnames(bfi2)<-c("a1","a2","a3","a4","a5","gender")
#分析モデル 1
model <- '
A =~ a1 + a2 + a3 + a4 + a5
a1 ~~ a1;a2 ~~ a2;a3 ~~ a3;a4 ~~ a4;a5 ~~ a5
A ~~ 1*A
'
fit1 <- lavaan(model, data=bfi2)
summary(fit1, standardized=T, fit.measures = TRUE)
#分析モデル 2
fit2 <- lavaan(model, data=bfi2, group = "gender")
summary(fit2, standardized=T, fit.measures = TRUE)
########################################
【R】ベースのカテゴリを変更したい その2 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
ロジスティク回帰分析の目的変数の設定を"購入する=1, 購入しない=0"とする場合と、逆に"購入する=0, 購入しない=0"とする場合があると思います。
どちらの設定になっているのかはどいうやって確認するのでしょうか?
【回答】
【R】ベースのカテゴリを変更したい
https://skellington.blog.ss-blog.jp/2021-03-29
↑
こちらの応用でできます。
まずは、irisのデータから、virginicaを削除します。
df <- subset(iris, Species == "setosa" | Species == "versicolor")
不要な(使っていない)Factorを除外。
df.new <- droplevels(df)
str(df.new)
デフォルトのロジスティック回帰分析
model_1a <- glm(Species ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_1a)
デフォルトのロジスティック回帰分析(ベースカテゴリは"setosa")
model_1b <- glm(relevel(factor(Species), ref = "setosa") ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_1b)
ベースカテゴリを"versicolor"に変更したロジスティック回帰分析
model_2 <- glm(relevel(factor(Species), ref = "versicolor") ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_2)
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
ロジスティク回帰分析の目的変数の設定を"購入する=1, 購入しない=0"とする場合と、逆に"購入する=0, 購入しない=0"とする場合があると思います。
どちらの設定になっているのかはどいうやって確認するのでしょうか?
【回答】
【R】ベースのカテゴリを変更したい
https://skellington.blog.ss-blog.jp/2021-03-29
↑
こちらの応用でできます。
まずは、irisのデータから、virginicaを削除します。
df <- subset(iris, Species == "setosa" | Species == "versicolor")
不要な(使っていない)Factorを除外。
df.new <- droplevels(df)
str(df.new)
デフォルトのロジスティック回帰分析
model_1a <- glm(Species ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_1a)
デフォルトのロジスティック回帰分析(ベースカテゴリは"setosa")
model_1b <- glm(relevel(factor(Species), ref = "setosa") ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_1b)
ベースカテゴリを"versicolor"に変更したロジスティック回帰分析
model_2 <- glm(relevel(factor(Species), ref = "versicolor") ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_2)
【R】ベースのカテゴリを変更したい [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rで回帰分析をする際に、カテゴリ変数の場合、自動でベースのカテゴリが決まりますが、変更することができますか?
【回答】
有名なirisデータを使って実験します。
str(iris)
summary(iris)
Speciesは、3カテゴリあります。
setosa: 1
versicolor: 2
virginica: 3
通常は、factorで最初の数字のものがベースになってしまいます。
model_1 <- lm(Sepal.Length ~ Species, data=iris)
summary(model_1)
(Intercept) 5.0060 0.0728 68.762 < 2e-16 ***
Speciesversicolor 0.9300 0.1030 9.033 8.77e-16 ***
Speciesvirginica 1.5820 0.1030 15.366 < 2e-16 ***
ここで、setosaではなく、versicolorをベースカテゴリにするにはどうすれば良いか?
relevel(factor(Species), ref = "versicolor")
で設定できます。
model_2 <- lm(Sepal.Length ~ relevel(factor(Species), ref = "versicolor"), data=iris)
summary(model_2)
(Intercept) 5.9360 0.0728 81.536 < 2e-16 ***
relevel(factor(Species), ref = "versicolor")setosa -0.9300 0.1030 -9.033 8.77e-16 ***
relevel(factor(Species), ref = "versicolor")virginica 0.6520 0.1030 6.333 2.77e-09 ***
このようにversicolorがベースとなり、setosaとvirginicaの係数を得ることができました。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rで回帰分析をする際に、カテゴリ変数の場合、自動でベースのカテゴリが決まりますが、変更することができますか?
【回答】
有名なirisデータを使って実験します。
str(iris)
summary(iris)
Speciesは、3カテゴリあります。
setosa: 1
versicolor: 2
virginica: 3
通常は、factorで最初の数字のものがベースになってしまいます。
model_1 <- lm(Sepal.Length ~ Species, data=iris)
summary(model_1)
(Intercept) 5.0060 0.0728 68.762 < 2e-16 ***
Speciesversicolor 0.9300 0.1030 9.033 8.77e-16 ***
Speciesvirginica 1.5820 0.1030 15.366 < 2e-16 ***
ここで、setosaではなく、versicolorをベースカテゴリにするにはどうすれば良いか?
