Google Brain [データサイエンス、統計モデル]
先日、Google Brainの人と話をする機会があった。
彼は日本人ではないけど、日本人以上に日本のことを心配していたのに驚き。
前職でも日本の将来をことを真剣に考えている人が多く、そんな会社が好きだったけど、そういう人も減ってきて、今の会社に転職をしたのだが、久々に懐かしい感じがしました。
GDPは3位だけど、実際はそうでないと思う。
しっかりとした危機感をもって行動しないと、リアル日本沈没になっていきそうな今日この頃。
コロナのピークは上がったり下がったりするし、まぁ、今後も同じ傾向が続いていく。
しかし、経済のダメージは少しずつ溜まっていって、このままでは、来年はそれがもっと進んでいくことだろう。
未来の子供たちにできることは何か真剣に考えていきたい。
彼は日本人ではないけど、日本人以上に日本のことを心配していたのに驚き。
前職でも日本の将来をことを真剣に考えている人が多く、そんな会社が好きだったけど、そういう人も減ってきて、今の会社に転職をしたのだが、久々に懐かしい感じがしました。
GDPは3位だけど、実際はそうでないと思う。
しっかりとした危機感をもって行動しないと、リアル日本沈没になっていきそうな今日この頃。
コロナのピークは上がったり下がったりするし、まぁ、今後も同じ傾向が続いていく。
しかし、経済のダメージは少しずつ溜まっていって、このままでは、来年はそれがもっと進んでいくことだろう。
未来の子供たちにできることは何か真剣に考えていきたい。
回帰分析の基礎の基礎 [データサイエンス、統計モデル]
最近、別のチームのメンバーを見ることになったのだが、元々、ML(機械学習)はできている人材。
今回、統計モデルを作ってもらうことにした。
といっても、とてもシンプルなロジスティック回帰分析。
過去の経験から、陥りやすいポイントはなんとなくわかっているのだが、今回は、まさしく、その部分に真正面から突っ込んできた。。。
やってはいけないこと。
その1 名義変数を連続値として扱うこと
男性=1, 女性=2, NA=3
という値が入っている場合、1,2,3という連続値を使ってしまうミス
その2 NAを適当な値で置換すること
例えば、年齢がNAの場合、0で置換してしまう。
この辺りは、MLしかやっていない人がよく落ちてしまうミスかなと思います。
今回、統計モデルを作ってもらうことにした。
といっても、とてもシンプルなロジスティック回帰分析。
過去の経験から、陥りやすいポイントはなんとなくわかっているのだが、今回は、まさしく、その部分に真正面から突っ込んできた。。。
やってはいけないこと。
その1 名義変数を連続値として扱うこと
男性=1, 女性=2, NA=3
という値が入っている場合、1,2,3という連続値を使ってしまうミス
その2 NAを適当な値で置換すること
例えば、年齢がNAの場合、0で置換してしまう。
この辺りは、MLしかやっていない人がよく落ちてしまうミスかなと思います。
そのとき人工知能はどう考えたのか [データサイエンス、統計モデル]
こちらの本を購入。
--そのとき人工知能はどう考えたのか? (AI/Data Science実務選書)")
KDD2016に出た時に紹介されたlimeなども書かれていました。
当時はよく分からなかったけど、こうして改めて見るとよくコンセプトがわかります。
気になる点と知れば、予測したブラックボックスをどう理解するかなのですが、どう予測するかは別問題でとなっています。
この前、インターン用に異質性を含んでいるデータセットを作ったのですが、みんなlightGBMとかで予測モデルを作ってくるけど、そもそも当たらないと。
モデルの構造自体は自分で作った上での説明可能なAIなので、この辺りを勘違いすると大きな落とし穴にハマってしまいます。
また、作者の意見と違う部分も多少あるので、まぁ、不可なく不可もなくって感じの本でした。
XAI(説明可能なAI)--そのとき人工知能はどう考えたのか? (AI/Data Science実務選書)
- 出版社/メーカー: リックテレコム
- 発売日: 2021/07/14
- メディア: 単行本
KDD2016に出た時に紹介されたlimeなども書かれていました。
当時はよく分からなかったけど、こうして改めて見るとよくコンセプトがわかります。
気になる点と知れば、予測したブラックボックスをどう理解するかなのですが、どう予測するかは別問題でとなっています。
この前、インターン用に異質性を含んでいるデータセットを作ったのですが、みんなlightGBMとかで予測モデルを作ってくるけど、そもそも当たらないと。
モデルの構造自体は自分で作った上での説明可能なAIなので、この辺りを勘違いすると大きな落とし穴にハマってしまいます。
また、作者の意見と違う部分も多少あるので、まぁ、不可なく不可もなくって感じの本でした。
カスタマのLTVを予測するためのモデリング [データサイエンス、統計モデル]
カスタマのLTVを予測することは重要なモデリング課題ですが、やってみると意外と難しい。
例えば、ほとんどが0であったり、0より大きくでも分散が大きく、通常のモデリングではあまり使い物にならないケースが多いです。
まだ、実装はできていませんが、この論文が役に立ちそう。
https://arxiv.org/pdf/1912.07753.pdf
例えば、ほとんどが0であったり、0より大きくでも分散が大きく、通常のモデリングではあまり使い物にならないケースが多いです。
まだ、実装はできていませんが、この論文が役に立ちそう。
https://arxiv.org/pdf/1912.07753.pdf
階層ベイズモデル、精度か解釈か [データサイエンス、統計モデル]
通常の線形回帰モデルではなく、階層ベイズモデルを使うメリットって何か?
