bayesmのcheeseを使ったモデリング、その1~通常の線形回帰モデル [階層ベイズ]
Rの bayesm というパッケージに入っている cheese というデータを使って、いろいろ分析していきたいと思います。
write.table(cheese, "cheese.txt", sep="\t", quote=F, col.names=T, row.names=F, append=F)
↑
いったん、ローカルにテキストファイルとして吐き出して、いろいろなモデルを作っていきます。
モデルは、SPSS Modelerを使用。
cheese のデータ概要ですが、全部で5,555レコード。
IDとなる、RETAILER数は、88社で、RETAILERをIDとすると、同じRETAILERのデータが複数存在します。
階層ベイズを使って線形回帰モデルを行っていくのですが、同じRETAILERでデータが、だいたい60レコード存在します。
5,555レコードあるのですが、
モデル作成用:5,359レコード
モデル検証用:176レコード
にランダムに分けます。
モデル検証用として、RETAILER 88社から2レコードずつ、合計176レコード取っておきます。
まずは、階層ベイズを使わないで、普通に線形回帰をしたらどうなるか?
目的変数:VOLUME
説明変数:DISP, log_PRICE
↑
もともとのデータは、PRICEが入っているのですが、ここではlog変換を行ってlog_PRICEを説明変数としています。
分析結果は、こんな感じ。
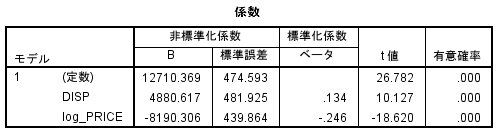
DSIP, log_PRICE ともに有意となっています。
DISP(陳列)した方が売れますし、PRICE(価格)が高くなると売れなくなります。
納得の結果ですね。
ただ、R2は、0.088とそれほど高くありません。
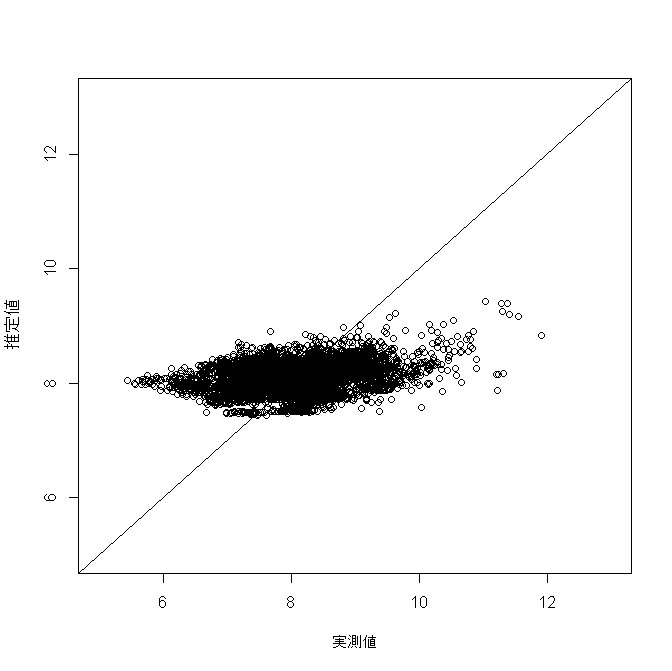
推定結果と実際の値を比較してみても、上手く予想できていないことがよくわかります。
【推定結果と実際の値の散布図】
【推定結果と実際の値のピアソンの積率相関係数】
0.098
ということで、ここから工夫をしていくわけですが、
1. 通常の線形回帰モデル ← 今、ココ
2. RETAILER をフラグ化した線形回帰モデル
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
とモデリングしていきます。
write.table(cheese, "cheese.txt", sep="\t", quote=F, col.names=T, row.names=F, append=F)
↑
いったん、ローカルにテキストファイルとして吐き出して、いろいろなモデルを作っていきます。
モデルは、SPSS Modelerを使用。
cheese のデータ概要ですが、全部で5,555レコード。
IDとなる、RETAILER数は、88社で、RETAILERをIDとすると、同じRETAILERのデータが複数存在します。
階層ベイズを使って線形回帰モデルを行っていくのですが、同じRETAILERでデータが、だいたい60レコード存在します。
5,555レコードあるのですが、
モデル作成用:5,359レコード
モデル検証用:176レコード
にランダムに分けます。
モデル検証用として、RETAILER 88社から2レコードずつ、合計176レコード取っておきます。
まずは、階層ベイズを使わないで、普通に線形回帰をしたらどうなるか?
目的変数:VOLUME
説明変数:DISP, log_PRICE
↑
もともとのデータは、PRICEが入っているのですが、ここではlog変換を行ってlog_PRICEを説明変数としています。
分析結果は、こんな感じ。
DSIP, log_PRICE ともに有意となっています。
DISP(陳列)した方が売れますし、PRICE(価格)が高くなると売れなくなります。
納得の結果ですね。
ただ、R2は、0.088とそれほど高くありません。
推定結果と実際の値を比較してみても、上手く予想できていないことがよくわかります。
【推定結果と実際の値の散布図】
【推定結果と実際の値のピアソンの積率相関係数】
0.098
ということで、ここから工夫をしていくわけですが、
1. 通常の線形回帰モデル ← 今、ココ
2. RETAILER をフラグ化した線形回帰モデル
3. 機械学習のアプローチ
4. 階層ベイズを使った線形回帰モデル
とモデリングしていきます。


コメント 0