Audi A4の納車式 [自動車 / バイク]
先日、Audi A4の車をディーラーに取りに行きました。
前回、スバルの車を買ったときは、もろもろの手続きを終えて、そのまま車を渡されたのですが、今回は、なんと納車ルームなるものがありました。
立派な部屋の中に、Audiが置かれていました。
今では、当たり前になっている(らしい)納車式ですが、もともとは、Audiのドイツで行われていたものだそうです。
個人的には、契約したディーラーで車を受け取る感覚なのですが、ドイツでは製造工場で直接車を受け取りたいみたいです。
しかも、オプションらしく少し割高になるらしい。
話を戻して、、、もろもろの手続きを終えたら、ノンアルコールのワインをもらいました。
昔は、シャンパンなどをもらえたそうですが、アルコール飲料と車の相性がわるく、今では、ノンアルコールになったそうです。
その後、納車ルームからそのままAudiに乗って帰ってきました。
営業の人だけでなく、整備士さんや受付の人も出口に並んでお見送りなのですが、ちょっと照れくさかったです。
前回、スバルの車を買ったときは、もろもろの手続きを終えて、そのまま車を渡されたのですが、今回は、なんと納車ルームなるものがありました。
立派な部屋の中に、Audiが置かれていました。
今では、当たり前になっている(らしい)納車式ですが、もともとは、Audiのドイツで行われていたものだそうです。
個人的には、契約したディーラーで車を受け取る感覚なのですが、ドイツでは製造工場で直接車を受け取りたいみたいです。
しかも、オプションらしく少し割高になるらしい。
話を戻して、、、もろもろの手続きを終えたら、ノンアルコールのワインをもらいました。
昔は、シャンパンなどをもらえたそうですが、アルコール飲料と車の相性がわるく、今では、ノンアルコールになったそうです。
その後、納車ルームからそのままAudiに乗って帰ってきました。
営業の人だけでなく、整備士さんや受付の人も出口に並んでお見送りなのですが、ちょっと照れくさかったです。
ヤキモキ・タンゴ [ファミリー]
今日は、息子のピアノの発表会でした。
昨年は、『タランティラ』という曲でしたが、今年は、『ヤキモキ・タンゴ (作曲: キャサリン・ロリン)』でした。
去年よりかは指の動きが難しくなっているみたいで、本番直前まで、なかなか上達しませんでしたが、前日あたりから急に上達してきました。
本番は、途中で少し間違えてしまいましたが、無事に最後まで弾くことができました。
けっこう人が入っていましたが、あまり緊張しなかったようで、本番に強い精神力なのかもしれません。
昨年は、『タランティラ』という曲でしたが、今年は、『ヤキモキ・タンゴ (作曲: キャサリン・ロリン)』でした。
去年よりかは指の動きが難しくなっているみたいで、本番直前まで、なかなか上達しませんでしたが、前日あたりから急に上達してきました。
本番は、途中で少し間違えてしまいましたが、無事に最後まで弾くことができました。
けっこう人が入っていましたが、あまり緊張しなかったようで、本番に強い精神力なのかもしれません。
時系列解析 季節調整済みARIMAモデルを推定 [時系列解析 / 需要予測]
