小学校の音楽会 [ファミリー]
今日は、小学校の音楽会でした。
いろんな歌を歌ったり、ピアニカで演奏したりしていました。
小学校1年生なのですが、ピアニカで演奏している姿を見ていると、ここまで弾けるようになったんだなぁって感心です。
まぁ、ピアノは習っているものの、本人いわくピアノとピアニカは違うとのこと。
自分が小学校の時はピアニカではなく、縦笛だったのでなんだか新鮮です。
いろんな歌を歌ったり、ピアニカで演奏したりしていました。
小学校1年生なのですが、ピアニカで演奏している姿を見ていると、ここまで弾けるようになったんだなぁって感心です。
まぁ、ピアノは習っているものの、本人いわくピアノとピアニカは違うとのこと。
自分が小学校の時はピアニカではなく、縦笛だったのでなんだか新鮮です。
スーパーマリオラン [ゲーム]
ダウンロードして3面まで軽くクリアしました。
色の違うコインを苦労して全部集めると、また、違う色のコインが出てきて、同じ面を何度も楽しめる設定になっていました。
息子も楽しそうにやっていたので、1200円出して、全面購入。
ただ、登録を息子の年齢で登録したので、課金する際に、エラーが出てしまいました。
なんだかよくわからず、何度か繰り返していると、無事に課金が成功。
もう少し簡単にできると良いのですが。。。
大人の年齢で登録しても良いかなって思ったのですが、このクリスマスでニンテンドー3DS買ったり、なんだかんだと本人のIDを使う可能性があったので、子供の実年齢で登録してしまいました。。。(^^;
色の違うコインを苦労して全部集めると、また、違う色のコインが出てきて、同じ面を何度も楽しめる設定になっていました。
息子も楽しそうにやっていたので、1200円出して、全面購入。
ただ、登録を息子の年齢で登録したので、課金する際に、エラーが出てしまいました。
なんだかよくわからず、何度か繰り返していると、無事に課金が成功。
もう少し簡単にできると良いのですが。。。
大人の年齢で登録しても良いかなって思ったのですが、このクリスマスでニンテンドー3DS買ったり、なんだかんだと本人のIDを使う可能性があったので、子供の実年齢で登録してしまいました。。。(^^;
欠損値を含むレコードの処理 その1 欠測データの生成方法 [データサイエンス、統計モデル]
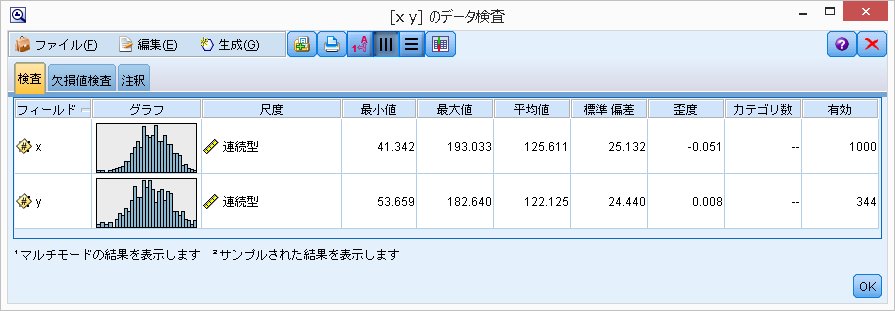
レコードの中に欠損値があることは、よくあります。
IBM SPSS Modelerでも欠損値がある場合、それを補正するノードは用意されているのですが、今回、欠測データ解析の講義を受けて、なるほど!と思ったことがあったので、まとめたいと思います。
基本、SPSS Modelerでシミュレーションしていきます。
欠測データ解析と言えば、Rubin(1976)があまりにも有名です。
欠損値を3つのタイプに分けることができます。
今、(X, Y)の2変量データ、Yに欠測があるとします。
・MCAR(Missing Completely At Random)
YにもXにも依存しない。
・MAR(Missing At Random)
Yには依存しないが、Xに依存する。
・MNAR(Missing Not At Random)
Yに依存する。
いろいろな方法がありますが、上手く行くのはMCARとMARの場合です。
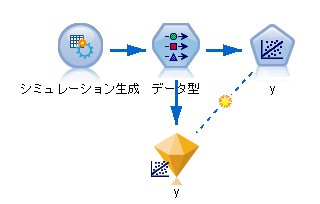
まずは、欠測データ解析用のデータを作ります。
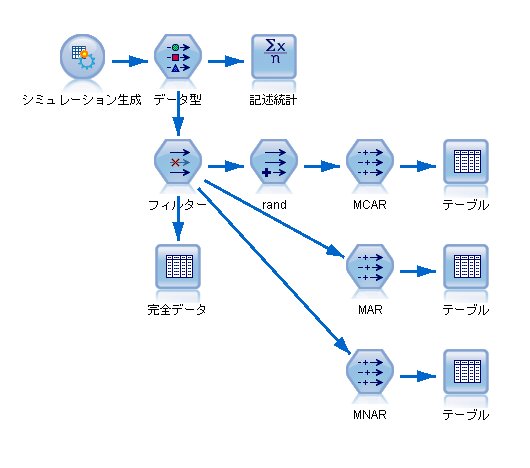
[入力]タブにあるシミュレーション生成ノードを使います。
2変数(x, y)はともに平均が125, 標準偏差が25, 相関は0.6とします。
項目の選択
シミュレーションしたフィールド
ここで平均が125, 標準偏差が25を設定
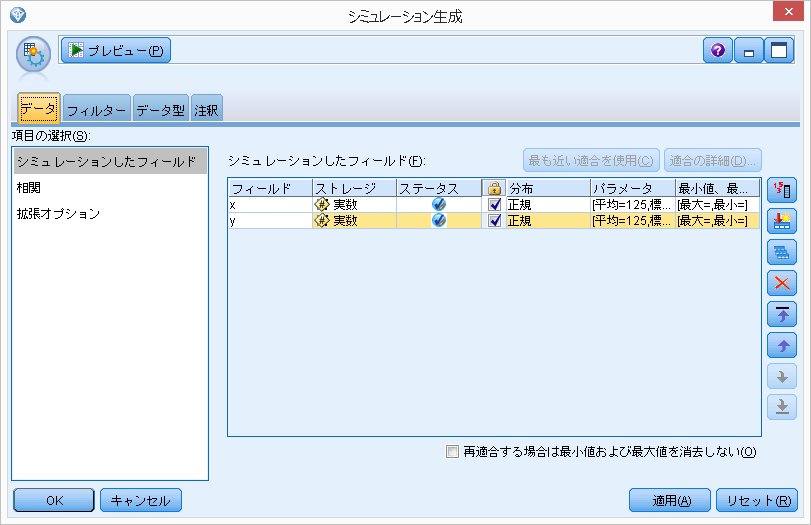
相関
ここで相関0.6を設定
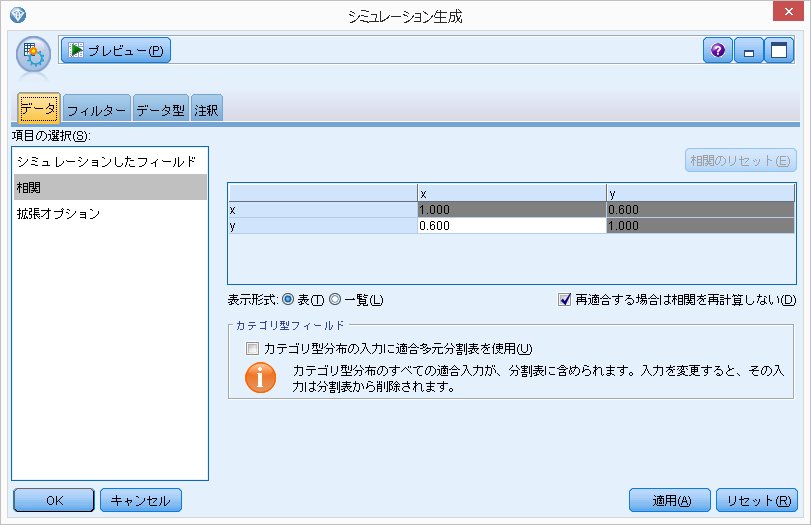
拡張オプション
発生させる乱数として1000個のデータを生成
ランダムシードを12345と設定
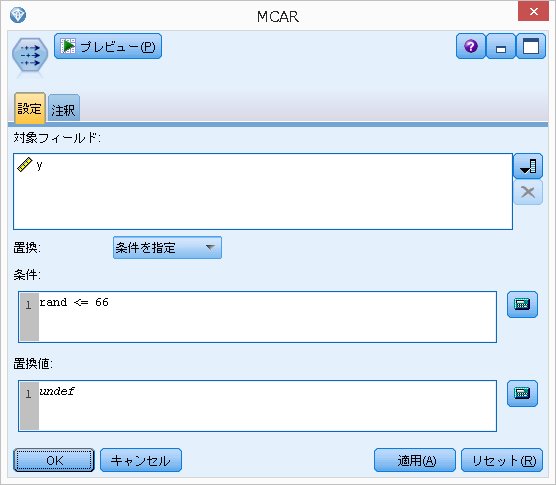
・MCAR(Missing Completely At Random)の作り方
