Parametric Bootstrap 法 [データサイエンス、統計モデル]
こんな実験をしたと仮定する。
「パッチリ二重の人と一重の人とでバレンタインのチョコの個数って違うのか?」
グループA(パッチリ二重グループ)10人
7 4 2 4 1 5 2 3 6 3
⇒ 平均3.7個のチョコをゲット
グループB(一重グループ)5人
2 3 2 2 3
⇒ 平均2.4個のチョコをゲット
チョコがもらえる個数は、ポアソン分布から得られるものと仮定して、
グループAとグループBの「平均値の差」に注目します。
つまり、
3.7 - 2.4 = 1.3
この1.3個って平均の差は、よくあることなのか?あるいは、滅多に起こらないことなのか?
この問題を Parametric Bootstrap法 ってやつを使って解くことにする。
Rを使うのではなく、SPSS Clementine(クレメンタイン)で解くとどうなるのか?
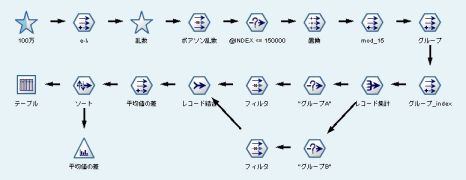
【手順1】ポアソン分布のλって?
まずは、平均λのポアソン分布を発生させることを考える。
注意として、(3.7 + 2.4) ÷ 2 = 3.05 ではない!
グループAは10人、グループBは5人いるので、加重平均を取って
(3.7 × 10 + 2.4 × 5) ÷ (10 + 5) = 3.266666667
λ = 3.266666667 からのポアソン乱数を発生させる。
【手順2】クレメンタインでポアソン乱数ってどうやって発生させるのか?
CLEM式でサポートしていると、簡単なんだが、一様分布と正規分布しか関数が用意されていない。
そこで、自分でポアソン分布の乱数を発生させる必要があるのだが、ポアソン分布に従う乱数 x は、区間 [0,1) の一様分布の乱数を複数個使って生成することができる。
U1 ,U2 ,… を、区間 [0,1) の一様乱数として、その積が初めて e-λ より小さくなった時を x+1 回目とする。
{ U1 ≧ e-λ} & { U1 * U2 ≧ e-λ} & … & { U1 * U2 * …* Ux ≧ e-λ}
&
{U1 * U2 * … * Ux * Ux+1 < e-λ}
これらの積が初めて e-λ より小さくなる直前の個数 x が、ポアソン分布に従うことが証明できる。
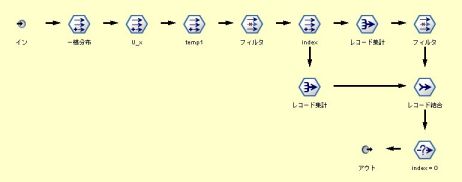
オフセット関数を上手く使えばできる。
【手順3】Parametric Bootstrap 法
平均 3.266666667 のポアソン分布から乱数を
グループA(ニセ集団A)に10個
グループB(ニセ集団B)に5個
用意する。
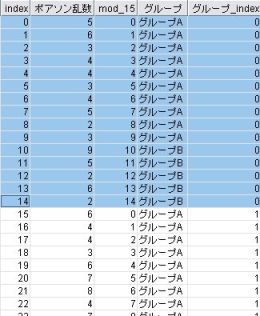
このグループAとグループBの15セットを10,000回用意する。
※ 100万の一様分布を用意して、約23万のポアソン乱数を得ることができた。
上記の中から、15 × 10,000 = 15万のポアソン乱数を使用している。
【手順4】棄却域で判定
滅多に起こらないかどうかを危険率5%に設定すると、左右の2.5%が棄却域となる。
今回、10,000サンプルなので、平均の差を小さいものから大きいものにソートすると、最初の250サンプルと、最後の250サンプルの平均に入ると滅多に起こらない現象って考えることができるだろう。
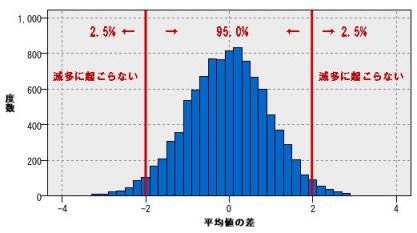
平均の差を思い出すと、1.3 であった。
つまり、"パッチリ二重グループA" と "一重グループB" では、統計学的な有意差はないことがわかる。
そんな俺はパッチリ二重にあこがれるふつーの一重グループBである。
(-∀-)


「パッチリ二重の人と一重の人とでバレンタインのチョコの個数って違うのか?」
グループA(パッチリ二重グループ)10人
7 4 2 4 1 5 2 3 6 3
⇒ 平均3.7個のチョコをゲット
グループB(一重グループ)5人
2 3 2 2 3
⇒ 平均2.4個のチョコをゲット
チョコがもらえる個数は、ポアソン分布から得られるものと仮定して、
グループAとグループBの「平均値の差」に注目します。
つまり、
3.7 - 2.4 = 1.3
この1.3個って平均の差は、よくあることなのか?あるいは、滅多に起こらないことなのか?