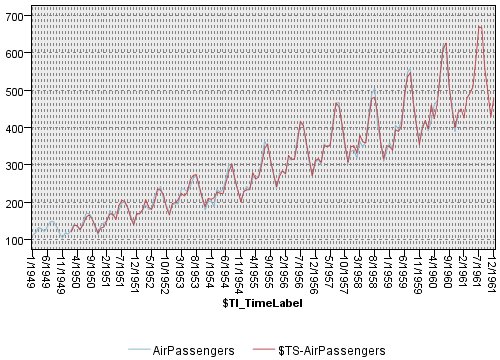
Rのパッケージをインストールするとついてくる有名な時系列のデータAirPassengersがあります。
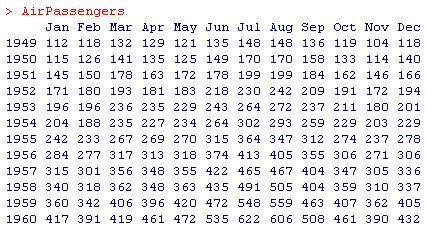
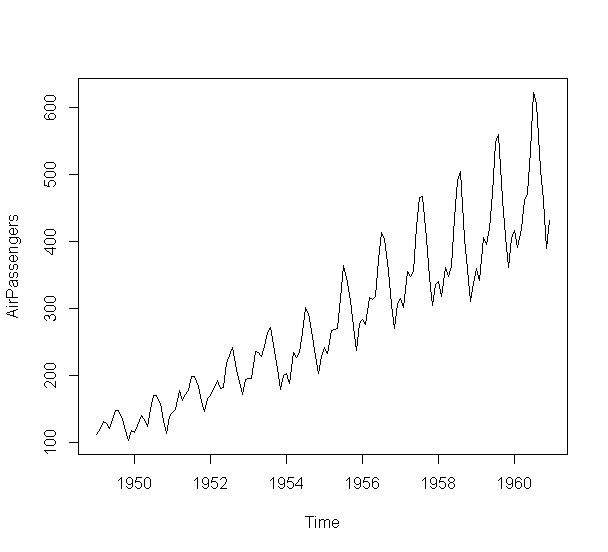
このような時系列データは、企業の売上データとしてよく見るかと思います。
特徴としては、
・はっきりとした季節性がみられる
・時間とともに売上や人数といった(平均値)が大きくなる
・時間とともに売上や人数といった(分散)が大きくなる
となっています。
時系列においては、定常か非定常かがとても重要で、このデータは明らかに非定常の時系列となっています。
このようなデータを季節調整済みARIMA(SARIMA)を使って時系列分析を行っていきます。
SPSS ModelerにもARIMAが実装されているので、同様のアプローチで分析が可能です。
この様な時系列データを分析する手順としては、
1. logで置換
2. 自己相関と偏相関を確認する
3. 階差を取って、自己相関と偏相関を確認する
4. 季節階差を取って、自己相関と偏相関を確認する
5. SARIMA(0,1,1)(0,1,1)でフィッティング
6. 予測をする
となります。
SARIMA(0,1,1)(0,1,1)は別名、エアラインモデルとも呼ばれているそうです。
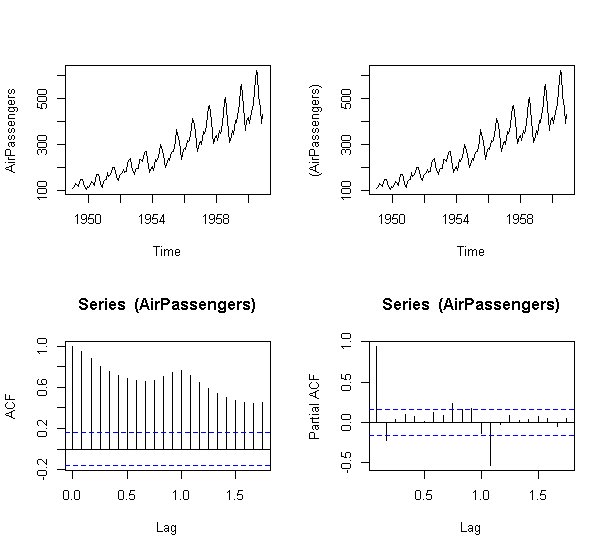
左上:元の時系列
右上:元の時系列のlogを取ったもの
左下:自己相関
右下:偏自己相関
自己相関を見ると、1期前,2期前,3期前,・・・,n期前の情報がダラダラと残っていることがわかります。
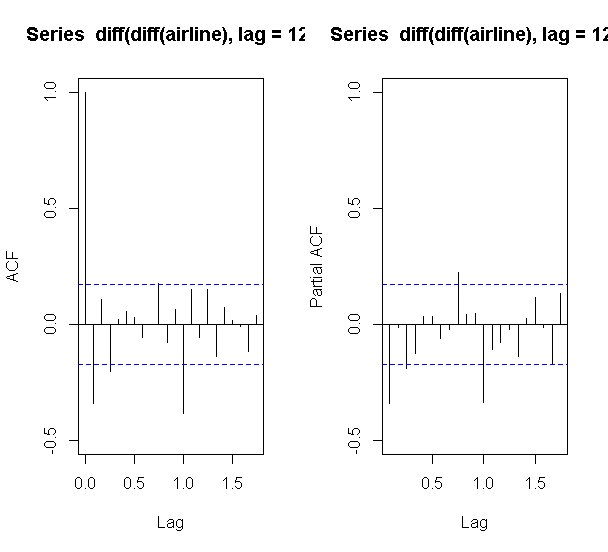
偏相関を見ると、ちょうど1年前の相関がありますが、それ以外の相関は消えていることが分かります。
acfのオプション type="partial" で偏自己相関をプロットできます。
オプション一覧はこちら。
type="correlation" :自己相関(デフォルト)
type="covariance":自己共分散
type="partial":偏相関

data(AirPassengers)
plot(AirPassengers)
このような時系列データは、企業の売上データとしてよく見るかと思います。
特徴としては、
・はっきりとした季節性がみられる
・時間とともに売上や人数といった(平均値)が大きくなる
・時間とともに売上や人数といった(分散)が大きくなる
となっています。
時系列においては、定常か非定常かがとても重要で、このデータは明らかに非定常の時系列となっています。
このようなデータを季節調整済みARIMA(SARIMA)を使って時系列分析を行っていきます。
SPSS ModelerにもARIMAが実装されているので、同様のアプローチで分析が可能です。
この様な時系列データを分析する手順としては、
1. logで置換
