IBM SPSS Modeler(Clementine):for ... endfor 使い方 2 [データサイエンス、統計モデル]
~使い方 2~
次に、一歩進んだ使い方を紹介。。
このままだと、リストを自分で作成する必要があります。
そこで、少し書き方を変えて、
とすると、ノードにある各フィールドに対し式を実行してくれます。
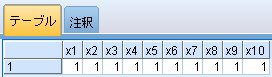
の場合、フィールドがx1~x10まで10個あるので、forループは10回繰り返されます。
-----
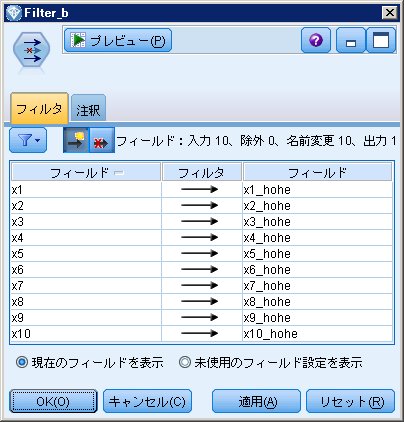
for f in_fields_to Filter_b
set Filter_b.new_name.^f = ^f >< '_hohe'
endfor
-----
と書いた場合、どうなるか?
1回目のループ
for f in_fields_to Filter_b
↑
ここで、fにx1が入力されます。
Filter_b.new_name.x1 = x1 >< '_hohe'
↑
この式が実行されます。
new_nameというのは、新しい名前。
つまり、新しい名前に_hogeを追加しなさい、という処理になります。
これを応用すれば、各フィールドに、自由に値を追加することができます。
では、追加するのではなく、削除するにはどうすれば良いか?
これは、別の関数を使うことになります。
次に、一歩進んだ使い方を紹介。。
for パラメータ in リスト
ここに式を書く
endfor
このままだと、リストを自分で作成する必要があります。
そこで、少し書き方を変えて、
for パラメータ in_fields_to ノードの名前
ここに式を書く
endfor
とすると、ノードにある各フィールドに対し式を実行してくれます。
の場合、フィールドがx1~x10まで10個あるので、forループは10回繰り返されます。
-----
for f in_fields_to Filter_b
set Filter_b.new_name.^f = ^f >< '_hohe'
endfor
-----
と書いた場合、どうなるか?
1回目のループ
for f in_fields_to Filter_b
↑
ここで、fにx1が入力されます。
Filter_b.new_name.x1 = x1 >< '_hohe'
↑
この式が実行されます。
new_nameというのは、新しい名前。
つまり、新しい名前に_hogeを追加しなさい、という処理になります。
これを応用すれば、各フィールドに、自由に値を追加することができます。
では、追加するのではなく、削除するにはどうすれば良いか?
これは、別の関数を使うことになります。


コメント 0