relevel(factor(Species), ref = "versicolor")
で設定できます。
model_2 <- lm(Sepal.Length ~ relevel(factor(Species), ref = "versicolor"), data=iris)
summary(model_2)
(Intercept) 5.9360 0.0728 81.536 < 2e-16 ***
relevel(factor(Species), ref = "versicolor")setosa -0.9300 0.1030 -9.033 8.77e-16 ***
relevel(factor(Species), ref = "versicolor")virginica 0.6520 0.1030 6.333 2.77e-09 ***
このようにversicolorがベースとなり、setosaとvirginicaの係数を得ることができました。
R version 4.0.4で漢字の読み込みエラー [データサイエンス、統計モデル]
バージョン4.0.3ではエラーが起きなかったのですが、最新の4.0.4を使うと漢字を読み込むとエラーが起こっています。
(例)
df <- read.table(file=csv1, header=TRUE, sep=",", fileEncoding = "utf-8")
"ひらがな"や"カタカナ"はきちんと読み込めますが、漢字だけ文字化けになっていました。(^^;
(例)
df <- read.table(file=csv1, header=TRUE, sep=",", fileEncoding = "utf-8")
"ひらがな"や"カタカナ"はきちんと読み込めますが、漢字だけ文字化けになっていました。(^^;
共分散構造分析における自由度の計算方法 [データサイエンス、統計モデル]
共分散構造分析(因子分析)における自由度の計算方法のまとめ
共分散を元に計算していきます。
自由度 = 共分散の数 - 推定するパラメータ数(矢印の数)
【ケース 1】識別不能の場合の適合度
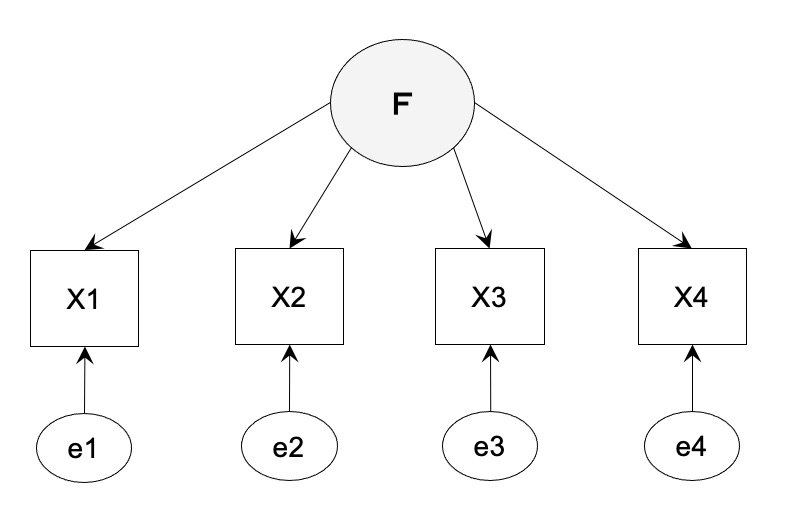
自由度 4x3/2 + 4 - 8 = 2
【ケース 2】丁度識別の場合の適合度
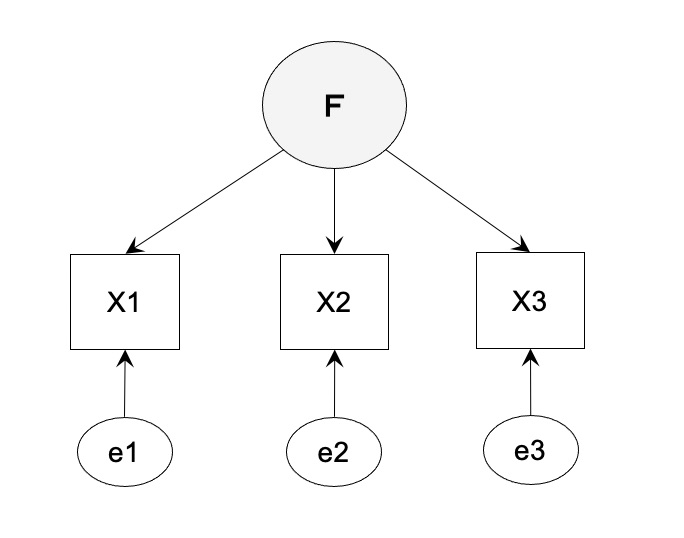
自由度 3x2/2 + 3 - 6 = 0
【ケース 3】識別不定の場合の適合度
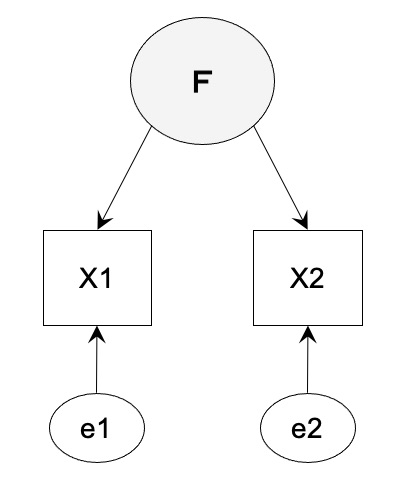
自由度 2/2 + 2 - 4 = -1
共分散を元に計算していきます。
自由度 = 共分散の数 - 推定するパラメータ数(矢印の数)
【ケース 1】識別不能の場合の適合度
自由度 4x3/2 + 4 - 8 = 2
【ケース 2】丁度識別の場合の適合度
自由度 3x2/2 + 3 - 6 = 0
【ケース 3】識別不定の場合の適合度
自由度 2/2 + 2 - 4 = -1
データサイエンスから視た人工知能 [データサイエンス、統計モデル]
データサイエンスから視た人工知能
https://www.ism.ac.jp/events/2021/meeting0319.html
統計数理研究所のセミナー。
椿先生らしいモデレーターで、さりげない一言が心に残りました。
ベイズ最適化とか、いくつかやってみたいアイデアも浮かびました。
コロナの影響で公開セミナーとかも減ってきていますが、こういった頭のリフレッシュって大切だなと思います。
https://www.ism.ac.jp/events/2021/meeting0319.html
統計数理研究所のセミナー。
椿先生らしいモデレーターで、さりげない一言が心に残りました。
ベイズ最適化とか、いくつかやってみたいアイデアも浮かびました。
コロナの影響で公開セミナーとかも減ってきていますが、こういった頭のリフレッシュって大切だなと思います。
ABテストのメリットと検定の罠 [データサイエンス、統計モデル]
ランダムに実験をして得られたデータはかなり良質なデータだったりします。
この辺りのことを整理してみると・・・
ランダムな実験は企業として難しい、意図的に配信したデータでもランダムな実験と同様の分析がしたい。
最近では、傾向スコアとか、反実仮想機械学習とかの概念が出てきて、必ずしもランダムデータは必須ではないと言われています。
ただ、実際に配信していないセグメントに対して予測することはなかなか難しいですし、効果を見積もるときに、何かとランダムデータの方が便利なので、ランダム実験できるならした方が良いと思います。
ポイントとかクーポンの介入の効果(因果)を見るには、やはりABテストは最強だったりします。
ここで陥りやすい罠として、ABテストって2つの群に分けているので人としては、検定をやりたくなる。
簡単だし、有意かどうかで白黒はっきりするし。
ただ、用意された2つのデータ(ABテストデータ)が、検定向きのデータであっても、統計検定ではなく、統計モデルを作ろうという発想になる人はあまりいない。
よく見るアプローチとしては、最近流行の機械学習とABテスト組み合わせて使うケースが多い。
ただ、ポイントとかクーポンの介入の分析って、本来、マーケティングをやっている人が欲しいのは、予測精度だけでなく、クーポンをもらってカスタマの構造がどう変わるのか/変わらないのかといったインサイトも欲しい。
しかし、このインサイトの理解と機械学習の相性がめちゃくちゃ悪かったりします。
そこでおすすめなのが、統計モデルとABテストの組み合わせが、良いと思います。
できれば、通常の線形回帰ではなく、階層ベイズモデルといったモデルが作れるとさらに良いと思っています。
この辺りのことを整理してみると・・・
ランダムな実験は企業として難しい、意図的に配信したデータでもランダムな実験と同様の分析がしたい。
最近では、傾向スコアとか、反実仮想機械学習とかの概念が出てきて、必ずしもランダムデータは必須ではないと言われています。
ただ、実際に配信していないセグメントに対して予測することはなかなか難しいですし、効果を見積もるときに、何かとランダムデータの方が便利なので、ランダム実験できるならした方が良いと思います。
