ABテストのメリットと検定の罠 [データサイエンス、統計モデル]
ランダムに実験をして得られたデータはかなり良質なデータだったりします。
この辺りのことを整理してみると・・・
ランダムな実験は企業として難しい、意図的に配信したデータでもランダムな実験と同様の分析がしたい。
最近では、傾向スコアとか、反実仮想機械学習とかの概念が出てきて、必ずしもランダムデータは必須ではないと言われています。
ただ、実際に配信していないセグメントに対して予測することはなかなか難しいですし、効果を見積もるときに、何かとランダムデータの方が便利なので、ランダム実験できるならした方が良いと思います。
ポイントとかクーポンの介入の効果(因果)を見るには、やはりABテストは最強だったりします。
ここで陥りやすい罠として、ABテストって2つの群に分けているので人としては、検定をやりたくなる。
簡単だし、有意かどうかで白黒はっきりするし。
ただ、用意された2つのデータ(ABテストデータ)が、検定向きのデータであっても、統計検定ではなく、統計モデルを作ろうという発想になる人はあまりいない。
よく見るアプローチとしては、最近流行の機械学習とABテスト組み合わせて使うケースが多い。
ただ、ポイントとかクーポンの介入の分析って、本来、マーケティングをやっている人が欲しいのは、予測精度だけでなく、クーポンをもらってカスタマの構造がどう変わるのか/変わらないのかといったインサイトも欲しい。
しかし、このインサイトの理解と機械学習の相性がめちゃくちゃ悪かったりします。
そこでおすすめなのが、統計モデルとABテストの組み合わせが、良いと思います。
できれば、通常の線形回帰ではなく、階層ベイズモデルといったモデルが作れるとさらに良いと思っています。
この辺りのことを整理してみると・・・
ランダムな実験は企業として難しい、意図的に配信したデータでもランダムな実験と同様の分析がしたい。
最近では、傾向スコアとか、反実仮想機械学習とかの概念が出てきて、必ずしもランダムデータは必須ではないと言われています。
ただ、実際に配信していないセグメントに対して予測することはなかなか難しいですし、効果を見積もるときに、何かとランダムデータの方が便利なので、ランダム実験できるならした方が良いと思います。
ポイントとかクーポンの介入の効果(因果)を見るには、やはりABテストは最強だったりします。
ここで陥りやすい罠として、ABテストって2つの群に分けているので人としては、検定をやりたくなる。
簡単だし、有意かどうかで白黒はっきりするし。
ただ、用意された2つのデータ(ABテストデータ)が、検定向きのデータであっても、統計検定ではなく、統計モデルを作ろうという発想になる人はあまりいない。
よく見るアプローチとしては、最近流行の機械学習とABテスト組み合わせて使うケースが多い。
ただ、ポイントとかクーポンの介入の分析って、本来、マーケティングをやっている人が欲しいのは、予測精度だけでなく、クーポンをもらってカスタマの構造がどう変わるのか/変わらないのかといったインサイトも欲しい。
しかし、このインサイトの理解と機械学習の相性がめちゃくちゃ悪かったりします。
そこでおすすめなのが、統計モデルとABテストの組み合わせが、良いと思います。
できれば、通常の線形回帰ではなく、階層ベイズモデルといったモデルが作れるとさらに良いと思っています。
【訃報】「午後9時」3月末まで継続 [時事 / ニュース]
「う〜ん。。。」としか言いようがない。
8時から9時に変更して、1時間だけ、伸ばす意味ってなんだろう?
8時以降については、空いているお店に人が殺到して、激混み状態。
おそらく、9時にしたところで、全く状況は同じだと思う。
それに、飲食店で感染するみたいな印象操作をしていますが、データをみれば、
・高齢者施設でのクラスタ
・家庭内感染
の方がリスクが高い。
個人的には、
・GoToトラベルは、影響はなかった(問題なかった)。
・新型コロナウィルスは、多くの人にとっては怖くない。
むしろ、インフルエンザとか交通事故の方が個人的には怖い。
・今後も、何をしても、しなくても、第x波は繰り返される。
そして、緩やかに減衰していく。
と思っています。
そして、お金をばらまくことしかしない対策で、必要な税金がどんどん消えていっている。
将来の子供のために使って欲しいと思う。
8時から9時に変更して、1時間だけ、伸ばす意味ってなんだろう?