大きく2つあると思います。
(1) 1つ目は、精度が向上すること。
機械学習より精度が向上する場合も多いです。
(2) 2つ目は、よりメカニズムを深く理解できること。
(1)と(2)はトレードオフの関係ですが、階層ベイズモデルをどう定式化するかにも影響を与えます。
例えば、
(model a)
観測モデル y = b1*x1 + b2*x2 + b3*x3 + ε
階層モデル b1 = a0, b1 = a1, b3 = a3
いわゆる階層モデルは切片のみのモデル。
(model b)
観測モデル y = b1*x1 + b2*x2 + ε
階層モデル b1 = a0 + a3*x3
b2 = a0 + a3*x3
b3 = a0 + a3*x3
というように x3 を観測モデルはなく、階層モデルに持っきたモデル。
変数を観測モデルか階層モデルかにするかは、さまざまな議論がありますが、
精度に着目すると、(model a)の方が精度が良いと思われます。
基本的は観測モデルの変数量で精度が決まるので。
なので、高い説明力が欲しいのか、ある程度精度を犠牲にしつつ構造の理解をしたいのかでモデリングの方向性が変わってきます。
大きく2つあると思います。
(1) 1つ目は、精度が向上すること。
機械学習より精度が向上する場合も多いです。
(2) 2つ目は、よりメカニズムを深く理解できること。
(1)と(2)はトレードオフの関係ですが、階層ベイズモデルをどう定式化するかにも影響を与えます。
例えば、
(model a)
観測モデル y = b1*x1 + b2*x2 + b3*x3 + ε
階層モデル b1 = a0, b1 = a1, b3 = a3
いわゆる階層モデルは切片のみのモデル。
(model b)
観測モデル y = b1*x1 + b2*x2 + ε
階層モデル b1 = a0 + a3*x3
b2 = a0 + a3*x3
b3 = a0 + a3*x3
というように x3 を観測モデルはなく、階層モデルに持っきたモデル。
変数を観測モデルか階層モデルかにするかは、さまざまな議論がありますが、
精度に着目すると、(model a)の方が精度が良いと思われます。
基本的は観測モデルの変数量で精度が決まるので。
なので、高い説明力が欲しいのか、ある程度精度を犠牲にしつつ構造の理解をしたいのかでモデリングの方向性が変わってきます。
階層ベイズ線形回帰モデルの対数尤度関数 [データサイエンス、統計モデル]
bayesmとかstanを使ってMCMCをする場合は楽なのですが、自分で尤度関数を作ってメトロポリスヘイスティングなりを作る場合の落とし穴。
正規分布の対数尤度関数を与える必要があるのですが、うっかりミスをしていました。
loglike <- function(y, X, param) {
ll <- sum( ( y - X %*% param )^2 )
}
optimとかに入れて計算する場合は上記で良いのですが・・・
正しくは、sumの前にマイナスが必要で
loglike <- function(y, X, param) {
ll <- -sum( ( y - X %*% param )^2 )
}
としないと値が収束しない。
正規分布の対数尤度関数を与える必要があるのですが、うっかりミスをしていました。
loglike <- function(y, X, param) {
ll <- sum( ( y - X %*% param )^2 )
}
optimとかに入れて計算する場合は上記で良いのですが・・・
正しくは、sumの前にマイナスが必要で
loglike <- function(y, X, param) {
ll <- -sum( ( y - X %*% param )^2 )
}
としないと値が収束しない。
【階層ベイズモデル】パラメータの収束 [データサイエンス、統計モデル]
通常の線形回帰モデルと階層ベイズモデルの2種類モデルを作って精度を比較すると、通常は階層ベイズモデルの方が精度が良いはずなのに、あまり精度があがらない。
はて?と思い・・・
(1)log-likelihoodのプロットを書いてみる
イテレーション回数を増やすても、激しく向上し続ける。
通常は、10万回くらいMCMCを増やしても爆上がりし続けるので何かおかしい。
(2)Deltaの統計値を書いてみると・・・
なるほど!と。
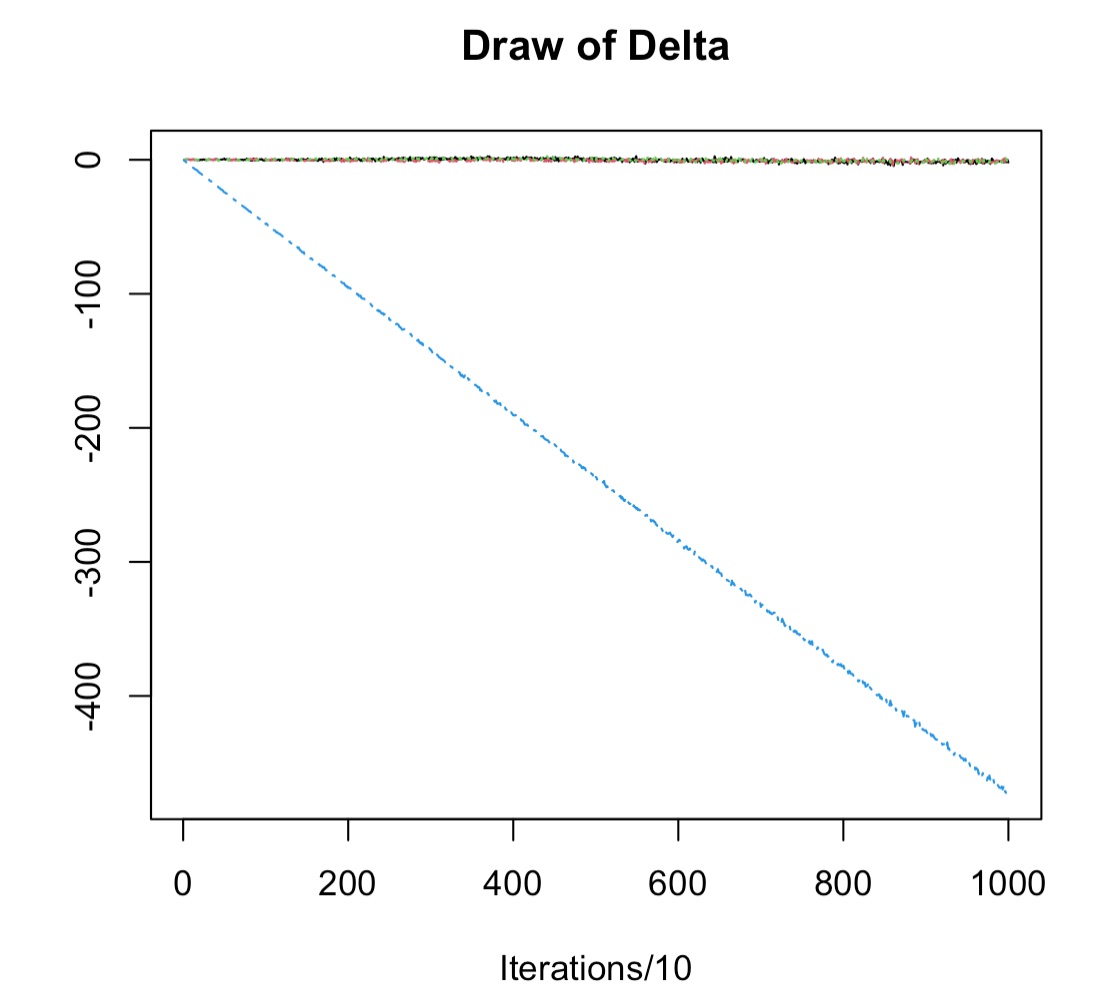
つまり、こういうこと。
回帰係数の推定値だけど
b1: 0.12
b2: 0.23
b3: 0.34
b4: 560000
みたいな場合、0付近から探索をしたとしても、b4がなかなか収束しない!
