IBM SPSS Modelerの引用符の罠 [データサイエンス、統計モデル]
引用符(ダブルクォーテーションとシングルクォーテーション)の罠
他人が作ったストリームを見ていて、一見気が付かなかったのだが、
「あ、なるほど!(・∀・)」
と思った罠がありました。
(例)
変数でテストグループと通常グループを作りたい。
変数名は、【テストグループ】とする。
本来なら、変数名と中身は変えるべきで、
変数名:グループ
変数の中身:{テストグループ, 通常グループ}
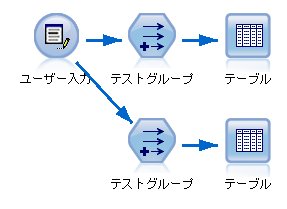
奇数 ⇒ テストグループ
偶数 ⇒ 通常グループ
【正しい書き方】
if index rem 2 = 1 then "テストグループ"
else "通常グループ" endif

【変な書き方】
if index rem 2 = 1 then "テストグループ"
else "通常グループ" endif

ちなみに、
if index rem 2 = 0 then 'テストグループ'
else '通常グループ' endif
とすると、
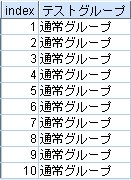
本来、フィールドの中身は、ダブルクォーテーション " " でくくり、
他のフィールドの中身を持ってくるときは、シングルクォーテーション' 'でくくる
今回、何が起こっていたか考えてみると、
1行目を実行した時、変数'テストグループ'の中身を持ってきなさいとなるが、自分自身なため、空白になる。
2行目を実行した時、変数'通常グループ'の中身を持ってきなさいとなるが、その様な変数はない。
そのため、文字列を入力すると、判断し、"通常グループ"という文字列が入る。
2行目を実行した時、変数'テストグループ'の中身を持ってきなさいとなり、今入っている値は"通常グループ"なため、"通常グループ"という文字列が入る。
ちなみに、テキストで処理をしているので、上記のような値になるのだが、
これをNetezzaデータベースで処理した場合、SPSS Modeler自身が強制終了になってしまうので、注意が必要です。。。
他人が作ったストリームを見ていて、一見気が付かなかったのだが、
「あ、なるほど!(・∀・)」
と思った罠がありました。
(例)
変数でテストグループと通常グループを作りたい。
変数名は、【テストグループ】とする。
本来なら、変数名と中身は変えるべきで、
変数名:グループ
変数の中身:{テストグループ, 通常グループ}
奇数 ⇒ テストグループ
偶数 ⇒ 通常グループ
【正しい書き方】
if index rem 2 = 1 then "テストグループ"
else "通常グループ" endif
【変な書き方】
if index rem 2 = 1 then "テストグループ"
else "通常グループ" endif
ちなみに、
if index rem 2 = 0 then 'テストグループ'
else '通常グループ' endif
とすると、
本来、フィールドの中身は、ダブルクォーテーション " " でくくり、
他のフィールドの中身を持ってくるときは、シングルクォーテーション' 'でくくる
今回、何が起こっていたか考えてみると、
1行目を実行した時、変数'テストグループ'の中身を持ってきなさいとなるが、自分自身なため、空白になる。
2行目を実行した時、変数'通常グループ'の中身を持ってきなさいとなるが、その様な変数はない。
そのため、文字列を入力すると、判断し、"通常グループ"という文字列が入る。
2行目を実行した時、変数'テストグループ'の中身を持ってきなさいとなり、今入っている値は"通常グループ"なため、"通常グループ"という文字列が入る。
ちなみに、テキストで処理をしているので、上記のような値になるのだが、
これをNetezzaデータベースで処理した場合、SPSS Modeler自身が強制終了になってしまうので、注意が必要です。。。


コメント 0