8時以降については、空いているお店に人が殺到して、激混み状態。
おそらく、9時にしたところで、全く状況は同じだと思う。
それに、飲食店で感染するみたいな印象操作をしていますが、データをみれば、
・高齢者施設でのクラスタ
・家庭内感染
の方がリスクが高い。
個人的には、
・GoToトラベルは、影響はなかった(問題なかった)。
・新型コロナウィルスは、多くの人にとっては怖くない。
むしろ、インフルエンザとか交通事故の方が個人的には怖い。
・今後も、何をしても、しなくても、第x波は繰り返される。
そして、緩やかに減衰していく。
と思っています。
そして、お金をばらまくことしかしない対策で、必要な税金がどんどん消えていっている。
将来の子供のために使って欲しいと思う。
データサイエンスから視た人工知能 [データサイエンス、統計モデル]
データサイエンスから視た人工知能
https://www.ism.ac.jp/events/2021/meeting0319.html
統計数理研究所のセミナー。
椿先生らしいモデレーターで、さりげない一言が心に残りました。
ベイズ最適化とか、いくつかやってみたいアイデアも浮かびました。
コロナの影響で公開セミナーとかも減ってきていますが、こういった頭のリフレッシュって大切だなと思います。
https://www.ism.ac.jp/events/2021/meeting0319.html
統計数理研究所のセミナー。
椿先生らしいモデレーターで、さりげない一言が心に残りました。
ベイズ最適化とか、いくつかやってみたいアイデアも浮かびました。
コロナの影響で公開セミナーとかも減ってきていますが、こういった頭のリフレッシュって大切だなと思います。
【モンスト】オーズの超究極をクリア [ゲーム]
今回の仮面ライダーコラボの超究極は、オーズ。
試しに準備適当に行ったら、ボス最終面あと少しで撃沈。
意外と簡単?
そこで、加撃は厳選せずに、「兵命削り」と「将命削りの力」を入れたところ、無事にクリアできました。
桜艦隊とかいろいろあるようですですが、割とオーソドックスなガチパーティーでした。(^^;
【クリアパーティ】
クウガ(獣神化)
小南桐絵(獣神化)
キリト(獣神化)
桜(さくら)獣神化
やはり、クウガいると楽でした。。。
試しに準備適当に行ったら、ボス最終面あと少しで撃沈。
意外と簡単?
そこで、加撃は厳選せずに、「兵命削り」と「将命削りの力」を入れたところ、無事にクリアできました。
桜艦隊とかいろいろあるようですですが、割とオーソドックスなガチパーティーでした。(^^;
【クリアパーティ】
クウガ(獣神化)
小南桐絵(獣神化)
キリト(獣神化)
桜(さくら)獣神化
やはり、クウガいると楽でした。。。
富津アクアファームでイチゴ狩り [ファミリー]
富津アクアファーム
https://www.jalan.net/kankou/spt_guide000000190825/
マザー牧場すぐ近くにある富津アクアファームに行ってきました。
通常は40分ですが、じゃらんで予約をすると60分に延長となります。
実際のところ、いちご食べ放題30分だと、ちょっとバタバタする感じ。
時間に追われて、イチゴの味が楽しめない。
40分がちょうど良い時間かなと。
60分は、ちょっと長い。。。
ただ、子供がいたりして、トイレに行ったり、子供の世話をしていると、のんびり60分ってのもありでした。
富津アクアファームのいちご狩りは、いろいろな種類のイチゴがありました。
いちごの種類によって酸っぱかったり、みずみずしかったり全然味が違います。
食べ比べてみると、この違いがはっきりとわかって勉強になりました。
https://www.jalan.net/kankou/spt_guide000000190825/
マザー牧場すぐ近くにある富津アクアファームに行ってきました。
通常は40分ですが、じゃらんで予約をすると60分に延長となります。
実際のところ、いちご食べ放題30分だと、ちょっとバタバタする感じ。
時間に追われて、イチゴの味が楽しめない。
40分がちょうど良い時間かなと。
60分は、ちょっと長い。。。
ただ、子供がいたりして、トイレに行ったり、子供の世話をしていると、のんびり60分ってのもありでした。
富津アクアファームのいちご狩りは、いろいろな種類のイチゴがありました。
いちごの種類によって酸っぱかったり、みずみずしかったり全然味が違います。
食べ比べてみると、この違いがはっきりとわかって勉強になりました。
リクルート、Airブランドで法人カード参入 [マネー]
リクルートカードというのがあるのですが、そちらは個人を対象にしたカード。
今回、新たにAirカードが登場しました。
https://airregi.jp/aircard/
ポイント還元率が1.5%とけっこうお得!