2. 自己相関と偏相関を確認する
3. 階差を取って、自己相関と偏相関を確認する
4. 季節階差を取って、自己相関と偏相関を確認する
5. SARIMA(0,1,1)(0,1,1)でフィッティング
6. 予測をする
となります。
SARIMA(0,1,1)(0,1,1)は別名、エアラインモデルとも呼ばれているそうです。
## 1. logで置換
## 2. 自己相関と偏相関を確認する
par(mfrow=c(2,2))
plot(AirPassengers)
plot(log(AirPassengers))
acf(log(AirPassengers))
acf(log(AirPassengers),type="partial")
airline <- log(AirPassengers)
左上:元の時系列
右上:元の時系列のlogを取ったもの
左下:自己相関
右下:偏自己相関
自己相関を見ると、1期前,2期前,3期前,・・・,n期前の情報がダラダラと残っていることがわかります。
偏相関を見ると、ちょうど1年前の相関がありますが、それ以外の相関は消えていることが分かります。
acfのオプション type="partial" で偏自己相関をプロットできます。
オプション一覧はこちら。
type="correlation" :自己相関(デフォルト)
type="covariance":自己共分散
type="partial":偏相関
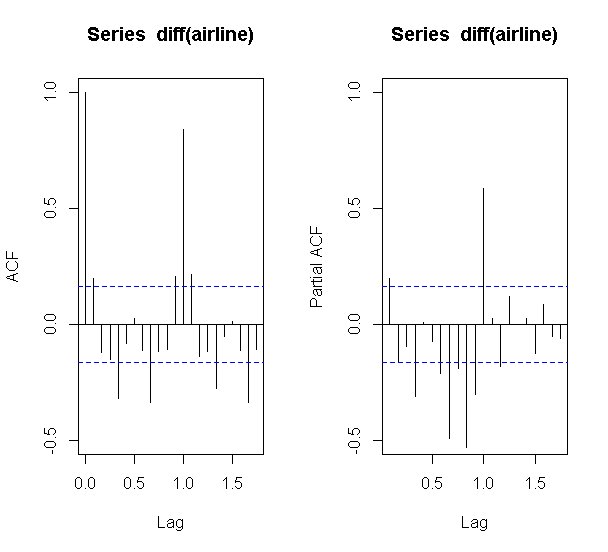
## 3. 階差を取って、自己相関と偏相関を確認する
par(mfrow=c(1,2))
acf(diff(airline),ylim=c(-0.5,1.0))
acf(diff(airline),type="partial", ylim=c(-0.5,1.0))
## 4. 季節階差を取って、自己相関と偏相関を確認する
par(mfrow=c(1,2))
acf(diff(diff(airline),lag=12),ylim=c(-0.5,1.0))
acf(diff(diff(airline),lag=12),type="partial", ylim=c(-0.5,1.0))
## 5. SARIMA(0,1,1)(0,1,1)でフィッティング
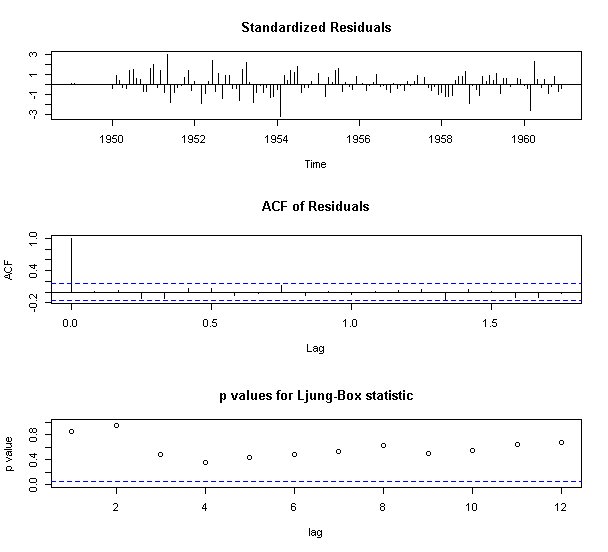
fit <- arima(airline, order=c(0,1,1), seasonal=list(order=c(0,1,1),period=12))
tsdiag(fit, gof.lag=12)
## 6. 予測をする
predict(fit, n.ahead=12)
時系列解析 季節調整済みARIMAモデルを推定 その2 [時系列解析 / 需要予測]
時系列解析 季節調整済みARIMAモデルを推定
http://skellington.blog.so-net.ne.jp/2018-02-19
↑
同じようなアプローチをSPSS Modelerを使って行っていきます。
データは、RのAirPassengersのデータを使います。
【時間区分】ノードの設定