randというフィールドを作成します。
random(100) と書くと、0 < x <= 100となります。
実際は、1から100までの100通りの乱数が生成されます。
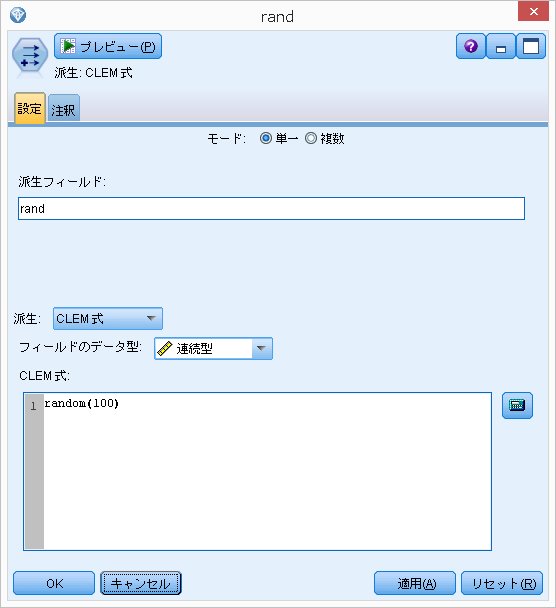
random0(100) と書くと、0 <= x <= 100となります。
実際は、0から100までの101通りの乱数が生成されます。
通常は、randomを使うことが多いかと思われます。
YにもXにも依存しない。
つまり、randの値が66以下の場合にデータを欠損させます。
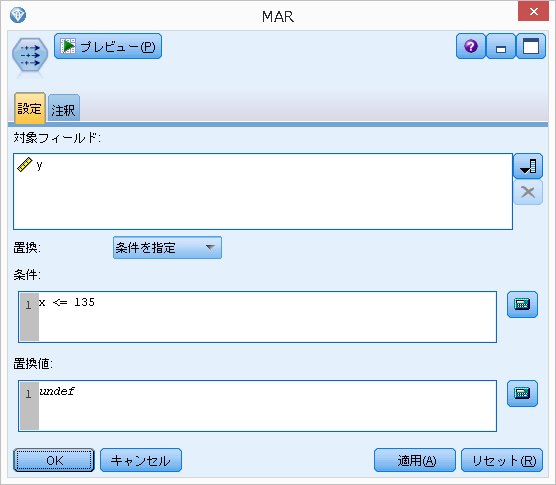
・MAR(Missing At Random)の作り方
Yには依存しないが、Xに依存する。
つまり、x <= 135 の場合に、yの値を欠損させます。
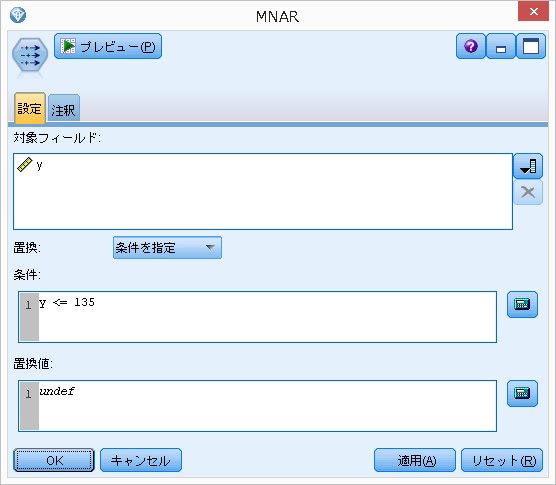
・MNAR(Missing Not At Random)
Yに依存する。
つまり、y <= 135 の場合に、yの値を欠損させます。
以下、欠測データを補完した場合にどうなるかをシミュレーションしていきます。
ちなみに、このデータは、相関は0.6で作っているので、y = a x + b という単回帰を考えた場合、回帰係数は0.6となるはずです。
完全データで線形回帰を行った場合、
y = 0.5962 * x + 50.83
となりました。
確かに、回帰係数は 0.6 となっています。
欠測データじゃないので、当然の結果と言えば当然の結果ですが。。。(^^;
欠測データがある場合、
・そのレコードを削除する
・平均値や最頻値などの固定値で置換する
・回帰などのアルゴリズムを使う
が考えられます。
SPSS Staticsでは、Missing Valuesを購入すれば、EMアルゴリズムで推定したり
多重代入を使って置換することができるようです。
SPSS Modelerに搭載されているアルゴリズムは、C&RT Treeが使えます。
IBM SPSS Modelerでも欠損値がある場合、それを補正するノードは用意されているのですが、今回、欠測データ解析の講義を受けて、なるほど!と思ったことがあったので、まとめたいと思います。
基本、SPSS Modelerでシミュレーションしていきます。
欠測データ解析と言えば、Rubin(1976)があまりにも有名です。
欠損値を3つのタイプに分けることができます。
今、(X, Y)の2変量データ、Yに欠測があるとします。
・MCAR(Missing Completely At Random)
YにもXにも依存しない。
・MAR(Missing At Random)
Yには依存しないが、Xに依存する。
・MNAR(Missing Not At Random)
Yに依存する。
いろいろな方法がありますが、上手く行くのはMCARとMARの場合です。
まずは、欠測データ解析用のデータを作ります。
[入力]タブにあるシミュレーション生成ノードを使います。
2変数(x, y)はともに平均が125, 標準偏差が25, 相関は0.6とします。
項目の選択
シミュレーションしたフィールド
ここで平均が125, 標準偏差が25を設定
相関
ここで相関0.6を設定
拡張オプション
発生させる乱数として1000個のデータを生成
ランダムシードを12345と設定
・MCAR(Missing Completely At Random)の作り方
randというフィールドを作成します。
random(100) と書くと、0 < x <= 100となります。
実際は、1から100までの100通りの乱数が生成されます。
random0(100) と書くと、0 <= x <= 100となります。
実際は、0から100までの101通りの乱数が生成されます。
通常は、randomを使うことが多いかと思われます。
YにもXにも依存しない。
つまり、randの値が66以下の場合にデータを欠損させます。
・MAR(Missing At Random)の作り方
Yには依存しないが、Xに依存する。
つまり、x <= 135 の場合に、yの値を欠損させます。
・MNAR(Missing Not At Random)
Yに依存する。
