連続値を予測する場合の評価関数 [データサイエンス、統計モデル]
今、5つのデータがあったと仮定して、値が高い順番になるように予測をする。
model_Aとmodel_Bの2つのモデルを作った場合、どちらの方が精度が良いか評価したい。
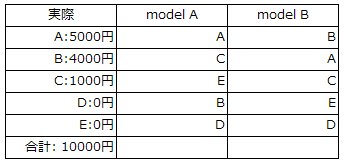
背景として、A~Eをどの順位にすれば良いのか?ということを考えたい。
売上の期待値が高いものを上位の順位に持って来て、低いものを下位の順位に持ってくる。
その際、どういう評価関数を使えば、その順位のソートの良し悪しを評価できるのか?を考えた。
グラフに書いてみると、明らかにAの方がよさそうだ。
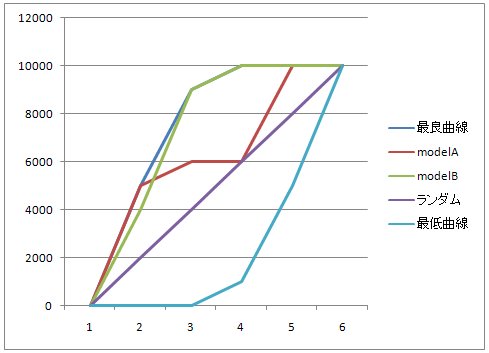
評価関数の特徴として、
1. 最良なモデル(神様モデル)は、1.0になるようにする。
2. 最低なモデルは、0.0になるようにする。
3. ランダムなモデルは、0.5になるようにする。
これらを加味すると、
(モデルの面積 - 最低モデルの面積)
= ----------------------------------------
(最良モデルの面積 - 最低モデルの面積)
上記の式だと、上手く評価関数を作れそうである。
上記の場合、
1. 最良モデル → 1.0
2. 最低モデル → 0.0
3. ランダムモデル → 0.5
最良曲線と最低曲線はランダム曲線を境に反転させたものなので、完全なランダムの場合の期待値は、0.5となっている。
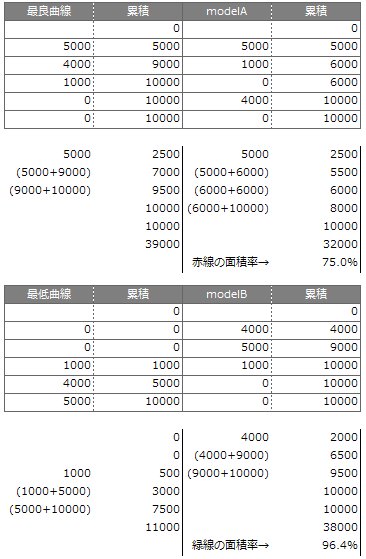
実際に、model A と model B を比較すると、Aは75.0%の一致率、Bだと96.4%になります。
model_Aとmodel_Bの2つのモデルを作った場合、どちらの方が精度が良いか評価したい。
背景として、A~Eをどの順位にすれば良いのか?ということを考えたい。
売上の期待値が高いものを上位の順位に持って来て、低いものを下位の順位に持ってくる。
その際、どういう評価関数を使えば、その順位のソートの良し悪しを評価できるのか?を考えた。
グラフに書いてみると、明らかにAの方がよさそうだ。
評価関数の特徴として、
1. 最良なモデル(神様モデル)は、1.0になるようにする。
2. 最低なモデルは、0.0になるようにする。
3. ランダムなモデルは、0.5になるようにする。
これらを加味すると、
(モデルの面積 - 最低モデルの面積)
= ----------------------------------------
(最良モデルの面積 - 最低モデルの面積)
上記の式だと、上手く評価関数を作れそうである。
上記の場合、
1. 最良モデル → 1.0
2. 最低モデル → 0.0
3. ランダムモデル → 0.5
最良曲線と最低曲線はランダム曲線を境に反転させたものなので、完全なランダムの場合の期待値は、0.5となっている。
実際に、model A と model B を比較すると、Aは75.0%の一致率、Bだと96.4%になります。

