ユーザベースの協調フィルタリングの一般的な原理 [データサイエンス、統計モデル]
以前、
★ アイテムベースの協調フィルタリングの作り方 その1 ★
http://skellington.blog.so-net.ne.jp/2009-08-20
★ アイテムベースの協調フィルタリングの作り方 その2 ★
http://skellington.blog.so-net.ne.jp/2009-08-21
という記事を書いた。
今度は、ユーザベースの協調フィルタリングの話。
例として、5人のユーザが下記の4つの食べ物について食べたい度合い(得点)を付けたとする。

Step1
ユーザとユーザの距離をコサイン類似度や相関係数などを利用して計算する。
このあたりの距離をどう計算するかは、一つの研究課題。
ユーザ数が M 人いた場合、M ×(M - 1)個の類似度を計算する。

得点(連続値)ではなく、1 or 0 で与えてあげれば、アクションする/しないの判別分析に使うことができる。
Step2
iさんは、チョコを買う/買わない?
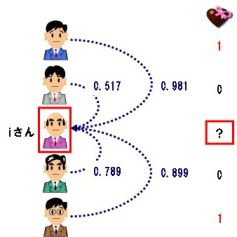
( 1 × 0.981 + 0 × 0.517 + 0 × 0.789 + 1 × 0.899 )
= -----------------------------------------------------
0.981 + 0.517 + 0.789 + 0.899
= 0.590
全ユーザの類似度を用いて計算をするか、自分に近いユーザの集合だけを用いて計算をするかは、一つの研究課題。
以下、iさんのステップを全ユーザに対して行う。
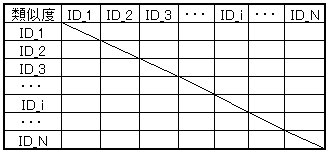
実際、計算しているのは、ユーザ間の類似性を表す行列(Kernel行列)。
この方法を、素直にSPSS Clementine(PASW Modeler)で実装すると、ユーザ数が増えてくると、必要HDD空き容量、計算時間が激しくかかる。
どう改良したかは、また、別の機会で書くとする。
★ アイテムベースの協調フィルタリングの作り方 その1 ★
http://skellington.blog.so-net.ne.jp/2009-08-20
★ アイテムベースの協調フィルタリングの作り方 その2 ★
http://skellington.blog.so-net.ne.jp/2009-08-21
という記事を書いた。
今度は、ユーザベースの協調フィルタリングの話。
例として、5人のユーザが下記の4つの食べ物について食べたい度合い(得点)を付けたとする。
Step1
ユーザとユーザの距離をコサイン類似度や相関係数などを利用して計算する。
このあたりの距離をどう計算するかは、一つの研究課題。
ユーザ数が M 人いた場合、M ×(M - 1)個の類似度を計算する。
得点(連続値)ではなく、1 or 0 で与えてあげれば、アクションする/しないの判別分析に使うことができる。
Step2
iさんは、チョコを買う/買わない?
( 1 × 0.981 + 0 × 0.517 + 0 × 0.789 + 1 × 0.899 )
= -----------------------------------------------------
0.981 + 0.517 + 0.789 + 0.899
= 0.590
全ユーザの類似度を用いて計算をするか、自分に近いユーザの集合だけを用いて計算をするかは、一つの研究課題。
以下、iさんのステップを全ユーザに対して行う。
実際、計算しているのは、ユーザ間の類似性を表す行列(Kernel行列)。
この方法を、素直にSPSS Clementine(PASW Modeler)で実装すると、ユーザ数が増えてくると、必要HDD空き容量、計算時間が激しくかかる。
どう改良したかは、また、別の機会で書くとする。