つまり、y <= 135 の場合に、yの値を欠損させます。
以下、欠測データを補完した場合にどうなるかをシミュレーションしていきます。
ちなみに、このデータは、相関は0.6で作っているので、y = a x + b という単回帰を考えた場合、回帰係数は0.6となるはずです。
完全データで線形回帰を行った場合、
y = 0.5962 * x + 50.83
となりました。
確かに、回帰係数は 0.6 となっています。
欠測データじゃないので、当然の結果と言えば当然の結果ですが。。。(^^;
欠測データがある場合、
・そのレコードを削除する
・平均値や最頻値などの固定値で置換する
・回帰などのアルゴリズムを使う
が考えられます。
SPSS Staticsでは、Missing Valuesを購入すれば、EMアルゴリズムで推定したり
多重代入を使って置換することができるようです。
SPSS Modelerに搭載されているアルゴリズムは、C&RT Treeが使えます。
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理 [データサイエンス、統計モデル]
IBM SPSS Modelerには欠損値検査が付いています。
(手法としては、全部、微妙なのであまり使わない方が良さそうです。)
[データ検査]ノードというものがあります。
実行すると、このようなアウトプットが出てきます。
欠損値検査タブをクリックすると、どのようなアルゴリズムで欠損値を補完するかを選択することができます。
用意されているのは、下記の4種類。
1. 固定値
2. 無作為
3. 式(回帰式)
4. アルゴリズム(CRT)
1.~3.は、また、別の機会に調べるとして、まずは、4.のアルゴリズムから。
元々、データマイニングツールということもあり、補完するアルゴリズムは決定木のCRT(CA&RT)になっています。
なんで、CARTかといえば、classification and regression treesの名前の通り、
分類と回帰の両方を扱えます。
つまり、名義変数の補完の場合はclassification、連続値の補完としてregressionを使うことができるかです。
一見、上手く行きそうですが、細かく見ていくとおかしなことが起こっています。
今回、xとyは、相関0.600の関係になるようにサンプリングしています。
欠測を与える前のxとy値は0.592となっています。
欠測データを補完した際にxとyの相関も0.600(0.592)付近になることが期待されるのですが、0.315という結果になっていました。
出来上がったモデルを見ると、下図のようになっています。
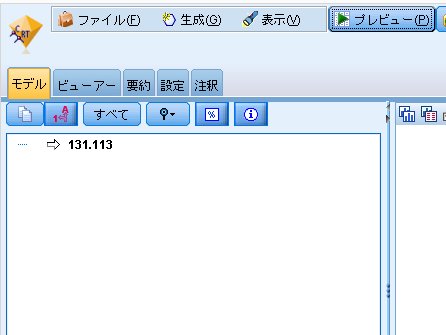
つまり、欠損データ部分にすべて同じ値を埋めましょう、ということを意味しています。
次に、散布図を書いてみると、このようになります。
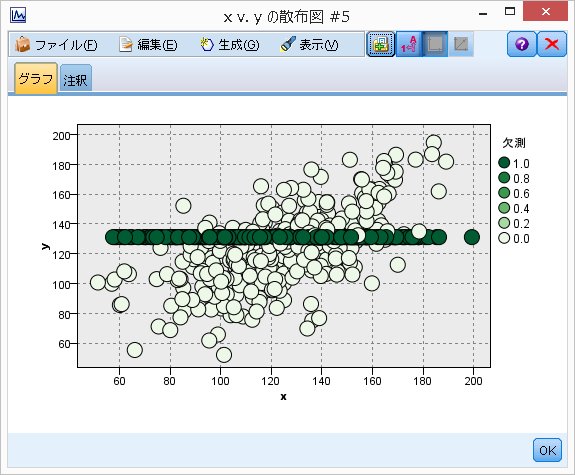
緑色の部分が欠損値のデータを補完した部分になります。
このようにすべて同じ値で埋めてしまうため、xとyの相関が0.315と低い値になってしまいました。
次にランダムシードを変更して実行すると、今度は、木が分岐し、散布図は下図のようになっています。
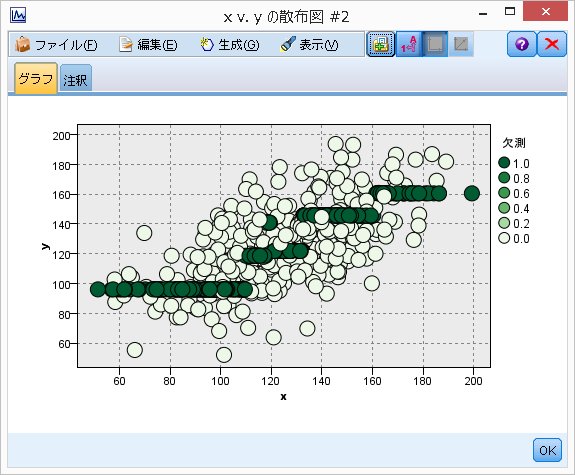
先ほど違ってすべて同じ値ではないのですが、やはり多くの個所を一つの値で置換していることがわかります。
また、別の問題として、C&RTを使って分岐するということは、
ちょっとした決定木の分岐の違いによって補完される値が変わってしまいます。
その結果、相関係数の値が実行するたびに大きく変化することも問題です。
ということで、一見、もっともらしいアルゴリズム(CRT)で置換しているように見えますが、細かく見ていくと、変なことが起こっているので、この置換方法はやめた方が良いように思えます。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
(手法としては、全部、微妙なのであまり使わない方が良さそうです。)
[データ検査]ノードというものがあります。
実行すると、このようなアウトプットが出てきます。