年会費も初年度無料です。
ただ、
本会員 5,500円(税込)
使用者 3,300円(税込)
ということで、2名で使うとなると1万円近くなってきます。
こうなると、ポイント以外のサービスも欲しいかなと。
ポイントだけでカードを決めるわけでないので、他のカードみたいな福利厚生とか、旅行時の充実などがあると良いのですが。。。
今回、新たにAirカードが登場しました。
https://airregi.jp/aircard/
ポイント還元率が1.5%とけっこうお得!
年会費も初年度無料です。
ただ、
本会員 5,500円(税込)
使用者 3,300円(税込)
ということで、2名で使うとなると1万円近くなってきます。
こうなると、ポイント以外のサービスも欲しいかなと。
ポイントだけでカードを決めるわけでないので、他のカードみたいな福利厚生とか、旅行時の充実などがあると良いのですが。。。
法人でおすすめのクレジットカード [マネー]
■ リクルート、Airブランドで法人カード参入
https://skellington.blog.ss-blog.jp/2021-03-22
ポイントの利率は良いのですが、年会費を考えると、ちょっと微妙。
ポイントだけでない人には響かない。
■ 三井住友ビジネスカード
ポイントのレートは悪いですが、
福利厚生支援ということで、福利厚生サービス「ベネフィット・ステーション」を使うことができます。
有料ですが、三井住友ビジネスカード経由で入る方がお得っぽい。
■ NTTファイナンス Bizカード
ポイントは、1%。
年会費も無料。
リクルートカードと比較するとポイントは低いけど、年会費が無料なのはかなり魅力的です。
https://skellington.blog.ss-blog.jp/2021-03-22
ポイントの利率は良いのですが、年会費を考えると、ちょっと微妙。
ポイントだけでない人には響かない。
■ 三井住友ビジネスカード
ポイントのレートは悪いですが、
福利厚生支援ということで、福利厚生サービス「ベネフィット・ステーション」を使うことができます。
有料ですが、三井住友ビジネスカード経由で入る方がお得っぽい。
■ NTTファイナンス Bizカード
ポイントは、1%。
年会費も無料。
リクルートカードと比較するとポイントは低いけど、年会費が無料なのはかなり魅力的です。
共分散構造分析における自由度の計算方法 [データサイエンス、統計モデル]
共分散構造分析(因子分析)における自由度の計算方法のまとめ
共分散を元に計算していきます。
自由度 = 共分散の数 - 推定するパラメータ数(矢印の数)
