SPSS Clementine でユーザーベースの協調フィルタリングを実装する方法 [データサイエンス、統計モデル]
SPSS Clementine でユーザーベースの協調フィルタリングを実装する方法
SPSS Clementine(PASW Modeler)でユーザーベースの協調フィルタリングを作った。
モデルに使ったデータは、
ユーザ数:5,000
アイテム数:40
レコード数:12,000行
だ。
ここで、クラスタを作成することで計算時間を早くすることを考える。
クラスタ数:20
1クラスタあたり、250人程度。
処理にかかった実行時間としては、約15秒~20秒程度。
クラスタをかまさないと、約3分程度かかってしまった。
さて、Clementine への実装方法だが、まず下記の様な raw data を考える。
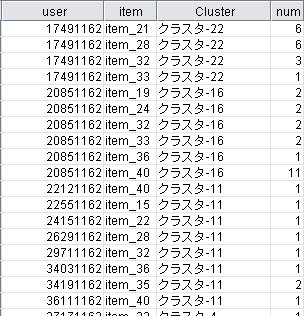
Cluster のフィールドがついているが、あらかじめ用意しておく。
どうやってクラスタを作るかは今回省略。
類似度の計算は、下記の様なストリーム(プログラミング)で計算できる。
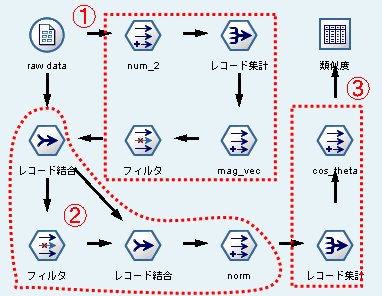
では、一つ一つノードの中身を見ていく。
今回、計算に用いたアルゴリズムとしては、コサイン類似度を使っている。
【①の部分】
派生フィールド: num_2
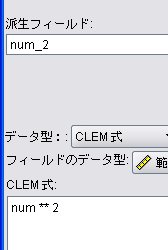
レコード集計
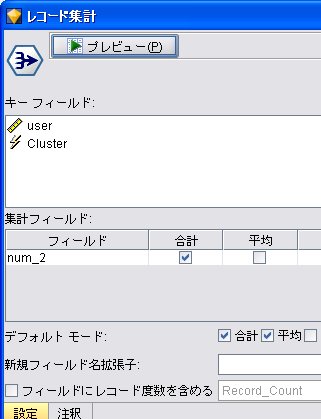
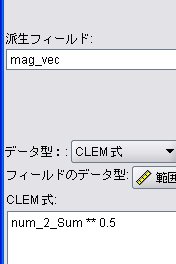
派生フィールド: mag_vec
フィルタ

【②の部分】
レコード結合
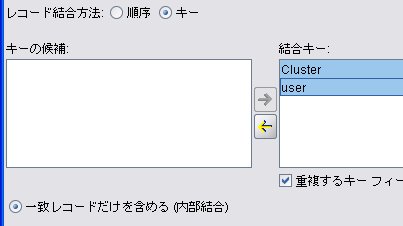
※クラスタがない場合は、user だけで内部結合すれば、OK。
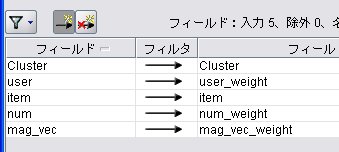
フィルタ
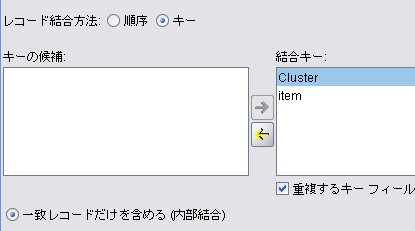
レコード結合
派生フィールド: norm
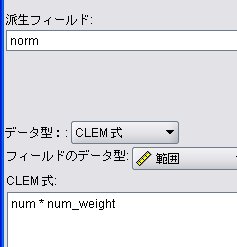
【③の部分】
レコード集計
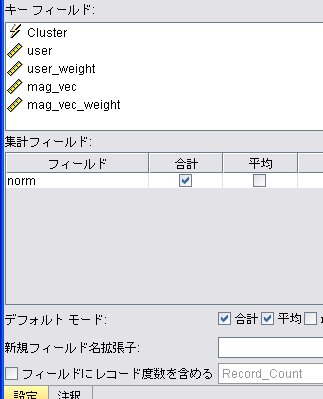
派生フィールド: cos_theta
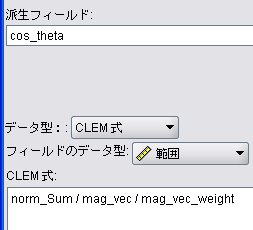
【結果】
ユーザとユーザとの類似度は、
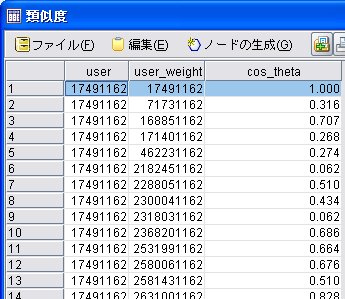
と計算できる。
同じユーザのレコードは、類似度は、1.000になるので、同一ユーザのレコードは削除して使えばよい。
このように類似度が計算できれば、ここから先は、これらを重みに考えて、itemのscoreを計算するだけとなる。
以下の実装過程は省略。
~ その他、過去の参考ブログ ~
★ アイテムベースの協調フィルタリングの話 ★
・アイテムベースの協調フィルタリングの作り方 その1