欠損値検査タブをクリックすると、どのようなアルゴリズムで欠損値を補完するかを選択することができます。
用意されているのは、下記の4種類。
1. 固定値
2. 無作為
3. 式(回帰式)
4. アルゴリズム(CRT)
1.~3.は、また、別の機会に調べるとして、まずは、4.のアルゴリズムから。
元々、データマイニングツールということもあり、補完するアルゴリズムは決定木のCRT(CA&RT)になっています。
なんで、CARTかといえば、classification and regression treesの名前の通り、
分類と回帰の両方を扱えます。
つまり、名義変数の補完の場合はclassification、連続値の補完としてregressionを使うことができるかです。
一見、上手く行きそうですが、細かく見ていくとおかしなことが起こっています。
今回、xとyは、相関0.600の関係になるようにサンプリングしています。
欠測を与える前のxとy値は0.592となっています。
欠測データを補完した際にxとyの相関も0.600(0.592)付近になることが期待されるのですが、0.315という結果になっていました。
出来上がったモデルを見ると、下図のようになっています。
つまり、欠損データ部分にすべて同じ値を埋めましょう、ということを意味しています。
次に、散布図を書いてみると、このようになります。
緑色の部分が欠損値のデータを補完した部分になります。
このようにすべて同じ値で埋めてしまうため、xとyの相関が0.315と低い値になってしまいました。
次にランダムシードを変更して実行すると、今度は、木が分岐し、散布図は下図のようになっています。
先ほど違ってすべて同じ値ではないのですが、やはり多くの個所を一つの値で置換していることがわかります。
また、別の問題として、C&RTを使って分岐するということは、
ちょっとした決定木の分岐の違いによって補完される値が変わってしまいます。
その結果、相関係数の値が実行するたびに大きく変化することも問題です。
ということで、一見、もっともらしいアルゴリズム(CRT)で置換しているように見えますが、細かく見ていくと、変なことが起こっているので、この置換方法はやめた方が良いように思えます。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その3 リストワイズ削除 [データサイエンス、統計モデル]
リストワイズ削除とは、一つでも欠損があったら全部のレコードを削除するという方法になります。
なんだかもったいない気もします。。。
リストワイズ削除をすると、どのような影響になるのか、SPSS Modelerで検証します。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:126 ○
yの標準偏差:25.2 ○
xとyの相関:0.557 ○
[MAR]
yの平均:141 ×(高すぎる)
yの標準偏差:22.8 ×(低い)
xとyの相関:0.380 ×(低い)
[MNAR]
yの平均:152 ×(高すぎる)
yの標準偏差:14.2 ×(低すぎる)
xとyの相関:0.401 ×(低い)
xとyが完全ランダムの場合のみyの平均もyの標準偏差も同じになっていますが、
MARやMNARの場合は上手く復元できません。
特にxとyの相関係数は、切断効果により小さくなってしまいます。
リストワイズは手っ取り早いのですが、単純にデータを削除すると、平均や標準偏差など得られた結果がおかしい場合があるので注意が必要ですね。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
なんだかもったいない気もします。。。
リストワイズ削除をすると、どのような影響になるのか、SPSS Modelerで検証します。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:126 ○
yの標準偏差:25.2 ○
xとyの相関:0.557 ○
[MAR]
yの平均:141 ×(高すぎる)
yの標準偏差:22.8 ×(低い)
xとyの相関:0.380 ×(低い)
[MNAR]
yの平均:152 ×(高すぎる)
yの標準偏差:14.2 ×(低すぎる)
xとyの相関:0.401 ×(低い)
xとyが完全ランダムの場合のみyの平均もyの標準偏差も同じになっていますが、