というのが原因でした。
そこで、x4の値を適当にスケールすると、無事収束しました。
つまり、
b1: 0.12
b2: 0.23
b3: 0.34
b4: 0.56
みたいになるように事前に調整しておくと良さそうです。
はて?と思い・・・
(1)log-likelihoodのプロットを書いてみる
イテレーション回数を増やすても、激しく向上し続ける。
通常は、10万回くらいMCMCを増やしても爆上がりし続けるので何かおかしい。
(2)Deltaの統計値を書いてみると・・・
なるほど!と。
つまり、こういうこと。
回帰係数の推定値だけど
b1: 0.12
b2: 0.23
b3: 0.34
b4: 560000
みたいな場合、0付近から探索をしたとしても、b4がなかなか収束しない!
というのが原因でした。
そこで、x4の値を適当にスケールすると、無事収束しました。
つまり、
b1: 0.12
b2: 0.23
b3: 0.34
b4: 0.56
みたいになるように事前に調整しておくと良さそうです。
標準回帰係数の求め方 [データサイエンス、統計モデル]
方法は、2種類あって、
[その1]
回帰分析をする前に、変数自体を標準化する方法。
df2 <- scale( df )
とすれば、OKです。
[その2]
出てきた結果に、標準偏差をかける方法
sapply(df, sd)
本当は、目的変数の不偏標準偏差で割る必要があるのですが、
各変数同士横比較をするだけなら、共通して割ることになるので、分母は省略することができます。
[その1]
回帰分析をする前に、変数自体を標準化する方法。
df2 <- scale( df )
とすれば、OKです。
[その2]
出てきた結果に、標準偏差をかける方法
sapply(df, sd)
本当は、目的変数の不偏標準偏差で割る必要があるのですが、
各変数同士横比較をするだけなら、共通して割ることになるので、分母は省略することができます。
予測モデル、古い物件ほど価格が高くなる!? [データサイエンス、統計モデル]
中古マンションの価格を予測すると
築年数が古い方がマンションの価格が高くなるという結果になる場合があります。
実際に、古くなるにつれマンション価格が上がるということも考えられなくはないのですが、レアケースかと思われます。
そこで、他の変数の影響を考えてみると・・・
ここ最近、新築、中古ともに物件価格が上がっており
古い物件 = 最近の物件
と考えられますね。
最初のモデルの欠点としては、時間と共に効果が一定であったと考えてしまったところです。
回帰変数は、固定の値ではなく時変の変数であると考えるとこのあたり解決できそうです。
築年数が古い方がマンションの価格が高くなるという結果になる場合があります。
実際に、古くなるにつれマンション価格が上がるということも考えられなくはないのですが、レアケースかと思われます。
そこで、他の変数の影響を考えてみると・・・
ここ最近、新築、中古ともに物件価格が上がっており
古い物件 = 最近の物件
と考えられますね。
最初のモデルの欠点としては、時間と共に効果が一定であったと考えてしまったところです。
回帰変数は、固定の値ではなく時変の変数であると考えるとこのあたり解決できそうです。
IBM SPSS Modeler User Conference 2021 Autumn [データサイエンス、統計モデル]
めっきりSPSSは使わなくなってしまったのと、手を動かす仕事からマネージメント主体の仕事に変わっていることもあり、少し違った視点で見ていました。
100%そうだよねと思う部分と、自分ならこう考えるというのは、企業のレベルやそこにいる人材層による違いなのかもしれません。
最近感じることは、ものすごくマーケティングができる人に対して、さらっと分析してみました的なことをしても全く動いてくれないわけで、彼ら以上に高いレベルで顧客の解像度を上げていく必要があります。
そのためには家庭料理レベルから会席料理レベルへ解析技術を上げいくことも必要だと思っています。
100%そうだよねと思う部分と、自分ならこう考えるというのは、企業のレベルやそこにいる人材層による違いなのかもしれません。
最近感じることは、ものすごくマーケティングができる人に対して、さらっと分析してみました的なことをしても全く動いてくれないわけで、彼ら以上に高いレベルで顧客の解像度を上げていく必要があります。
そのためには家庭料理レベルから会席料理レベルへ解析技術を上げいくことも必要だと思っています。
A framework for massive scale personalized promotion [データサイエンス、統計モデル]
A framework for massive scale personalized promotion
https://arxiv.org/pdf/2108.12100.pdf
アップリフトモデルみたいにキャンペーンの効果をどう計算するかというのは重要なテーマ。
そこに単調性などの条件を数学的な最適化で補正しようというアイデア。
このあたりよくやっているアプローチなのですが、論文になっていました。
https://arxiv.org/pdf/2108.12100.pdf
アップリフトモデルみたいにキャンペーンの効果をどう計算するかというのは重要なテーマ。
そこに単調性などの条件を数学的な最適化で補正しようというアイデア。
このあたりよくやっているアプローチなのですが、論文になっていました。
2021秋の行動計量セミナー [データサイエンス、統計モデル]
今回のテーマは、「はじめての機械学習: 機械学習の基礎から深層学習まで」でした。
状態空間モデルをテーマにしたセミナーに参加してともて分かりやすかったので、今回も参加してみる予定です。
日本行動計量学会 2021秋の行動計量セミナー
http://michioyamamoto.com/event/index.php/bsj/autumn2021
田口善弘著「はじめての機械学習 中学数学でわかるAIのエッセンス (ブルーバックス)」が教科書なので、事前に買っておきます。
")
状態空間モデルをテーマにしたセミナーに参加してともて分かりやすかったので、今回も参加してみる予定です。
日本行動計量学会 2021秋の行動計量セミナー
http://michioyamamoto.com/event/index.php/bsj/autumn2021