ポイントとかクーポンの介入の効果(因果)を見るには、やはりABテストは最強だったりします。
ここで陥りやすい罠として、ABテストって2つの群に分けているので人としては、検定をやりたくなる。
簡単だし、有意かどうかで白黒はっきりするし。
ただ、用意された2つのデータ(ABテストデータ)が、検定向きのデータであっても、統計検定ではなく、統計モデルを作ろうという発想になる人はあまりいない。
よく見るアプローチとしては、最近流行の機械学習とABテスト組み合わせて使うケースが多い。
ただ、ポイントとかクーポンの介入の分析って、本来、マーケティングをやっている人が欲しいのは、予測精度だけでなく、クーポンをもらってカスタマの構造がどう変わるのか/変わらないのかといったインサイトも欲しい。
しかし、このインサイトの理解と機械学習の相性がめちゃくちゃ悪かったりします。
そこでおすすめなのが、統計モデルとABテストの組み合わせが、良いと思います。
できれば、通常の線形回帰ではなく、階層ベイズモデルといったモデルが作れるとさらに良いと思っています。
機械学習で大量の変数を作ることの問題点 [データサイエンス、統計モデル]
若手のエンジニアと話していた時の話。
いろんな変数をmaxとかminとか一見意味のない処理で大量に増幅させて、予測精度をあげようという方針でした。
精度ということに着目すれば、こういうアプローチもあるんだろうな、と思うのですが、個人的には大きな違和感があったので、問題点を整理してみます。
(問題点 1)
モデルが2つあった場合、予測精度がA:90%とB:95%である。
B:95%のモデルが良いモデルかといえば、必ずしもそうではない。
クーポンとかポイントの配布をする際に、クーポンの効用部分の精度を確認しないと、大きな失敗をする場合がある。
つまり、介入するという場合、介入する効果の精度が全体の精度より大切。
(問題点 2)
多くの変数をカウントするのではなく、もっと単純な構造が隠れている場合があり、シンプルに少ない変数を加工して使った場合と精度が変わらない。
そして、前者の場合は、作ったモデルは予測にしか使えないが、後者の場合は予測に加えて、構造も同時に理解することができる。
(問題点 3)
大量に変数を使うことで、0.1%精度が上がるかもしれない。
しかし、クーポンをそれなりの人に配るのであれば、0.1%で何が変わるかといえば、ほんの少し順番が変わるくらいだろう。
その辺りのことは無視した方が良い。
(問題点 4)
点で推定した確率しかみない人がいる。
しかし、期待確率は点ではなく、ある幅を持っている。
確率的な幅を出すためには、機械学習モデルより統計モデルの方が良い。
いろんな変数をmaxとかminとか一見意味のない処理で大量に増幅させて、予測精度をあげようという方針でした。
精度ということに着目すれば、こういうアプローチもあるんだろうな、と思うのですが、個人的には大きな違和感があったので、問題点を整理してみます。
(問題点 1)
モデルが2つあった場合、予測精度がA:90%とB:95%である。
B:95%のモデルが良いモデルかといえば、必ずしもそうではない。
クーポンとかポイントの配布をする際に、クーポンの効用部分の精度を確認しないと、大きな失敗をする場合がある。
つまり、介入するという場合、介入する効果の精度が全体の精度より大切。
(問題点 2)
多くの変数をカウントするのではなく、もっと単純な構造が隠れている場合があり、シンプルに少ない変数を加工して使った場合と精度が変わらない。
そして、前者の場合は、作ったモデルは予測にしか使えないが、後者の場合は予測に加えて、構造も同時に理解することができる。
(問題点 3)
大量に変数を使うことで、0.1%精度が上がるかもしれない。
しかし、クーポンをそれなりの人に配るのであれば、0.1%で何が変わるかといえば、ほんの少し順番が変わるくらいだろう。
その辺りのことは無視した方が良い。
(問題点 4)
点で推定した確率しかみない人がいる。
しかし、期待確率は点ではなく、ある幅を持っている。
確率的な幅を出すためには、機械学習モデルより統計モデルの方が良い。
pythonで回帰分析をやる際の落とし穴 [データサイエンス、統計モデル]
最近、機械学習をずっとやってきた人のレビューをする機会があって、いろいろ衝撃を受けているのですが、よく見かける間違いについて。
機械学習とかだとあまり意識しなくても良いんだろうけど、統計モデルの回帰分析をやる時、説明変数にカテゴリ変数が入っている場合があります。
血液型とか、性別とか。
Rでカテゴリ変数が入っている場合、Rの内部でよしなにダミー変数に変換してくれます。
具体的には、「カテゴリ数-1」となっています。
ずっと、pythonで機械学習をやってきた人はこの辺りのことを知らない人がそれなりにいるみたいでして、そのまま突っ込んで回帰分析をしてしまう。
pythonの場合は、それっぽく動いてしまうのがやっかい。
結果を見て、なんかおかしいんですけど、どうでしてですか?的な質問を何度か受けました。
先日のAICを知らない問題もそうなんですが、統計モデルのかなり初歩的な部分だと思っていただけに、ちょっと驚き。
コードのレビューとかができるエンジニアはたくさんいるけど、肝心のモデル部分のレビューって出来る人って意外と世の中的に少ないのかなって感じる今日この頃です。
機械学習とかだとあまり意識しなくても良いんだろうけど、統計モデルの回帰分析をやる時、説明変数にカテゴリ変数が入っている場合があります。
血液型とか、性別とか。
Rでカテゴリ変数が入っている場合、Rの内部でよしなにダミー変数に変換してくれます。
具体的には、「カテゴリ数-1」となっています。
ずっと、pythonで機械学習をやってきた人はこの辺りのことを知らない人がそれなりにいるみたいでして、そのまま突っ込んで回帰分析をしてしまう。
pythonの場合は、それっぽく動いてしまうのがやっかい。
結果を見て、なんかおかしいんですけど、どうでしてですか?的な質問を何度か受けました。
先日のAICを知らない問題もそうなんですが、統計モデルのかなり初歩的な部分だと思っていただけに、ちょっと驚き。