MARやMNARの場合は上手く復元できません。
特にxとyの相関係数は、切断効果により小さくなってしまいます。
リストワイズは手っ取り早いのですが、単純にデータを削除すると、平均や標準偏差など得られた結果がおかしい場合があるので注意が必要ですね。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その4 平均値代入 [データサイエンス、統計モデル]
リストワイズ削除は、データを削除するのでもったいない感じがします。
そこで、平均値で代入してみてはどうか?という発想です。
まずは、結果から。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:127 ○
yの標準偏差:14.5 ×(低い)
xとyの相関:0.322 ×(低い)
[MAR]
yの平均:141 ×(高い)
yの標準偏差:13.2 ×(低い)
xとyの相関:0.111 ×(低い)
[MNAR]
yの平均:152 ×(高い)
yの標準偏差:7.99 ×(低い)
xとyの相関:0.194 ×(低い)
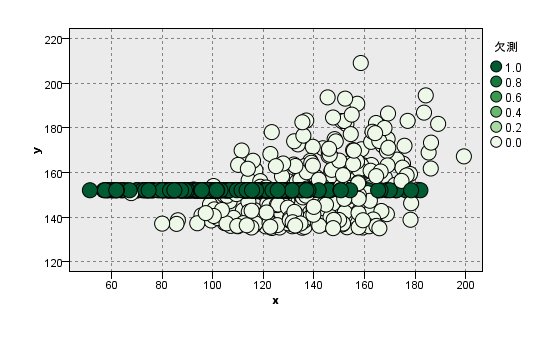
なぜ、このような事が起こっているのか散布図を書いてみます。
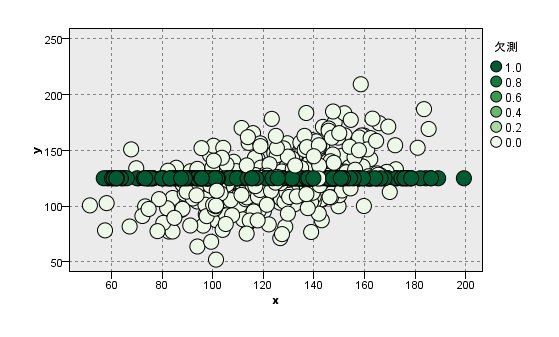
[MCAR]の場合
平均値は真値に近いです。
これは、xとyが完全にランダムであるから。
しかし、yの値を一定の値にしてしまっているために
yの標準偏差が低くなったり、xとyの相関も低くなったりします。
CRT Treeを使った欠測処理で、CRTが分岐せずに全部同じ値になっていることと同様の結果ですね。
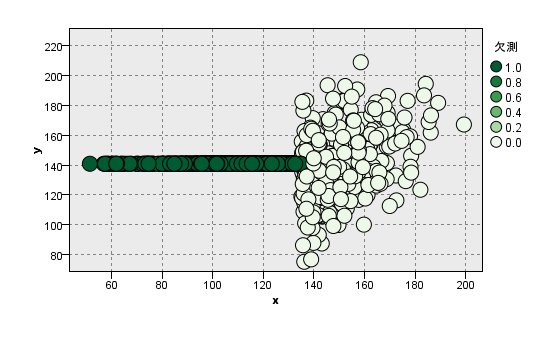
[MAR]の場合(x <= 135を欠損させる)
yの平均が高くなる理由ですが、xとyが相関があります。
欠測している個所は、欠損していない箇所よりも平均値が低くなっているはずです。
しかし、欠損していない個所の平均値で欠損箇所を埋めてしまっているために平均値が低くなってしまいます。
[MNAR]の場合(y <= 135を欠損させる)
MARよりもさらに平均値が高いです。
今回は、低いyの値を欠損させているにもかかわらず、高いyの値で補完していることが原因です。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その3 リストワイズ削除
http://skellington.blog.so-net.ne.jp/2016-12-21
そこで、平均値で代入してみてはどうか?という発想です。
まずは、結果から。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:127 ○
yの標準偏差:14.5 ×(低い)
xとyの相関:0.322 ×(低い)
[MAR]
yの平均:141 ×(高い)
yの標準偏差:13.2 ×(低い)
xとyの相関:0.111 ×(低い)
[MNAR]
yの平均:152 ×(高い)
yの標準偏差:7.99 ×(低い)
xとyの相関:0.194 ×(低い)
なぜ、このような事が起こっているのか散布図を書いてみます。
[MCAR]の場合
平均値は真値に近いです。
これは、xとyが完全にランダムであるから。
しかし、yの値を一定の値にしてしまっているために
yの標準偏差が低くなったり、xとyの相関も低くなったりします。
CRT Treeを使った欠測処理で、CRTが分岐せずに全部同じ値になっていることと同様の結果ですね。
[MAR]の場合(x <= 135を欠損させる)
yの平均が高くなる理由ですが、xとyが相関があります。
欠測している個所は、欠損していない箇所よりも平均値が低くなっているはずです。
しかし、欠損していない個所の平均値で欠損箇所を埋めてしまっているために平均値が低くなってしまいます。
[MNAR]の場合(y <= 135を欠損させる)
MARよりもさらに平均値が高いです。
今回は、低いyの値を欠損させているにもかかわらず、高いyの値で補完していることが原因です。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その3 リストワイズ削除