田口善弘著「はじめての機械学習 中学数学でわかるAIのエッセンス (ブルーバックス)」が教科書なので、事前に買っておきます。
はじめての機械学習 中学数学でわかるAIのエッセンス (ブルーバックス)
- 作者: 田口善弘
- 出版社/メーカー: 講談社
- 発売日: 2021/07/14
- メディア: Kindle版
Pythonによる因果分析 [データサイエンス、統計モデル]
「Pythonによる因果分析」を購入しました。
")
因果推論の教科書は何冊か持っているのですが、実際にpythonコードとセットで解説されている本があまりなかったです。
実際に、届いて読み始めていますが、内容としてはかなり基礎部分から書かれているかなと思っています。
また、実際のコードもGoogle Colabを使って紹介されているのでセットアップなど面倒な作業も不要でした。
つくりながら学ぶ! Pythonによる因果分析 ~因果推論・因果探索の実践入門 (Compass Data Science)
- 作者: 小川雄太郎
- 出版社/メーカー: マイナビ出版
- 発売日: 2020/06/30
- メディア: 単行本(ソフトカバー)
因果推論の教科書は何冊か持っているのですが、実際にpythonコードとセットで解説されている本があまりなかったです。
実際に、届いて読み始めていますが、内容としてはかなり基礎部分から書かれているかなと思っています。
また、実際のコードもGoogle Colabを使って紹介されているのでセットアップなど面倒な作業も不要でした。
離反について深く理解する輪読会 [データサイエンス、統計モデル]
Fighting Churn with Data
https://www.manning.com/books/fighting-churn-with-data
社内で、離反に関するニーズが高まっており、それに伴って勉強会をすることにしました。
ボリュームはあるので、いくつか章を絞って読んでみようかと思います。
興味がある人はお気軽に参加してみてください。
https://www.manning.com/books/fighting-churn-with-data
社内で、離反に関するニーズが高まっており、それに伴って勉強会をすることにしました。
ボリュームはあるので、いくつか章を絞って読んでみようかと思います。
興味がある人はお気軽に参加してみてください。
【R】lavaan ERROR: missing observed variables in dataset: [データサイエンス、統計モデル]
lavaanは、パス解析とかSEM(共分散構造分析)などができる優秀なパッケージです。
lavaanを使った分析で出てきたエラー。
意味をみれば、そんな変数はデータセットにないよってことなのですが、確かにその変数はあるはず・・・
よーくみると、O(オー)と0(ゼロ)の違いでした
最近、老眼が進んでいるのか、夜になると細かい文字が見えにくくなります。(;_;)
lavaanを使った分析で出てきたエラー。
意味をみれば、そんな変数はデータセットにないよってことなのですが、確かにその変数はあるはず・・・
よーくみると、O(オー)と0(ゼロ)の違いでした
最近、老眼が進んでいるのか、夜になると細かい文字が見えにくくなります。(;_;)
同時確率と条件付き確率 その2 周辺化 [データサイエンス、統計モデル]
下記の問題を考えたとします。
1. 袋が2つあり、袋aには赤玉3個、青玉7個。袋bには赤玉5個、青玉4個。
2. まず、袋a,bを決めて、玉を取る時、赤玉が選ばれる確率は?
【アプローチ1】
素直に条件付き確率で計算する場合
p(x): 袋a, bを選択する確率、1/2
p(y): 赤玉を選択する確率
p(x, y) = p(x|y)*p(y)より
袋aが選択されて赤玉が選ばれる確率は
3/10 * 1/2 = 0.15
袋bが選択されて赤玉が選ばれる確率は
5/9 * 1/2 = 0.2777778
よって、赤玉がえらばる確率は、0.15+0.28=0.4277778
【アプローチ2】
袋a, bが選ばれる確率が等しいので、袋を一つにして
(3+5)/(10+9)=0.4210526
ということで、
【アプローチ1】の結果 ≠ 【アプローチ2】の結果
となりました。
選ばれる確率が等しくても、分母が違うと上手くいきません。
算数(数学)的考えてみると
3/10 * 1/2 + 5/9 * 1/2
= (3/10 + 5/9) * 1/2
(3/10 + 5/9) を (3+5)/(10+9) と計算してはダメなのは、小学生の分数で理解できます。
このように赤玉が出る確率を袋a, bと分けて考えていく考えが、ベイズ統計の第一歩である周辺化(周辺確率)につながっていきます。
1. 袋が2つあり、袋aには赤玉3個、青玉7個。袋bには赤玉5個、青玉4個。
2. まず、袋a,bを決めて、玉を取る時、赤玉が選ばれる確率は?
【アプローチ1】
素直に条件付き確率で計算する場合
p(x): 袋a, bを選択する確率、1/2
p(y): 赤玉を選択する確率
p(x, y) = p(x|y)*p(y)より
袋aが選択されて赤玉が選ばれる確率は
3/10 * 1/2 = 0.15
袋bが選択されて赤玉が選ばれる確率は
5/9 * 1/2 = 0.2777778
よって、赤玉がえらばる確率は、0.15+0.28=0.4277778
【アプローチ2】
袋a, bが選ばれる確率が等しいので、袋を一つにして
(3+5)/(10+9)=0.4210526
ということで、
【アプローチ1】の結果 ≠ 【アプローチ2】の結果
となりました。
選ばれる確率が等しくても、分母が違うと上手くいきません。
算数(数学)的考えてみると
3/10 * 1/2 + 5/9 * 1/2
= (3/10 + 5/9) * 1/2
(3/10 + 5/9) を (3+5)/(10+9) と計算してはダメなのは、小学生の分数で理解できます。
このように赤玉が出る確率を袋a, bと分けて考えていく考えが、ベイズ統計の第一歩である周辺化(周辺確率)につながっていきます。
同時確率と条件付き確率 その1 シンプルな問題設定 [データサイエンス、統計モデル]
下記の問題を考えたとします。
1. 袋が2つあり、袋aには赤玉3個、青玉7個。袋bには赤玉5個、青玉5個。
2. まず、袋a,bを決めて、玉を取る時、赤玉が選ばれる確率は?