コードのレビューとかができるエンジニアはたくさんいるけど、肝心のモデル部分のレビューって出来る人って意外と世の中的に少ないのかなって感じる今日この頃です。
AICを知らない!? [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
RかPythonどっちが良いですか?
【回答】
RとPythonの違いですが、Rは統計モデル向けで、Pythonは機械学習向け。
統計モデルは、ある程度の精度を犠牲にして構造の理解やインサイトの理解をするのに便利。
機械学習は、基本ブラックボックスで、予測精度に重きを置いている。
いずれにしても、実際に使う課題から入った方が理解が進むし、持続すると思います。
話がそれますが、自分的には衝撃の出来事が。
機械学習に関して、ものすごく出来る子がいるのですが、AICを知らなかった。
統計をやっていると、AICはしょっちゅう出てきますが、機械学習メインだとこの辺りって未学習なんですかね。
ただ、とても優秀なので、すぐに理解したのはさすがです。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
RかPythonどっちが良いですか?
【回答】
RとPythonの違いですが、Rは統計モデル向けで、Pythonは機械学習向け。
統計モデルは、ある程度の精度を犠牲にして構造の理解やインサイトの理解をするのに便利。
機械学習は、基本ブラックボックスで、予測精度に重きを置いている。
いずれにしても、実際に使う課題から入った方が理解が進むし、持続すると思います。
話がそれますが、自分的には衝撃の出来事が。
機械学習に関して、ものすごく出来る子がいるのですが、AICを知らなかった。
統計をやっていると、AICはしょっちゅう出てきますが、機械学習メインだとこの辺りって未学習なんですかね。
ただ、とても優秀なので、すぐに理解したのはさすがです。
SQL where 1=1 の意味 [データサイエンス、統計モデル]
最近、SQLを書いたり読んだりする機会が増えてきましたが、
といったように、1=1が書かれています。
昔調べたときに、1=1は必ずtrueなので、あってもなくても同じという記事をみて、そんなもんかと思っていました。
気になったので、少し詳しく調べてみると、
動的にプログラミングができるとか、可読性があるとかって記事が多かったのですが、個人的にしっくりきたのは、コメントアウトしやすくなるという理由。
1=1を書いておくだけで、かなり見やすくなります。
SELECT
A
,B
,C
,D
,E
FROM TABLE
WHERE 1=1
and B='This'
and C='That'
and D is not null
といったように、1=1が書かれています。
昔調べたときに、1=1は必ずtrueなので、あってもなくても同じという記事をみて、そんなもんかと思っていました。
気になったので、少し詳しく調べてみると、
動的にプログラミングができるとか、可読性があるとかって記事が多かったのですが、個人的にしっくりきたのは、コメントアウトしやすくなるという理由。
SELECT
A
-- ,B
-- ,C
,D
,E
FROM TABLE
WHERE 1=1
-- and B='This'
-- and C='That'
and D is not null
1=1を書いておくだけで、かなり見やすくなります。
[R]線形回帰に非負制約を入れるやり方 [データサイエンス、統計モデル]
線形回帰で、この変数は必ず0以上の値が欲しいという場合があるかもしれません。
基本的には、この様な制約は入れない方が良いです。
というのは、最尤法や最小二乗法で推定する場合、そのパラメータが負である場合が妥当だと推定しているにもかかわらず、無理やりに0以上にしてしまうわけです。
無理に非負制約を入れた結果、どうなるかと言えば、おそらく、推定されたパラメータは0になってしまいます。
(↑)という前提で・・・
通常のlmやglmではなく、lavaanというパッケージを使って、線形回帰に非負制約を入れるやり方について。
lavaanのモデルの書き方(制約なしの場合)
目的変数: y
説明変数: x1, x2
model_1 <- "
y ~ x1 + x2
myLable1 > 0
y ~ 1
"
lavaanのモデルの書き方(制約ありの場合)
目的変数: y
説明変数: x1, x2
制約: x1 > 0
model_1 <- "
y ~ myLable1 * x1 + x2
myLable1 > 0
y ~ 1
"
myLable1 > 0
という条件を加えるとできます。
基本的には、この様な制約は入れない方が良いです。
というのは、最尤法や最小二乗法で推定する場合、そのパラメータが負である場合が妥当だと推定しているにもかかわらず、無理やりに0以上にしてしまうわけです。
無理に非負制約を入れた結果、どうなるかと言えば、おそらく、推定されたパラメータは0になってしまいます。
(↑)という前提で・・・
通常のlmやglmではなく、lavaanというパッケージを使って、線形回帰に非負制約を入れるやり方について。
lavaanのモデルの書き方(制約なしの場合)
目的変数: y
説明変数: x1, x2
model_1 <- "
y ~ x1 + x2
myLable1 > 0
y ~ 1
"
lavaanのモデルの書き方(制約ありの場合)
目的変数: y
説明変数: x1, x2
制約: x1 > 0
model_1 <- "
y ~ myLable1 * x1 + x2
myLable1 > 0
y ~ 1
"
myLable1 > 0
という条件を加えるとできます。
Towards Causal Representation Learning [データサイエンス、統計モデル]
Towards Causal Representation Learning
https://arxiv.org/abs/2102.11107
機械学習と因果推論の融合に関する論文。
著者はディープラーニングで有名なBengio先生。
数年前から、ディープラーニングといった機械学習分野にも因果推論的な話がよく聞かれる様になってきたと思います。
いろいろな理由があるかと思いますが、自分なりに整理してみると、