【ケース 1】識別不能の場合の適合度
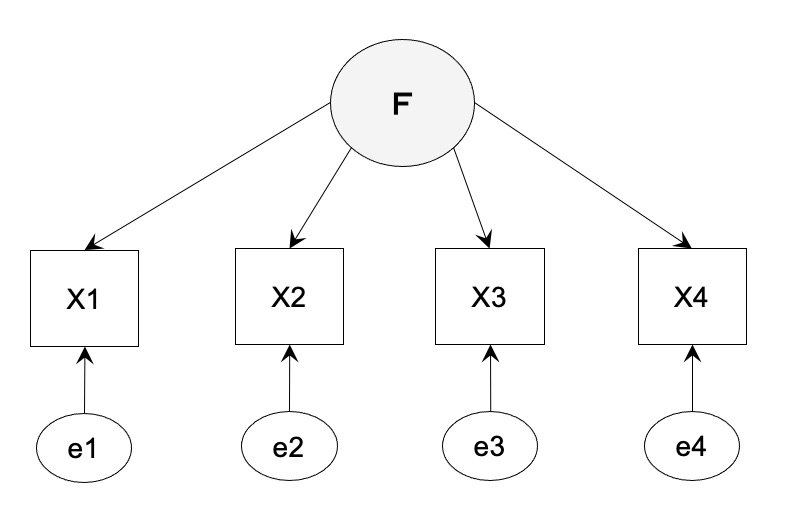
自由度 4x3/2 + 4 - 8 = 2
【ケース 2】丁度識別の場合の適合度
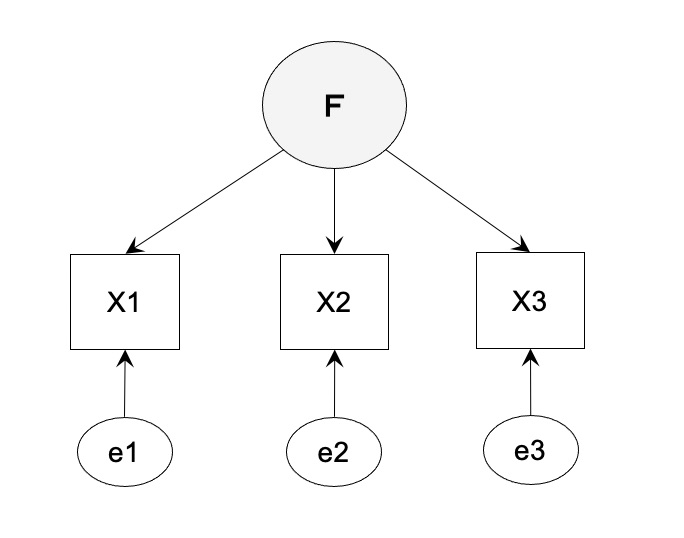
自由度 3x2/2 + 3 - 6 = 0
【ケース 3】識別不定の場合の適合度
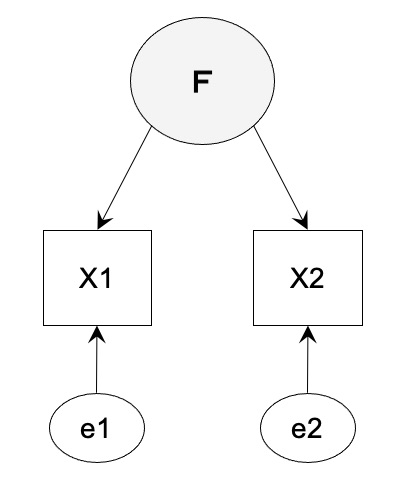
自由度 2/2 + 2 - 4 = -1
共分散を元に計算していきます。
自由度 = 共分散の数 - 推定するパラメータ数(矢印の数)
【ケース 1】識別不能の場合の適合度
自由度 4x3/2 + 4 - 8 = 2
【ケース 2】丁度識別の場合の適合度
自由度 3x2/2 + 3 - 6 = 0
【ケース 3】識別不定の場合の適合度
自由度 2/2 + 2 - 4 = -1
R version 4.0.4で漢字の読み込みエラー [データサイエンス、統計モデル]
バージョン4.0.3ではエラーが起きなかったのですが、最新の4.0.4を使うと漢字を読み込むとエラーが起こっています。
(例)
df <- read.table(file=csv1, header=TRUE, sep=",", fileEncoding = "utf-8")
"ひらがな"や"カタカナ"はきちんと読み込めますが、漢字だけ文字化けになっていました。(^^;
(例)
df <- read.table(file=csv1, header=TRUE, sep=",", fileEncoding = "utf-8")
"ひらがな"や"カタカナ"はきちんと読み込めますが、漢字だけ文字化けになっていました。(^^;
無意識バイアスワークショップ [マーケティング / 仕事]
無意識バイアスワークショップ(Unconscious Bias Workshop)という研修を受けてきました。
無意識バイアスは、悪いわけではなく、全部なくせない。
無意識が思考エネルギーをセーブしているなど、元々ラベリング機能が人間についている。
バイアス特徴を知ることが大切とのことでした。
成功と失敗で人はその原因を逆に考えがちだそうです。
自分が成功した場合は、自分が頑張ったから。
他人が成功した場合は、運が良かったから。
一方で、
自分が失敗した場合は、運が悪かった。
他人が失敗した場合は、その人が悪かった。
この辺りの非対称性が面白いですね。
無意識バイアスは、悪いわけではなく、全部なくせない。