http://skellington.blog.so-net.ne.jp/2016-12-21
欠損値を含むレコードの処理 その5 回帰代入 [データサイエンス、統計モデル]
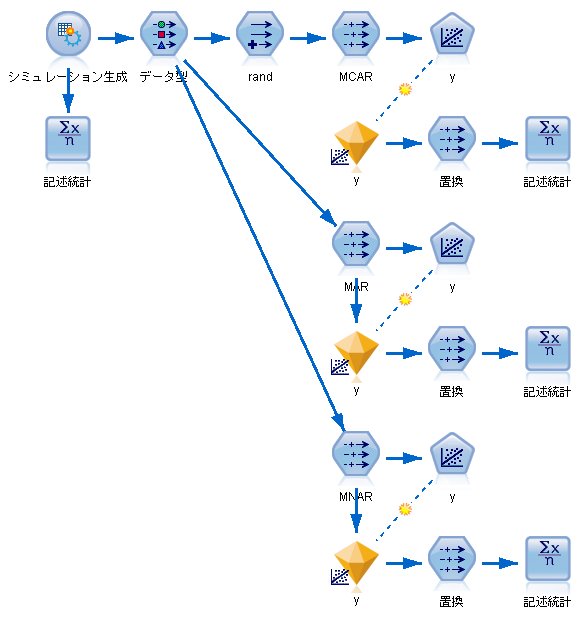
その2 C&RT Treeを使った欠測処理 で行った決定木を使う補完方法の場合、同じ枝の値は全部同じ値になってしまうため、上手く補完ができませんでした。
だったら、決定木ではなく回帰分析を行ってその値で補正しましょうというのは自然な流れです。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:124 ○
yの標準偏差:19.2 ×(小さい)
xとyの相関:0.793 ×(高い)
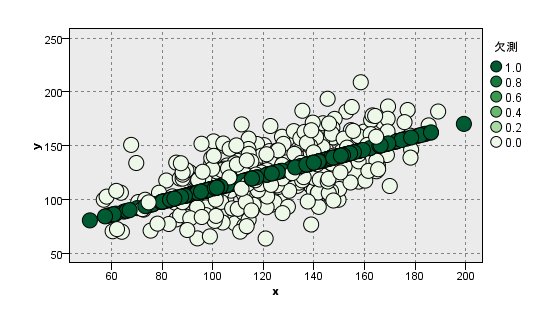
[MAR]
yの平均:122 ○
yの標準偏差:21.1 ×(小さい)
xとyの相関:0.816 ×(高い)
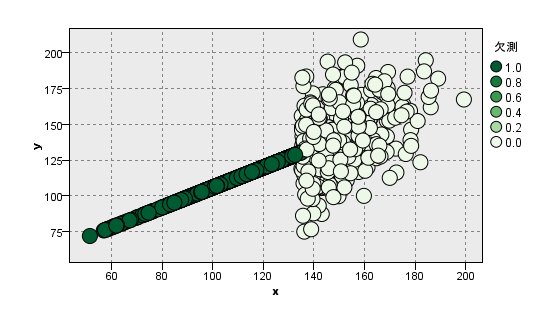
[MNAR]
yの平均:148 ×(高すぎる)
yの標準偏差:9.86 ×(小すぎる)
xとyの相関:0.671 ×(高い)
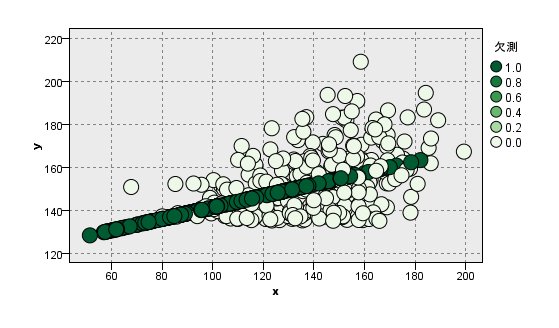
平均値に関して言えば、MCARとMARは大丈夫そうです。
yの標準偏差やxとyの相関に関しては上手く行っていません。
これは、CRT代入や平均値代入と同じく、一つの値で補正をしてしまっているため、母数にバイアスがないのが原因です。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その3 リストワイズ削除
http://skellington.blog.so-net.ne.jp/2016-12-21
欠損値を含むレコードの処理 その4 平均値代入
http://skellington.blog.so-net.ne.jp/2016-12-22
だったら、決定木ではなく回帰分析を行ってその値で補正しましょうというのは自然な流れです。
[真値]
yの平均:124
yの標準偏差:25.0
xとyの相関:0.592
[MCAR]
yの平均:124 ○
yの標準偏差:19.2 ×(小さい)
xとyの相関:0.793 ×(高い)
[MAR]
yの平均:122 ○
yの標準偏差:21.1 ×(小さい)
xとyの相関:0.816 ×(高い)
[MNAR]
yの平均:148 ×(高すぎる)
yの標準偏差:9.86 ×(小すぎる)
xとyの相関:0.671 ×(高い)
平均値に関して言えば、MCARとMARは大丈夫そうです。
yの標準偏差やxとyの相関に関しては上手く行っていません。
これは、CRT代入や平均値代入と同じく、一つの値で補正をしてしまっているため、母数にバイアスがないのが原因です。
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その3 リストワイズ削除
http://skellington.blog.so-net.ne.jp/2016-12-21
欠損値を含むレコードの処理 その4 平均値代入
http://skellington.blog.so-net.ne.jp/2016-12-22
欠損値を含むレコードの処理 その6 オススメの補完方法 [データサイエンス、統計モデル]
★ 過去の記事 ★
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その3 リストワイズ削除
http://skellington.blog.so-net.ne.jp/2016-12-21
欠損値を含むレコードの処理 その4 平均値代入
http://skellington.blog.so-net.ne.jp/2016-12-22
欠損値を含むレコードの処理 その5 回帰代入
http://skellington.blog.so-net.ne.jp/2016-12-23
↑
こちらの方法ではなんらかの不具合が生じてしまいました。
優れている手法としては、完全情報最尤推定(Full-Information Maximum Likelihood: FIML)や多重代入法(Multiple Imputation: MI)を使うのが良いようです。