1. 企業の中で実際にアップリフトモデルなどをやろうとした際に、マーケティングサイドに説明が必要。
ブラックボックス的な話よりも多少、精度を落としても説明力のあるモデルで語った方が早い。
ここまでは、よくある普通の話。
マーケティングが一歩進んでいる企業の場合、ポイントやクーポンを使った施策をしているわけですが、やがてそこも限界が出てくる。
限界が見えた時に、ふと我に帰ると、なんかCRMといってもクーポンしか配布していないやん!これってCRMと言えるのか?といった段階になるんだと思います。
そこで、この段階で必要なのが、誰にクーポンを配るのか(who)といった問題ではなく、なぜクーポンを配るのか(why)に着目する様になります。
そうなってくると、機械学習よりかはマーケティングモデル(統計モデル)が必要になってくるのかと。
世界的にも、機械学習を使って精度をあげよう的なステージから、構造理解へという流れなのかもしれません。
https://arxiv.org/abs/2102.11107
機械学習と因果推論の融合に関する論文。
著者はディープラーニングで有名なBengio先生。
数年前から、ディープラーニングといった機械学習分野にも因果推論的な話がよく聞かれる様になってきたと思います。
いろいろな理由があるかと思いますが、自分なりに整理してみると、
1. 企業の中で実際にアップリフトモデルなどをやろうとした際に、マーケティングサイドに説明が必要。
ブラックボックス的な話よりも多少、精度を落としても説明力のあるモデルで語った方が早い。
ここまでは、よくある普通の話。
マーケティングが一歩進んでいる企業の場合、ポイントやクーポンを使った施策をしているわけですが、やがてそこも限界が出てくる。
限界が見えた時に、ふと我に帰ると、なんかCRMといってもクーポンしか配布していないやん!これってCRMと言えるのか?といった段階になるんだと思います。
そこで、この段階で必要なのが、誰にクーポンを配るのか(who)といった問題ではなく、なぜクーポンを配るのか(why)に着目する様になります。
そうなってくると、機械学習よりかはマーケティングモデル(統計モデル)が必要になってくるのかと。
世界的にも、機械学習を使って精度をあげよう的なステージから、構造理解へという流れなのかもしれません。
R stan、コンパイルとMCMCサンプリング [データサイエンス、統計モデル]
ステップ 1 rstanを呼び出す
library(rstan)
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
ステップ 2 データとモデルを読み込む
外部データでも良いし、Rの中に記述するやり方でも良いです。
↑
3-1, 3-2を同時にする方法もあって、下記の様に書くと、コンパイルとモデルが同時に実行されます。
fit = stan(file="./stan/Binom.stan", data=data_stan_bin)
イテレーションの回数を変更したい、とか、chainsをとりあえず1回にして、後で4回実行したいという要望があると思うので、コンパイルとサンプリングは分けておいた方が良い気がします。
library(rstan)
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
ステップ 2 データとモデルを読み込む
外部データでも良いし、Rの中に記述するやり方でも良いです。
# stan モデルの定義
stan_code <- '
data{
int n;
int x;
}
parameters{
real p;
}
model{
x ~ binomial(n, p);
}
'
# stan データの定義
data_stan_bin <- list(n=30, x=3)
ステップ 3-1 C++に変換してコンパイルする
model.mcmc = rstan::stan_model(model_code = stan_code)
ステップ 3-2 MCMCサンプリング
fit = rstan::sampling(model.mcmc, data = data_stan_bin, iter = 10000, chains = 4)
↑
3-1, 3-2を同時にする方法もあって、下記の様に書くと、コンパイルとモデルが同時に実行されます。
fit = stan(file="./stan/Binom.stan", data=data_stan_bin)
イテレーションの回数を変更したい、とか、chainsをとりあえず1回にして、後で4回実行したいという要望があると思うので、コンパイルとサンプリングは分けておいた方が良い気がします。
傾向スコアを使ったアップリフトモデルについて考える その2 [データサイエンス、統計モデル]
傾向スコアを使ったアップリフトモデルについて考える
https://skellington.blog.ss-blog.jp/2021-02-12
↑
こちらの続き。
まずは、前回のおさらいから。
傾向スコアの手順
1. データを3つに分けて考えます。
目的変数:y
説明変数その1:CTL or TG
説明変数その2:他の変数X(変数Xの中にyや"説明変数その1"は入れない)
2. CTLとTGを他の変数Xを使ってロジスティック回帰分析で変数XがCTL/TGにあたえる影響をモデリングする。
3. 目的変数yとCTL/TGの傾向スコアをみて、yとCTL/TGの関係をモデル化する。
アップリフトモデルの思想としては、
a. CTL と TGの効果を正しく見積もりたい
b. 人によって、施策効果(TGの効果)は違うはずなので、効率の良いセグメントを見つけたい
です。
しかし、この方法だと、a.の効果は分かっても、b.の効果はわからない。
CTL/TGの効果は、平均的な消費者像を扱っていることになります。
b.に関して、人ごとの効果のモデリングはは難しいとして、ある程度のセグメントごとにその傾向をみたいと考えるわけです。
簡単なセグメントの場合(一般顧客、優良顧客くらい)だと、データを一般と優良の2つに分けることで、それぞれのCTL/TGの効果をみることはできそうです。
しかし、セグメントをものすごく細かくしていった場合どうなるか?