無意識が思考エネルギーをセーブしているなど、元々ラベリング機能が人間についている。
バイアス特徴を知ることが大切とのことでした。
成功
内的帰属 | 外的帰属
自分-----------------------------------他人
外的帰属 | 内的帰属
失敗
成功と失敗で人はその原因を逆に考えがちだそうです。
自分が成功した場合は、自分が頑張ったから。
他人が成功した場合は、運が良かったから。
一方で、
自分が失敗した場合は、運が悪かった。
他人が失敗した場合は、その人が悪かった。
この辺りの非対称性が面白いですね。
ピアノの発表会 2021 [ファミリー]
毎年春に開催されるピアノの発表会。
昨年は新型コロナウィルスの影響で残念ながら中止となりました。
今年は無事に開催となりました。
長男は、受験勉強で忙しい中、それなりに時間を作って練習。
無事に、最後まで弾くことができました。
長女は、ピアノが好きということもあり、毎日弾き込んでいて、安心して見ることができました。
こうやっていろいろなイベントが少しずつ開催されていくことって大切なことだなと改めて思った今日この頃です。
昨年は新型コロナウィルスの影響で残念ながら中止となりました。
今年は無事に開催となりました。
長男は、受験勉強で忙しい中、それなりに時間を作って練習。
無事に、最後まで弾くことができました。
長女は、ピアノが好きということもあり、毎日弾き込んでいて、安心して見ることができました。
こうやっていろいろなイベントが少しずつ開催されていくことって大切なことだなと改めて思った今日この頃です。
日本行動計量学会 第23回春の合宿セミナー [時系列解析 / 需要予測]
参加しました。
土日に開催となると、なかなか参加出来ない場合が多いのですが、今回は、zoomでのオンライン開催ということで自宅からアクセスして勉強させてもらいました。
時系列前半に関して2日間というセミナーはあまりなく、良い勉強になりました。
さっそく使ってみたいと思います。
土日に開催となると、なかなか参加出来ない場合が多いのですが、今回は、zoomでのオンライン開催ということで自宅からアクセスして勉強させてもらいました。
時系列前半に関して2日間というセミナーはあまりなく、良い勉強になりました。
さっそく使ってみたいと思います。
【R】ベースのカテゴリを変更したい [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rで回帰分析をする際に、カテゴリ変数の場合、自動でベースのカテゴリが決まりますが、変更することができますか?
