IBM SPSS Modeler: ループ/条件付き実行のスクリプト 前半 [データサイエンス、統計モデル]
※ IBM insight 2015 の "Automation in IBM SPSS Modeler Using Python and R" を元にしています。
【目的】
様々な変数でクロス集計を行いたいが、いちいちクロス集計ノードを追加するのは面倒だし、見栄えが悪くなる。
そこで、スクリプトでループ処理ができないか?
【設定方法】
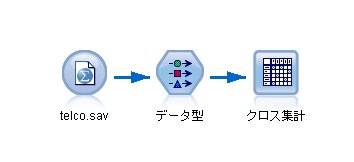
1. スクリプトを設定する前に、クロス集計ノードの設定から。
デモデータで用意されているtelco.savを使います。
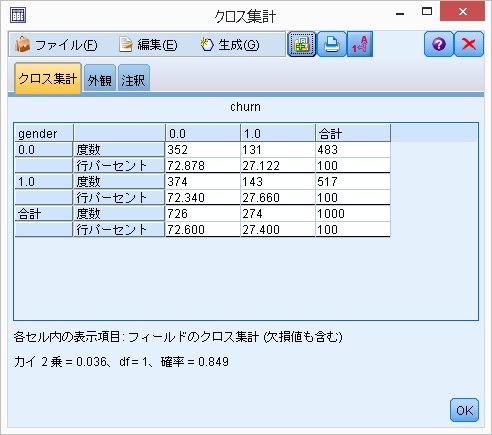
行に[gender]、列に[churn]を持ってきます。
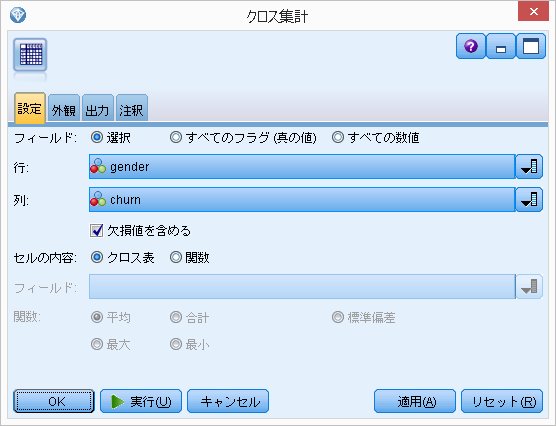
後で、この[gender]部分にいろんな変数を入れるやり方を紹介します。
外観と注釈を少しいじっておきます。
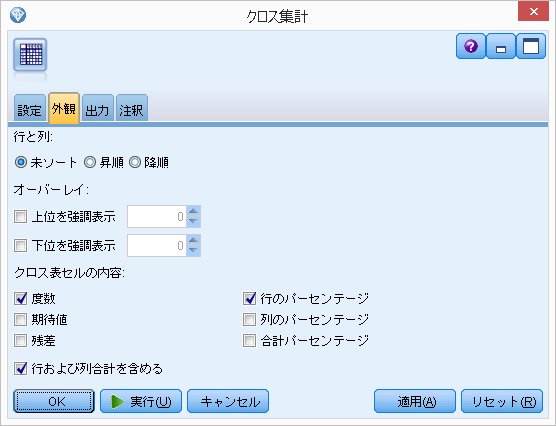
アウトプットはこんな感じになるかと。
2. 続いてループ処理の設定方法
ループ処理を行うやり方はいろいろあります。
スクリプトを書くというやり方もありますが、まずは、一番簡単な(?)方法を紹介します。
クロス集計ノードを右クリックして、
[ループ/条件付き実行] → [反復キーの定義(フィールド)]
をクリックします。

反復対象が [ノード プロパティー - フィールド] になっていることを確認。
既に [クロス集計:matrix] という値が入っている場合はそのまま。
入っていなければ、ノード(N)の右をクリックし、[クロス集計]を選択します。
下のプロパティは、[row]を選択します。
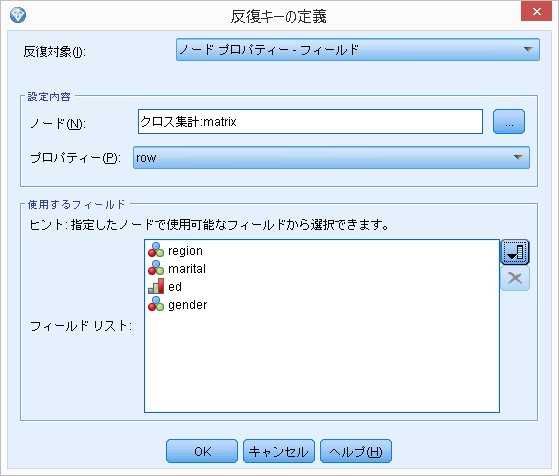
最後に、フィールドリストを選択し、[region]、[marital]、[ed]、[gender]を選択し、OKを押します。
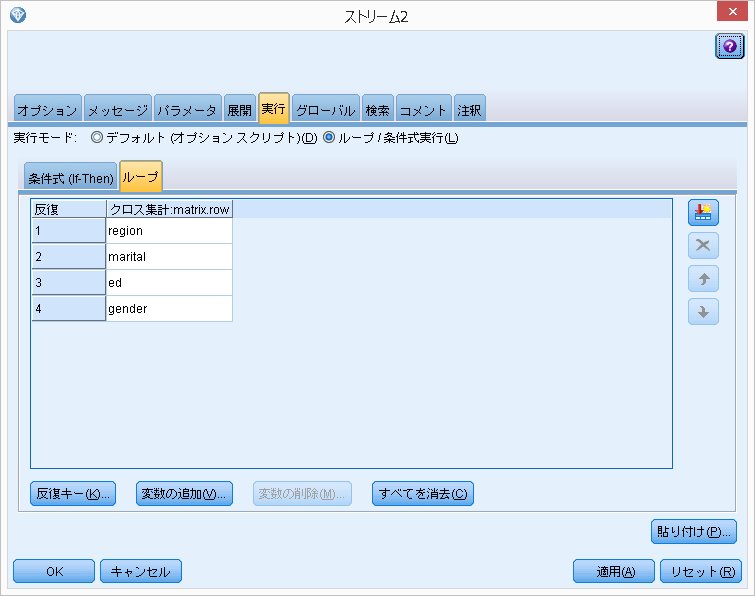
クロス集計は、[region] -> [marital] -> [ed] -> [gender] という順番で実行されます。
ここで、やりたいことを再度確認すると、列(column)の[churn]を固定して行(row)の[gender]部分に色々な変数を代入してループ処理を行っていきます。
