入門 共分散構造分析の実際: 5章 事例に見る分析結果の読み方 [入門 共分散構造分析の実際]
入門 共分散構造分析の実際: 5章 事例に見る分析結果の読み方

- 作者: 朝野 煕彦, 小島 隆矢, 鈴木 督久
- 出版社/メーカー: 講談社
- 発売日: 2005/12/20
- メディア: 単行本
5章 事例に見る分析結果の読み方で書かれていることは
5.1 板橋ひったくりマップについての住民意識調査
5.2 仮説の構築を進める
5.3 モデリングの実際
5.4 モデルの解釈
5.5 共分散構造分析のご利益
です。
この章の狙いは
・仮説が強固でない場合の調査設計・探索的モデリング
・やや複雑な因果モデルの読み方に慣れる
・重回帰と比べてSEMはどこが優れているか
と書かれています。
【適合度検定】
SEMでは、サンプル数が大きくなると、モデルとデータのわずかな乖離も見逃さないほど適合度検定の検出力が高くなり、たいていのモデルは棄却されてしまう。
このあたりはデータマイニングでも言えることだが、往来は、モデルが正しいか間違っているかを考えていた。
しかし、T or F の世界ではなく、どれくらい正しいのか、どれくらい間違っているのかといったグレーな比較ができる指標が大切になってくる。
それが、GFI, AGFI, SRMR, CFI, RMSEA といった指標である。
【潜在変数は「真値」を表す】
観測変数は、実際に測定して得られる変数である。
つまり、そこには「測定誤差」が存在する。
逆に、潜在変数は、測定誤差を含まない「真の値」である。
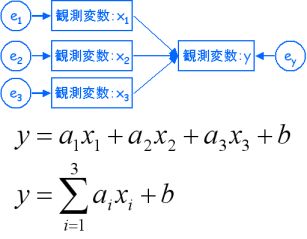
ここで、決定係数(coefficient of determination)についての話。
決定係数とは、基準変数の分散のうち、説明変数で説明できる割合のことである。
決定係数はモデル内の要因による「真値」に対する説明力を表している。
結果変数(目的変数)が観測変数の場合、誤差変数には測定誤差も含まれる。
その分だけ誤差変数の分散が大きくなり、決定係数や標準化係数が小さくなる。
では、決定係数がどれだけあれば良いのか?
例えば、決定係数が 0.5 であったとする。
測定誤差を含む観測変数の場合、0.5 も説明できる!といえるが、逆に、測定誤差を含まない潜在変数の場合、0.5 しか説明できない…となってしまう。
潜在変数と観測変数のでは、決定係数や標準化パス係数の評価基準は変える必要がある。
【潜在変数は相関の高い変数を整理する】
重回帰分析で、説明変数を増やしたり減らしたり、あるいは、どの説明変数を選択するかで偏回帰係数の値が大きく変わったことがないだろうか。
今までは、係数の値が大きかったのに、ほとんど効果がなくなってしまったり、あるいは、今までプラスだった値がマイナスになってしまったりすることも少なくはない。
本来プラスの意味であるはずなのに、マイナスになってしまったりと。
SEMによる分析では、互いに相関が高い観測変数の背後に共通の潜在因子をおくことによって変数を整理することができるので、上記の様な変数選択の悩みは軽減される。

- 作者: 朝野 煕彦
- 出版社/メーカー: 講談社
- 発売日: 2000/10
- メディア: 単行本(ソフトカバー)
⌒ヽ / /
_ノ ∠_____________ / .|
/\ \ |
.\ \ \ |
○ / \ \ \ |
/> / / \ \ \ , "⌒ヽ /
/// ./ / .\ \ \ i .i ./
./\\\ / / \ \ \ .ヽ、_ノ /
/ .\\ ./ / \ \ \ .| /
\ \\ ./ .∧ ∧ /. \ \ \ | /
\ \\∪(・ω・) / \ \ \ .| /
o .\ \\ ⊂ノ / \ \ \ | /
"⌒ヽ . \\ / \ \ \| /
i i \\ ○ _\ \/|/
○ ヽ _.ノ .\ \\ _,. - ''",, -  ̄
\ \\_,. - ''",. - '' o


コメント 0