時間区分:月数
年月のラベル:1949年1月に設定
将来への拡張:12か月分を予測
【時系列(モデル)】ノードの設定
今回のデータは、
・エキスパートモデラー
・ARIMA(0,1,1)(0,1,1)
のどちらも同じ結果となりました。
自動モデリング(エキスパートモデラー)ではなく、手動で行う場合は、下図となります。
対象の時系列の変換で、"自然対数"に設定しておきます。
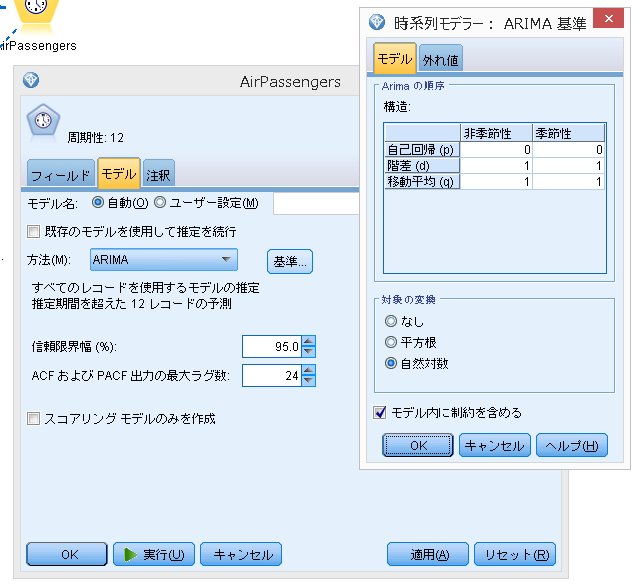
後は、モデルを作成し終了。
出力結果(将来の予測)を確認すると、Rのパッケージで予測したものとほとんど同じ値になっていました。
http://skellington.blog.so-net.ne.jp/2018-02-19
↑
同じようなアプローチをSPSS Modelerを使って行っていきます。
データは、RのAirPassengersのデータを使います。
【時間区分】ノードの設定
時間区分:月数
年月のラベル:1949年1月に設定
将来への拡張:12か月分を予測
【時系列(モデル)】ノードの設定
今回のデータは、
・エキスパートモデラー
・ARIMA(0,1,1)(0,1,1)
のどちらも同じ結果となりました。
自動モデリング(エキスパートモデラー)ではなく、手動で行う場合は、下図となります。
対象の時系列の変換で、"自然対数"に設定しておきます。
後は、モデルを作成し終了。
出力結果(将来の予測)を確認すると、Rのパッケージで予測したものとほとんど同じ値になっていました。
【モンスト】レディドルチェ、運極達成 [ゲーム]
バレンタイン限定の降臨モンスターとして、ココアとドルチェが降臨していますね。
まずは、作りやすいドルチェの運極を作りました。

1. オニオンナイト(進化)
2. オニオンナイト(進化)
3. オニオンナイト(進化)
4. マナ(進化)
ということで、運枠3人ともオニオンナイト(進化)にしました。
SSのジョブチェンジで、マナ(進化)に進化できるのもポイントです。
マナに当たりに行くだけなので、オリンピック見ながらでも、クリアできました。
まずは、作りやすいドルチェの運極を作りました。
1. オニオンナイト(進化)
2. オニオンナイト(進化)
3. オニオンナイト(進化)
4. マナ(進化)
ということで、運枠3人ともオニオンナイト(進化)にしました。
SSのジョブチェンジで、マナ(進化)に進化できるのもポイントです。
マナに当たりに行くだけなので、オリンピック見ながらでも、クリアできました。
【モンスト】ココア、運極達成 [ゲーム]
バレンタイン限定の降臨モンスターとして、ココアとドルチェが降臨していますね。
ドルチェの次に作った運極はココアです。
ドルチェは、運枠3人でも余裕だったのですが、ココアは運枠1人にしました。

1. エレシュキ(進化)
2. 坂本龍馬(獣神化)
3. マナ(神化)
4. パンドラ(神化)
反射制限が出てくるので、貫通を多めでパンドラを引っ張る作戦です。
坂本龍馬がダメージウォールに突っ込むことに注意する以外は難しいところはないかと思われます。