完全にランダムデータの場合(CTLとTGがランダムに選ばれている場合)は、わざわざ傾向スコアを持ち出さなくても、簡単に分析できます。
マーケティングの施策(CTLとTG)は、何かの戦略によって、TGになったりCTLになったりしているので、セグメントを細かく指定いくと、ほとんどCTLだったりTGだったりとなる可能性出てきます。
このような状況の場合は、各セグメント後の施策効果を正しく判断するのはできなくなります。
いっけん遠回りに思えるかもしれないが、最初にランダムな実験をしておいて、質の良いトレーニングデータを作っておくことで、その後のモデル化が効率化されたり、各セグメントの効果を正しく見積もれるようになると考えています。
https://skellington.blog.ss-blog.jp/2021-02-12
↑
こちらの続き。
まずは、前回のおさらいから。
傾向スコアの手順
1. データを3つに分けて考えます。
目的変数:y
説明変数その1:CTL or TG
説明変数その2:他の変数X(変数Xの中にyや"説明変数その1"は入れない)
2. CTLとTGを他の変数Xを使ってロジスティック回帰分析で変数XがCTL/TGにあたえる影響をモデリングする。
3. 目的変数yとCTL/TGの傾向スコアをみて、yとCTL/TGの関係をモデル化する。
アップリフトモデルの思想としては、
a. CTL と TGの効果を正しく見積もりたい
b. 人によって、施策効果(TGの効果)は違うはずなので、効率の良いセグメントを見つけたい
です。
しかし、この方法だと、a.の効果は分かっても、b.の効果はわからない。
CTL/TGの効果は、平均的な消費者像を扱っていることになります。
b.に関して、人ごとの効果のモデリングはは難しいとして、ある程度のセグメントごとにその傾向をみたいと考えるわけです。
簡単なセグメントの場合(一般顧客、優良顧客くらい)だと、データを一般と優良の2つに分けることで、それぞれのCTL/TGの効果をみることはできそうです。
しかし、セグメントをものすごく細かくしていった場合どうなるか?
完全にランダムデータの場合(CTLとTGがランダムに選ばれている場合)は、わざわざ傾向スコアを持ち出さなくても、簡単に分析できます。
マーケティングの施策(CTLとTG)は、何かの戦略によって、TGになったりCTLになったりしているので、セグメントを細かく指定いくと、ほとんどCTLだったりTGだったりとなる可能性出てきます。
このような状況の場合は、各セグメント後の施策効果を正しく判断するのはできなくなります。
いっけん遠回りに思えるかもしれないが、最初にランダムな実験をしておいて、質の良いトレーニングデータを作っておくことで、その後のモデル化が効率化されたり、各セグメントの効果を正しく見積もれるようになると考えています。
二項ロジスティック回帰分析の結果が全て同じ結果になる!? [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
二項ロジスティック回帰分析を行ったところ、全ての説明変数で同じ数値(係数やp値)になってしまいました。
【回答】
この場合は、多重共線性が疑われます。
### vifで多重共線性を確認
library(car)
model <- glm(y~., family = binomial, data=dat)
vif(model)
### AICによる変数選択
library(MASS)
## 増減法"both"
modelAIC <- stepAIC(model, direction="both")
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
二項ロジスティック回帰分析を行ったところ、全ての説明変数で同じ数値(係数やp値)になってしまいました。
【回答】
この場合は、多重共線性が疑われます。
### vifで多重共線性を確認
library(car)
model <- glm(y~., family = binomial, data=dat)
vif(model)
### AICによる変数選択
library(MASS)
## 増減法"both"
modelAIC <- stepAIC(model, direction="both")
R stanを実行する方法 モデルを読み込む2つの方法 [データサイエンス、統計モデル]
stanを実行する際に必要なものが2つあります。
・データ
・stanのモデル
stanのモデルを読み込む方法として、
- 外部にテキストで保存してそれを読み込む方法
- Rでモデルを書いてそれを読み込む方法
があります。
?stan
をRで実行するとヘルプが出てくるのですが、それぞれ引数が書かれています。
- 外部にテキストで保存してそれを読み込む方法
file= 引数を使う
res_mcmc_bin <- stan(file="./stan/Binom.stan", data=data_stan_bin)
- Rでモデルを書いてそれを読み込む方法
model_code= 引数を使う
stan_code <- '
data{
int n;
int x;
}
parameters{
real p;
}
model{
x ~ binomial(n, p);
}
'
res_mcmc_bin <- stan(model_code=stan_code, data=data_stan_bin)
あらかじめRでモデルを書く方法ですが、複数行のコードなので、シングルクォートでくくります。
stan_code <- '
*****
*****
*****
'
・データ
・stanのモデル
stanのモデルを読み込む方法として、
- 外部にテキストで保存してそれを読み込む方法
- Rでモデルを書いてそれを読み込む方法
があります。
?stan
をRで実行するとヘルプが出てくるのですが、それぞれ引数が書かれています。
Usage
stan(file, model_name = "anon_model", model_code = "", fit = NA,
data = list(), pars = NA,
chains = 4, iter = 2000, warmup = floor(iter/2), thin = 1,
init = "random", seed = sample.int(.Machine$integer.max, 1),
algorithm = c("NUTS", "HMC", "Fixed_param"),
control = NULL, sample_file = NULL, diagnostic_file = NULL,
save_dso = TRUE, verbose = FALSE, include = TRUE,
cores = getOption("mc.cores", 1L),
open_progress = interactive() && !isatty(stdout()) &&
!identical(Sys.getenv("RSTUDIO"), "1"),
...,
boost_lib = NULL, eigen_lib = NULL
)
file
The path to the Stan program to use. file should be a character string file name or a connection that R supports containing the text of a model specification in the Stan modeling language.