http://skellington.blog.so-net.ne.jp/2009-08-20
・アイテムベースの協調フィルタリングの作り方 その2
http://skellington.blog.so-net.ne.jp/2009-08-21
★ ユーザーベースでの協調フィルタリングの話 ★
・ユーザベースの協調フィルタリングの一般的な原理
http://skellington.blog.so-net.ne.jp/2009-08-26
・ユーザベースの協調フィルタリングの拡張
http://skellington.blog.so-net.ne.jp/2009-08-27
SPSS Clementine(PASW Modeler)でユーザーベースの協調フィルタリングを作った。
モデルに使ったデータは、
ユーザ数:5,000
アイテム数:40
レコード数:12,000行
だ。
ここで、クラスタを作成することで計算時間を早くすることを考える。
クラスタ数:20
1クラスタあたり、250人程度。
処理にかかった実行時間としては、約15秒~20秒程度。
クラスタをかまさないと、約3分程度かかってしまった。
さて、Clementine への実装方法だが、まず下記の様な raw data を考える。
Cluster のフィールドがついているが、あらかじめ用意しておく。
どうやってクラスタを作るかは今回省略。
類似度の計算は、下記の様なストリーム(プログラミング)で計算できる。
では、一つ一つノードの中身を見ていく。
今回、計算に用いたアルゴリズムとしては、コサイン類似度を使っている。
【①の部分】
派生フィールド: num_2
レコード集計
派生フィールド: mag_vec
フィルタ
【②の部分】
レコード結合
※クラスタがない場合は、user だけで内部結合すれば、OK。
フィルタ
レコード結合
派生フィールド: norm
【③の部分】
レコード集計
派生フィールド: cos_theta
【結果】
ユーザとユーザとの類似度は、
と計算できる。
同じユーザのレコードは、類似度は、1.000になるので、同一ユーザのレコードは削除して使えばよい。
このように類似度が計算できれば、ここから先は、これらを重みに考えて、itemのscoreを計算するだけとなる。
以下の実装過程は省略。
~ その他、過去の参考ブログ ~
★ アイテムベースの協調フィルタリングの話 ★
・アイテムベースの協調フィルタリングの作り方 その1
http://skellington.blog.so-net.ne.jp/2009-08-20
・アイテムベースの協調フィルタリングの作り方 その2
http://skellington.blog.so-net.ne.jp/2009-08-21
★ ユーザーベースでの協調フィルタリングの話 ★
・ユーザベースの協調フィルタリングの一般的な原理
http://skellington.blog.so-net.ne.jp/2009-08-26
・ユーザベースの協調フィルタリングの拡張
http://skellington.blog.so-net.ne.jp/2009-08-27