ドルチェの次に作った運極はココアです。
ドルチェは、運枠3人でも余裕だったのですが、ココアは運枠1人にしました。
1. エレシュキ(進化)
2. 坂本龍馬(獣神化)
3. マナ(神化)
4. パンドラ(神化)
反射制限が出てくるので、貫通を多めでパンドラを引っ張る作戦です。
坂本龍馬がダメージウォールに突っ込むことに注意する以外は難しいところはないかと思われます。
国立極地研究所 南極・北極科学館 [よもやま日記]
立川にある統計数理研究所に行ったのですが、そのすぐ隣に「国立極地研究所 南極・北極科学館」があります。
国立極地研究所 南極・北極科学館
http://www.nipr.ac.jp/science-museum/
元々あるのは知っていたのですが、一度も入ったことはありませんでした。
先週、『イッテQ!』で「ヴィンソン・マシフ」の登頂を見た影響もあり、入ってみることにしました。
入館料:無料
開園時間:10:00~16:30
休館日:日曜日、月曜日、祝日、年末年始
・南極の模型

・昭和基地から南極点まで観測旅行へ行った雪上車

他には、オーロラのシアタールームがあったり、南極の氷に触れたりしました。
ただ、南極の氷はそのままむき出しで、少しずつ溶けて小さくなっていたのですが、毎日、取り替えているんでしょうかね?w
国立極地研究所 南極・北極科学館
http://www.nipr.ac.jp/science-museum/
元々あるのは知っていたのですが、一度も入ったことはありませんでした。
先週、『イッテQ!』で「ヴィンソン・マシフ」の登頂を見た影響もあり、入ってみることにしました。
入館料:無料
開園時間:10:00~16:30
休館日:日曜日、月曜日、祝日、年末年始
・南極の模型
・昭和基地から南極点まで観測旅行へ行った雪上車
他には、オーロラのシアタールームがあったり、南極の氷に触れたりしました。
ただ、南極の氷はそのままむき出しで、少しずつ溶けて小さくなっていたのですが、毎日、取り替えているんでしょうかね?w
アプリケーションエンジニアのためのApache Spark入門 [Hadoop / Spark]
『アプリケーションエンジニアのためのApache Spark入門』が発売され、寄贈されました。

アマゾンでベストセラーマークが付いていますね。
せっかくなので、これを機会に、Apache Sparkを触ってみたいと思います。
アプリケーションエンジニアのためのApache Spark入門
- 作者: 新郷美紀
- 出版社/メーカー: 秀和システム
- 発売日: 2018/02/17
- メディア: 単行本
アマゾンでベストセラーマークが付いていますね。
せっかくなので、これを機会に、Apache Sparkを触ってみたいと思います。
平昌オリンピック、閉会式 [時事 / ニュース]
始まる前は、なんだかんだと心配した平昌オリンピックでしたが、始まってみるとなんだかんだと観てしまいます。
いつもは終電ギリギリまで会社で仕事をしていることが多いですが、平昌オリンピックの開催期間はなるべく早く帰り、テレビで応援していました。
次は、2020年の東京オリンピック!