【回答】
有名なirisデータを使って実験します。
str(iris)
summary(iris)
Speciesは、3カテゴリあります。
setosa: 1
versicolor: 2
virginica: 3
通常は、factorで最初の数字のものがベースになってしまいます。
model_1 <- lm(Sepal.Length ~ Species, data=iris)
summary(model_1)
(Intercept) 5.0060 0.0728 68.762 < 2e-16 ***
Speciesversicolor 0.9300 0.1030 9.033 8.77e-16 ***
Speciesvirginica 1.5820 0.1030 15.366 < 2e-16 ***
ここで、setosaではなく、versicolorをベースカテゴリにするにはどうすれば良いか?
relevel(factor(Species), ref = "versicolor")
で設定できます。
model_2 <- lm(Sepal.Length ~ relevel(factor(Species), ref = "versicolor"), data=iris)
summary(model_2)
(Intercept) 5.9360 0.0728 81.536 < 2e-16 ***
relevel(factor(Species), ref = "versicolor")setosa -0.9300 0.1030 -9.033 8.77e-16 ***
relevel(factor(Species), ref = "versicolor")virginica 0.6520 0.1030 6.333 2.77e-09 ***
このようにversicolorがベースとなり、setosaとvirginicaの係数を得ることができました。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
Rで回帰分析をする際に、カテゴリ変数の場合、自動でベースのカテゴリが決まりますが、変更することができますか?
【回答】
有名なirisデータを使って実験します。
str(iris)
summary(iris)
Speciesは、3カテゴリあります。
setosa: 1
versicolor: 2
virginica: 3
通常は、factorで最初の数字のものがベースになってしまいます。
model_1 <- lm(Sepal.Length ~ Species, data=iris)
summary(model_1)
(Intercept) 5.0060 0.0728 68.762 < 2e-16 ***
Speciesversicolor 0.9300 0.1030 9.033 8.77e-16 ***
Speciesvirginica 1.5820 0.1030 15.366 < 2e-16 ***
ここで、setosaではなく、versicolorをベースカテゴリにするにはどうすれば良いか?
relevel(factor(Species), ref = "versicolor")
で設定できます。
model_2 <- lm(Sepal.Length ~ relevel(factor(Species), ref = "versicolor"), data=iris)
summary(model_2)
(Intercept) 5.9360 0.0728 81.536 < 2e-16 ***
relevel(factor(Species), ref = "versicolor")setosa -0.9300 0.1030 -9.033 8.77e-16 ***
relevel(factor(Species), ref = "versicolor")virginica 0.6520 0.1030 6.333 2.77e-09 ***
このようにversicolorがベースとなり、setosaとvirginicaの係数を得ることができました。
【R】ベースのカテゴリを変更したい その2 [データサイエンス、統計モデル]
統計の講師をしていて、なるほど!と思う質問を受けることがあります。
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
ロジスティク回帰分析の目的変数の設定を"購入する=1, 購入しない=0"とする場合と、逆に"購入する=0, 購入しない=0"とする場合があると思います。
どちらの設定になっているのかはどいうやって確認するのでしょうか?
【回答】
【R】ベースのカテゴリを変更したい
https://skellington.blog.ss-blog.jp/2021-03-29
↑
こちらの応用でできます。
まずは、irisのデータから、virginicaを削除します。
df <- subset(iris, Species == "setosa" | Species == "versicolor")
不要な(使っていない)Factorを除外。
df.new <- droplevels(df)
str(df.new)
デフォルトのロジスティック回帰分析
model_1a <- glm(Species ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_1a)
デフォルトのロジスティック回帰分析(ベースカテゴリは"setosa")
model_1b <- glm(relevel(factor(Species), ref = "setosa") ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_1b)
ベースカテゴリを"versicolor"に変更したロジスティック回帰分析
model_2 <- glm(relevel(factor(Species), ref = "versicolor") ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_2)
せっかくなので、その中からピックアップして紹介できればと思います。
【質問】
ロジスティク回帰分析の目的変数の設定を"購入する=1, 購入しない=0"とする場合と、逆に"購入する=0, 購入しない=0"とする場合があると思います。
どちらの設定になっているのかはどいうやって確認するのでしょうか?
