bayesmのcheeseを使ったモデリング、その4~階層ベイズを使った線形回帰モデル [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-10
目的変数:VOLUME(販売数量)
観測モデルの説明変数:DISP(陳列の有無), log_PRICE(販売価格のlog), 切片
階層モデル:切片のみ
RETAILERごとに説明変数のβ(係数)を求めることができます。
本当は、RETAILERに関する情報(土地情報, 店舗数)などを追加で用意できると、それらの特徴ごとに、βの傾向を把握することができます。
例えば、地方都市だと、陳列の有無が重要であるとか。
今回の cheese にはそのような情報が含まれていないので、切片のみのモデルとなっています。
【推定結果と実際の値の散布図】
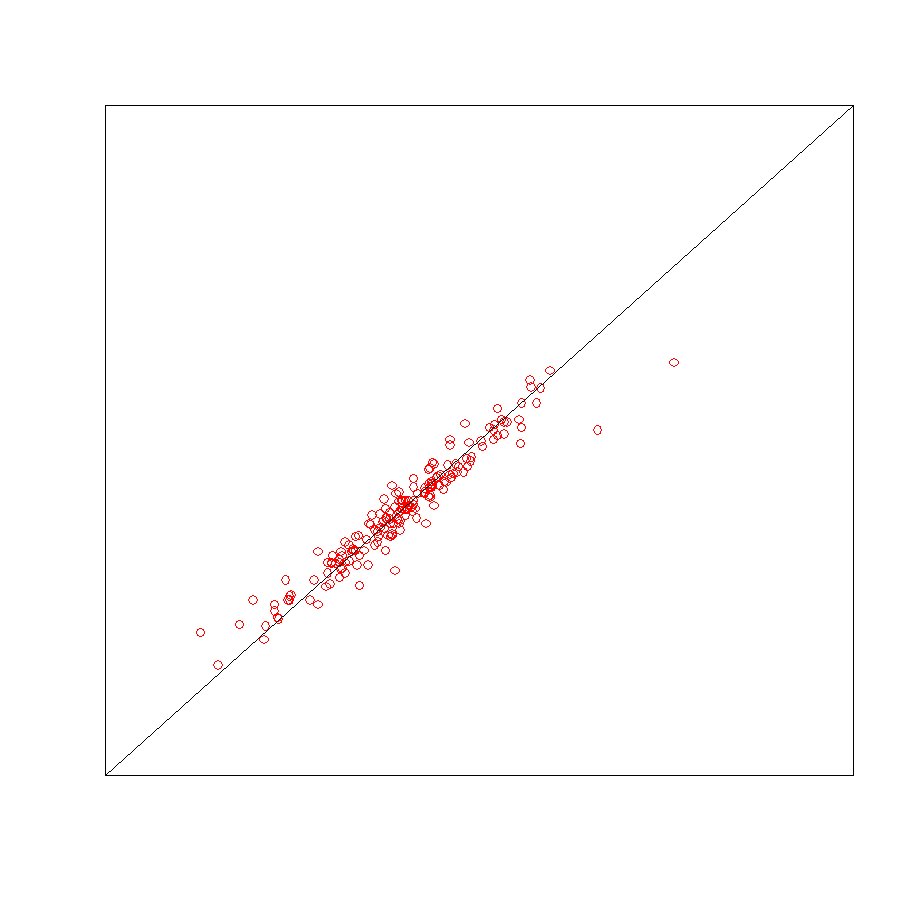
【推定結果と実際の値のピアソンの積率相関係数】
通常の線形回帰モデル:0.098
フラグ化した線形回帰モデル:0.705
ニューラルネットワーク:0.816
決定木(CHAID):0.705
階層ベイズを使った線形回帰モデル:0.961
となって、圧倒的に階層ベイズを使った線形回帰モデルの精度が高いです。
もともと、階層ベイズでモデルを作る場合、モデル作成用データに対して
推定結果と実際の値は非常に近い値になる傾向にあります。