A model may also be specified directly as a character string using the model_code argument, but we recommend always putting Stan programs in separate files with a .stan extension.
The stan function can also use the Stan program from an existing stanfit object via the fit argument. When fit is specified, the file argument is ignored.
model_code
A character string either containing the model definition or the name of a character string object in the workspace. This argument is used only if arguments file and fit are not specified.
- 外部にテキストで保存してそれを読み込む方法
file= 引数を使う
res_mcmc_bin <- stan(file="./stan/Binom.stan", data=data_stan_bin)
- Rでモデルを書いてそれを読み込む方法
model_code= 引数を使う
stan_code <- '
data{
int n;
int x;
}
parameters{
real
傾向スコアを使ったアップリフトモデルについて考える [データサイエンス、統計モデル]
ABテストみたいにランダム実験ができる環境だと良いのですが、例えば、薬を投与する/投与しないといったことをランダムでやるには人道的に反しますし、ビジネスにおいてもあえて効果がない群にキャンペーンを実施することはNGとなる場合が多いです。
そこで傾向スコアみたいな考え方が出てきて、あえてランダム実験をしていなくてもアップリフトが計算したいというニーズはありそうです。
傾向スコアでもでりんぐしてみるとこんな感じです。
知りたいのは、
目的変数: re78
介入効果: treat
の効果が知りたい。
# Propensity Score
install.packages("Matching")
library(Matching)
data(lalonde)
head(lalonde)
# どんな人に介入をしたのか(treat)をロジスティック回帰分析で傾向をつかんでおきます。
model.glm <- glm(treat ~ age + educ + black + hisp + married + nodegr + re74 + re75 + u74+ u75,
family=binomial, data=lalonde)
summary(model.glm)
# 傾向スコアを使わない場合
model2 <- lm(re78~treat, data=lalonde)
summary(model2)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4554.8 408.0 11.162 < 2e-16 ***
## treat 1794.3 632.9 2.835 0.00479 **
##
## 介入効果は、1794.3
## ただし、他の変数の影響を受けている
# 傾向スコアを使う場合
model3 <- Match(Y=lalonde$re78, Tr=lalonde$treat, X = model.glm$fitted)
summary(model3)
## Estimate... 2138.6
## AI SE...... 797.76
## T-stat..... 2.6807
## p.val...... 0.0073468
##
## Original number of observations.............. 445
## Original number of treated obs............... 185
## Matched number of observations............... 185
## Matched number of observations (unweighted). 322
2138.6というのがtreatの効果だと言っています。
ここで、ふと気がついたのですが・・・
マーケティングにおけるキャンペーンって、人によって、また、タイミングによって施策の効果が変わってくるはずです。
知りたいのは、平均的な消費者像に対するキャンペーン効果ではないはず。
となると、傾向スコアを使ったアップリフトモデルというのは、ちょっと厳しそう。
実は、ここの異質性を考慮した傾向スコアというのも出せるのかもしれませんが、ちょっと研究不足です。m(_ _)m
そこで傾向スコアみたいな考え方が出てきて、あえてランダム実験をしていなくてもアップリフトが計算したいというニーズはありそうです。
傾向スコアでもでりんぐしてみるとこんな感じです。
知りたいのは、
目的変数: re78
介入効果: treat
の効果が知りたい。
# Propensity Score
install.packages("Matching")
library(Matching)
data(lalonde)
head(lalonde)
# どんな人に介入をしたのか(treat)をロジスティック回帰分析で傾向をつかんでおきます。
model.glm <- glm(treat ~ age + educ + black + hisp + married + nodegr + re74 + re75 + u74+ u75,
family=binomial, data=lalonde)
summary(model.glm)
# 傾向スコアを使わない場合
model2 <- lm(re78~treat, data=lalonde)
summary(model2)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4554.8 408.0 11.162 < 2e-16 ***
## treat 1794.3 632.9 2.835 0.00479 **
##
## 介入効果は、1794.3
## ただし、他の変数の影響を受けている
# 傾向スコアを使う場合
model3 <- Match(Y=lalonde$re78, Tr=lalonde$treat, X = model.glm$fitted)
summary(model3)
## Estimate... 2138.6
## AI SE...... 797.76
## T-stat..... 2.6807
## p.val...... 0.0073468
##
## Original number of observations.............. 445
## Original number of treated obs............... 185
## Matched number of observations............... 185
## Matched number of observations (unweighted). 322
2138.6というのがtreatの効果だと言っています。
ここで、ふと気がついたのですが・・・
マーケティングにおけるキャンペーンって、人によって、また、タイミングによって施策の効果が変わってくるはずです。
知りたいのは、平均的な消費者像に対するキャンペーン効果ではないはず。
となると、傾向スコアを使ったアップリフトモデルというのは、ちょっと厳しそう。
実は、ここの異質性を考慮した傾向スコアというのも出せるのかもしれませんが、ちょっと研究不足です。m(_ _)m
R stanのエラー: コネクションを開くことができません [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
R stanでエラーが出ますが、どうすれば良いですか?