【回答】
【R】ベースのカテゴリを変更したい
https://skellington.blog.ss-blog.jp/2021-03-29
↑
こちらの応用でできます。
まずは、irisのデータから、virginicaを削除します。
df <- subset(iris, Species == "setosa" | Species == "versicolor")
不要な(使っていない)Factorを除外。
df.new <- droplevels(df)
str(df.new)
デフォルトのロジスティック回帰分析
model_1a <- glm(Species ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_1a)
デフォルトのロジスティック回帰分析(ベースカテゴリは"setosa")
model_1b <- glm(relevel(factor(Species), ref = "setosa") ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_1b)
ベースカテゴリを"versicolor"に変更したロジスティック回帰分析
model_2 <- glm(relevel(factor(Species), ref = "versicolor") ~ Sepal.Length, family = "binomial", data=df.new)
summary(model_2)
【R】lavaanを使った多母集団同時分析 [データサイエンス、統計モデル]
共分散構造分析で多母集団同時分析をする方法について。
通常は、単一の母集団からサンプリングされたと仮定しますが、実際は、様々な集団(セグメント)を感がる必要があります。
性別の違い、年代の違いなど。
ただ、各セグメントごとにデータを分けてしまうと、サンプルサイズが小さくなってしまいます。
そこで、登場するのが多母集団同時分析です。
全体の構造は同じとみて、ここのセグメントごとに、係数を微調整するイメージです。
lavaanで多母集団同時分析をするには、
group = "*****"
で設定することができます。
# 分析モデル 1
通常の共分散構造分析
# 分析モデル 2
多母集団同時分析
########################################
library(lavaan)
library(psych)
#分析前にNA(欠測)を含む個体(対象者)を除外する
#リストワイズ削除
bfi2<-na.omit(bfi[ , c("A1", "A2", "A3", "A4", "A5", "gender")])
#変数に名前を付ける
colnames(bfi2)<-c("a1","a2","a3","a4","a5","gender")
#分析モデル 1
model <- '
A =~ a1 + a2 + a3 + a4 + a5
a1 ~~ a1;a2 ~~ a2;a3 ~~ a3;a4 ~~ a4;a5 ~~ a5
A ~~ 1*A
'
fit1 <- lavaan(model, data=bfi2)
summary(fit1, standardized=T, fit.measures = TRUE)
#分析モデル 2
fit2 <- lavaan(model, data=bfi2, group = "gender")
summary(fit2, standardized=T, fit.measures = TRUE)
########################################
通常は、単一の母集団からサンプリングされたと仮定しますが、実際は、様々な集団(セグメント)を感がる必要があります。
性別の違い、年代の違いなど。
ただ、各セグメントごとにデータを分けてしまうと、サンプルサイズが小さくなってしまいます。
そこで、登場するのが多母集団同時分析です。
全体の構造は同じとみて、ここのセグメントごとに、係数を微調整するイメージです。
lavaanで多母集団同時分析をするには、
group = "*****"
で設定することができます。
# 分析モデル 1
通常の共分散構造分析
# 分析モデル 2
多母集団同時分析
########################################
library(lavaan)
library(psych)
#分析前にNA(欠測)を含む個体(対象者)を除外する
#リストワイズ削除
bfi2<-na.omit(bfi[ , c("A1", "A2", "A3", "A4", "A5", "gender")])
#変数に名前を付ける
colnames(bfi2)<-c("a1","a2","a3","a4","a5","gender")
#分析モデル 1
model <- '
A =~ a1 + a2 + a3 + a4 + a5
a1 ~~ a1;a2 ~~ a2;a3 ~~ a3;a4 ~~ a4;a5 ~~ a5
A ~~ 1*A
'
fit1 <- lavaan(model, data=bfi2)
summary(fit1, standardized=T, fit.measures = TRUE)
#分析モデル 2
fit2 <- lavaan(model, data=bfi2, group = "gender")
summary(fit2, standardized=T, fit.measures = TRUE)
########################################