【アプローチ1】
素直に条件付き確率で計算する場合
p(x): 袋a, bを選択する確率、1/2
p(y): 赤玉を選択する確率
p(x, y) = p(x|y)*p(y)より
袋aが選択されて赤玉が選ばれる確率は
3/10 * 1/2 = 0.15
袋bが選択されて赤玉が選ばれる確率は
5/10 * 1/2 = 0.25
よって、赤玉がえらばる確率は、0.15+0.25=0.4
【アプローチ2】
袋a, bが選ばれる確率が等しいので、袋を一つにして
(3+5)/(10+10)=0.4
とシンプルに考えても良さそうですね。
1. 袋が2つあり、袋aには赤玉3個、青玉7個。袋bには赤玉5個、青玉5個。
2. まず、袋a,bを決めて、玉を取る時、赤玉が選ばれる確率は?
【アプローチ1】
素直に条件付き確率で計算する場合
p(x): 袋a, bを選択する確率、1/2
p(y): 赤玉を選択する確率
p(x, y) = p(x|y)*p(y)より
袋aが選択されて赤玉が選ばれる確率は
3/10 * 1/2 = 0.15
袋bが選択されて赤玉が選ばれる確率は
5/10 * 1/2 = 0.25
よって、赤玉がえらばる確率は、0.15+0.25=0.4
【アプローチ2】
袋a, bが選ばれる確率が等しいので、袋を一つにして
(3+5)/(10+10)=0.4
とシンプルに考えても良さそうですね。
qini(キニ)とgini(ジニ)の違い [データサイエンス、統計モデル]
qini_auc_scoreというのを見た時、あれginiの間違いと思ったのですが、調べてみるとqiniで正解。
どちらも計算方法は似ていますが、同じではない。
どちらもAUCスコアがあります。
gini:収入の完全な平等、常に45度
qini:ランダムな隆起、常に45度の値とは限らない
gini:実績値と神様モデルの面積差で、神様モデルによって正規化
qini:実績値とランダムの面積差で、神様モデルによって正規化
https://www.uplift-modeling.com/en/latest/api/metrics/qini_auc_score.html
どちらも計算方法は似ていますが、同じではない。
どちらもAUCスコアがあります。
gini:収入の完全な平等、常に45度
qini:ランダムな隆起、常に45度の値とは限らない
gini:実績値と神様モデルの面積差で、神様モデルによって正規化
qini:実績値とランダムの面積差で、神様モデルによって正規化
https://www.uplift-modeling.com/en/latest/api/metrics/qini_auc_score.html
R stanをM1 MAC OS(big sur)にインストール [データサイエンス、統計モデル]
ここの手順に従ってインストールしていきます。
インストールガイド
https://github.com/stan-dev/rstan/wiki/RStan-Getting-Started-(Japanese)
1. RStanのインストール
install.packages('rstan', repos='https://cloud.r-project.org/', dependencies=TRUE)
エラーなく、無事に終了
2. C++コンパイラ
pkgbuild::has_build_tools(debug = TRUE)
[1] TRUE
となり、特に問題なし
3. RStanの実行テスト
ということで、M1チップになったことで、MCMCも劇的に早くなりました!
インストールガイド
https://github.com/stan-dev/rstan/wiki/RStan-Getting-Started-(Japanese)
1. RStanのインストール
install.packages('rstan', repos='https://cloud.r-project.org/', dependencies=TRUE)
エラーなく、無事に終了
2. C++コンパイラ
pkgbuild::has_build_tools(debug = TRUE)
[1] TRUE
となり、特に問題なし
3. RStanの実行テスト
library(rstan)
# 並列処理
options(mc.cores = parallel::detectCores())
rstan_options(auto_write = TRUE)
# データの準備
A.sales <- c(1000, 980, 1200, 1260, 1500, 1005, 820, 1490, 1500, 960)
B.sales <- c(880, 1080, 1580, 2180, 1900, 1950, 1200, 910, 2100, 1890)
sales <- c(A.sales, B.sales)
campaign.B <- c(rep(0,length(A.sales)), rep(1,length(B.sales)))
data_stan_ttest <- list(N=length(sales), sales=sales, campaignB=campaign.B)
data_stan_ttest
# stan モデルの定義
stan_code <- '
data{
int N;
int campaignB[N];
real sales[N];
}
parameters{
real mean_All;
real effect_B;
real sigma;
}
model{
for(n in 1:N){
sales[n] ~ normal(mean_All+effect_B*campaignB[n], sigma);
}
}
'
model.mcmc = rstan::stan_model(model_code = stan_code)
# MCMCサンプリング
res_mcmc_ttest <- rstan::sampling(model.mcmc, data = data_stan_ttest, iter = 10000, chains = 4)
# 結果の確認
res_mcmc_ttest
stan_hist(res_mcmc_ttest, pars=c("mean_All","effect_B", "sigma"))
mean(rstan::extract(res_mcmc_ttest)$effect_B<=0)
ということで、M1チップになったことで、MCMCも劇的に早くなりました!