多重代入法は、SPSS Modelerにはなく、SPSS Statisticsのオプションである Missing Values に入っているようです。
M.欠測データの統計科学:基礎理論と実践的な方法論
http://www.ism.ac.jp/lectures/28m.html
")
欠損値を含むレコードの処理 その1 欠測データの生成方法
http://skellington.blog.so-net.ne.jp/2016-12-19
欠損値を含むレコードの処理 その2 C&RT Treeを使った欠測処理
http://skellington.blog.so-net.ne.jp/2016-12-20
欠損値を含むレコードの処理 その3 リストワイズ削除
http://skellington.blog.so-net.ne.jp/2016-12-21
欠損値を含むレコードの処理 その4 平均値代入
http://skellington.blog.so-net.ne.jp/2016-12-22
欠損値を含むレコードの処理 その5 回帰代入
http://skellington.blog.so-net.ne.jp/2016-12-23
↑
こちらの方法ではなんらかの不具合が生じてしまいました。
優れている手法としては、完全情報最尤推定(Full-Information Maximum Likelihood: FIML)や多重代入法(Multiple Imputation: MI)を使うのが良いようです。
多重代入法は、SPSS Modelerにはなく、SPSS Statisticsのオプションである Missing Values に入っているようです。
M.欠測データの統計科学:基礎理論と実践的な方法論
http://www.ism.ac.jp/lectures/28m.html
欠測データの統計科学――医学と社会科学への応用 (調査観察データ解析の実際 第1巻)
- 作者:
- 出版社/メーカー: 岩波書店
- 発売日: 2016/04/20
- メディア: 単行本(ソフトカバー)
北海道スキー 2016 初日 大雪の北海道 [【旅行】北海道]
今年の北海道スキーは、サホロに行くことにしました。
往復千歳経由で行こうとしたのですが、朝の良い便が取れなくて、
行きは帯広空港着、帰りは千歳空港発にしました。
ただ、この日は前日から降り積もった雪のために千歳発着便が全て運休。
朝から大混乱でした。
結果的には自分たちは帯広空港経由だったので、問題なかったのですが、
千歳経由にしていたらキャンセルということでした。。。
帰りは千歳経由なので、それはまた別の事件がありましたが・・・。

そして、無事に帯広空港に着きました。
バスが出発するまでに時間があったので、十勝豚丼を食べたのですが、これが美味しかったです!

↑
これは十勝サホロリゾートにある花森熊カフェの豚丼です。
往復千歳経由で行こうとしたのですが、朝の良い便が取れなくて、
行きは帯広空港着、帰りは千歳空港発にしました。
ただ、この日は前日から降り積もった雪のために千歳発着便が全て運休。
朝から大混乱でした。
結果的には自分たちは帯広空港経由だったので、問題なかったのですが、
千歳経由にしていたらキャンセルということでした。。。
帰りは千歳経由なので、それはまた別の事件がありましたが・・・。
そして、無事に帯広空港に着きました。
バスが出発するまでに時間があったので、十勝豚丼を食べたのですが、これが美味しかったです!
↑
これは十勝サホロリゾートにある花森熊カフェの豚丼です。
北海道スキー 2016 二日目 初心者に優しいゲレンデ [【旅行】北海道]
今回は、4泊5日のツアーです。
初日と最終日は移動があるので半日だけ滑れます。
中3日がフルに遊べる日。
初日は、自分たちで子供たちを教えることにしました。
今回、サホロ来て、息子のスキーがかなり上達しました。
振り返って考えてみると、
1. スノーエスカレーターがあるので、リフトに乗れなくても傾斜面で練習ができます。
(距離は短い)
2. 雪に慣れてくると次は初心者用のコースが滑るのですが、かなりの距離を傾斜面で滑れます。
とりあえず、長い距離をある程度のスピードで滑りまくる!
