Clementine の標準偏差って n と n-1 のどっち? [データサイエンス、統計モデル]
Clementine の標準偏差って n と n-1 のどっち?
一般的に分散っていわれると、n で割る場合が多いのではないだろうか。
分散(正確には標本分散)は、
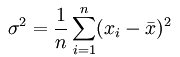
という式で計算できる。
分散には、不偏分散というものがあり、
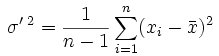
で計算される。
不偏分散の期待値は母集団の分散に等しいという性質がある。
この分散または不偏分散の正の平方根が標準偏差σなのだが、SPSS Clementine の標準偏差って n、または、n-1 のどっちで割った値なんだろう?
ちなみに、エクセルの関数(STDEV)は、n-1 で割った値を返している。
SPSS Clementine(PASW@ Modeler)で標準偏差を計算する場合、いくつか方法があるのだが、
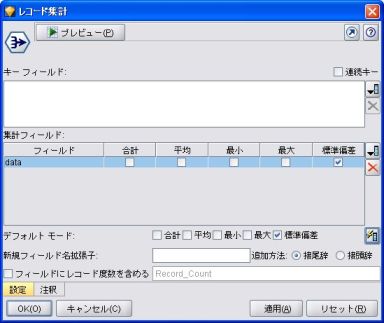
1. レコード集計で計算する方法
2. CLEM式の @SDEV を使う方法
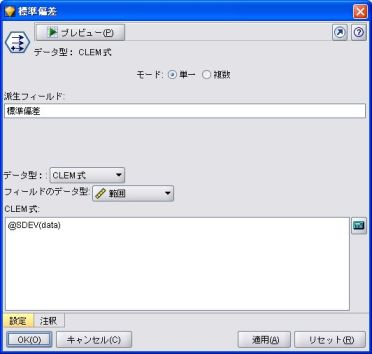
がある。
結果を調べると、、、n-1で割ったものとなっている。
AlgorithmsGuide.pdf をみても、やはり、n-1となっていた。
データマイニングの世界だと、大量のデータを扱うので、
(例えば、10万件とか100万件とか)
100,000 で割ろうと、100,001 でそんなに差はないのだが、、、
たまにはこういう細かい部分をつついてみるのも面白い。
一般的に分散っていわれると、n で割る場合が多いのではないだろうか。
分散(正確には標本分散)は、
という式で計算できる。
分散には、不偏分散というものがあり、
で計算される。
不偏分散の期待値は母集団の分散に等しいという性質がある。
この分散または不偏分散の正の平方根が標準偏差σなのだが、SPSS Clementine の標準偏差って n、または、n-1 のどっちで割った値なんだろう?
ちなみに、エクセルの関数(STDEV)は、n-1 で割った値を返している。
SPSS Clementine(PASW@ Modeler)で標準偏差を計算する場合、いくつか方法があるのだが、
1. レコード集計で計算する方法
2. CLEM式の @SDEV を使う方法
がある。
結果を調べると、、、n-1で割ったものとなっている。
AlgorithmsGuide.pdf をみても、やはり、n-1となっていた。
データマイニングの世界だと、大量のデータを扱うので、
(例えば、10万件とか100万件とか)
100,000 で割ろうと、100,001 でそんなに差はないのだが、、、
たまにはこういう細かい部分をつついてみるのも面白い。