状態空間モデルで欠損値の扱い方 [データサイエンス、統計モデル]
最近、とあるデータに対して状態空間モデルを適用しました。
このデータ、ある時点で、予測値が急激に下振れるポイントが存在します。
例えば、台風とか地震とかが原因と仮定します。
そのまま状態空間モデルで推定すると、その前後でトレンドが減少しているような予測なってしまう。
普通に考えるとそうなるのも自然なのですが、欲しい結果としては、
その事象が起こるまでは、既存のトレンドを引き継いで、その事象が起こるとトレンドが変化するような構造にしたい。
このような場合の対処法として、
・説明変数変数を入れて補正する
・その区間のデータがなかったものとして(欠損値扱いにして)処理をする
が考えられます。
試してみたところ、どちらも上手く推定できていました。
通常のARIMAモデルとかだと欠損値があると推定できないけど、状態空間モデルの枠組みだと、このようなデータに関しても扱えるのが便利かなと思います。
ちなみに、プログラムは、stanを使って推定しました。
このデータ、ある時点で、予測値が急激に下振れるポイントが存在します。
例えば、台風とか地震とかが原因と仮定します。
そのまま状態空間モデルで推定すると、その前後でトレンドが減少しているような予測なってしまう。
普通に考えるとそうなるのも自然なのですが、欲しい結果としては、
その事象が起こるまでは、既存のトレンドを引き継いで、その事象が起こるとトレンドが変化するような構造にしたい。
このような場合の対処法として、
・説明変数変数を入れて補正する
・その区間のデータがなかったものとして(欠損値扱いにして)処理をする
が考えられます。
試してみたところ、どちらも上手く推定できていました。
通常のARIMAモデルとかだと欠損値があると推定できないけど、状態空間モデルの枠組みだと、このようなデータに関しても扱えるのが便利かなと思います。
ちなみに、プログラムは、stanを使って推定しました。
IBM SPSS Modeler、条件付きレコード結合 [データサイエンス、統計モデル]
SPSSブログの記事です。
Modelerデータ加工Tips
#14-条件付きレコード結合で売り手と買い手のマッチング
https://www.ibm.com/blogs/solutions/jp-ja/modeler-tips-14/
最近、環境の変化でSPSS Modelerはほとんど使うことがなくなったのですが、個人的にはとても良い製品だと思っています。
これからも多くの企業のデータサイエンス業務をサポートし続ける製品になるでしょう。
Modelerデータ加工Tips
#14-条件付きレコード結合で売り手と買い手のマッチング
https://www.ibm.com/blogs/solutions/jp-ja/modeler-tips-14/
最近、環境の変化でSPSS Modelerはほとんど使うことがなくなったのですが、個人的にはとても良い製品だと思っています。
これからも多くの企業のデータサイエンス業務をサポートし続ける製品になるでしょう。
バイナリデータの因子分析 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
0,1データ(バイナリデータ)に対して因子分析(共分散構造分析)をしたい。
【回答】
まず、0,1データに対して、通常の方法で因子分析ができないというのは注意した方がいいところ。
このあたり理解していなくて、バイナリデータに対して、そのまま因子分析をかけてしまうケースがあります。
理由は、相関係数がきちんと計算できないから。
【統計の質問】名義変数(カテゴリカルデータ)の相関分析
https://skellington.blog.ss-blog.jp/2019-02-01
↑
このようにきちんと相関係数を計算することができれば、そのデータ(相関行列)を使って因子分析をすることができます。
library(polycor)
library(lavaan)
library(psych)
# 相関係数の比較
with(dat, polychor(x1, x2, ML=TRUE))
with(dat, cor(x1, x2))
# 0,1データをファクタ型に変換する
dat_2 <- sapply(dat, as.factor)
# 相関係数を計算する
het.mat <- hetcor(dat2)$cor
# 因子分析
fa.parallel(het.mat1)
# fa.1 <- fa(r = het.mat, nfactors = 2, n.obs = nrow(dat2), rotate = "varimax")
# fa.1
fa.2 <- factanal(covmat = het.mat, factors = 2, rotation = "varimax")
fa.2
plot(fa.2$loadings[,1:2], type="n")
text(fa.2$loadings[,1:2], colnames(fa.2))
# 因子得点を計算
result <- as.matrix(dat) %*% solve(het.mat) %*% fa.2$loadings
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
0,1データ(バイナリデータ)に対して因子分析(共分散構造分析)をしたい。
【回答】
まず、0,1データに対して、通常の方法で因子分析ができないというのは注意した方がいいところ。
このあたり理解していなくて、バイナリデータに対して、そのまま因子分析をかけてしまうケースがあります。
理由は、相関係数がきちんと計算できないから。
【統計の質問】名義変数(カテゴリカルデータ)の相関分析
https://skellington.blog.ss-blog.jp/2019-02-01
↑
このようにきちんと相関係数を計算することができれば、そのデータ(相関行列)を使って因子分析をすることができます。
library(polycor)
library(lavaan)
library(psych)
# 相関係数の比較
with(dat, polychor(x1, x2, ML=TRUE))
with(dat, cor(x1, x2))
# 0,1データをファクタ型に変換する
dat_2 <- sapply(dat, as.factor)
# 相関係数を計算する
het.mat <- hetcor(dat2)$cor
# 因子分析
fa.parallel(het.mat1)
# fa.1 <- fa(r = het.mat, nfactors = 2, n.obs = nrow(dat2), rotate = "varimax")
# fa.1
fa.2 <- factanal(covmat = het.mat, factors = 2, rotation = "varimax")
fa.2
plot(fa.2$loadings[,1:2], type="n")
text(fa.2$loadings[,1:2], colnames(fa.2))
# 因子得点を計算
result <- as.matrix(dat) %*% solve(het.mat) %*% fa.2$loadings
階層ベイズで○○予測 [データサイエンス、統計モデル]
とある商材を階層ベイズを使って予測をしたところ、劇的に精度がよくなった。
通常の線形回帰とかロジスティック回帰とかだと、あまり精度がでないので、機械学習を使ってkaggle的な感じでする人が多いと思う。
それはそれで良いと思うけど、データの特性によったら階層ベイズの方がより精度が出る場合があるんじゃないかって最近思う。
例えば、同じidの人のデータがたくさんあるとか、ある程度のセグメントで重要な特徴量が異なるとか。
比べてみると、機械学習以上の予測精度になるし、ブラックボックスモデルではない。
ただ、計算する時間が少しかかるのと、それなりの統計の知識が必要ってハードルはあるけど、試してみる価値は大きいと思う。
通常の線形回帰とかロジスティック回帰とかだと、あまり精度がでないので、機械学習を使ってkaggle的な感じでする人が多いと思う。
それはそれで良いと思うけど、データの特性によったら階層ベイズの方がより精度が出る場合があるんじゃないかって最近思う。
例えば、同じidの人のデータがたくさんあるとか、ある程度のセグメントで重要な特徴量が異なるとか。
比べてみると、機械学習以上の予測精度になるし、ブラックボックスモデルではない。
ただ、計算する時間が少しかかるのと、それなりの統計の知識が必要ってハードルはあるけど、試してみる価値は大きいと思う。
r subsetで条件抽出する際の注意点 [データサイエンス、統計モデル]
論理 OR : |
論理 AND : &
が正しい書き方。
うっかり、||とか&&と書いてしまうと、正しく条件抽出ができません。
しかも、エラーが出てこないのが、やっかい。
エラー出てくれたら気がつくんですけど・・・。
論理 AND : &
が正しい書き方。
うっかり、||とか&&と書いてしまうと、正しく条件抽出ができません。
しかも、エラーが出てこないのが、やっかい。
エラー出てくれたら気がつくんですけど・・・。
マハラノビス距離を利用した異常検知の応用 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
マハラノビス距離を使った異常検知をしました。
二変数の相関から異常値を検知するというのは理解しました。
では、全ての説明変数を使って何らか異常値を検知する方法はありますか?