ここで注意なのですが、SPSS Modelerのスクリプトを使ったループ処理は、行でも列でもどちらでもループ処理はできるのですが、行と列のダブルループはできません。
では、どうするか?といえば、Python Scriptを使う必要があります。
Python Scriptは、また、別の機会にでも。。。
【目的】
様々な変数でクロス集計を行いたいが、いちいちクロス集計ノードを追加するのは面倒だし、見栄えが悪くなる。
そこで、スクリプトでループ処理ができないか?
【設定方法】
1. スクリプトを設定する前に、クロス集計ノードの設定から。
デモデータで用意されているtelco.savを使います。
行に[gender]、列に[churn]を持ってきます。
後で、この[gender]部分にいろんな変数を入れるやり方を紹介します。
外観と注釈を少しいじっておきます。
アウトプットはこんな感じになるかと。
2. 続いてループ処理の設定方法
ループ処理を行うやり方はいろいろあります。
スクリプトを書くというやり方もありますが、まずは、一番簡単な(?)方法を紹介します。
クロス集計ノードを右クリックして、
[ループ/条件付き実行] → [反復キーの定義(フィールド)]
をクリックします。
反復対象が [ノード プロパティー - フィールド] になっていることを確認。
既に [クロス集計:matrix] という値が入っている場合はそのまま。
入っていなければ、ノード(N)の右をクリックし、[クロス集計]を選択します。
下のプロパティは、[row]を選択します。
最後に、フィールドリストを選択し、[region]、[marital]、[ed]、[gender]を選択し、OKを押します。
クロス集計は、[region] -> [marital] -> [ed] -> [gender] という順番で実行されます。
ここで、やりたいことを再度確認すると、列(column)の[churn]を固定して行(row)の[gender]部分に色々な変数を代入してループ処理を行っていきます。
ここで注意なのですが、SPSS Modelerのスクリプトを使ったループ処理は、行でも列でもどちらでもループ処理はできるのですが、行と列のダブルループはできません。
では、どうするか?といえば、Python Scriptを使う必要があります。
Python Scriptは、また、別の機会にでも。。。


コメント 0