IBM SPSS Modeler: ループ/条件付き実行のスクリプト 後半 [データサイエンス、統計モデル]
※ IBM insight 2015 の "Automation in IBM SPSS Modeler Using Python and R" を元にしています。
【目的】
様々な変数でクロス集計を行いたいが、いちいちクロス集計ノードを追加するのは面倒だし、見栄えが悪くなる。
そこで、スクリプトでループ処理ができないか?
【設定方法】
3. 集計するフィールドに応じて出力名の変更
最後に、少し工夫をしておきます。
このまま実行すると、出力が全て[クロス集計]になってしまいます。
クロス集計表を見れば、何と何をクロス集計したのか分かりますが、ちょっと見にくいです。
そこで、集計する変数に応じて、この出力名も変更するようにします。
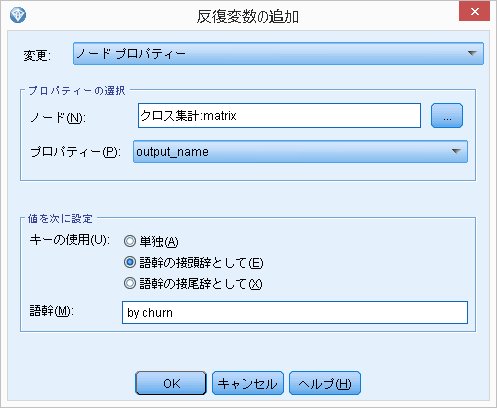
[変数の追加]をクリックし、
変更:ストリームパラメーター -> [ノード プロパティー] に変更。
↓
ノード(N)でクロス集計:matrixを選択。
↓
プロパティーで[output_name]を選択。
↓
キーの使用で、真ん中の [語幹の接頭辞として]を選択。
↓
語幹(M) に [ by churn] を入力。
( "by churn" の前にスペース入れておくと読みやすい)
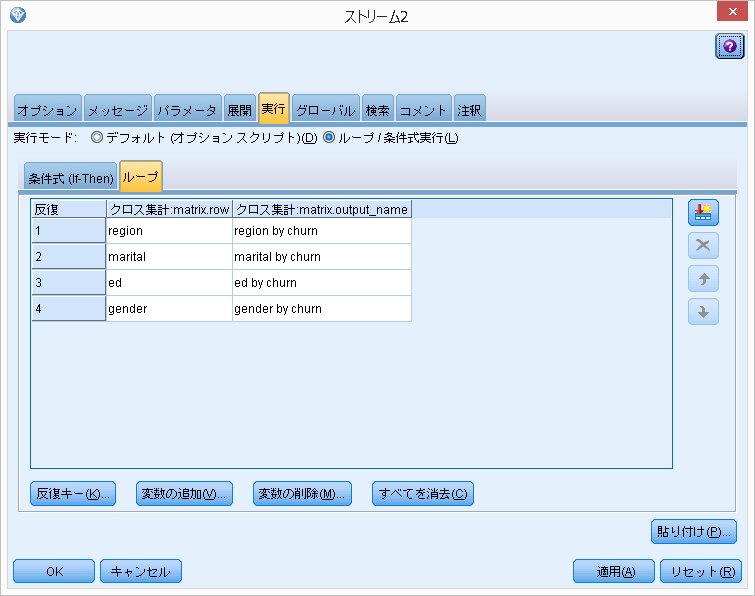
クロス集計ノードの左上にループ処理マークが追加されています。
この状態で、ストリーム全体を実行すれば、ループ処理されます。
[このノードを実行]だと、ループ処理されないので注意が必要です。
すると、4フィールドに対してのクロス集計表がループ処理されて出てきます。
4. スクリプトでの表記を確認
[貼り付け]をクリックすると、スクリプトが貼り付けられます。
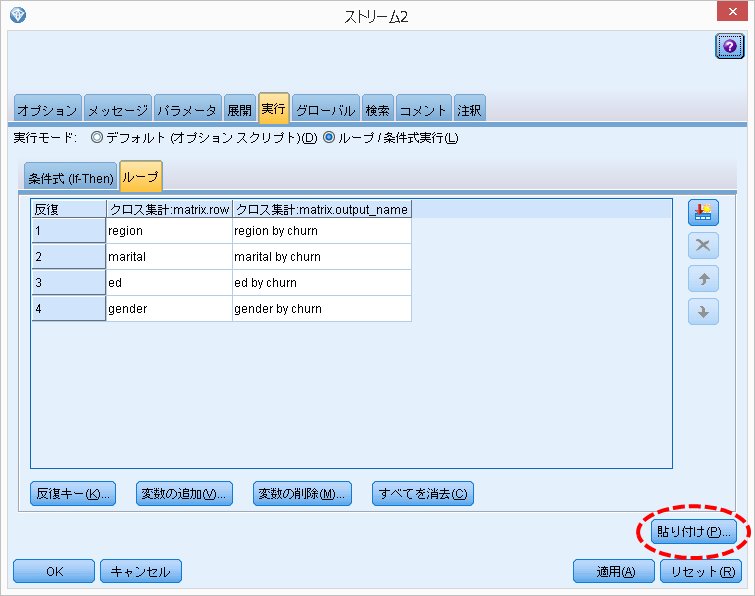
となります。
【目的】
様々な変数でクロス集計を行いたいが、いちいちクロス集計ノードを追加するのは面倒だし、見栄えが悪くなる。
そこで、スクリプトでループ処理ができないか?
【設定方法】
3. 集計するフィールドに応じて出力名の変更
最後に、少し工夫をしておきます。
このまま実行すると、出力が全て[クロス集計]になってしまいます。
クロス集計表を見れば、何と何をクロス集計したのか分かりますが、ちょっと見にくいです。
そこで、集計する変数に応じて、この出力名も変更するようにします。
[変数の追加]をクリックし、
変更:ストリームパラメーター -> [ノード プロパティー] に変更。
↓
ノード(N)でクロス集計:matrixを選択。
↓
プロパティーで[output_name]を選択。
↓
キーの使用で、真ん中の [語幹の接頭辞として]を選択。
↓
語幹(M) に [ by churn] を入力。
( "by churn" の前にスペース入れておくと読みやすい)
クロス集計ノードの左上にループ処理マークが追加されています。
この状態で、ストリーム全体を実行すれば、ループ処理されます。
[このノードを実行]だと、ループ処理されないので注意が必要です。
すると、4フィールドに対してのクロス集計表がループ処理されて出てきます。
4. スクリプトでの表記を確認
[貼り付け]をクリックすると、スクリプトが貼り付けられます。
stream = modeler.script.stream()
iterationKey_NodeID = "id26GSS7V876Z" # "クロス集計":matrix
iterationKey_NodeProperty = "row"
iterationKey_NodeFields = [u'region',u'marital',u'ed',u'gender']
iterationVariable1_NodeID = "id26GSS7V876Z" # "クロス集計":matrix
iterationVariable1_NodeProperty = "output_name"
for i in range(len(iterationKey_NodeFields)):
# 反復キーの初期化
field = iterationKey_NodeFields[i]
node = stream.findByID(iterationKey_NodeID)
node.setPropertyValue(iterationKey_NodeProperty,field)
# 反復変数の初期化 1
node = stream.findByID(iterationVariable1_NodeID)
iterationVariable1_stem = str(iterationKey_NodeFields[i]) + u" by churn"
node.setPropertyValue(iterationVariable1_NodeProperty,iterationVariable1_stem)
# この反復のストリームを今すぐ実行
executionResults = []
stream.runAll(executionResults)
print "実行を完了しました。"
となります。