すると、体が自然に滑り方を覚えるみたいで、気が付いたらボーゲンとかも普通にできるようになっていました。



初日と最終日は移動があるので半日だけ滑れます。
中3日がフルに遊べる日。
初日は、自分たちで子供たちを教えることにしました。
今回、サホロ来て、息子のスキーがかなり上達しました。
振り返って考えてみると、
1. スノーエスカレーターがあるので、リフトに乗れなくても傾斜面で練習ができます。
(距離は短い)
2. 雪に慣れてくると次は初心者用のコースが滑るのですが、かなりの距離を傾斜面で滑れます。
とりあえず、長い距離をある程度のスピードで滑りまくる!
すると、体が自然に滑り方を覚えるみたいで、気が付いたらボーゲンとかも普通にできるようになっていました。
北海道スキー 2016 三日目 [【旅行】北海道]
3日目は子供たちをスクールに預けて特訓の日。
娘は4歳なので、半日コース。
息子は小学生になったので、1日コース。w
半日も1日もそれほど値段が変わらないので、1日コースの方がお得です。
半日コースから1日コースに変更するのは差額料金だけで良いみたいです。


思いっきり体を動かした後は、ラーメンでお腹いっぱい。
一人前のラーメンを食べていました!



娘は4歳なので、半日コース。
息子は小学生になったので、1日コース。w
半日も1日もそれほど値段が変わらないので、1日コースの方がお得です。
半日コースから1日コースに変更するのは差額料金だけで良いみたいです。
思いっきり体を動かした後は、ラーメンでお腹いっぱい。
一人前のラーメンを食べていました!
北海道スキー 2016 四日目 [【旅行】北海道]
四日目は、スクールに入れる予定はなかったのですが、
息子がスキーのコツをつかみかけていたので、急きょ申し込むことに。
本人も嫌ではなかったみたいです。
去年までは、かなりの傾斜面でも滑るのが怪しかった息子ですが、
今回のスキーを通して、中級に近い初心者コースまで滑れるようになりました。
スキーの自身も付いたみたいで、転んだ子供たちを助けてあげたりもしたそうです。
ちょっとしたリーダー的な感じでしょうか。
サホロは、トマムやニセコに比べると小規模ですが、初心者的には良いコース作りになっていると思いました。



息子がスキーのコツをつかみかけていたので、急きょ申し込むことに。
本人も嫌ではなかったみたいです。
去年までは、かなりの傾斜面でも滑るのが怪しかった息子ですが、
今回のスキーを通して、中級に近い初心者コースまで滑れるようになりました。
スキーの自身も付いたみたいで、転んだ子供たちを助けてあげたりもしたそうです。
ちょっとしたリーダー的な感じでしょうか。
サホロは、トマムやニセコに比べると小規模ですが、初心者的には良いコース作りになっていると思いました。
北海道スキー 2016 五日目(最終日) [【旅行】北海道]
午後出発のバスだったので、午前中に滑って温泉入って、ランチしてという時間がありました。
ギリギリまで遊んでいました。w
さて、帰りなので、帯広空港ではなく、千歳経由でした。
連日の雪の影響で、二本ある滑走路が一本しか復旧していなくて出発までに2時間くらい遅延してしまいました。
時間はたっぷりあるので、北海道ならではの生ニシンを食べたり、チョコで有名なロイズのパンを食べたり。


パンが板チョコに挟まっていますw
そして、羽田空港に着いた時も、前に飛んでいた飛行機が部品を滑走路に落としたらしく、上空で待機。
なんだかんだと3時間くらい遅延して、羽田に着いたのが深夜2時近かったです。
公共機関は終電過ぎているので、タクシー(上限1万5千円)使っても良いですよってチケット配られていました。
自分たちは車を空港に駐車していたので、自分の車で帰ってきましたが、タクシーの列も大混雑していました。
一番最後にトラブルが多発しましたが、、、全体的に充実した旅行でした。
こうした経験も良い思い出の一つですかね。w
ギリギリまで遊んでいました。w
さて、帰りなので、帯広空港ではなく、千歳経由でした。
連日の雪の影響で、二本ある滑走路が一本しか復旧していなくて出発までに2時間くらい遅延してしまいました。
時間はたっぷりあるので、北海道ならではの生ニシンを食べたり、チョコで有名なロイズのパンを食べたり。
パンが板チョコに挟まっていますw
そして、羽田空港に着いた時も、前に飛んでいた飛行機が部品を滑走路に落としたらしく、上空で待機。
なんだかんだと3時間くらい遅延して、羽田に着いたのが深夜2時近かったです。
公共機関は終電過ぎているので、タクシー(上限1万5千円)使っても良いですよってチケット配られていました。
自分たちは車を空港に駐車していたので、自分の車で帰ってきましたが、タクシーの列も大混雑していました。
一番最後にトラブルが多発しましたが、、、全体的に充実した旅行でした。
こうした経験も良い思い出の一つですかね。w
サンタピカチュウをゲット [ゲーム]
千歳空港でサンタピカチュウをゲット

手乗りピカチュウにしようかと思ったら、ちょっとズレていました・・・(^^;
手乗りピカチュウにしようかと思ったら、ちょっとズレていました・・・(^^;
年末 2016 [自己紹介 / 挨拶]
英会話の教材でこんなのがありました。
Most people in Japan spend time with their family on NewYear's Day and don't go out on New Year's Eve.
なるほど、自分に当てはまっているなって思いました。
4月から大学院に通い始め、1日の中で社会人と学生をするという生活で、かなり大変だったけど、その分、思いっきり勉強したし、充実した1年だったと思います。
来年もまた頑張ります!
Most people in Japan spend time with their family on NewYear's Day and don't go out on New Year's Eve.
なるほど、自分に当てはまっているなって思いました。
4月から大学院に通い始め、1日の中で社会人と学生をするという生活で、かなり大変だったけど、その分、思いっきり勉強したし、充実した1年だったと思います。
来年もまた頑張ります!

