【SPSS Modeler】ロジスティック回帰とSVMを使った二値分類 その1 [データサイエンス、統計モデル]
買う/買わないといった0,1のデータを分離する方法は色々な方法があります。
その代表的なものといえば、ロジスティック回帰でしょうか。
機械学習的なアプローチでは、決定木やSVM(サポートベクターマシーン)などがあります。
今回は、SPSS Modelerを使って少し変わったやり方で何が起こっているかを理解したいと思います。
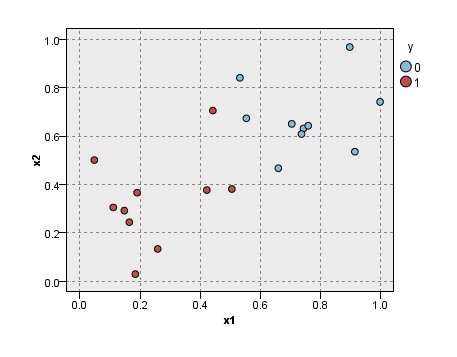
まずは、データの可視化から。
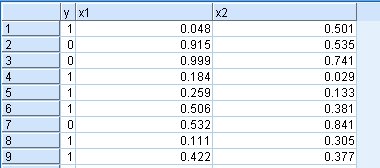
0 <= x1 <= 1
0 <= x2 <= 1
となっています
モデリングを使わなくても、判別は自明なのですが、赤丸と青丸をどのように分離するか考えてみます。
どのように分離になるか(なってほしいか)を考えると、
左上から右下に分離する線分をひきたい!と思うかと思います。
まずは、ロジスティック回帰から。
x1, x2を説明変数、yを目的変数に設定し、ロジスティック回帰のモデルを作成します。
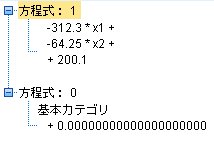
この式から分離する線を引きたいのですが、それは、yの値がちょうど0.5となるx1, x2を求めれば良いわけです。
ロジスティック回帰の場合は、その点を四則演算の組み合わせで計算できますが、SVMでは、簡単に求めることができません。
この様な場合は、適当なx1, x2の組み合わせを大量に発生させて、yの値がどうなるかシミュレーションします。
そして、ちょうどyの値が0.5となるx1, x2の組み合わせを持ってくれば、0, 1を分離する線分をひくことができます。
作成したストリームはこんな感じです。
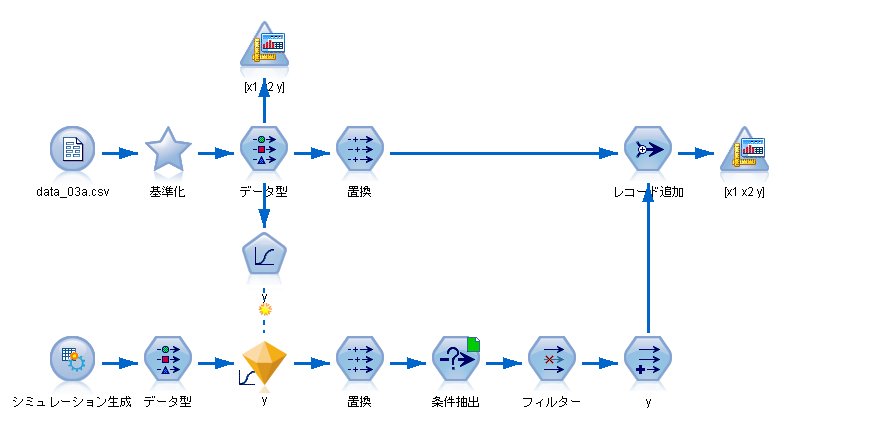
そして、判別結果はこのようになります。
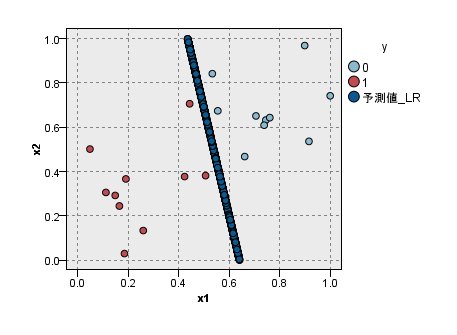
まぁ、仮説通りの納得の結果ですね。
続いて、SVM(サポートベクターマシーン)を使って分離するとどうなるか・・・見てみたいと思います。
※ 今回、作成したストリームが欲しい方は、ご連絡くださいませ。
その代表的なものといえば、ロジスティック回帰でしょうか。
機械学習的なアプローチでは、決定木やSVM(サポートベクターマシーン)などがあります。
今回は、SPSS Modelerを使って少し変わったやり方で何が起こっているかを理解したいと思います。
まずは、データの可視化から。
0 <= x1 <= 1
0 <= x2 <= 1
となっています
モデリングを使わなくても、判別は自明なのですが、赤丸と青丸をどのように分離するか考えてみます。
どのように分離になるか(なってほしいか)を考えると、
左上から右下に分離する線分をひきたい!と思うかと思います。
まずは、ロジスティック回帰から。
x1, x2を説明変数、yを目的変数に設定し、ロジスティック回帰のモデルを作成します。
この式から分離する線を引きたいのですが、それは、yの値がちょうど0.5となるx1, x2を求めれば良いわけです。
ロジスティック回帰の場合は、その点を四則演算の組み合わせで計算できますが、SVMでは、簡単に求めることができません。
この様な場合は、適当なx1, x2の組み合わせを大量に発生させて、yの値がどうなるかシミュレーションします。
そして、ちょうどyの値が0.5となるx1, x2の組み合わせを持ってくれば、0, 1を分離する線分をひくことができます。
作成したストリームはこんな感じです。
そして、判別結果はこのようになります。
まぁ、仮説通りの納得の結果ですね。
続いて、SVM(サポートベクターマシーン)を使って分離するとどうなるか・・・見てみたいと思います。
※ 今回、作成したストリームが欲しい方は、ご連絡くださいませ。