できれば現地で応援したいものです。
いつもは終電ギリギリまで会社で仕事をしていることが多いですが、平昌オリンピックの開催期間はなるべく早く帰り、テレビで応援していました。
次は、2020年の東京オリンピック!
できれば現地で応援したいものです。
レゴ(LEGO) ニンジャゴー ニンジャ・ナイトクローラー 70641 [ファミリー]
息子のピアノ発表会のご褒美に購入しました。
 ニンジャゴー ニンジャ・ナイトクローラー 70641")
新商品らしく、あまり口コミがないのですが・・・。
小学2年生ですが、二日かけて自力で作っていました。

車を動かすと自動でミサイルが発射される仕組みになっています。
特にバネとか使わずに、ミサイルが出てくる仕組みは驚きです。
息子と二人で、「この仕組みすごいね~」と盛り上がっていました。
子供にとって良い刺激になると思います。
レゴ(LEGO) ニンジャゴー ニンジャ・ナイトクローラー 70641
- 出版社/メーカー: レゴ(LEGO)
- メディア: おもちゃ&ホビー
新商品らしく、あまり口コミがないのですが・・・。
小学2年生ですが、二日かけて自力で作っていました。
車を動かすと自動でミサイルが発射される仕組みになっています。
特にバネとか使わずに、ミサイルが出てくる仕組みは驚きです。
息子と二人で、「この仕組みすごいね~」と盛り上がっていました。
子供にとって良い刺激になると思います。
R Tips:ヒストグラム [データサイエンス、統計モデル]
Rでヒストグラムの使い方は、色々なサイトに載っていますが、最近知った面白い使い方を紹介。
ここで、hist(dat)を別の変数 "x" に渡すことが出来るようです。
これを使えば、色々な情報をコマンドで得られますね。
# サンプルデータを作成
# 標準正規分布に従うデータを1000レコード作成
dat <- rnorm(1000, mean=0, sd=1.0)
# ヒストグラムを作成
hist(dat)
ここで、hist(dat)を別の変数 "x" に渡すことが出来るようです。
これを使えば、色々な情報をコマンドで得られますね。
# 変数 "x" にヒストグラムを格納
x <- hist(dat)
# ヒストグラムの情報を確認
x
# 例えば、ヒストグラムの密度を取り出す場合
x$density
# ヒストグラムの密度の最大値の位置
which.max(x$density)
# ヒストグラムの密度の最大値の値
x$density[which.max(x$density)]
R Tips:不偏分散と標本分散 [データサイエンス、統計モデル]
Rで不偏分散ではなく、標本分散を計算しようとしたら、不偏分散の関数しかないようです。
それほど難しくないので、下記のような関数を作れば、標本分散を求めることが出来ます。
基本情報として、サンプルサイズをnとして
nで割るのが、標本分散
n-1で割るのが不偏分散
ということは、不偏分散の値を var(x)とすると
標本分散 = var(x) * (n-1) / n
となります。
それほど難しくないので、下記のような関数を作れば、標本分散を求めることが出来ます。
基本情報として、サンプルサイズをnとして
nで割るのが、標本分散
n-1で割るのが不偏分散
ということは、不偏分散の値を var(x)とすると
標本分散 = var(x) * (n-1) / n
となります。
# 不偏分散を求める関数 var
# 標本分散を求める関数 varp
varp <- function(x) { var(x) * (length(x)-1) / length(x) }