上記の結果は、モデル検証用データ(モデル作成時に使用しなかったデータ)に対しての精度です。
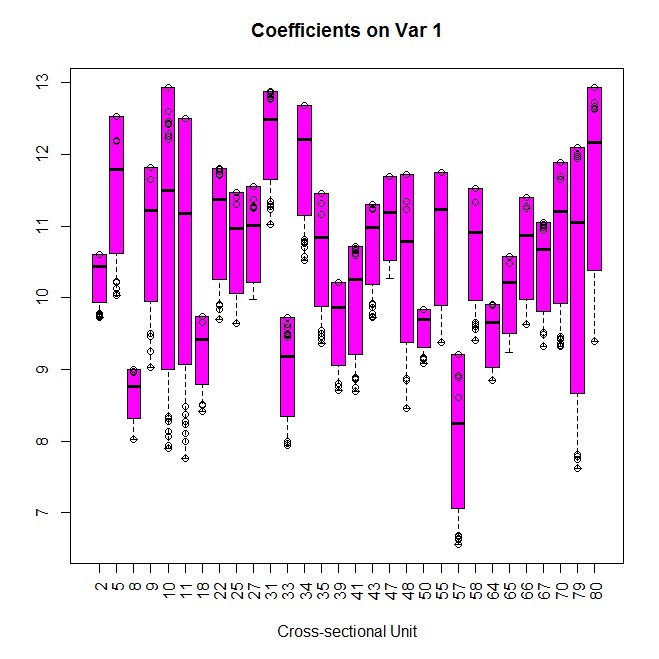
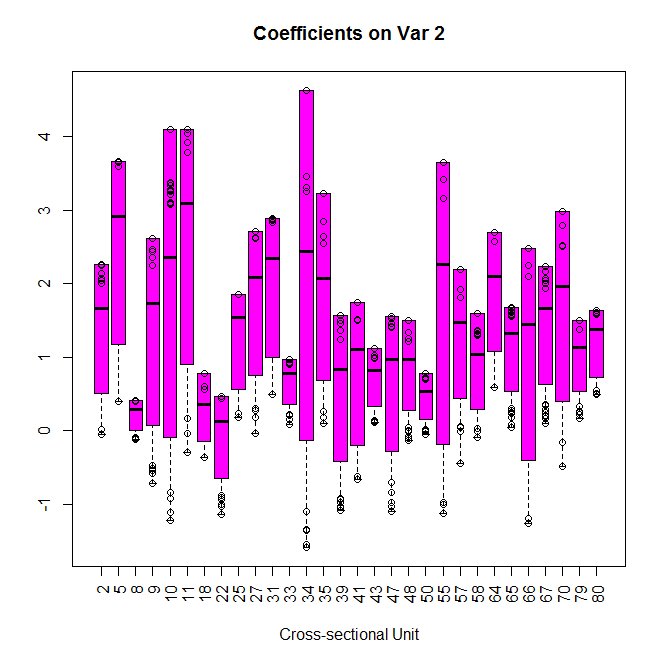
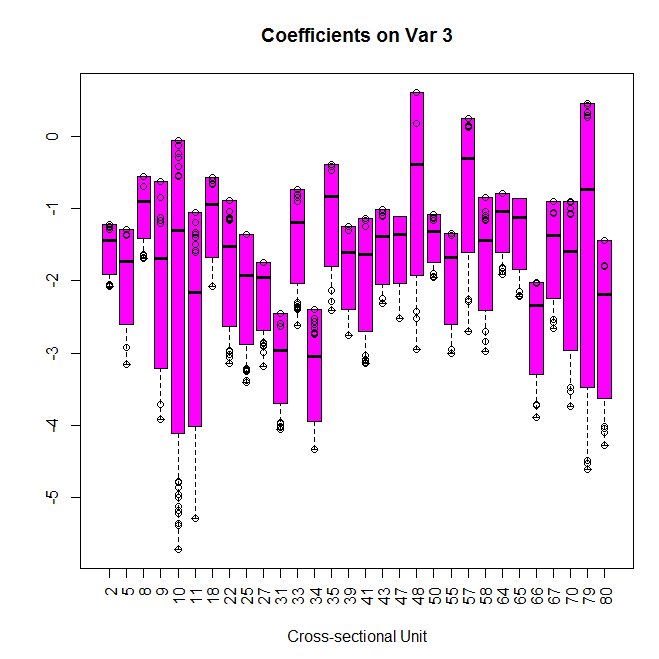
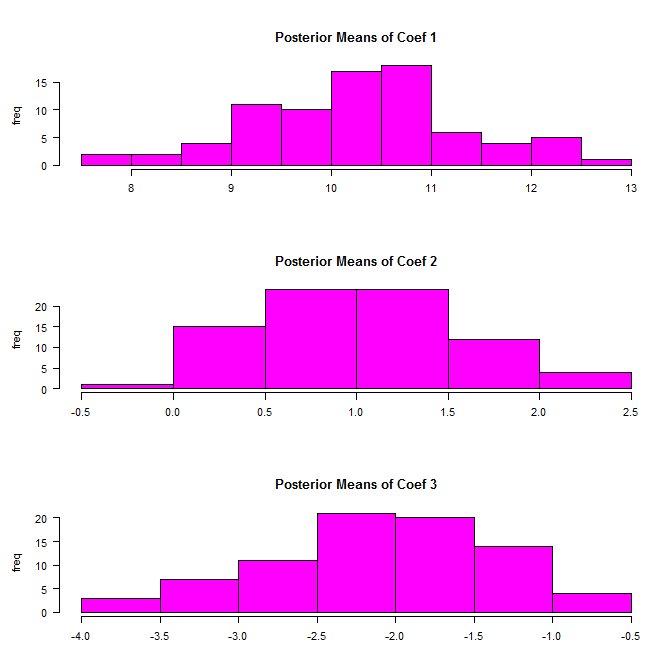
【RETAILERの回帰係数】
機械学習の場合、精度は良いのだが、中身がブラックボックスという欠点がありましたが、
階層ベイズを使った線形回帰モデルは、中身はシンプルな重回帰なので理解もしやすい。
回帰係数のパラメータが共通のものではなく、RETAILERごとに異なっている点が注意です。
1. 通常の線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-07
2. RETAILER をフラグ化した線形回帰モデル
http://skellington.blog.so-net.ne.jp/2017-11-08
3. 機械学習のアプローチ
http://skellington.blog.so-net.ne.jp/2017-11-09
4. 階層ベイズを使った線形回帰モデル ← 今回
http://skellington.blog.so-net.ne.jp/2017-11-10
目的変数:VOLUME(販売数量)