【回答】
なるほど・・・と少し悩みましたが、こういうのはどうでしょうか?
目的変数yに対して、ロジットモデルor線形回帰モデルを行います。
ここまでは、通常のアプローチと同じ。
一方で、階層ベイズのアプローチを使えば、各個人ごと(各セグメントごと)に回帰係数を計算できます。
各回帰係数の分布を見ることで、異常値を出している人を理解できます。
ただ、異常値と書くとなんだか他の人と違う外れ値的な感じがするのですが、
マーケティング的には異常値と言うよりかは、異質性という言い方します。
特に、インターネットのマーケティングにおいては、異質性を考慮した1to1マーケティングが求められています。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
マハラノビス距離を使った異常検知をしました。
二変数の相関から異常値を検知するというのは理解しました。
では、全ての説明変数を使って何らか異常値を検知する方法はありますか?
【回答】
なるほど・・・と少し悩みましたが、こういうのはどうでしょうか?
目的変数yに対して、ロジットモデルor線形回帰モデルを行います。
ここまでは、通常のアプローチと同じ。
一方で、階層ベイズのアプローチを使えば、各個人ごと(各セグメントごと)に回帰係数を計算できます。
各回帰係数の分布を見ることで、異常値を出している人を理解できます。
ただ、異常値と書くとなんだか他の人と違う外れ値的な感じがするのですが、
マーケティング的には異常値と言うよりかは、異質性という言い方します。
特に、インターネットのマーケティングにおいては、異質性を考慮した1to1マーケティングが求められています。
【R】corとcor.testの違い [データサイエンス、統計モデル]
【質問】
cor.test.default( ) でエラー: でエラー:
引数 "y" がありませんし、省略時既定値もありません
原因は何ですか?
【回答】
まず、corとcor.testの違いから。
iris[, 1:4]と使います。
cor(iris[, 1:4])を計算すると
> cor(iris[, 1:4])
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411
Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259
Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654
Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000
となり、それぞれの変数の相関係数が出てきます。
cor.testは、それぞれの相関係数に対し、相関係数の検定をしています。
すなわち、H0:相関係数は0 (2変数間は無相関)
細かい数字が出てくるため、1つのペア同士しか検定できません。
膨大に色々な統計量が出てくると見難いので。
例えば、Sepal.LengthとSepal.Widthの検定をしたい場合は、
cor.test(iris[, "Sepal.Length"], iris[, "Sepal.Width"])
と書きましょう。
> cor.test(iris[, "Sepal.Length"], iris[, "Sepal.Width"])
Pearson's product-moment correlation
data: iris[, "Sepal.Length"] and iris[, "Sepal.Width"]
t = -1.4403, df = 148, p-value = 0.1519
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.27269325 0.04351158
sample estimates:
cor
-0.1175698
この場合、p値がp-value = 0.1519とやや高いですね。
なので、帰無仮説を棄却できない。
つまり、相関係数は0でないとは言えない(2変数間は無相関とは言えない)となります。
相関係数は0である(2変数間は無相関である)と言っているわけではないので注意が必要です。
p値が十分に小さい時、例えば、0.05未満だと帰無仮説が棄却され、対立仮説が採択されます。
この場合は、
H1:相関係数は0でない (2変数間は無相関でない)、つまり、相関があると自然に答えることができます。
H0の場合は、自然な解釈がしづらいのが、検定の欠点でもあります。
cor.test.default( ) でエラー: でエラー:
引数 "y" がありませんし、省略時既定値もありません
原因は何ですか?
【回答】
まず、corとcor.testの違いから。
iris[, 1:4]と使います。
cor(iris[, 1:4])を計算すると
> cor(iris[, 1:4])
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411
Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259
Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654
Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000
となり、それぞれの変数の相関係数が出てきます。
cor.testは、それぞれの相関係数に対し、相関係数の検定をしています。
すなわち、H0:相関係数は0 (2変数間は無相関)
細かい数字が出てくるため、1つのペア同士しか検定できません。
膨大に色々な統計量が出てくると見難いので。
例えば、Sepal.LengthとSepal.Widthの検定をしたい場合は、
cor.test(iris[, "Sepal.Length"], iris[, "Sepal.Width"])
と書きましょう。
> cor.test(iris[, "Sepal.Length"], iris[, "Sepal.Width"])
Pearson's product-moment correlation
data: iris[, "Sepal.Length"] and iris[, "Sepal.Width"]
t = -1.4403, df = 148, p-value = 0.1519
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.27269325 0.04351158
sample estimates:
cor
-0.1175698
この場合、p値がp-value = 0.1519とやや高いですね。
なので、帰無仮説を棄却できない。
つまり、相関係数は0でないとは言えない(2変数間は無相関とは言えない)となります。
相関係数は0である(2変数間は無相関である)と言っているわけではないので注意が必要です。
p値が十分に小さい時、例えば、0.05未満だと帰無仮説が棄却され、対立仮説が採択されます。
この場合は、
H1:相関係数は0でない (2変数間は無相関でない)、つまり、相関があると自然に答えることができます。
H0の場合は、自然な解釈がしづらいのが、検定の欠点でもあります。
Python 初心者向けの開発環境をセットアップする [データサイエンス、統計モデル]
Visual Studio Code を使用して Python 初心者向けの開発環境をセットアップする
https://docs.microsoft.com/ja-jp/learn/modules/python-install-vscode/
やったこと
・Visual Studio Codeのインストール
・日本語化
・Python拡張機能をインストール
https://docs.microsoft.com/ja-jp/learn/modules/python-install-vscode/
やったこと
・Visual Studio Codeのインストール
・日本語化
・Python拡張機能をインストール
ヘッドスタート(Head Start)のデータを使ったパス解析 [データサイエンス、統計モデル]
単回帰の回帰係数や相関係数は正(or 負)にもかかわらず、重回帰分析をすると回帰係数が逆転し負(or 正)になっている場合があります。
色々な原因があり、一つの可能性としては多重共線性が考えられます。
多重共線性ではない場合、どう考えれば良いか?