Error in file(fname, "rt") : コネクションを開くことができません
追加情報: 警告メッセージ:
1: normalizePath(file) で:
path[1]="./stan/Binom.stan": No such file or directory
2: file(fname, "rt") で:
ファイル './stan/Binom.stan' を開くことができません: No such file or directory
get_model_strcode(file, model_code) でエラー:
cannot open model file "./stan/Binom.stan"
【回答】
stanを動かすには、なかなかプログラムを書くという難しがあります。
データを入れて、コマンドを書けば、それっぽい結果が出てくるというその辺りのツールとは違うので、取り扱うにはそれなりのスキルと、理論的な背景の理解が必要だったりします。
Error in file(fname, "rt") : コネクションを開くことができません
とか
No such file or directory
というメッセージをみると、多くは、ファイルの場所の問題です。
作業ディレクトリは、getwd()で確認できます。
上記の場合、作業ディレクトリの配下に、stanというフォルダがあり、その中に、Binom.stanというstanファイルがある前提です。
エラーの多くは、全然別の場所を指定している場合がほとんどなので、
setwd(" 作業ディレクトリの場所 ") で変更してあげると良いでしょう。
個人的な感覚ですが、エラーで動きませんと言われて、けっこうな確率で、このファイルの場所問題である場合が多いです。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
R stanでエラーが出ますが、どうすれば良いですか?
Error in file(fname, "rt") : コネクションを開くことができません
追加情報: 警告メッセージ:
1: normalizePath(file) で:
path[1]="./stan/Binom.stan": No such file or directory
2: file(fname, "rt") で:
ファイル './stan/Binom.stan' を開くことができません: No such file or directory
get_model_strcode(file, model_code) でエラー:
cannot open model file "./stan/Binom.stan"
【回答】
stanを動かすには、なかなかプログラムを書くという難しがあります。
データを入れて、コマンドを書けば、それっぽい結果が出てくるというその辺りのツールとは違うので、取り扱うにはそれなりのスキルと、理論的な背景の理解が必要だったりします。
Error in file(fname, "rt") : コネクションを開くことができません
とか
No such file or directory
というメッセージをみると、多くは、ファイルの場所の問題です。
作業ディレクトリは、getwd()で確認できます。
上記の場合、作業ディレクトリの配下に、stanというフォルダがあり、その中に、Binom.stanというstanファイルがある前提です。
エラーの多くは、全然別の場所を指定している場合がほとんどなので、
setwd(" 作業ディレクトリの場所 ") で変更してあげると良いでしょう。
個人的な感覚ですが、エラーで動きませんと言われて、けっこうな確率で、このファイルの場所問題である場合が多いです。
対応分析(コレスポンデンス分析)の結果をバブルチャートで作図したい [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
対応分析(コレスポンデンス分析)の結果をバブルチャートで作図したいけど、どうすれば良いでしょうか?
【回答】
まずは、対応分析の結果を出します。
library(MASS)
csv.movie <- "./data/movie_count.csv"
movie <- read.csv(file=csv.movie, header=TRUE, sep=",")
ca.res <- corresp(movie.x, nf=2)
ca.res
biplot(ca.res, cex=0.6)
対応分析の結果をca.resに入れておきます。
# バブルの大きさの定義
c <- colSums(movie.x)
r <- rowSums(movie.x)
# バブルプロットの描画
symbols(ca.res$cscore[, 1], ca.res$cscore[, 2], circle = c, inches = 0.4, fg = "white", bg = "lightblue", xlab = "Dim 1", ylab = "Dim 2")
text(ca.res$cscore[, 1], ca.res$cscore[, 2], colnames(movie.x))
par(new=T)
symbols(ca.res$rscore[, 1], ca.res$rscore[, 2], circle = r, inches = 0.4, fg = "white", bg = "pink", xlab = "Dim 1", ylab = "Dim 2")
text(ca.res$rscore[, 1], ca.res$rscore[, 2], rownames(movie.x))
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
対応分析(コレスポンデンス分析)の結果をバブルチャートで作図したいけど、どうすれば良いでしょうか?
【回答】
まずは、対応分析の結果を出します。
library(MASS)
csv.movie <- "./data/movie_count.csv"
movie <- read.csv(file=csv.movie, header=TRUE, sep=",")
ca.res <- corresp(movie.x, nf=2)
ca.res
biplot(ca.res, cex=0.6)
対応分析の結果をca.resに入れておきます。
# バブルの大きさの定義
c <- colSums(movie.x)
r <- rowSums(movie.x)
# バブルプロットの描画
symbols(ca.res$cscore[, 1], ca.res$cscore[, 2], circle = c, inches = 0.4, fg = "white", bg = "lightblue", xlab = "Dim 1", ylab = "Dim 2")
text(ca.res$cscore[, 1], ca.res$cscore[, 2], colnames(movie.x))
par(new=T)
symbols(ca.res$rscore[, 1], ca.res$rscore[, 2], circle = r, inches = 0.4, fg = "white", bg = "pink", xlab = "Dim 1", ylab = "Dim 2")
text(ca.res$rscore[, 1], ca.res$rscore[, 2], rownames(movie.x))