観測モデルの説明変数:DISP(陳列の有無), log_PRICE(販売価格のlog), 切片
階層モデル:切片のみ
RETAILERごとに説明変数のβ(係数)を求めることができます。
本当は、RETAILERに関する情報(土地情報, 店舗数)などを追加で用意できると、それらの特徴ごとに、βの傾向を把握することができます。
例えば、地方都市だと、陳列の有無が重要であるとか。
今回の cheese にはそのような情報が含まれていないので、切片のみのモデルとなっています。
【推定結果と実際の値の散布図】
【推定結果と実際の値のピアソンの積率相関係数】
通常の線形回帰モデル:0.098
フラグ化した線形回帰モデル:0.705
ニューラルネットワーク:0.816
決定木(CHAID):0.705
階層ベイズを使った線形回帰モデル:0.961
となって、圧倒的に階層ベイズを使った線形回帰モデルの精度が高いです。
もともと、階層ベイズでモデルを作る場合、モデル作成用データに対して
推定結果と実際の値は非常に近い値になる傾向にあります。
上記の結果は、モデル検証用データ(モデル作成時に使用しなかったデータ)に対しての精度です。
【RETAILERの回帰係数】
機械学習の場合、精度は良いのだが、中身がブラックボックスという欠点がありましたが、
階層ベイズを使った線形回帰モデルは、中身はシンプルな重回帰なので理解もしやすい。
回帰係数のパラメータが共通のものではなく、RETAILERごとに異なっている点が注意です。


コメント 0