ヘッドスタート(Head Start)のデータを使ったパス解析をしたいと思います。
■ データ
HS: 学習プログラムの参加
SES: 親の社会的地位
COG: プログラム終了後の認知能力
■ 相関係数
HS SES COG
HS 1.00 -0.41 -0.10
SES -0.41 1.00 0.52
COG -0.10 0.52 1.00
これによると、HSを受けるとCOGが-0.10となっています。
つまり、学習プログラムに参加すると認知能力が下がるということです。
感覚と違いますね。
■ パス解析
社会的地位が高い家庭はそもそも学習プログラムに参加しにくい傾向があります。
この影響を取り除かないと学習プログラムの効果がわかりません。
そこでパス解析を実施します。
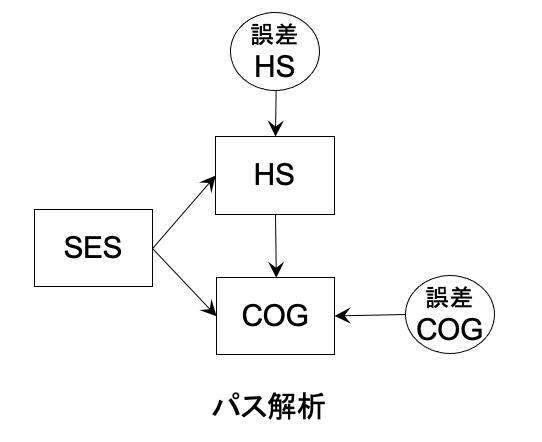
これは、SESの影響を統制した時に、HSとCOGの関係を見ていることになります。
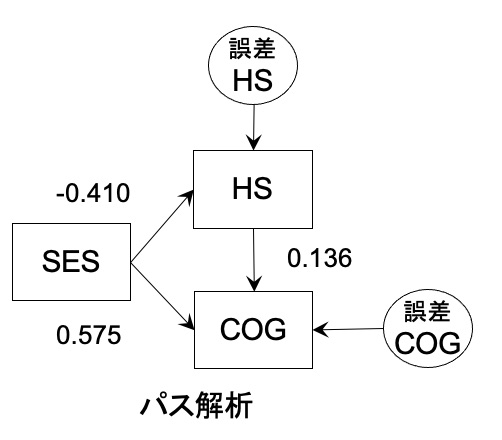
結果は、HSプログラムに参加するほどCOGが高くなる(0.136)となっていました。
色々な原因があり、一つの可能性としては多重共線性が考えられます。
多重共線性ではない場合、どう考えれば良いか?
ヘッドスタート(Head Start)のデータを使ったパス解析をしたいと思います。
■ データ
HS: 学習プログラムの参加
SES: 親の社会的地位
COG: プログラム終了後の認知能力
■ 相関係数
HS SES COG
HS 1.00 -0.41 -0.10
SES -0.41 1.00 0.52
COG -0.10 0.52 1.00
これによると、HSを受けるとCOGが-0.10となっています。
つまり、学習プログラムに参加すると認知能力が下がるということです。
感覚と違いますね。
■ パス解析
社会的地位が高い家庭はそもそも学習プログラムに参加しにくい傾向があります。
この影響を取り除かないと学習プログラムの効果がわかりません。
そこでパス解析を実施します。
これは、SESの影響を統制した時に、HSとCOGの関係を見ていることになります。
結果は、HSプログラムに参加するほどCOGが高くなる(0.136)となっていました。
検定で使う効果量とは? [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
検定で使う効果量ってなんですか?
【回答】
p値はサンプルサイズによって影響を受けてしまいます。
サンプルサイズが大きくなるとp値は小さくなります。
わずかな効果量であっても差があるとなってしまうので、それがビジネス的なインパクトがあるかといった指標が必要なのですが、そこで登場するのが効果量と言われるものです。
基本的には、二つの平均値の差を取ったものと考えて良いのですが、平均値の差を取るだけだと単位に依存してしまいます。
kgとgといった単位の影響を除外したい。
そこで、平均値の差を標準偏差で割って標準化したものが効果量となります。
ちなみに、効果量は、「d族」と「r族」があります。
d族は、差の大きさを表現したもので、r族は相関の強さを表現したものとなっています。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
検定で使う効果量ってなんですか?
【回答】
p値はサンプルサイズによって影響を受けてしまいます。
サンプルサイズが大きくなるとp値は小さくなります。
わずかな効果量であっても差があるとなってしまうので、それがビジネス的なインパクトがあるかといった指標が必要なのですが、そこで登場するのが効果量と言われるものです。
基本的には、二つの平均値の差を取ったものと考えて良いのですが、平均値の差を取るだけだと単位に依存してしまいます。
kgとgといった単位の影響を除外したい。
そこで、平均値の差を標準偏差で割って標準化したものが効果量となります。
ちなみに、効果量は、「d族」と「r族」があります。
d族は、差の大きさを表現したもので、r族は相関の強さを表現したものとなっています。
Rによる極値統計学 [データサイエンス、統計モデル]
Rによる極値統計学
https://www.ism.ac.jp/lectures/2021a.html
久々の極値統計学。
理論的にも美しく、最大値(最小値)を集めてくると、ガンベル型、フレシェ型、ワイブル型に収束するという性質があります。
Rでのパッケージも充実しているので、裾野は広まってきているかなと。
あとは、応用ですが、みんな平均的なものの扱いは慣れているけど、最大値を集めてきて、どう使えるのか?という部分に関しては、まだまだ応用先が限定的な気がします。
アイデア次第で、意外と身近な分野に応用できると思うので、いろいろ研究してみたいと思います。
https://www.ism.ac.jp/lectures/2021a.html
久々の極値統計学。
理論的にも美しく、最大値(最小値)を集めてくると、ガンベル型、フレシェ型、ワイブル型に収束するという性質があります。
Rでのパッケージも充実しているので、裾野は広まってきているかなと。
あとは、応用ですが、みんな平均的なものの扱いは慣れているけど、最大値を集めてきて、どう使えるのか?という部分に関しては、まだまだ応用先が限定的な気がします。
アイデア次第で、意外と身近な分野に応用できると思うので、いろいろ研究してみたいと思います。