この問題を Parametric Bootstrap法 ってやつを使って解くことにする。
Rを使うのではなく、SPSS Clementine(クレメンタイン)で解くとどうなるのか?
【手順1】ポアソン分布のλって?
まずは、平均λのポアソン分布を発生させることを考える。
注意として、(3.7 + 2.4) ÷ 2 = 3.05 ではない!
グループAは10人、グループBは5人いるので、加重平均を取って
(3.7 × 10 + 2.4 × 5) ÷ (10 + 5) = 3.266666667
λ = 3.266666667 からのポアソン乱数を発生させる。
【手順2】クレメンタインでポアソン乱数ってどうやって発生させるのか?
CLEM式でサポートしていると、簡単なんだが、一様分布と正規分布しか関数が用意されていない。
そこで、自分でポアソン分布の乱数を発生させる必要があるのだが、ポアソン分布に従う乱数 x は、区間 [0,1) の一様分布の乱数を複数個使って生成することができる。
U1 ,U2 ,… を、区間 [0,1) の一様乱数として、その積が初めて e-λ より小さくなった時を x+1 回目とする。
{ U1 ≧ e-λ} & { U1 * U2 ≧ e-λ} & … & { U1 * U2 * …* Ux ≧ e-λ}
&
{U1 * U2 * … * Ux * Ux+1 < e-λ}
これらの積が初めて e-λ より小さくなる直前の個数 x が、ポアソン分布に従うことが証明できる。
オフセット関数を上手く使えばできる。
【手順3】Parametric Bootstrap 法
平均 3.266666667 のポアソン分布から乱数を
グループA(ニセ集団A)に10個
グループB(ニセ集団B)に5個
用意する。
このグループAとグループBの15セットを10,000回用意する。
※ 100万の一様分布を用意して、約23万のポアソン乱数を得ることができた。
上記の中から、15 × 10,000 = 15万のポアソン乱数を使用している。
【手順4】棄却域で判定
滅多に起こらないかどうかを危険率5%に設定すると、左右の2.5%が棄却域となる。
今回、10,000サンプルなので、平均の差を小さいものから大きいものにソートすると、最初の250サンプルと、最後の250サンプルの平均に入ると滅多に起こらない現象って考えることができるだろう。
平均の差を思い出すと、1.3 であった。
つまり、"パッチリ二重グループA" と "一重グループB" では、統計学的な有意差はないことがわかる。
そんな俺はパッチリ二重にあこがれるふつーの一重グループBである。
(-∀-)
- 作者: Alan Agresti
- 出版社/メーカー: サイエンティスト社
- 発売日: 2003/02
- メディア: 単行本
一般線形モデルによる生物科学のための現代統計学―あなたの実験をどのように解析するか
- 作者: アラン グラフェン
- 出版社/メーカー: 共立出版
- 発売日: 2007/01
- メディア: 単行本

