PASW Modeler 13 で追加された新アルゴリズム [データサイエンス、統計モデル]
新機能のページをみると以下のアルゴリズムが追加されたようだ。
http://www.spss.co.jp/software/modeler/
最近隣アルゴリズム 予測やセグメンテーションを使って他のケースとの類似性を基にケースを分類します。
いろいろな呼び方があって、
・KNNアルゴリズム(k-nearest neighbor algorithm)
・k近傍法
・最近隣法
なども呼ばれている。
アルゴリズムは非常に単純で、おそらく世の中の機械学習の中で一番単純なアルゴリズムかもしれない。
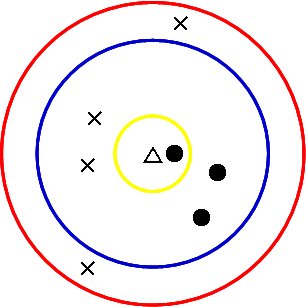
以下、簡単にアルゴリズムを説明すると、今予測したいものがあったとする。
上の図の場合は、△。
過去のデータなりを持ってきたときに、この△と近いk個が●なのか×なのかを数えて、多数決で●か×かを判定するアルゴリズムだ。
【 k = 1 の場合(黄色の枠場合)】
自分に一番近いもののみを参考にする。
この場合、●が一番近いので、△は●だろうと予測する。
【 k = 5 の場合(青色の枠の場合)】
●が3個、×が2個なので、△は●だろうと予測する。
【 k = 7 の場合(青色の枠の場合)】
●が3個、×が4個なので、△は×だろうと予測する。
k は正の整数で、一般に小さい。
また、二項の場合(1 - 0 予測の場合)、k が偶数の場合、同票数で分類できなくなるので奇数に設定しておく。
次のこの近さをどう計算するかだが、ユークリッドやマンハッタン距離を使うことが多い。
Clementine でもユークリッド距離やマンハッタン距離(都市ブロック距離)が使える。
【その他の特徴】
・離散値だけでなく、連続値に対しても適応可能。
・データ量 ⇒ ∞ の場合、誤り率はベイズ誤り率の2倍以下となる。
・kを増やすことでベイズ誤り率に近づく。
http://www.spss.co.jp/software/modeler/
最近隣アルゴリズム 予測やセグメンテーションを使って他のケースとの類似性を基にケースを分類します。
いろいろな呼び方があって、
・KNNアルゴリズム(k-nearest neighbor algorithm)
・k近傍法
・最近隣法
なども呼ばれている。
アルゴリズムは非常に単純で、おそらく世の中の機械学習の中で一番単純なアルゴリズムかもしれない。
以下、簡単にアルゴリズムを説明すると、今予測したいものがあったとする。
上の図の場合は、△。
過去のデータなりを持ってきたときに、この△と近いk個が●なのか×なのかを数えて、多数決で●か×かを判定するアルゴリズムだ。
【 k = 1 の場合(黄色の枠場合)】
自分に一番近いもののみを参考にする。
この場合、●が一番近いので、△は●だろうと予測する。
【 k = 5 の場合(青色の枠の場合)】
●が3個、×が2個なので、△は●だろうと予測する。
【 k = 7 の場合(青色の枠の場合)】
●が3個、×が4個なので、△は×だろうと予測する。
k は正の整数で、一般に小さい。
また、二項の場合(1 - 0 予測の場合)、k が偶数の場合、同票数で分類できなくなるので奇数に設定しておく。
次のこの近さをどう計算するかだが、ユークリッドやマンハッタン距離を使うことが多い。
Clementine でもユークリッド距離やマンハッタン距離(都市ブロック距離)が使える。
【その他の特徴】
・離散値だけでなく、連続値に対しても適応可能。
・データ量 ⇒ ∞ の場合、誤り率はベイズ誤り率の2倍以下となる。
・kを増やすことでベイズ誤り率に近づく。

