IBM SPSS Modeler 横と縦の変換 [データサイエンス、統計モデル]
BAF2012で西牧さんの講演で
・横もちデータ(要約済み)を縦もちデータ(トランザクション)に復元
するというものがあった。
実際にIBM SPSS Modeler(旧Clementine)のストリームを作ってみた。
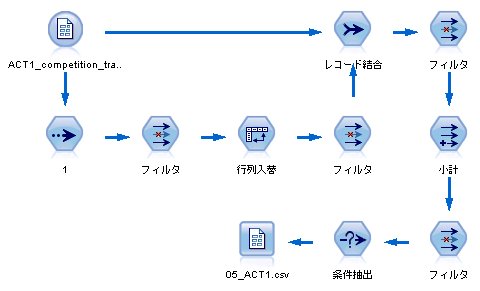
悪くはないのだが、一つ欠点がある。
横が長すぎる場合、結合の部分で爆発的にデータが増えることが問題である。
例えば、
10万レコード×1万フィールドだった場合、
10万×1万=10億レコードの超巨大ファイルになってしまう。
しかも、横のフィールド数自体も1万行あって巨大。
実際にストリームを実行してみると、翌朝、クレメンタインが落ちていた…
という悲しい結果が待っていた。
そこで、別途スクリプトを使いストリームを作ることにした。
<ストリームの思想>
一度に縦持ちにするのは、レコード数が爆発してしまうので、ファイルを1万回読みこみ、縦持ちにしてみようというスクリプトを書いた。
ストリーム自体はいたって簡単。
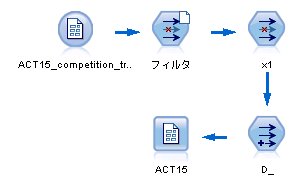
次に、スクリプトだが、下記のように書ける。
------------------------------------------------------------
set x0 = "\""
# in_fields_to でフィールドを一つ一つ読み込む
for f in_fields_to x1
# 処理しないフィールドは無視
if ^f = "MOLECULE" or ^f = "Act"
set D_.formula_expr = x0 >< ^f >< x0
# 縦持ちにしたい1万フィールドについて処理を行う
else
set x1.include.^f=true
set D_.formula_expr = x0 >< ^f >< x0
set x1.new_name.^f='num'
execute 'ACT15'
set x1.include.^f=false
endif
endfor
------------------------------------------------------------
大切なのは、キャッシュを最初に作っておくこと。
1万フィールドもあると、読み込みがスタートするだけで、時間がかかってしまう。
最初の1回目のループが実行されるとキャッシュが作成されるので、2回目以降のループがかなり高速になる。
・横もちデータ(要約済み)を縦もちデータ(トランザクション)に復元
するというものがあった。
実際にIBM SPSS Modeler(旧Clementine)のストリームを作ってみた。
悪くはないのだが、一つ欠点がある。
横が長すぎる場合、結合の部分で爆発的にデータが増えることが問題である。
例えば、
10万レコード×1万フィールドだった場合、
10万×1万=10億レコードの超巨大ファイルになってしまう。
しかも、横のフィールド数自体も1万行あって巨大。
実際にストリームを実行してみると、翌朝、クレメンタインが落ちていた…
という悲しい結果が待っていた。
そこで、別途スクリプトを使いストリームを作ることにした。
<ストリームの思想>
一度に縦持ちにするのは、レコード数が爆発してしまうので、ファイルを1万回読みこみ、縦持ちにしてみようというスクリプトを書いた。
ストリーム自体はいたって簡単。
次に、スクリプトだが、下記のように書ける。
------------------------------------------------------------
set x0 = "\""
# in_fields_to でフィールドを一つ一つ読み込む
for f in_fields_to x1
# 処理しないフィールドは無視
if ^f = "MOLECULE" or ^f = "Act"
set D_.formula_expr = x0 >< ^f >< x0
# 縦持ちにしたい1万フィールドについて処理を行う
else
set x1.include.^f=true
set D_.formula_expr = x0 >< ^f >< x0
set x1.new_name.^f='num'
execute 'ACT15'
set x1.include.^f=false
endif
endfor
------------------------------------------------------------
大切なのは、キャッシュを最初に作っておくこと。
1万フィールドもあると、読み込みがスタートするだけで、時間がかかってしまう。
最初の1回目のループが実行されるとキャッシュが作成されるので、2回目以降のループがかなり高速になる。


コメント 0