【Hadoop MapReduce】MapReduceの処理効率を向上させる"combiners" [Hadoop / Spark]
combiners: MapReduceの処理効率を向上させるためにコンバイナを使用する
複数のMapperがデータを取得し、単一のReducerで処理をするのだが、大量のレコードをMapperがReducerに渡してしまうと、処理速度が遅くなってしまいます。
そこで、MapperとReducerの間にたちデータを処理するのがcombiners。
Hadoopnoのログを見ると、URLが書かれていて、そこにアクセスると、MapperやReducerがどれくらいのレコードを受け取って、どれくらいのレコードをアウトプットしたのかなどの情報が見れます。
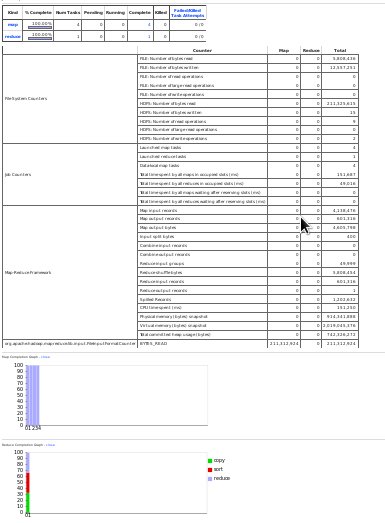
複数のMapperがデータを取得し、単一のReducerで処理をするのだが、大量のレコードをMapperがReducerに渡してしまうと、処理速度が遅くなってしまいます。
そこで、MapperとReducerの間にたちデータを処理するのがcombiners。
Hadoopnoのログを見ると、URLが書かれていて、そこにアクセスると、MapperやReducerがどれくらいのレコードを受け取って、どれくらいのレコードをアウトプットしたのかなどの情報が見れます。

