IBM SPSS Modelerで一般化線形モデル(GLM):オフセットフィールドの使い方 [データサイエンス、統計モデル]
R と IBM SPSS Modeler(Clementine)との比較です。
単位時間あたりのアクション数や、単位面積あたりの店舗数などを扱う場合にオフセットフィールドが登場します。
こじつけの例として、ある期間Aにおけるアクション数 y があり、変数として x が与えられたとします。
その際、単位時間あたりのアクション数 y と x との関係をもモデリングするというものです。
単位時間あたりのアクション数 = アクション数(λ) / A
λ = A × 単位時間あたりのアクション数
= A exp(β1 + β2 x)
= exp(β1 + β2 x + log(A) )
となります。
logを取ると、
log(λ) = β1 + β2 x + log(A)
と線形で書けるようになります。
つまり、β1 + β2 x + log(A) を線形予測子とするポアソン分布として扱うことができます。
log(λ)ということなので、リンク関数は、対数になります。
log(A)は、パラメータがつかないので、オフセット項となります。
Rで書く場合は、
fit.all <- glm(y ~ x, offset = log(A), family = poisson, data = d)
と書きます。
Modelerの場合の設定は、
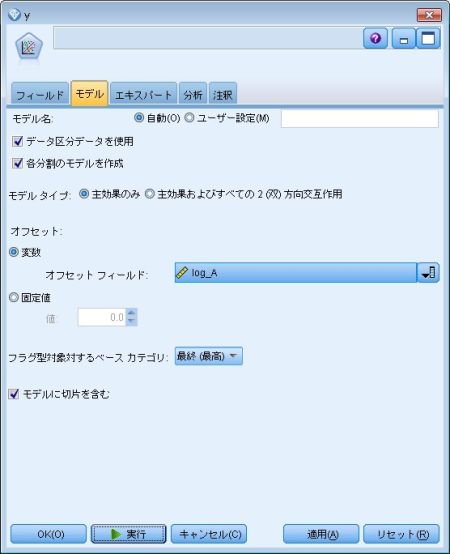
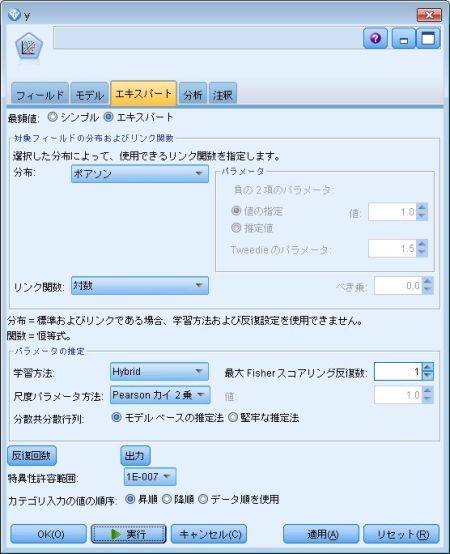
と設定します。
実際は、Aというフィールドに面積やら時間が入っているかと思うのですが、Rでは、log(A)と書くのに対し、IBM SPSS Modeler(Clementine)では、いったん log(A) というフィールドを作成してあげる必要があります。
単位時間あたりのアクション数や、単位面積あたりの店舗数などを扱う場合にオフセットフィールドが登場します。
こじつけの例として、ある期間Aにおけるアクション数 y があり、変数として x が与えられたとします。
その際、単位時間あたりのアクション数 y と x との関係をもモデリングするというものです。
単位時間あたりのアクション数 = アクション数(λ) / A
λ = A × 単位時間あたりのアクション数
= A exp(β1 + β2 x)
= exp(β1 + β2 x + log(A) )
となります。
logを取ると、
log(λ) = β1 + β2 x + log(A)
と線形で書けるようになります。
つまり、β1 + β2 x + log(A) を線形予測子とするポアソン分布として扱うことができます。
log(λ)ということなので、リンク関数は、対数になります。
log(A)は、パラメータがつかないので、オフセット項となります。
Rで書く場合は、
fit.all <- glm(y ~ x, offset = log(A), family = poisson, data = d)
と書きます。
Modelerの場合の設定は、
と設定します。
実際は、Aというフィールドに面積やら時間が入っているかと思うのですが、Rでは、log(A)と書くのに対し、IBM SPSS Modeler(Clementine)では、いったん log(A) というフィールドを作成してあげる必要があります。

